1 Spark作业提交流程

2 Spark提交作业参数
1)在提交任务时的几个重要参数
executor-cores —— 每个executor使用的内核数,默认为1,官方建议2-5个
num-executors —— 启动executors的数量,默认为2
executor-memory —— executor内存大小,默认1G
driver-cores —— driver使用内核数,默认为1
driver-memory —— driver内存大小,默认512M
2)边给一个提交任务的样式
spark-submit \
--master local[5] \
--driver-cores 2 \
--driver-memory 8g \
--executor-cores 4 \
--num-executors 10 \
--executor-memory 8g \
--class PackageName.ClassName XXXX.jar \
--name "Spark Job Name" \
InputPath \
OutputPath
3 RDD五大属性
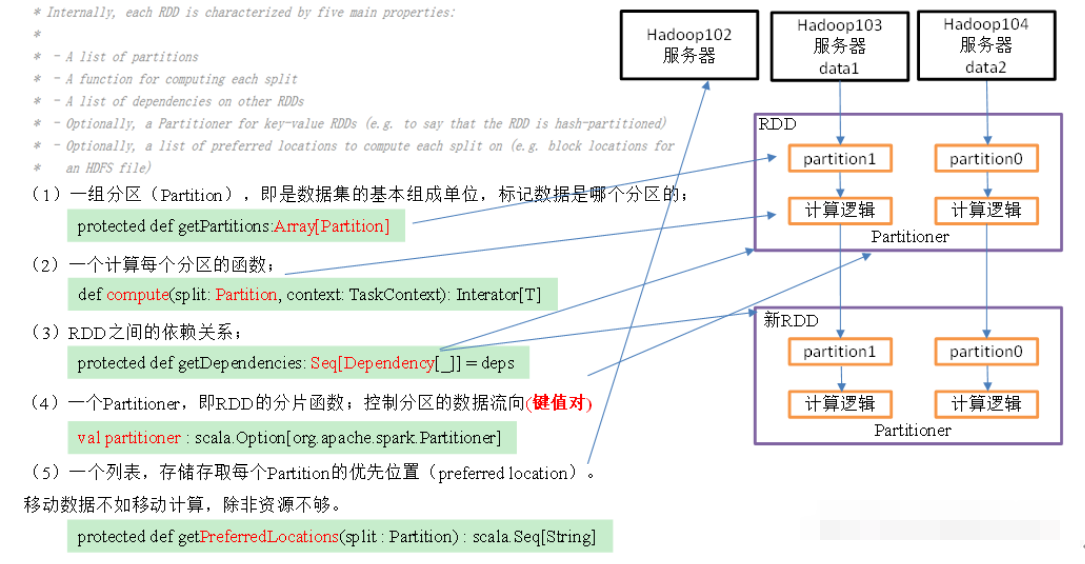
4 算子
4.1 Transformation
1)单Value
(1)map
(2)mapPartitions
(3)mapPartitionsWithIndex
(4)flatMap
(5)glom
(6)groupBy
(7)filter
(8)sample
(9)distinct
(10)coalesce
(11)repartition
(12)sortBy
(13)pipe
2)双vlaue
(1)intersection
(2)union
(3)subtract
(4)zip
3)Key-Value
(1)partitionBy
(2)reduceByKey
(3)groupByKey
(4)aggregateByKey
(5)foldByKey
(6)combineByKey
(7)sortByKey
(8)mapValues
(9)join
(10)cogroup
4.2 Action
(1)reduce
(2)collect
(3)count
(4)first
(5)take
(6)takeOrdered
(7)aggregate
(8)fold
