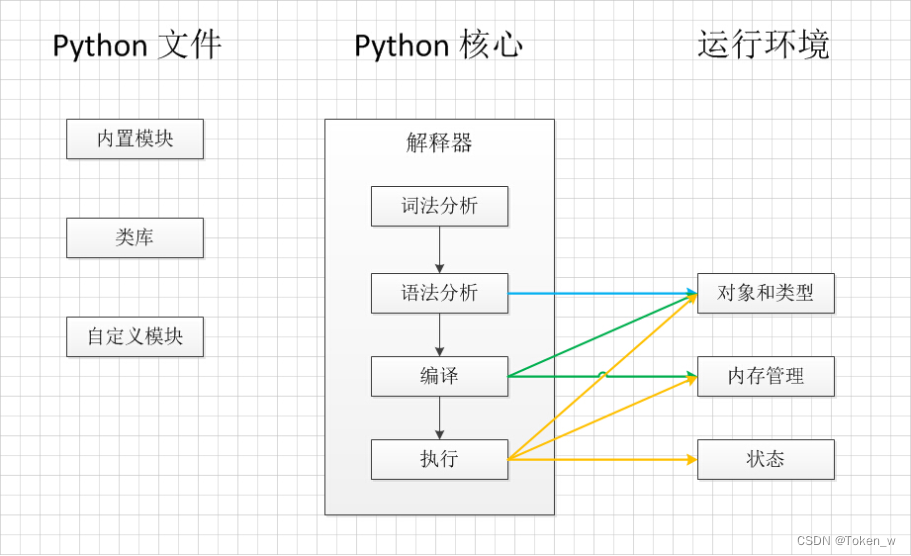

👉导读
一个有所追求的程序员一定都希望自己能够写出高质量的代码,但高质量代码从何而来呢?有人认为是设计出来的,就像一栋稳固的大厦,如果没有前期优秀的设计那么肯定难逃豆腐渣工程的命运;也有人认为是重构出来的,软件的一个基本特性就是易变,随着时间的推移软件会不断腐化,因此需要不断重构来保持代码的高质量。哪种说法更有道理?今天就跟大家聊一聊重构、设计与高质量代码的关系。欢迎阅读。
👉目录
1 从一个案例说起
1.1 混乱
1.2 秩序
2 代码质量
2.1 编写易于理解(可读)的代码
2.2 避免意外
2.3 编码难以被误用的代码
2.4 实现代码模块化
2.5 编写可重用可推广的代码
2.6 编写可测试的代码并适当测试
2.7 小结
3 编程范式、设计原则和设计模式
3.1 编程范式
3.2 设计原则
3.3 设计模式
4 技术债、代码坏味道和重构
4.1 技术债
4.2 代码坏味道
4.3 重构
5 总结
01
从一个案例说起
故事还得从一个性能优化的经历说起,信息流业务中经常需要展示图片,如果图片的体积过大则会导致性能问题,体积过小用户看得模糊体验又不好,因此需要一个适中的图片体积。得益于腾讯强大的基建,业务方不需要自己对图片进行处理,而只需要修改图片链接的参数即可调整图片的裁剪和压缩尺寸。
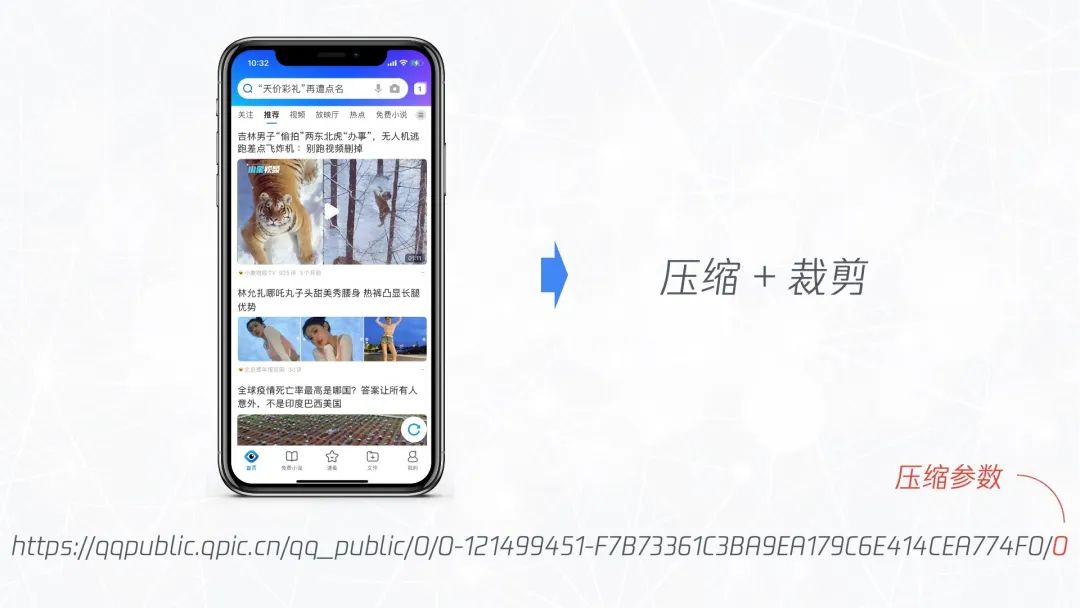
