任少斌
上一期:推荐系统(一)简要介绍
用户提供信息
正所谓“知己知彼,百战不殆”,为了让推荐系统更符合用户的偏好,我们需要深入了解用户的行为特征。如果有用户在注册的时候能够描述个人的偏好,则是更好的,目前很多APP也确实是这么做的,比如新浪微博在注册的时候会让用户选择喜欢的话题或者明星。
但是我们必须意识到
· 用户提供的信息未必是准确的、全面的,比如用户不太清楚自己的偏好、用户在注册的时候随便乱填、用户的偏好很多,不能被问卷完全表示。
· 用户的偏好会发生变化,有些偏好会随着时间消失而有些会生成。
典型的利用用户行为数据进行推荐的例子就是各大排行榜,这在互联网出现之前已经得到了广泛的应用也取得了较好的结果。

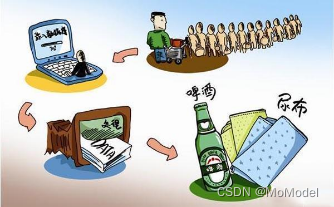
“啤酒和尿布”是数据挖掘的经典案例,在我们购物的时候,会生成一个购物车也被称为购物篮子,包含一次购物的所有商品,商家发现很多购物篮子里啤酒和尿布一同出现,就将两个商品的货架放到一起,使得两种商品的销售量均有提升。
(啤酒和尿布的数据挖掘可以用到Apriori算法,是一种关联规则挖掘算法,之后我们也许会介绍)
用户行为数据简介
用户行为在个性化推荐系统中一般分为两种——显性反馈行为和隐形反馈行为。显性反馈行为包括用户明确表示对物品偏好的行为,比如“喜欢”与“不喜欢”,评分从1-5来评判视频,但是人们在观看视频的时候往往只会给出5分或者1分,在之后就采用“喜欢”或者“不喜欢”的评分标准了,这个在bilibili中相当于“顶”和“踩”。
隐式反馈是指不能明确反应用户喜欢的行为,比如页面浏览、与物品发生交互的记录(比如听歌、阅读)。用户浏览一个物品并不能说明其偏好,不过要好于根本没有记录的物品。隐式反馈的数据往往是很庞大的,在通常情况下可以表明用户对于物品是偏好的。

用户行为分析
用户活跃度与物品流行度的分布
互联网的数据常常会表现出长尾分布的样子。
令fu(k)为对k个物品产生过行为的用户数,令fi(k)为被k个用户产生过行为的物品数。那么fu(k)和fi(k)均服从长尾分布。即
这是自然的,大家可以思考原理、自行验证。
用户活跃度与物品流行度的关系
通常来说,新用户会倾向于浏览热门的物品,而老用户会逐渐开始浏览冷门的物品。因为在刚接触时用户并不熟悉,会点击首页的热门物品,而老用户已经浏览过这些热门物品,开始着手于不那么热门的物品。
结尾
本次我们介绍了用户的行为数据,这对于实际问题的理解有很大的帮助,下一期会介绍协同过滤算法,虽然是老话题了但还是期待大家的阅读与分享。
关于我们
Mo(网址:http://www.zhihu.com/momodel.cn?src=9d29c23d0e)
是一个支持 Python的人工智能在线建模平台,能帮助你快速开发、训练并部署模型。
近期 Mo 也在持续进行机器学习相关的入门课程和论文分享活动,欢迎大家关注我们的公众号:MomodelAI 获取新资讯!