【必看】原创声明:转载请注明作者 & 文章来源:都在用Stream流?
hello,我是小索奇,这次讲解JDK 8新特性的重点!Stream流,到后期学习框架时候你会发现大量的Stream流出现,如果你不了解,相信索奇,你一定会再次回来的(索奇学习框架时也是..)
内容虽然很干货,但代码比较枯燥,现在不想看的可收藏备看~
Stream API
为什么要用Stream API
-
Stream流是Java 8中引入的一种新的API !importance重要 它主要是用于对集合数据进行处理的工具。Stream流可以用于对集合进行过滤、排序、映射、归约等操作,这些操作可以通过链式调用来完成,使得代码更加简洁和易于阅读。Stream流还支持并行处理,可以帮助我们更快地处理大量数据。
-
Stream流的强大之处便是在于提供了丰富的中间操作,相比集合或数组这类容器,极大的简化源数据的计算复杂度
实际开发中,项目中多数数据源都来自于MySQL、Oracle等。但现在数据源可以更多了,有MongDB,Radis等,而这些NoSQL的数据就需要Java层面去处理。
非关系型数据库(NOSQL):MongDB,Radis,采用非传统的表格结构,比如文档、键-值对、图形等,这些结构不需要使用SQL语句进行查询和操作
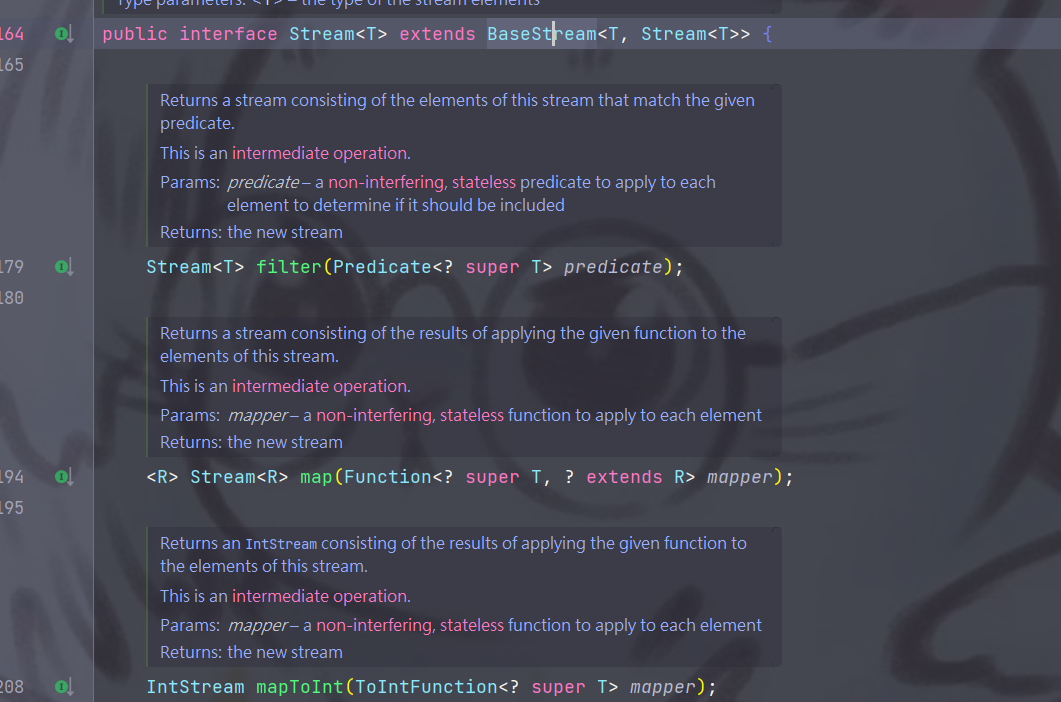
image-20230717001419217
举例
比例客户端发送请求->Java后台(写SQL语句)->DB查询,结果返回给Java后台->客户端显示
对于非关系型数据库,我们可以在内存层面使用StreamAPI进行过滤
在内存层面,非关系型数据库通常采用键-值存储方式,可以直接将数据存储在内存中,这样可以大大提高数据的读取和写入速度。此外,非关系型数据库通常采用分布式架构来实现高可用性和可扩展性
使用关系型数据库进行数据过滤可能会比使用非关系型数据库慢一些,因为关系型数据库需要进行表格结构的转换和查询优化等操作。但是,关系型数据库也有其优点,比如支持事务、数据一致性等。因此,在选择数据库时,需要根据具体的应用场景和需求来进行选择。
-
Stream它主要是用于对集合数据进行处理的工具。Stream流可以用于对集合进行过滤、排序、映射、归约等操作
Stream API vs 集合框架
-
Stream API 关注的是多个数据的计算(排序、查找、过滤、映射、遍历等),面向CPU的。
-
集合关注的数据的存储,面向内存的。
-
Stream API 之于集合,类似于SQL之于数据表的查询。
使用说明
①Stream 自己不会存储元素。
②Stream 不会改变源对象。相反,他们会返回一个持有结果的新Stream。
③Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行。即一旦执行终止操作,就执行中间操作链,并产生结果。
④ Stream一旦执行了终止操作,就不能再调用其它中间操作或终止操作了。
Stream 执行流程
步骤1:Stream的实例化
-
一个数据源,如集合、数组,获取一个流
步骤2:一系列的中间操作
-
每次处理都会返回一个持有结果的新Stream,即中间操作的方法返回值仍然是Stream类型的对象。因此中间操作
可以是个操作链,可对数据源的数据进行次处理,但是在终结操作前,并不会真正执行。
步骤3:执行终止操作(终端操作)
终止操作的方法返回值类型就不再是Stream了,因此一旦执行终止操作,就结束整个Stream操作了。一旦执行终止操作,就执行中间操
作链,最终产生结果并结束Stream。
拓展
stream方法
在Java 8中,集合类(如List、Set等)新增了一个stream()方法,可以返回一个Stream对象。Stream是一个Java 8中新增的API,用于操
作集合数据,可以实现函数式编程的方式来处理集合数据。
List的默认方法
forEach方法
forEach()是Java 8中新增的一个方法,它是Stream API的一部分,可以对集合中的每个元素执行指定的操作。forEach()方法接受一个Lambda表达式或者方法引用作为参数,Lambda表达式中定义了对每个元素要执行的操作。
下面分别用Lambda和方法引用输出,结果相同
List<String> list2 = Arrays.asList("apple", "banana", "orange");
System.out.println("方法引用");
list2.forEach(System.out::println);
System.out.println("Lambda表达式");
list2.forEach(s-> System.out.println(s));
-
Arrays.asList() 方法可以方便地将一个数组转换为一个List集合
代码演示
员工表Employee
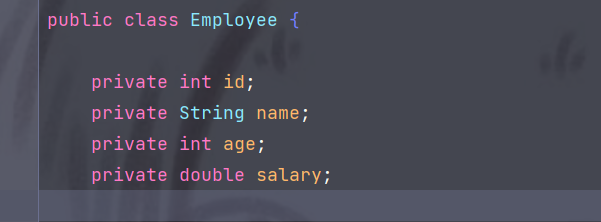
image-20230716222356654
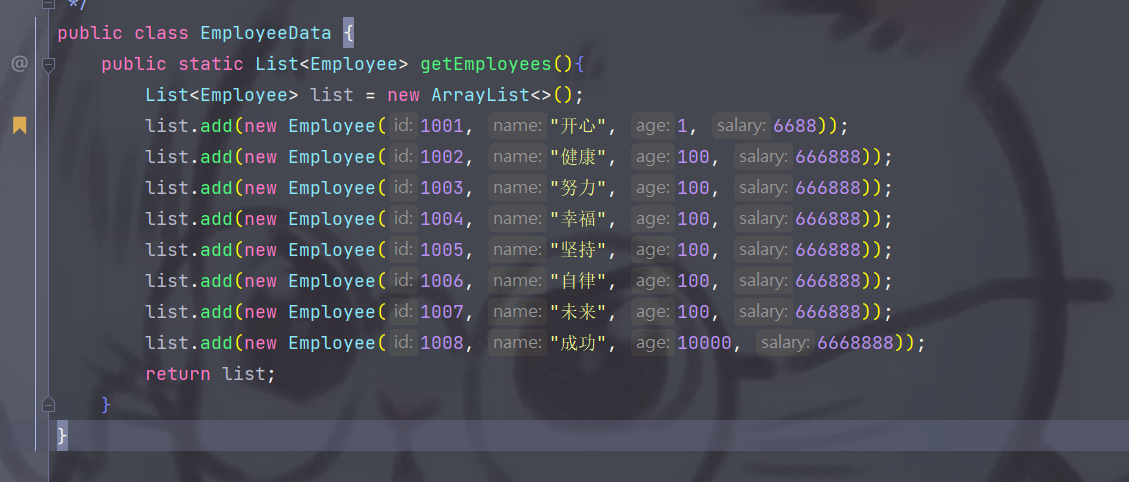
image-20230726011231112
Stream的所有方法都给大家截了下来,见下图
image-20230726004337375
StreamAPITest
public class StreamAPITest {
