文章目录
- 前言
- 项目运行效果图
- 导入模块和库
- 伪装请求头
- 获取英雄列表
- 遍历英雄列表
- 创建英雄目录
- 访问英雄主页并解析HTML代码
- 获取皮肤名称
- 下载皮肤图片
- 完整代码
- 总结

前言
当谈到王者荣耀游戏时,无法忽视的是其丰富多样的英雄皮肤。这些皮肤不仅为玩家提供了个性化的游戏体验,还展示了设计师们的创造力和努力。然而,要手动下载每个英雄的皮肤图片是一项枯燥且费时的任务。
幸运的是,我们可以利用编程的力量来自动化这一过程。本文将介绍如何使用Python编写一个简单的爬虫程序,通过访问英雄主页并解析HTML代码,来批量下载王者荣耀英雄的皮肤图片。
我们将使用
requests模块发送HTTP请求,lxml库解析HTML代码,以及其他一些常用的Python模块和库。代码将从官方网站获取英雄列表数据,并遍历列表获取英雄的ID和中文名。然后,我们将访问每个英雄的主页,提取其中的皮肤名称,并根据名称构建皮肤图片的URL。最后,我们将使用requests模块下载图片,并保存到对应的英雄目录中。
这个爬虫程序不仅能够帮助玩家轻松获取王者荣耀英雄的所有皮肤图片,还可以为开发人员提供学习和研究的素材
请继续阅读本文,了解如何使用Python编写这个简单而有用的爬虫程序,并快速获取王者荣耀英雄的精美皮肤图片吧
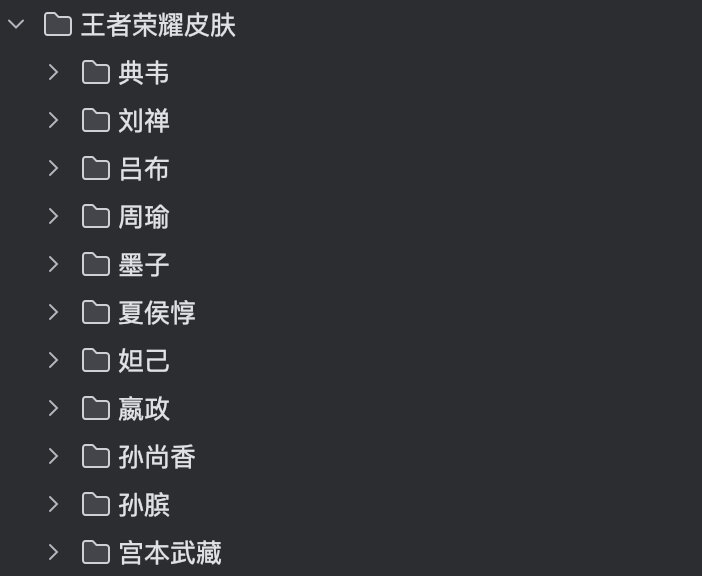
项目运行效果图

