目录
UTF-8 字符串编解码
解决方法
解析
utf8_to_b64
b64_to_utf8
弃用 unescape 和 escape 方法
原由
解决方法
Node.js 下的 Base64 编解码
Base64 编解码
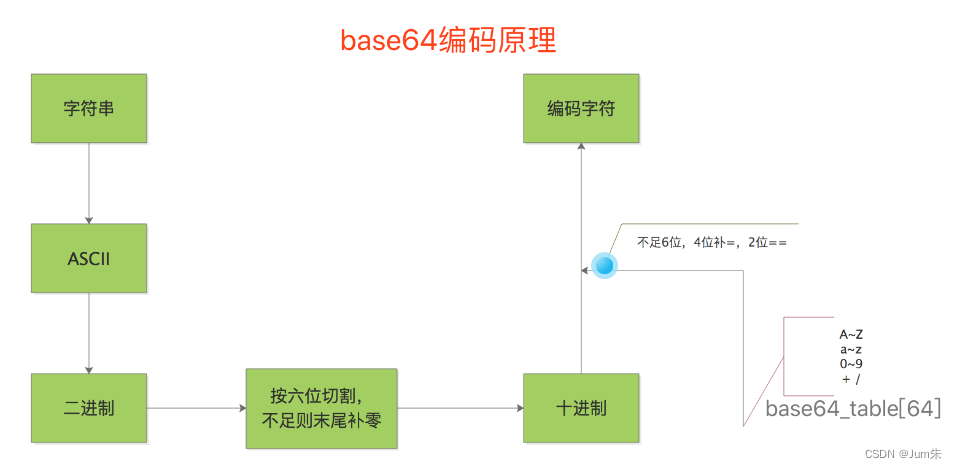
Base64是一种使用64基的位置计数法。它使用2的最大次方来代表仅可打印的ASCII 字符。这使它可用来作为电子邮件的传输编码。在Base64中的变量使用字符A-Z、a-z和0-9 ,这样共有62个字符,用来作为开始的64个数字,最后两个用来作为数字的符号在不同的系统中而不同。一些如uuencode的其他编码方法,和之后binhex的版本使用不同的64字符集来代表6个二进制数字,但是它们不叫Base64。
其实在 JavaScript 中,原生就有两个函数被分别用来处理解码和编码 base64 字符串:
btoa(): 从二进制数据的 “字符串” 创建一个 Base64 编码的 ASCII 字符串(“btoa” 其实是 “二进制转 ASCII” 的意思)。atob(): 解码 Base64 编码的字符串(“atob” 其实是 “ASCII 到二进制” 的意思)。
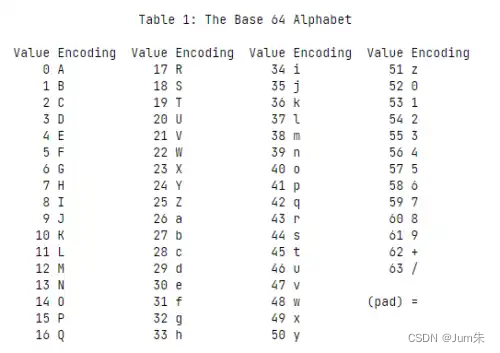
可以通过 window.atob(string)、window.btoa(base64string) 的方式调用,非常方便。
UTF-8 字符串编解码
UTF-8(8位元,Universal Character Set/Unicode Transformation Format)是针对Unicode的一种可变长度字符编码。它可以用来表示Unicode标准中的任何字符,而且其编码中的第一个字节仍与ASCII相容,使得原来处理ASCII字符的软件无须或只进行少部分修改后,便可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。

如上面的描述所言,btoa 和 atob 都只支持 ASCII 字符,并不支持 Unicode 字符。在大多数浏览器中对 Unicode 字符串调用将会报 Character Out Of Range 错误,因为字符超出了 ASCII 的范围。
解决方法
我们可以将字符串转义过后再进行编码,解码时将解码结果重新转义为 Unicode 字符串。
function utf8_to_b64(str) {
return btoa(unescape(encodeURIComponent(str)));
}
function b64_to_utf8(str) {
return decodeURIComponent(escape(atob(str)));
}
// 用例:
utf8_to_b64("测试"); // "5rWL6K+V"
b64_to_utf8("5rWL6K+V"); // "测试"解析
这中间看起来比较神奇,发生了个什么事呢?