(9)countByKey
(10)save
(11)foreach
(12)foreachPartition
4.3 map和mapPartitions区别
1)map:每次处理一条数据
2)mapPartitions:每次处理一个分区数据
4.4 Repartition和Coalesce区别
1)关系:
两者都是用来改变RDD的partition数量的
repartition底层调用的就是coalesce方法:coalesce(numPartitions, shuffle = true)
2)区别:
repartition一定会发生shuffle,coalesce根据传入的参数来判断是否发生shuffle
一般情况下增大rdd的partition数量使用repartition,减少partition数量时使用coalesce
4.5 reduceByKey与groupByKey的区别
reduceByKey:具有预聚合操作
groupByKey:没有预聚合
在不影响业务逻辑的前提下,优先采用reduceByKey。
4.6 reduceByKey、foldByKey、aggregateByKey、combineByKey区别
| ReduceByKey | 没有初始值 | 分区内和分区间逻辑相同 |
|---|---|---|
| foldByKey | 有初始值 | 分区内和分区间逻辑相同 |
| aggregateByKey | 有初始值 | 分区内和分区间逻辑可以不同 |
| combineByKey | 初始值可以变化结构 | 分区内和分区间逻辑不同 |
5 Spark任务的划分
(1)Application:初始化一个SparkContext即生成一个Application;
(2)Job:一个Action算子就会生成一个Job;
(3)Stage:Stage等于宽依赖的个数加1;
(4)Task:一个Stage阶段中,最后一个RDD的分区个数就是Task的个数。
6 Cache
spark 非常重要的一个功能特性就是可以将 RDD 持久化在内存中。调用 cache()和 persist()方法即可。
cache()和 persist()的区别在于, cache()是 persist()的一种简化方式, cache()的底层就是调用 persist()的无参版本persist(MEMORY_ONLY), 将数据持久化到内存中。如果需要从内存中清除缓存, 可以使用 unpersist()方法。 RDD 持久化是可以手动选择不同的策略的。 在调用 persist()时传入对应的 StorageLevel 即可。