/**
* 创建 Stream方式一:通过集合
*/
@Test
public void test1(){
List<Employee> list = EmployeeData.getEmployees();
// default Stream<E> stream() : 返回一个顺序流
Stream<Employee> stream = list.stream();
// default Stream<E> parallelStream() : 返回一个并行流
Stream<Employee> stream1 = list.parallelStream();
System.out.println(stream);
System.out.println(stream1);
}
/**
* 创建 Stream方式二:通过数组
*/
@Test
public void test2(){
//调用Arrays类的static <T> Stream<T> stream(T[] array): 返回一个流
Integer[] arr = new Integer[]{1,2,3,4,5};
// 先得到Stream的示例
Stream<Integer> stream = Arrays.stream(arr);
int[] arr1 = new int[]{1,2,3,4,5};
IntStream stream1 = Arrays.stream(arr1);
}
/**
* 创建 Stream方式三:通过Stream的of()
*/
@Test
public void test3(){
Stream<String> stream = Stream.of("AA", "BB", "CC", "SS", "DD");
}
}
StreamAPITest1
public class StreamAPITest01 {
//1-筛选与切片
@Test
public void test1() {
// filter(Predicate p)——接收 Lambda,从流中排除某些元素。
//练习:查询员工表中薪资大于7000的员工信息
List<Employee> list = EmployeeData.getEmployees();
Stream<Employee> stream = list.stream();
// forEach遍历是终止操作
stream.filter(emp -> emp.getSalary() > 7000).forEach(System.out::println);
System.out.println();
// limit(n)——截断流,使其元素不超过给定数量。
//这里报错,因为stream已经执行了终止操作,就不可以再调用其它的中间操作或终止操作了。要重新调用
// stream.limit(2).forEach(System.out::println);
list.stream().filter(emp -> emp.getSalary() > 7000).limit(2).forEach(System.out::println);
System.out.println();
// skip(n) —— 跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。与 limit(n) 互补
list.stream().skip(5).forEach(System.out::println);
System.out.println();
// distinct()——筛选,通过流所生成元素的 hashCode() 和 equals() 去除重复元素
list.add(new Employee(1009, "马斯克", 40, 12500.32));
list.add(new Employee(1009, "马斯克", 40, 12500.32));
list.add(new Employee(1009, "马斯克", 40, 12500.32));
list.add(new Employee(1009, "马斯克", 40, 12500.32));
list.stream().distinct().forEach(System.out::println);
}
//2-映射
@Test
public void test2() {
//map(Function f)——接收一个函数作为参数,将元素转换成其他形式或提取信息,该函数会被应用到每个元素上,并将其映射成一个新的元素。
//练习:转换为大写
List<String> list = Arrays.asList("aa", "bb", "cc", "dd");
//方式1:
list.stream().map(str -> str.toUpperCase()).forEach(System.out::println);
//方式2:
list.stream().map(String :: toUpperCase).forEach(System.out::println);
//练习:获取员工姓名长度大于3的员工。
List<Employee> employees = EmployeeData.getEmployees();