主要呢就是利用了 encodeURIComponent、decodeURIComponent 会把接受到的字符串参数当作 UTF-8 字符串来进行处理。
utf8_to_b64
先看 utf8_to_b64 方法。
这里由于 encodeURIComponent 方法接受的是 UTF-8 字符串,可以先用 encodeURIComponent 方法将 UTF-8 字符串转成了形如 %XX%XX 的十六进制符号。然后使用 unescape 方法将十六进制翻译为了 ASCII 中对应的内容,这样就变成了 btoa 方法能够接受的 ASCII 字符串。最后直接使用 btoa 方法编码为 Base64 字符串。
encodeURIComponent("测试"); // "%E6%B5%8B%E8%AF%95"
unescape("%E6%B5%8B%E8%AF%95"); // "æµ\x8Bè¯\x95"
btoa("æµ\x8Bè¯\x95"); // "5rWL6K+V"总的来说就是一个将 UTF-8 字符串转为 ASCII 字符串再编码的一个过程。
b64_to_utf8
再看 b64_to_utf8 方法。
其实就是反过来,先将 Base64 字符串通过 atob 方法解码为 ASCII 字符串,然后通过 escape 方法将 ASCII 字符串转为十六进制符号,最后将十六进制符号通过 decodeURIComponent 方法解析为 UTF-8。
atob("5rWL6K+V"); // "æµ\x8Bè¯\x95"
escape("æµ\x8Bè¯\x95"); // "%E6%B5%8B%E8%AF%95"
decodeURIComponent("%E6%B5%8B%E8%AF%95"); // "测试"弃用 unescape 和 escape 方法
原由
该特性已经从 Web 标准中删除,虽然一些浏览器目前仍然支持它,但也许会在未来的某个时间停止支持,请尽量不要使用该特性。
可以看到 unescape 和 escape 方法已经被标记为废弃,并推荐使用 decodeURI 或 decodeURIComponent 替代 unescape,推荐使用 encodeURI 或 encodeURIComponent 替代 escape。
根据百分号编码 - 维基百科中的内容可以知道,escape 在处理 0xff 之外字符的时候,是直接使用字符的 unicode 在前面加上一个 「% u」,而 encodeURI 则是先进行 UTF-8,再在 UTF-8 的每个字节码前加上一个 「%」
2005 年 1 月发布的 RFC 3986,建议所有新的 URI 必须对未保留字符不加以百分号编码;其它字符建议先转换为 UTF-8 字节序列,然后对其字节值使用百分号编码。此前的 URI 不受此标准的影响。
有一些不符合标准的把 Unicode 字符在 URI 中表示为:%uxxxx, 其中 xxxx 是用 4 个十六进制数字表示的 Unicode 的码位值。任何 RFC 都没有这样的字符表示方法,并且已经被 W3C 拒绝 (页面存档备份,存于互联网档案馆)。第三版的 ECMA-262 仍然包含函数escape(string)使用这种语法,但也有函数encodeURI(uri)转换字符到 UTF-8 字节序列并用百分号编码每个字节。
所以 escape 是对百分号编码的非标准实现,所以被废弃实属正常。
解决方法
虽说 escape 是对百分号编码的非标准实现,但是在上面的方法中我们实际上利用了 escape 的这种特性,这边提供了不使用 unescape 和 escape 方法后的实现。
function utf8_to_b64(str) {
return btoa(
encodeURIComponent(str).replace(/%([0-9A-F]{2})/g, function (match, p1) {
return String.fromCharCode("0x" + p1);
})
);
}
function b64_to_utf8(str) {
return decodeURIComponent(
atob(str)
.split("")
.map(function (c) {
return "%" + ("00" + c.charCodeAt(0).toString(16)).slice(-2);
})
.join("")
);
}
// 用例:
utf8_to_b64("测试"); // "5rWL6K+V"
b64_to_utf8("5rWL6K+V"); // "测试"Node.js 下的 Base64 编解码
在 Node.js 中使用上面的方法,你可能会发现,btoa 和 atob 方法,由于只支持 ASCII 方法也已经被标记为废弃了,那么在 Node.js 中用什么方法呢?
Node.js 中提供了一个更加简便的方法,那就是利用 Buffer,除了支持字符串,也支持其他数据。
function utf8_to_b64(str) {
return Buffer.from(str).toString("base64");
}
function b64_to_utf8(str) {
return Buffer.from(str, "base64").toString("utf8");
}