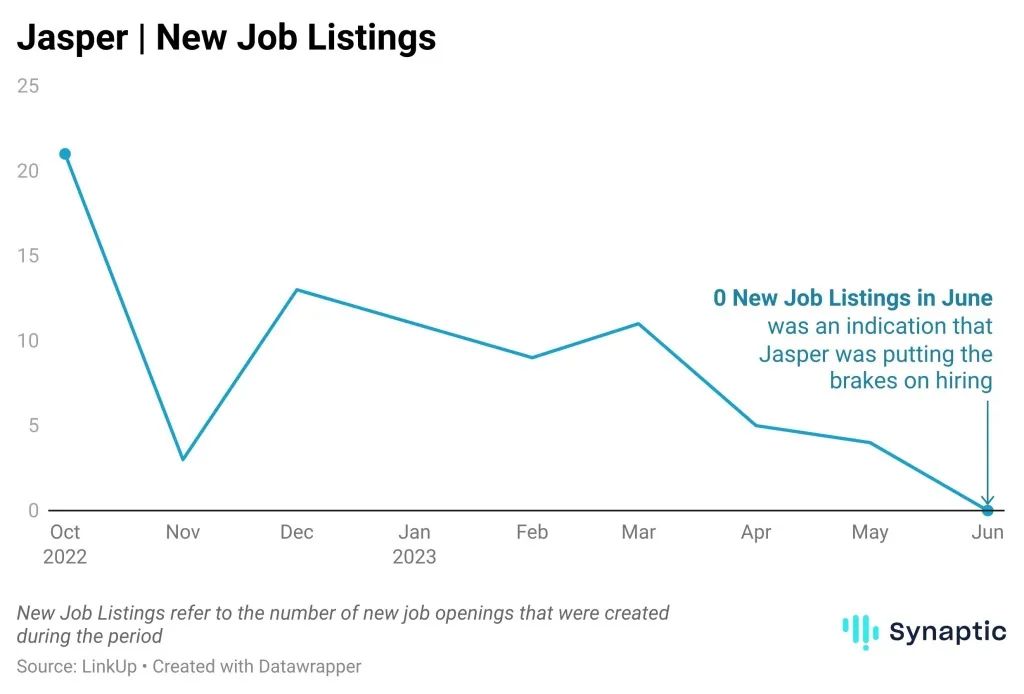
1. 解决了什么问题?
实时的目标检测器是计算机视觉系统的重要组成部分。目前应用在 CPU 端的实时目标检测方法大多基于 MobileNet、ShuffleNet、GhostNet,而用在 GPU 的实时目标检测方法大多基于 ResNet、DarkNet、DLA,然后使用 CSPNet 策略来优化网络架构。本文方法主要侧重于优化训练的过程,而非模型架构。这些优化方法会增加一定的训练成本,提升检测的表现,但不会增加推理成本。
要想优化目标检测器,可以从下面几个方向入手:
- 更快、更强的网络架构;
- 更有效的特征融合方法;
- 更准确的检测方法;
- 更鲁棒的损失函数;
- 更高效的标签分配方法;
- 更有效的训练方法。
本文没有尝试自监督学习或知识蒸馏方法,它们需要更多的训练数据或更大的模型。
模型重参数化、动态标签分配开始在目标检测领域流行起来。对于模型重参数化,如何将重参数化模块替换原来的模块,作者尝试将模型重参数化技术应用到不同网络的层。关于如何分配动态目标给不同分支的输出,作者提出了 coarse-to-fine lead guided 标签分配方法。
模型缩放将模型缩小或放大,以匹配不同的计算设备。模型缩放系数一般包括输入图像的分辨率、网络深度(层数)、网络宽度(通道数)、特征金字塔个数、从而平衡网络的参数量、计算量、推理速度和准确率。本文发现,几乎所有的方法都是独立地研究各缩放系数的,因为在这些方法中,缩放系数之间关系并不紧密。而基于 concat 的模型,如 DenseNet 和 VoVNet,当它们的网络深度变化时,某些层的输入宽度也会相应变化,于是作者提出了新的混合缩放策略。
2. 提出了什么方法?
2.1 架构
2.1.1 Extended efficient layer aggregation networks
在设计高效网络架构时,主要考量因素无非是参数量、计算量和计算密度。ShuffleNet 分析了输入/输出通道比、网络分支的个数、element-wise 操作的影响。
下图b 的 CSPVoVNet 是 VoVNet 的变体,它分析了梯度路径,让不同层的权重学习更改多样的特征,从而让推理更快速、准确。下图c 的 ELAN 则通过控制 the shortest longest gradient path,网络能更加高效地收敛。于是作者提出了下图d 的 E-ELAN,它不会改变原结构的梯度传递路径,使用分组卷积来增加特征的 cardinality,以 shuffle 和 merge cardinality 的方式将不同分组的特征结合,从而增强不同特征图学到的特征,提升参数与计算利用效率。