DataFrame的cache默认采用 MEMORY_AND_DISK
RDD 的cache默认方式采用MEMORY_ONLY
缓存:(1)dataFrame.cache
(2)sparkSession.catalog.cacheTable(“tableName”)
释放缓存:(1)dataFrame.unpersist
(2)sparkSession.catalog.uncacheTable(“tableName”)
7 Cache和CheckPoint
7.1 CheckPoint
Checkpoint 首先会调用 SparkContext 的 setCheckPointDIR()方法, 设置一个容错的文件系统的目录, 比如说 HDFS;然后对 RDD 调用 checkpoint()方法。之后在 RDD 所处的 job 运行结束之后, 会启动一个单独的 job, 来将checkpoint 过的 RDD 数据写入之前设置的文件系统, 进行高可用、 容错的类持久化操作。
检查点机制是我们在 spark streaming 中用来保障容错性的主要机制, 它可以使 spark streaming 阶段性的把应用数据存储到诸如 HDFS 等可靠存储系统中,以供恢复时使用。 具体来说基于以下两个目的服务:
1. 控制发生失败时需要重算的状态数。 Spark streaming 可以通过转化图的谱系图来重算状态, 检查点机制则可以控制需要在转化图中回溯多远。
2. 提供驱动器程序容错。 如果流计算应用中的驱动器程序崩溃了, 你可以重启驱动器程序并让驱动器程序从检查点恢复, 这样 spark streaming 就可以读取之前运行的程序处理数据的进度, 并从那里继续。
7.2 Cache和CheckPoint区别
1)Cache只是将数据保存在 BlockManager 中, 但是 RDD 的lineage(血缘关系, 依赖关系)是不变的。但是 checkpoint 执行完之后, rdd 已经没有之前所谓的依赖 rdd 了, 而只有一个强行为其设置的 checkpointRDD,checkpoint 之后 rdd 的 lineage 就改变了。