这里需要知道的是,我写了一个图片优化工具用来将代表原图的图片链接修改为合适的图片链接。举个例子,下图中上面的链接是原图链接,所谓原图就是用户上传的没有经过处理的图片。原图经过处理后就得到下面新的图片链接,新链接与原图链接的区别就是加了两个参数,分别代表裁剪的比例和压缩的尺寸。
接下来的问题就是,这个“图片优化工具”的代码如何去写。
1.1 混乱

梳理一下业务逻辑,完成原图链接到最佳链接的步骤可以划分为 3 个:
|
既然逻辑已然清晰,代码也不难写。目光所及的伪代码已经充斥了 if else 的条件分支,看似简单的一段代码实则弯弯绕绕。
if (必要参数是否填写) {
if (指定域名 && 符合裁剪规则) { // 计算最优裁剪比例 }
if (指定域名 && 符合压缩规则) { // 计算最优压缩规则 }
if (指定域名) { // 计算新图链接 }
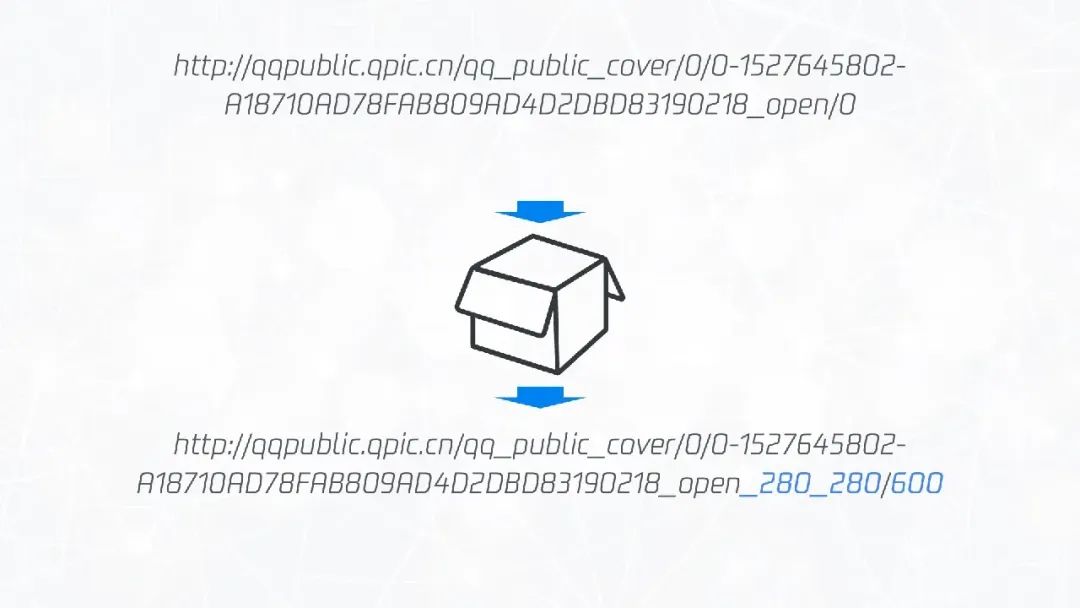
}这还没完,突然产品经理说:“再支持两个新域名”。由于一些历史原因,司内存在不少相似的服务,但能力都大同小异,都是通过改变链接中的参数来修改图片的裁剪和压缩尺寸。比如下图所示,有的域名同时支持裁剪和压缩,但需要直接修改路径;有的域名不支持裁剪,参数也是通过 query 形式传入。因此我们需要针对不同域名进行不同判断。

兵来将挡水来土掩,来个新需求就改代码嘛,这似乎已经成了惯例。在这个业务场景里,就是用 if else 来判断一下不同域名,然后再各自处理。
if (A 域名) {
// 计算 A 域名最佳链接
} else if (B 域名) {
// 计算 B 域名最佳链接
} else if (...) {
...