employees.stream().filter(emp -> emp.getName().length() > 3).forEach(System.out::println);
//练习:获取员工姓名长度大于3的员工的姓名。
//方式1:
employees.stream().filter(emp -> emp.getName().length() > 3).map(emp -> emp.getName()).forEach(System.out::println);
//方式2:
employees.stream().map(emp -> emp.getName()).filter(name -> name.length() > 3).forEach(System.out::println);
//方式3:
employees.stream().map(Employee::getName).filter(name -> name.length() > 3).forEach(System.out::println);
}
//3-排序
@Test
public void test3() {
//sorted()——自然排序
Integer[] arr = new Integer[]{345,3,64,3,46,7,3,34,65,68};
String[] arr1 = new String[]{"GG","DD","MM","SS","JJ"};
Arrays.stream(arr).sorted().forEach(System.out::println);
System.out.println(Arrays.toString(arr));//arr原数组并没有因为升序,做调整。
Arrays.stream(arr1).sorted().forEach(System.out::println);
//因为Employee没有实现Comparable接口,所以报错!使用Collections.sort()或者Arrays.sort()方法对一个对象集合进行排序时,需要使用对象的自然排序规则进行比较。而默认情况下,Java并不知道如何比较一个自定义对象的大小,因此需要我们自己定义比较规则。
// List<Employee> list = EmployeeData.getEmployees();
// list.stream().sorted().forEach(System.out::println);
//sorted(Comparator com)——定制排序
List<Employee> list = EmployeeData.getEmployees();
list.stream().sorted((e1,e2) -> e1.getAge() - e2.getAge()).forEach(System.out::println);
//针对于字符串从大大小排列
Arrays.stream(arr1).sorted((s1, s2) -> -s1.compareTo(s2)).forEach(System.out::println);
// Arrays.stream(arr1).sorted(String :: compareTo).forEach(System.out::println);
}
}
精准练习
public class StreamAPITest2 {
@Test
public void test01(){
// boolean allMatch(Predicate<? super T> predicate);
List<Employee> list = EmployeeData.getEmployees();
//是否所有员工可以匹配到age>100
System.out.println(list.stream().allMatch(employee -> employee.getAge() > 100));
//是否存在一个员工age>99
System.out.println(list.stream().anyMatch(employee -> employee.getAge() > 99));
// findFirst()返回第一个元素,获取到的是第一个Optional,再调用get方法才可以获取第一个员工:
// Employee{id=1001, name='开心', age=100, salary=666888.0}
System.out.println(list.stream().findFirst().get());
}
@Test
public void test02(){
// count 返回流中元素的总个数
// 返回流中工资大于1w的员工的总个数
List<Employee> list = EmployeeData.getEmployees();
System.out.println(list.stream().filter(employee -> employee.getSalary()>10000).count());
// max(Comparator c) 返回流中的最大值
// 打算获取最高工资
//先返回最高(最低min)工资的员工
System.out.println(list.stream().max((e1, e2) -> Double.compare(e1.getSalary(), e2.getSalary())));
