Text Detect Metric
![]()
![]()

![]()
- 该库用于计算
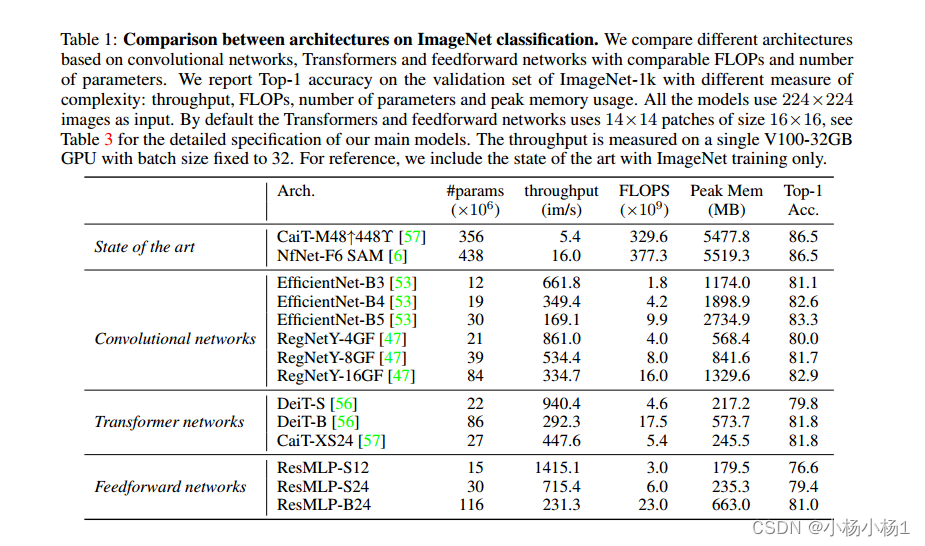
Precision、Recall和H-mean三个指标,用来评测文本检测算法效果。与魔搭-文本检测测试集配套使用。 - 指标计算代码参考:PaddleOCR 和 DB
整体框架
数据集上评测
- 如果想要评测其他文本检测算法,需要将预测结果写入
pre.txt中,格式为图像全路径\t检测框多边形坐标\t得分- ⚠️注意:图形全路径来自modelscope加载得到,只要保证
txt和json在同一目录下即可。 - 如下示例:
C:\Users\xxxx\.cache\modelscope\hub\datasets\liekkas\text_det_test_dataset\master\data_files\extracted\f3ca4a17a478c1d798db96b03a5da8b144f13054fd06401e5a113a7ca4953491\text_det_test_dataset/25.jpg [[[519.0, 634.0], [765.0, 632.0], [765.0, 683.0], [519.0, 685.0]]] [0.8451064699863124]
- ⚠️注意:图形全路径来自modelscope加载得到,只要保证
- 这里以
ch_mobile_v2_det在文本检测测试集liekkas/text_det_test_dataset上的评测代码,大家可以以此类推。 - 安装必要的包
pip install modelscope==1.5.2 pip install text_det_metric - 运行测试
- 运行
get_pred_txt.py得到pred.txtimport cv2 from modelscope.msdatasets import MsDataset from ch_mobile_v2_det import TextDetector test_data = MsDataset.load( "text_det_test_dataset", namespace="liekkas", subset_name="default", split="test", ) text_detector = TextDetector() content = [] for one_data in test_data: img_path = one_data.get("image:FILE") print(img_path) img = cv2.imread(str(img_path)) dt_boxes, scores, _ = text_detector(img) content.append(f"{img_path}\t{dt_boxes.tolist()}\t{scores}") with open("pred.txt", "w", encoding="utf-8") as f: for v in content: f.write(f"{v}\n") - 运行
compute_metric.py得到在该数据集上的指标from text_det_metric import DetectionIoUEvaluator metric = DetectionIoUEvaluator() # pred_path pred_path = "1.txt" mertric = metric(pred_path) print(mertric) # {'precision': 0.6926406926406926, 'recall': 0.8247422680412371, 'hmean': 0.7529411764705882}
- 运行