}这里不得不提一个与软件质量息息相关的指标:圈复杂度。根据维基百科的定义,“圈复杂度是一种软件度量,用来表示程序的复杂度,循环复杂度由程序的源代码中量测线性独立路径的个数”。处理单个域名的逻辑已经超过了 10 个圈复杂度,每加一个新域名,圈复杂度就会线性增加 10,那可想而知,再增加几个新域名,这段逻辑的复杂程度可就高到难以理解了。因此,对这段代码重构迫在眉睫。
1.2 秩序
程序的大部分威力来源于条件逻辑,但是非常不幸的是,程序的复杂度也往往来源于条件逻辑。从刚刚的例子中可以看出,如果不加以控制,我们的代码里很快就充斥了 if else,因此我们需要简化条件逻辑。《重构》这本书中提供了 6 种建议。
|
我们看看哪些建议可以用得上。
1.2.1 重构方式 1:分解条件表达式
所谓分解条件表达式就是将一个巨大的逻辑代码块分解为一个个独立的函数,每个函数的命名能够表达其意图,就像例子中这么一改造,代码就可以更加突出条件逻辑,每个分支的作用也更加清晰。

1.2.2 重构方式 2:以多态取代条件表达式
仅仅做了分解条件表达式就够了吗,肯定不够。因为这样的代码在结构上还不够清晰,实际上我们可以将不同的条件逻辑分拆到不同的场景中去,利用多态将逻辑拆分得更加清晰。
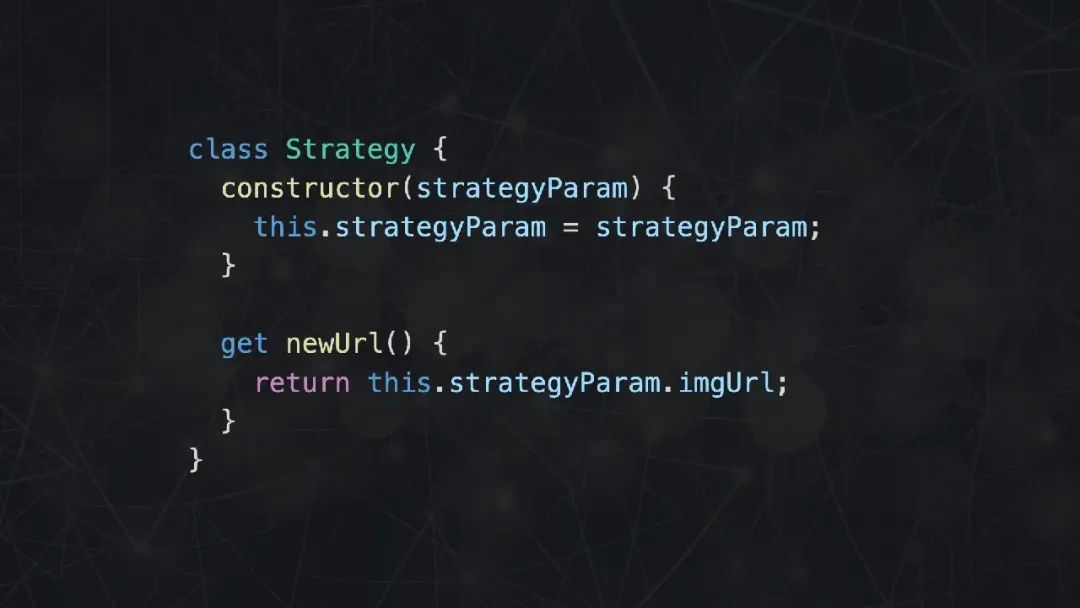