//Method-1 获取到员工,在获取自身的工资即可
System.out.println(list.stream().max((e1, e2) -> Double.compare(e1.getSalary(), e2.getSalary())).get().getSalary());
//Method-2 先映射工资在调用最高工资 Double.compare是返回一个int,只要返回int就行()--int compare(T o1, T o2);
System.out.println(list.stream().map(employee -> employee.getSalary()).max((s1, s2) -> Double.compare(s1, s2)).get());
// 改为方法引用
System.out.println(list.stream().map(employee -> employee.getSalary()).max(Double::compare).get());
// forEach 内部迭代
list.stream().forEach(System.out::println);
// 针对集合jdk8 增加一个遍历的方法 -- Iterator迭代器、增强for、一般for、ForEach
list.forEach(System.out::println);
}
@Test
public void test03(){
/**
* 归约操作,可以将流中元素反复结合起来,得到一个值。返回T
*/
//T reduce(T identity, BinaryOperator<T> accumulator);
//BinaryOperator 继承 BiFunction , 其中的方法: R apply(T t, U u);
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
// identity 是一个累计函数的恒等值,可以把它理解为种子,在此基础上进行相加,比如10,x1+x2为55,则共65
System.out.println(list.stream().reduce(0, (x1, x2) -> x1 + x2));
// 改为函数式接口
System.out.println(list.stream().reduce(0, (x1, x2) -> Integer.sum(x1,x2)));
System.out.println(list.stream().reduce(0, Integer::sum));
// 获取所有员工工资总和
List<Employee> list1 = EmployeeData.getEmployees();
// 利用reduce将所有员工工资相加
System.out.println(list1.stream().map(emp -> emp.getSalary()).reduce((salary1, salary2) -> Double.sum(salary1, salary2)));
System.out.println(list1.stream().map(emp -> emp.getSalary()).reduce(Double::sum));
}
@Test
public void test04(){
// collect(Collector c) 将流转换为其它形式,接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法
// 练习1:查找工资大于666888的员工,结果返回为一个List或Set
List<Employee> list = EmployeeData.getEmployees();
List<Employee> list1 = list.stream().filter(emp -> emp.getSalary() > 666888).collect(Collectors.toList());
list1.forEach(System.out::println);
System.out.println("------list2------");
// 练习2:按照员工的年龄进行排序,返回到一个新的List中
List<Employee> list2 = list.stream().sorted((e1, e2) -> e1.getAge() - e2.getAge()).collect(Collectors.toList());
list2.forEach(System.out::println);
}
}
索奇语录
-
世界就像人类掌控蚂蚁、多维掌控三维一样简单而又复杂且又微妙(以前的个性签名,放到这里做个记录)


![[详细教程+渠道对接+实战陪跑社区]抖音超火小说推文新玩法](https://img-blog.csdnimg.cn/img_convert/6365cdb008e4ceee328785daa7fe3614.jpeg)




![后端Linux软件安装大全[JDK、Tomcat、MySQL、Irzsz、Git、Maven、Redis、Nginx...持续更新中]](https://img-blog.csdnimg.cn/9e691c072f9e4993a340fef4f9118d02.png)