2)Cache缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint的数据通常存储在HDFS等容错、高可用的文件系统,可靠性高。
3)建议对checkpoint()的RDD使用Cache缓存,这样checkpoint的job只需从Cache缓存中读取数据即可,否则需要再从头计算一次RDD。
8 累加器
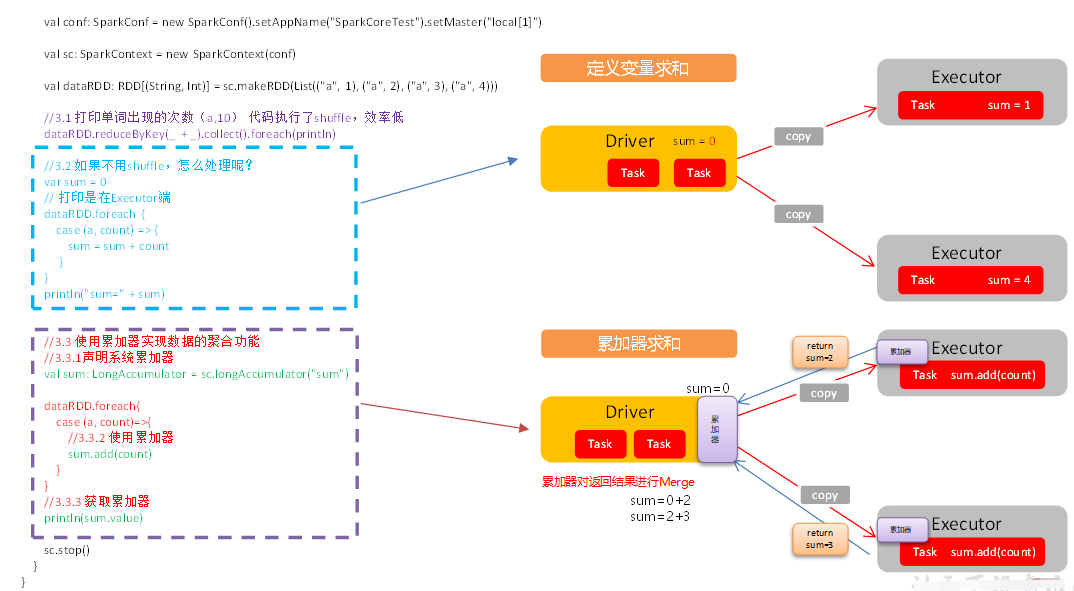
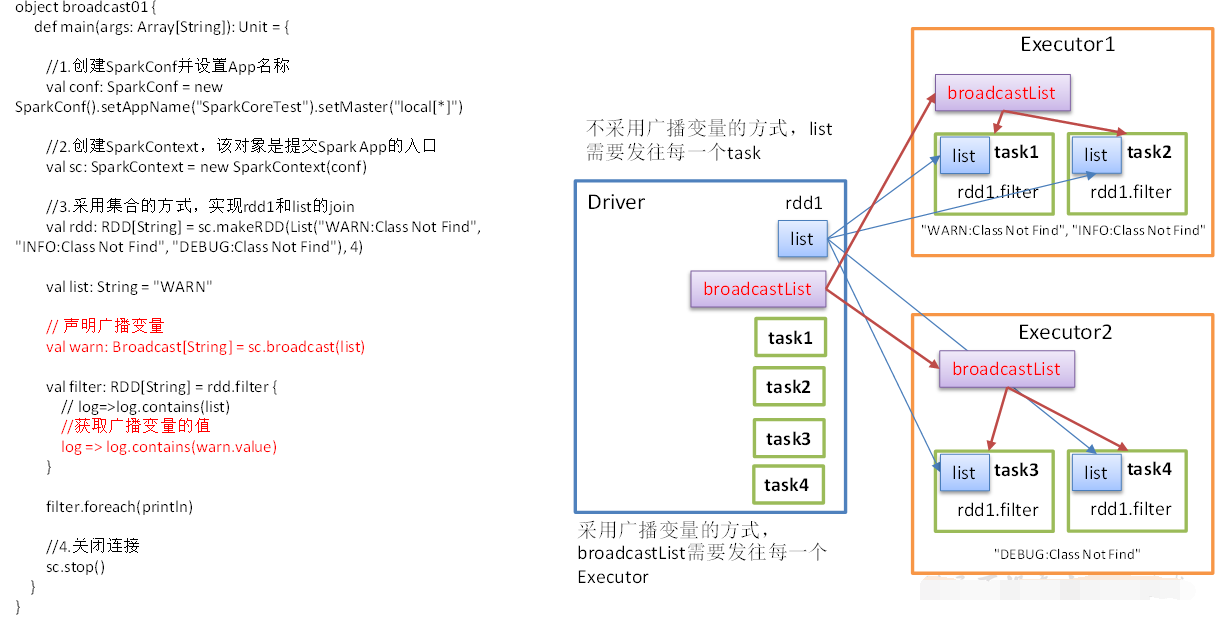
9 广播变量
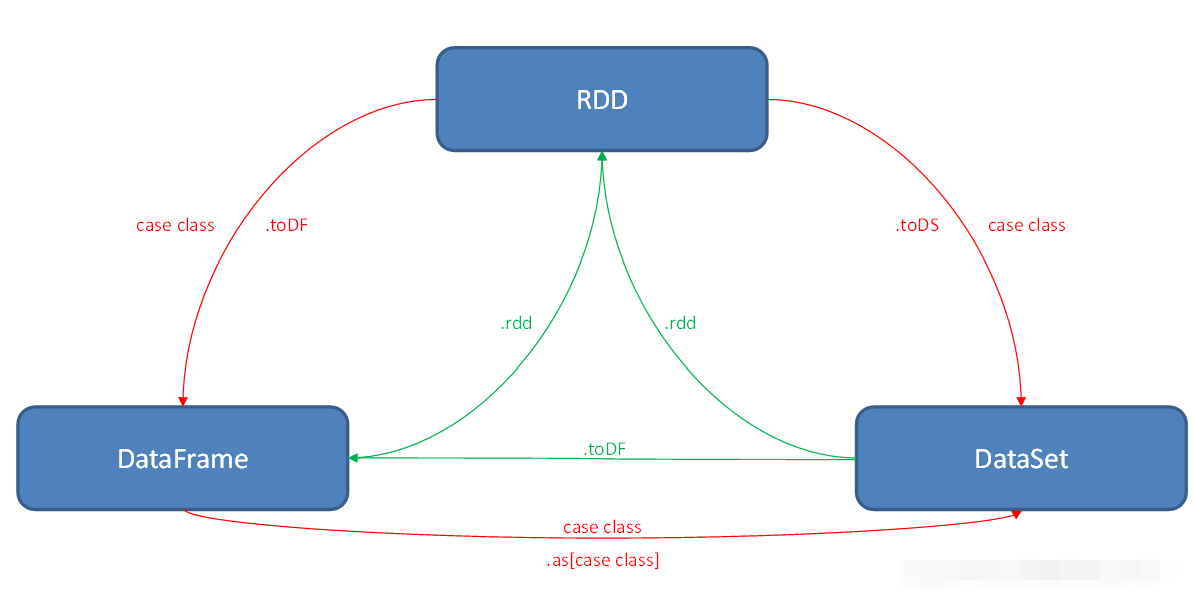
10 RDD、DataFrame、DataSet三者的转换
11 Spark Streaming消费Kafka数据
11.1 Spark Streaming第一次运行不丢失数据
kafka参数 auto.offset.reset 设置成`earliest ``从最初始偏移量开始消费数据
11.2 Spark Streaming精准一次消费Kafka
手动维护偏移量,处理完业务数据后,再进行提交偏移量操作
极端情况下,如在提交偏移量时断网或停电会造成spark程序第二次启动时重复消费问题,所以在涉及到金额或精确性非常高的场景会使用事物保证精准一次消费
11.3 Spark Streaming控制每秒消费数据的速度
通过spark.streaming.kafka.maxRatePerPartition参数来设置Spark Streaming从kafka分区每秒拉取的条数
11.4 Spark Streaming背压机制
把spark.streaming.backpressure.enabled 参数设置为ture,开启背压机制后Spark Streaming会根据延迟动态去kafka消费数据,上限由spark.streaming.kafka.maxRatePerPartition参数控制,所以两个参数一般会一起使用。
11.5 Spark Streaming消费Kafka数据默认分区个数
Spark Streaming默认分区个数与所对接的kafka topic分区个数一致,Spark Streaming里一般不会使用repartition算子增大分区,因为repartition会进行shuffle增加耗时。