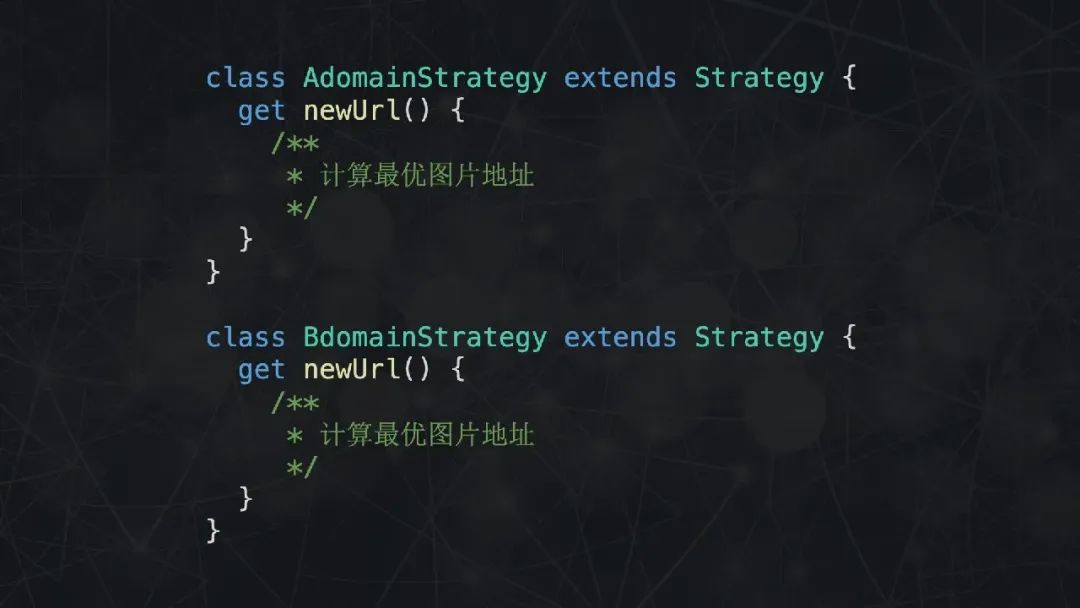
首先声明一个 Strategy 基类,在构造函数中传入必要的参数,提供一个 getter 函数,用于计算最佳图片链接。每当有新的域名需要处理,就声明一个类继承 Strategy 基类。就这样,利用了多态的代码在逻辑上显得更为清晰。
1.2.3 重构方式 3:策略模式
《设计模式》这本书提到:“组合优于继承”。我们再细细分析上面这段包含多态的代码,就会发现 AdomainStrategy 与 Stragtegy 之间并不天然存在继承关系,而且继承会增加系统耦合,而组合可以更好地实现运行时的灵活性。那我们可以用策略模式进一步重构这段代码。
所谓“策略模式”,就是“定义一系列的算法,把它们一个个封装起来,并且使它们可以相互替换”。
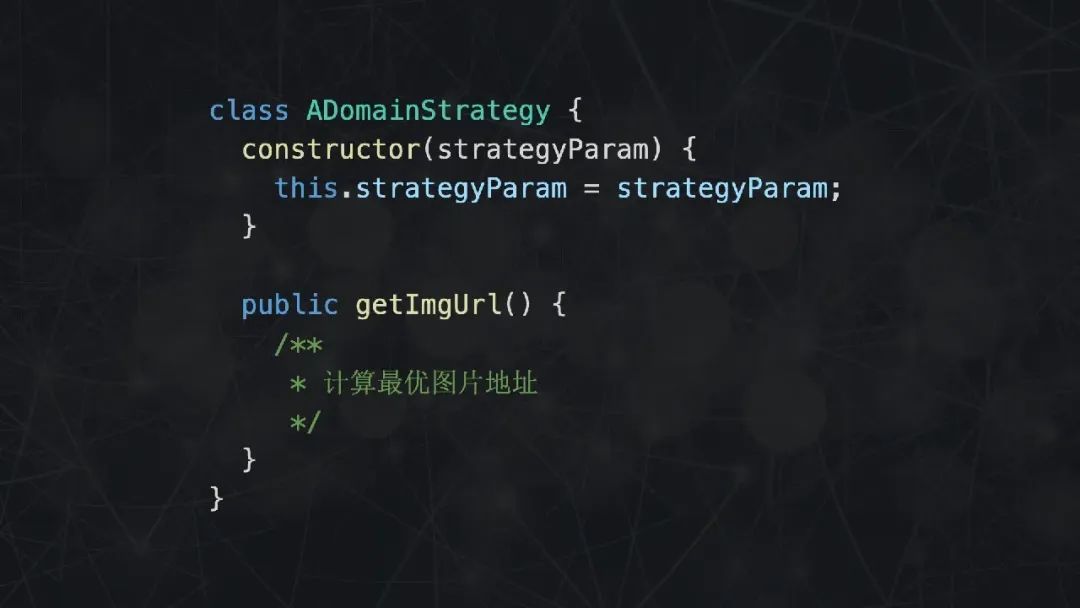
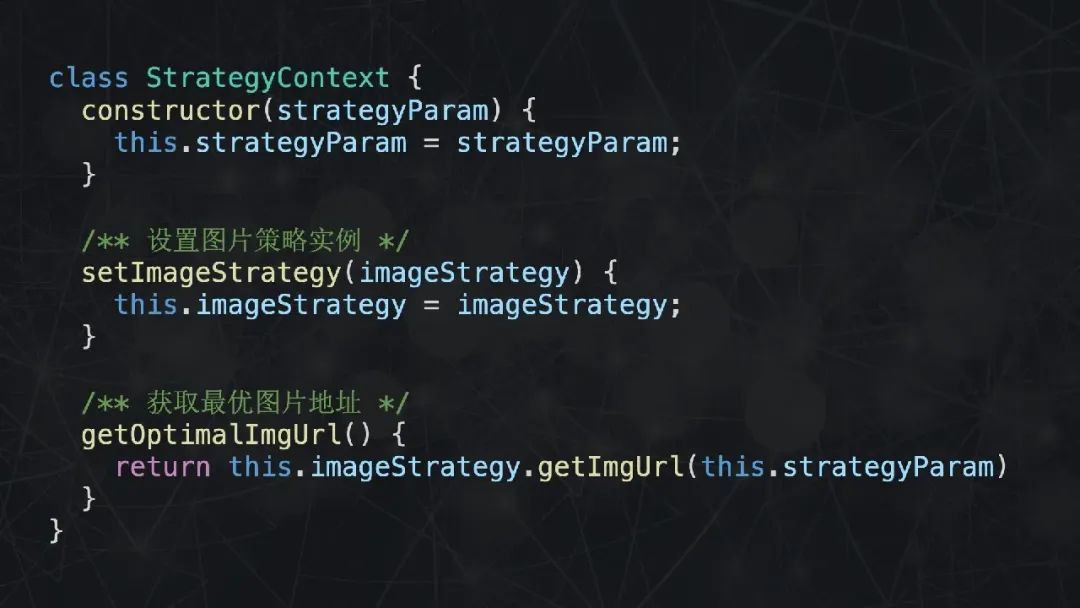
每个具体的策略类通过构造函数传入所需的参数,提供一个名为 getImgUrl 的公共方法。而在策略上下文类中,设置具体的策略以及提供获取最优图片地址的方法。
1.2.4 重构方式 4:模版方法模式
进一步分析,发现无论是 A 域名还是 B 域名,或者是其他任何域名,处理逻辑具有相同部分,即“计算裁剪比例” -> “计算压缩规格” -> “拼接新的链接” -> “返回新的链接”。