ELAN 已达到一个稳定状态,如果无限地码放计算模块,稳定性会被破坏,参数利用率会降低。E-ELAN 利用 expand、shuffle 和 merge cardinality,不断增强网络的学习能力,不会破坏原有的梯度路径。E-ELAN 只改变计算模块的结构,转换层的结构完全没变。本文的策略是用分组卷积来扩大通道数和计算模块的 cardinality。对所有的计算模块使用相同的分组参数和通道乘数,然后每个计算模块的特征图会被 shuffle 为 g g g组,然后再 concat 到一起。每个特征图分组的通道数与原结构的通道数一样。最后,将 g g g组特征图融合起来。E-ELAN 不仅维持了 ELAN 的设计,也指导不同的计算模块分组学习更多样的特征。
2.1.2 Model scaling for concatenation-based models
模型缩放通过调整模型的一些性质,产生不同大小的模型,从而满足不同的推理速度要求。比如 EfficientNet 对模型的宽度、深度和图像分辨率做缩放。这些缩放方法主要应用在 ResNet 或 PlainNet,每层的 in-degrees 和 out-degrees 不变,因此可以单独地分析各缩放因素对参数量和计算量的影响。但对于 concat-based 架构,如下图 a 和 b,对深度做缩放会改变转换层(在 concat-based 计算模块后)的 in-degree。
对于 concat-based 模型,我们不能单独地分析各缩放系数。增大模型的深度会增大计算模块的输出宽度,转换层输入通道和输出通道比值的变化会降低硬件利用效率。如下图 c,当我们缩放 concat-based 模型的深度系数时,只缩放计算模块的深度系数,对其余的转换层只缩放相应的宽度系数。这种混合缩放方法能够保持模型的初始设计及最佳结构。

2.2 Trainable bag-of-freebies
2.2.1 Planned re-parameterized convolution
直接将 RepConv 应用到 ResNet 或 DenseNet 等结构,会造成准确率大幅下降。作者使用梯度流传播路径来分析如何在不同的网络中重参数化卷积。
RepConv 将
3
×
3
3\times 3
3×3卷积、
1
×
1
1\times 1
1×1卷积和恒等连接转换为一个卷积层。作者分析了 RepConv 和不同的网络结构组合的表现,发现 RepConv 里面的恒等连接会破坏 ResNet 的残差和 DenseNet 的 concat,它们原本能提供更丰富的梯度。因此作者使用的 RepConv 不带恒等连接,即 RepConvN。当我们重参数化一个带残差或 concat 操作的卷积层时,不应使用恒等连接。

2.2.2 Coarse for auxiliary and fine for lead loss
深度监督是给网络的中间层添加一个额外的辅助 head,用辅助损失指导浅层网络的权重。深度监督能大幅提高模型的表现。本文将负责网络最终输出的 head 叫 lead head,辅助训练的 head 叫 auxiliary head。
以前的标签分配方法直接用 ground-truths 根据一定的规则生成硬标签。后来,人们使用网络预测结果的质量和分布,结合 ground-truths 来生成一个可靠的软标签。比如,YOLO 使用边框回归预测与 ground-truths 的 IoU 作为 objectness 的软标签。
作者发现一个问题,如何给 auxiliary head 和 lead head 分配软标签。下图 c 是目前最流行的办法,将 auxiliary head 和 lead head 分开考虑,使用各自的预测结果和 ground-truths 完成标签分配。如下图 d 和 e,本文提出的方法则使用 lead head 的预测结果来指导 auxiliary head 和 lead head。用 lead head 的预测作为指导,生成 coarse-to-fine 的标签,分别用于 auxiliary head 和 lead head 的学习。

Lead head guided label assigner 基于 lead head 的预测结果和 ground-truths 来计算软标签。Lead head 有着更强的学习能力,所以它生成的软标签更能体现源数据和目标之间的关系。我们可以将该学习看作泛化残差学习,让浅层 auxiliary head 直接学习 lead head 学到的信息,lead head 就能更关注于尚未学到的残差信息。这些软标签会作为目标来训练 auxiliary head 和 lead head。
Coarse-to-fine lead head guided label assigner 也用 lead head 的预测结果与 ground-truths 来生成软标签。但在这个过程中会产生两类软标签,粗粒度标签和细粒度标签。细粒度标签与 lead head guided label assigner 的软标签是一样的,但粗粒度标签则是放宽正样本分配的约束条件,将更多的网格作为潜在目标对待。这么做是因为 auxiliary head 的学习能力不强,为了防止模型漏掉应该学到的信息,就只关注于 auxiliary head 的召回。最后从召回率高的结果中筛选出精度高的作为 lead head 的最终输出。为了降低粗粒度正网格的影响,在 decoder 中作者加入了一些约束,于是这些粗粒度正网格就无法完美地输出软标签,该机制动态地调节细粒度标签和粗粒度标签的重要程度,让细粒度标签的优化上界始终高于粗粒度标签。
2.2.3 其他训练技巧
- Batch Norm:BN 层直接连接到卷积层,推理时将 BN 的均值和方差整合到卷积层的权重和偏置。
- 在 YOLOR 中以相加或相乘的方式,在卷积特征图内融入隐含知识:YOLOR 的隐含知识可以简化为一个向量,在推理阶段提前计算好。该向量可以结合到卷积层里面。
- EMA 模型:将 EMA 模型作为最终的推理模型。