导入模块和库

import requests
from lxml import etree
import os
from time import sleep
这部分代码导入了需要使用的模块和库。
requests模块用于发送HTTP请求,lxml库用于解析HTML代码,os模块用于操作文件和目录,time模块中的sleep函数用于控制请求的间隔时间。
伪装请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'}
这里设置了一个伪装的请求头,用于模拟浏览器访问。通过设置请求头,可以避免被服务器识别为爬虫而导致请求被拒绝。
获取英雄列表
hero_list_url = 'https://pvp.qq.com/web201605/js/herolist.json'
hero_list_resp = requests.get(hero_list_url, headers=headers)
发送GET请求获取英雄列表的JSON数据。
requests.get()函数用于发送HTTP请求,并返回一个包含服务器响应的Response对象。
遍历英雄列表
for h in hero_list_resp.json():
ename = h.get('ename')
cname = h.get('cname')
遍历英雄列表,获取每个英雄的
ename(英雄ID)和cname(中文名)。hero_list_resp.json()将服务器响应的JSON数据转换为Python对象,这里是一个包含多个英雄信息字典的列表。
创建英雄目录
if not os.path.exists(cname):
os.makedirs(cname)
如果英雄目录不存在,则创建英雄目录。
os.path.exists()函数用于检查路径是否存在,os.makedirs()函数用于递归创建目录。
访问英雄主页并解析HTML代码
hero_info_url = f'https://pvp.qq.com/web201605/herodetail/{ename}.shtml'
hero_info_resp = requests.get(hero_info_url, headers=headers)
hero_info_resp.encoding = 'gbk'
e = etree.HTML(hero_info_resp.text)
构建英雄主页的URL,并发送GET请求获取页面内容。通过在URL中插入英雄的
ename,可以访问到每个英雄的详细信息页面。设置encoding为gbk,以正确解析中文字符。使用etree.HTML()函数将页面内容转换为可解析的HTML对象。
获取皮肤名称
names = e.xpath('//ul[@class="pic-pf-list pic-pf-list3"]/@data-imgname')[0]
names = [name[0:name.index('&')] for name in names.split('|')]
使用XPath表达式提取HTML代码中的皮肤名称。这里的XPath表达式定位到
ul节点的class属性为pic-pf-list pic-pf-list3的元素,然后提取其中的data-imgname属性值。返回的是一个字符串,包含了多个皮肤名称,用竖线分隔。通过切片和分割操作,将字符串处理成一个包含所有皮肤名称的列表。
下载皮肤图片
for i, n in enumerate(names):
resp = requests.get(f'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{ename}/{ename}-bigskin-{i+1}.jpg', headers=headers)
with open(f'{cname}/{n}.jpg', 'wb') as f:
f.write(resp.content)
print(f'已下载:{n} 的皮肤')
sleep(1)
遍历皮肤名称列表,构建皮肤图片的URL并发送GET请求获取图片内容。根据皮肤的URL模式,使用英雄的
ename和皮肤的序号构建具体的URL。使用requests.get()函数发送请求,并返回一个包含服务器响应的Response对象。使用open()函数创建一个文件对象,以二进制写入模式打开文件,将图片内容写入该文件中,以保存皮肤图片。最后输出已下载皮肤的信息,并使用sleep(1)函数暂停1秒,控制请求的间隔时间,避免对服务器造成过大的负载。
完整代码
# 发送请求的模块 pip install requests
import requests
# 解析html代码的工具 lxml pip install lxml
from lxml import etree
import os
from time import sleep
# 伪装自己
headers ={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'}
# 获取英雄列表的URL
hero_list_url = 'https://pvp.qq.com/web201605/js/herolist.json'
# 发送HTTP请求获取英雄列表数据
hero_list_resp = requests.get(hero_list_url,headers=headers)
# 遍历英雄列表数据
for h in hero_list_resp.json():
# 获取英雄的ID和中文名
ename = h.get('ename')
cname = h.get('cname')
# 如果英雄目录不存在,则创建
if not os.path.exists(cname):
os.makedirs(cname)
# 访问英雄主页
hero_info_url = f'https://pvp.qq.com/web201605/herodetail/{ename}.shtml'
hero_info_resp = requests.get(hero_info_url,headers=headers)
hero_info_resp.encoding='gbk'
e = etree.HTML(hero_info_resp.text)
# 提取皮肤名称
names = e.xpath('//ul[@class="pic-pf-list pic-pf-list3"]/@data-imgname')[0]
names = [name[0:name.index('&')] for name in names.split('|')]
# 遍历每个皮肤名称
for i,n in enumerate(names):
# 构建皮肤图片的URL
resp = requests.get(f'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{ename}/{ename}-bigskin-{i+1}.jpg',headers=headers)
# 保存皮肤图片
with open(f'{cname}/{n}.jpg','wb') as f:
f.write(resp.content)
# 打印已下载的皮肤信息
print(f'已下载:{n} 的皮肤')
# 等待1秒,避免请求频率过快
sleep(1)
总结
本文介绍了如何使用Python编写一个简单的爬虫程序,来批量下载王者荣耀英雄的皮肤图片。通过访问英雄主页并解析HTML代码,我们可以获取到每个英雄的皮肤名称,并根据名称构建皮肤图片的URL。然后使用Python的requests模块发送HTTP请求,并将下载得到的图片保存到对应的英雄目录中。
这个爬虫程序不仅可以帮助玩家轻松获取王者荣耀英雄的所有皮肤图片,还为开发人员提供了学习和研究的素材。通过阅读本文,读者可以了解到如何使用requests模块发送HTTP请求、如何使用lxml库解析HTML代码,以及一些常用的Python模块和库的使用方法。
在实现过程中,我们还介绍了如何伪装请求头,避免被服务器识别为爬虫。并且,为了控制请求的间隔时间,我们使用了time模块的sleep函数。
通过阅读本文,读者可以学到许多有用的爬虫技巧和Python编程技巧,同时也可以获得更好的游戏体验和更多的创作灵感。希望本文对读者有所帮助,能够在王者荣耀的世界中畅游愉快!