写高质量代码时应该要警惕重复代码,这里也不例外,我们可以使用“模版方法模式”来进一步重构,所谓“模板方法模式”,就是“在模板方法模式中,子类实现中的相同部分被上移到父类中,而将不同的部分留待子类来实现”。落实到代码中就是,声明一个抽象类,将公共的逻辑都抽到该抽象类中,然后在子类中再实现具体的业务逻辑。
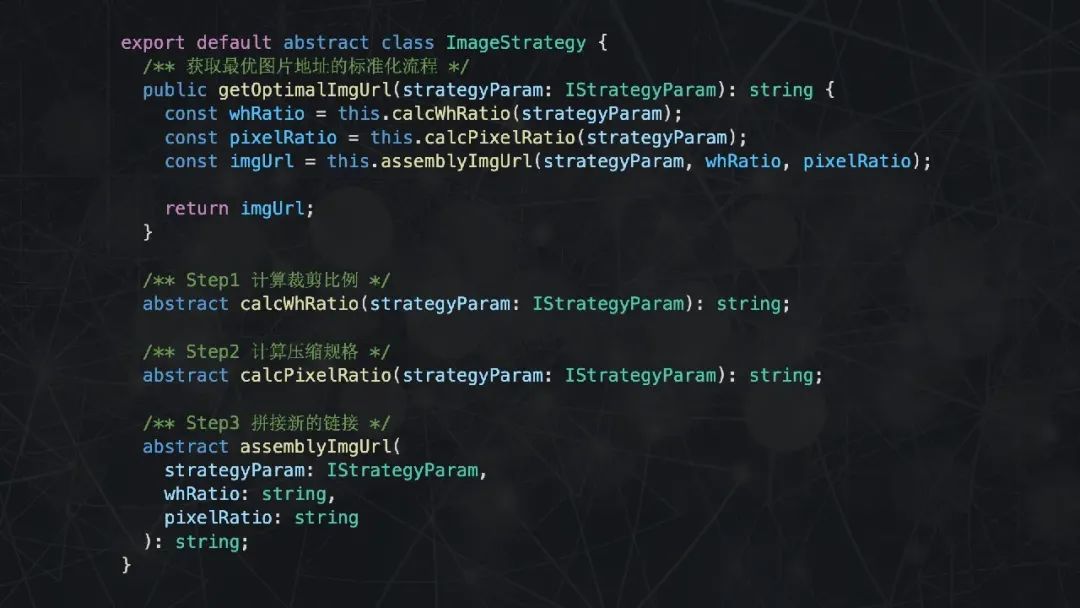
1.2.5 小结
这是一段不算复杂的逻辑,但如何放任不管,代码则会越来越复杂,直至无法维护。因此,我们对这段代码进行了多轮重构,从一开始分解条件表达式,到采用多态使得代码在结构上更为清晰,进一步地采用了策略模式和模板方法模式,不断提升了代码质量。
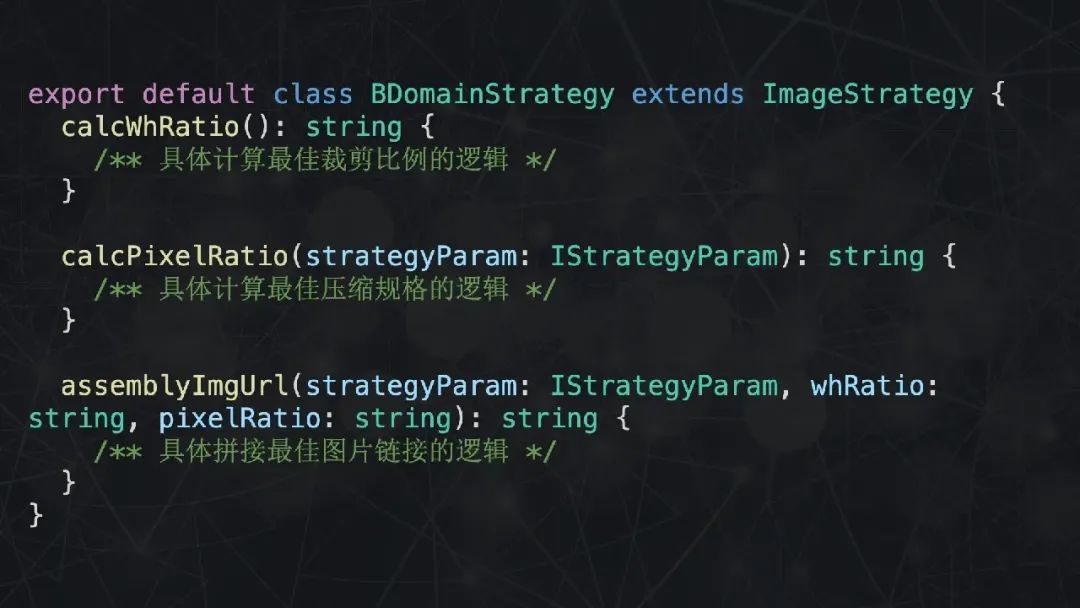
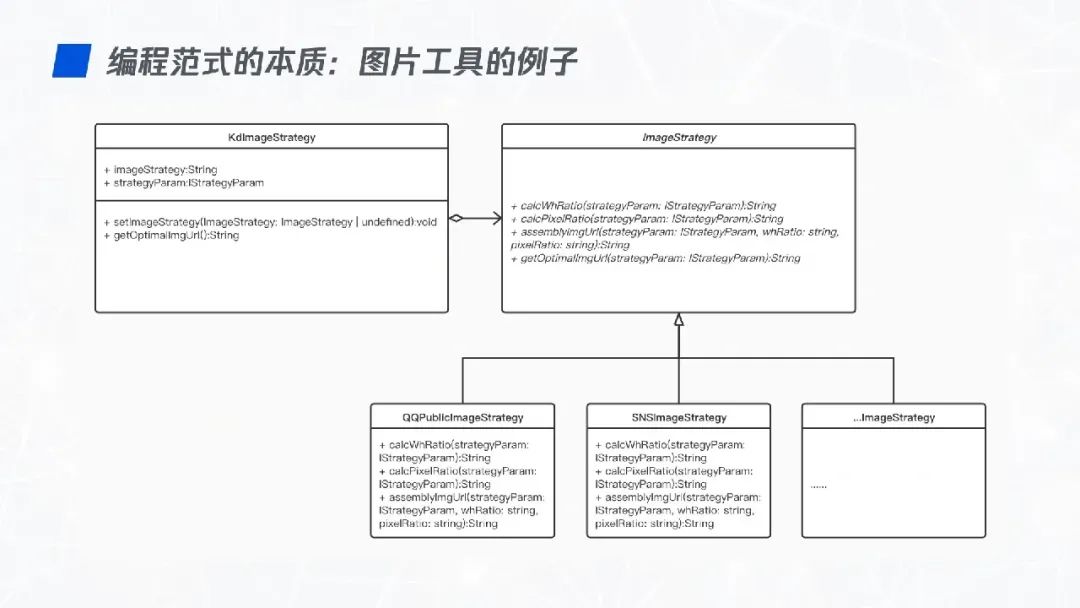
那现在如果再遇到产品经理说再支持两个新域名,那就非常简单了。只需要继承 ImageStrategy,然后依次实现业务相关的 3 个方法就可以了。
02
代码质量
前面我们花了很大的篇幅介绍了图片优化工具是如何一步步重构的,你可能对高质量代码有了一些感觉,但什么是代码质量,当我们在谈论代码质量时到底在谈论什么呢?下面我们就将这一概念变得更加明晰。