11.6 SparkStreaming有哪几种方式消费Kafka中的数据?它们之间的区别是什么?
一、基于Receiver的方式
这种方式使用Receiver来获取数据。Receiver是使用Kafka的高层次Consumer API来实现的。receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的(如果突然数据暴增,大量batch堆积,很容易出现内存溢出的问题),然后Spark Streaming启动的job会去处理那些数据。
然而,在默认的配置下,这种方式可能会因为底层的失败而丢失数据。如果要启用高可靠机制,让数据零丢失,就必须启用Spark Streaming的预写日志机制(Write Ahead Log,WAL)。该机制会同步地将接收到的Kafka数据写入分布式文件系统(比如HDFS)上的预写日志中。所以,即使底层节点出现了失败,也可以使用预写日志中的数据进行恢复。
二、基于Direct的方式
这种新的不基于Receiver的直接方式,是在Spark 1.3中引入的,从而能够确保更加健壮的机制。替代掉使用Receiver来接收数据后,这种方式会周期性地查询Kafka,来获得每个topic+partition的最新的offset,从而定义每个batch的offset的范围。当处理数据的job启动时,就会使用Kafka的简单consumer api来获取Kafka指定offset范围的数据。
优点如下:
简化并行读取:如果要读取多个partition,不需要创建多个输入DStream然后对它们进行union操作。Spark会创建跟Kafka partition一样多的RDD partition,并且会并行从Kafka中读取数据。所以在Kafka partition和RDD partition之间,有一个一对一的映射关系。
高性能:如果要保证零数据丢失,在基于receiver的方式中,需要开启WAL机制。这种方式其实效率低下,因为数据实际上被复制了两份,Kafka自己本身就有高可靠的机制,会对数据复制一份,而这里又会复制一份到WAL中。而基于direct的方式,不依赖Receiver,不需要开启WAL机制,只要Kafka中作了数据的复制,那么就可以通过Kafka的副本进行恢复。
一次且仅一次的事务机制。
三、对比:
基于receiver的方式,是使用Kafka的高阶API来在ZooKeeper中保存消费过的offset的。这是消费Kafka数据的传统方式。这种方式配合着WAL机制可以保证数据零丢失的高可靠性,但是却无法保证数据被处理一次且仅一次,可能会处理两次。因为Spark和ZooKeeper之间可能是不同步的。
基于direct的方式,使用kafka的简单api,Spark Streaming自己就负责追踪消费的offset,并保存在checkpoint中。Spark自己一定是同步的,因此可以保证数据是消费一次且仅消费一次。
在实际生产环境中大都用Direct方式
12 Spark Streaming优雅关闭
把spark.streaming.stopGracefullyOnShutdown参数设置成ture,Spark会在JVM关闭时正常关闭StreamingContext,而不是立马关闭。
13 Spark性能调优
Spark性能调优
14 为什么区分宽窄依赖
对于窄依赖:
窄依赖的多个分区可以并行计算;
窄依赖的一个分区的数据如果丢失只需要重新计算对应的分区的数据就可以了。
对于宽依赖:
划分 Stage(阶段)的依据:对于宽依赖,必须等到上一阶段计算完成才能计算下一阶段。
DAG 划分为 Stage 的算法:
核心算法: 回溯算法
从后往前回溯/反向解析, 遇到窄依赖加入本 Stage, 遇见宽依赖进行 Stage 切分。Spark 内核会从触发 Action 操作的那个 RDD 开始从后往前推, 首先会为最后一个 RDD 创建一个 Stage, 然后继续倒推, 如果发现对某个 RDD 是宽依赖, 那么就会将宽依赖的那个 RDD 创建一个新的 Stage, 那个 RDD 就是新的 Stage的最后一个 RDD。 然后依次类推, 继续倒推, 根据窄依赖或者宽依赖进行 Stage的划分, 直到所有的 RDD 全部遍历完成为止。
15 Spark 主备切换机制原理
Master 实际上可以配置两个, Spark 原生的 standalone 模式是支持 Master主备切换的。 当 Active Master 节点挂掉以后, 我们可以将 Standby Master 切换为 Active Master。
Spark Master 主备切换可以基于两种机制, 一种是基于文件系统的, 一种是基于 ZooKeeper 的。
基于文件系统的主备切换机制, 需要在 Active Master 挂掉之后手动切换到Standby Master 上;
而基于 Zookeeper 的主备切换机制, 可以实现自动切换 Master。
注: Master 切换需要注意 2 点:
1、 在 Master 切换的过程中, 所有的已经在运行的程序皆正常运行! 因为 SparkApplication 在运行前就已经通过Cluster Manager 获得了计算资源, 所以在运行时 Job 本身的 调度和处理和 Master 是没有任何关系。
2、 在 Master 的切换过程中唯一的影响是不能提交新的 Job: 一方面不能够提交新的应用程序给集群, 因为只有 Active Master 才能接受新的程序的提交请求; 另外一方面, 已经运行的程序中也不能够因 Action 操作触发新的 Job 的提交请求。
Tips: Spark Master 使用 Zookeeper 进行 HA, 有哪些源数据保存到Zookeeper 里面?
spark 通过这个参数 spark.deploy.zookeeper.dir 指定 master 元数据在zookeeper 中保存的位置, 包括 Worker, Driver 和 Application 以及Executors。 standby 节点要从 zk 中, 获得元数据信息, 恢复集群运行状态,才能对外继续提供服务, 作业提交资源申请等, 在恢复前是不能接受请求的。
16 如何保证数据不丢失?
flume 那边采用的 channel 是将数据落地到磁盘中, 保证数据源端安全性;
sparkStreaming 通过拉模式整合的时候, 使用了 FlumeUtils 这样一个类,该类是需要依赖一个额外的 jar 包( spark-streaming-flume_2.10)
要想保证数据不丢失, 数据的准确性, 可以在构建 StreamingConext 的时候, 利用 StreamingContext.getOrCreate( checkpoint, creatingFunc:() => StreamingContext) 来创建一个 StreamingContext
传入的第一个参数是 checkpoint 的存放目录, 第二参数是生成StreamingContext 对象的用户自定义函数。
如果 checkpoint 的存放目录存在, 则从这个目录中生成 StreamingContext 对象; 如果不存在, 才会调用第二个函数来生成新的 StreamingContext 对象。 在 creatingFunc函数中, 除了生成一个新的 StreamingContext 操作, 还需要完成各种操作,然后调用ssc.checkpoint(checkpointDirectory)来初始化checkpoint 功能, 最后再返回StreamingContext 对象。这样, 在StreamingContext.getOrCreate 之后, 就可以直接调用 start()函数来启动( 或者是从中断点继续运行) 流式应用了。如果有其他在启动或继续运行都要做的工作, 可以在 start()调用前执行。








![[附源码]Node.js计算机毕业设计出版社样书申请管理系统Express](https://img-blog.csdnimg.cn/b2c20e3b49834374bc52d22ec65035ee.png)