《好代码,坏代码》这本书提出,编写的代码应该满足 4 个高层目标:
|
虽然我们知道了高质量代码的目标,但仅仅知道目标也没有办法下手,我们还需要更加具体的策略。为什么很多人讨厌鸡汤,就是因为那些人只给了鸡汤而不给勺子,我们这里既给目标也给具体的策略。这就是代码质量的六大支柱。接下来我会结合前面所讲的例子分别介绍这六大代码质量的支柱。需要注意的是,每个支柱代表了一种原则,而实现这个原则可以有很多具体的措施。

2.1 编写易于理解(可读)的代码
编写易于理解的代码是代码质量六大支柱的第一个支柱,我们举 3 个不同的例子来看看如何实现该支柱的思想。
2.1.1 使用描述性名称
前面策略上下文类中,“获取最佳图片地址”的方法名称是 getOptimalImgUrl,从这个名称中可以一眼看出其含义。但如果改成 getU 或者 getUrl 或者 calcU,相信你肯定得愣几秒甚至半天都可能猜不出什么含义,那这样的代码显然不易于理解。
2.1.2 适当使用注释
注释往往可以帮助我们更好地理解代码,但是不是所有注释都是好的呢?我们可以看下面这段代码的注释,里面包含两段注释,一个是描述方法的用途,另一个是描述具体的实现。第二个注释就是个糟糕的注释,因为工程师在代码维护时不得不维护这个注释,如若更新了实现方式,则需要记得更改注释。同时,如果 100 行代码中有 50 行像这样的无效注释,那么反而增加阅读代码的难度。
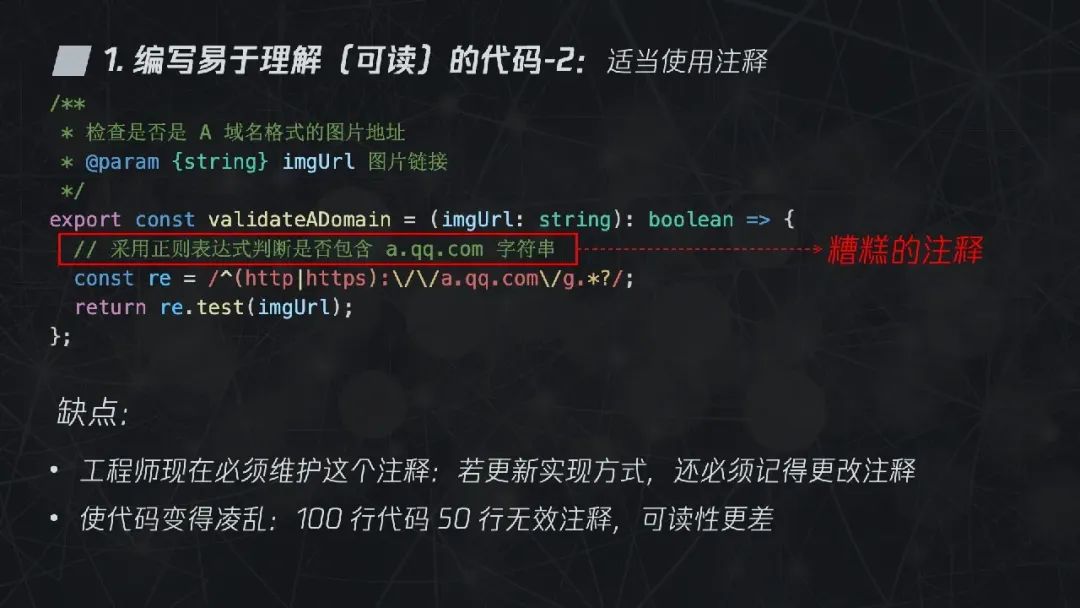
那么该如何正确地使用注释呢?可以用注释说明以下内容:
|
2.1.3 坚持一致的编程风格
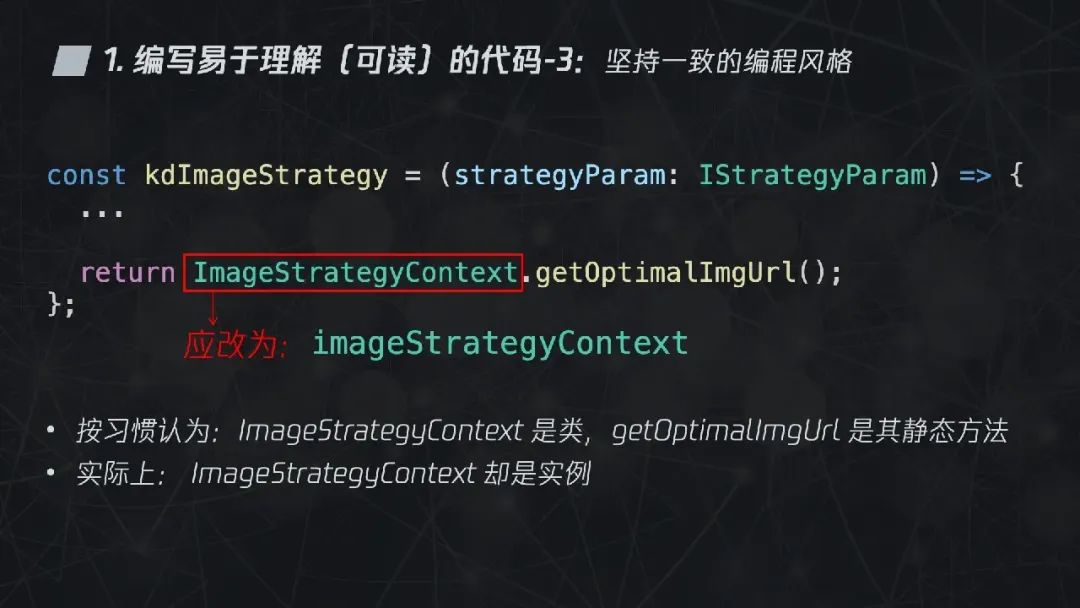
按照我们的习惯,可能会认为 ImageStrategyContext 是类,getOptimalImgUrl 是其静态方法。出现这样的误会的原因就是写错了变量的命名风格。
2.2 避免意外
代码往往以多层次的形式进行构建,高层代码依赖于底层代码,我们所编写的代码往往只是大规模系统中的一小部分,我们依赖于其他人的代码,他人也可能依赖于我们的代码,大家协作的方式就是代码契约,输入是什么输出又是什么,但这种契约很多时候并不是稳固的,经常会出现意外的情况。而我们需要做的就是尽可能地避免意外。
2.2.1 避免编写误导性的函数
“避免编写误导性的函数”是一种避免意外的方式。比如下图中的代码,使用 kdImageStrategy 的代码契约就是传入的参数必须要是对象,并且对象中要包含 imgUrl 和 imgWidth 这两个参数。但遇到不符合要求的参数情况,应该主动抛出错误。

2.3 编写难以被误用的代码
前面提到,一个系统往往是很多人协作而成的结果,如果一段代码很容易误用,根据墨菲定律,那么它迟早要回被误用从而导致软件无法正常运行。因此,我们应该编写难以被误用的代码。
这段是前面例子中的策略上下文中的代码,这段代码实际上是不符合“编写难以被误用的代码”这条支柱的,因为它对谁调用 setImageStrategy 没有限制,从而使得 ImageStrategyContext 的实例会被误用。

而如果把代码改成只能在构建时设值,那么就可以使得类编程不可变类,大大降低了代码被误用的可能性。

2.4 实现代码模块化
模块化的主旨之一是我们应创建可以轻松调整和重新配置的代码,而无须准确地知道如何调整或重新配置这些代码。要想实现这一目标的关键点在于,不同的功能应该可以准确的映射到代码库的不同部分。
2.4.1 考虑使用依赖注入
代码在解决高层次问题时常常需要依赖于低层次,但是子问题并不总是只有一个解决方案,因此在构造代码时允许子问题解决方案重新配置是很有帮助的,而依赖注入能够帮助我们实现这个目标。
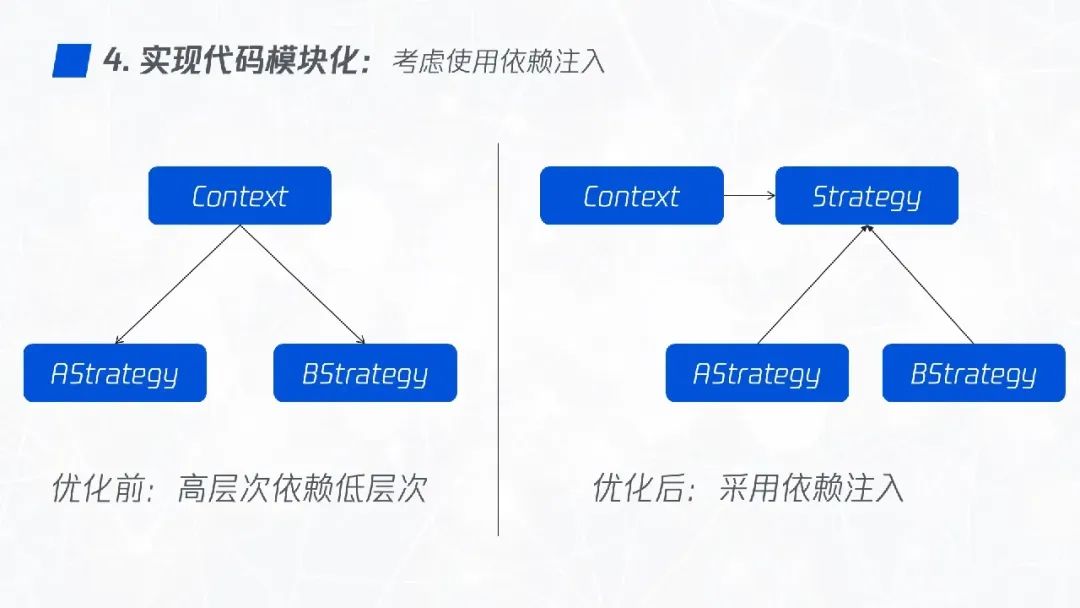
下面的代码中,ImageStrategyContext 对它的子解决方案是硬编码依赖的,直接在内部声明了两个策略的实例。

我们可以采用依赖注入的方式,通过构造函数传递将策略实例进来,这样可以更好地实现代码模块化。

2.5 编写可重用可推广的代码
在编写代码时经常会需要引用他人的代码,如果什么都需要自己编写,那么很难实现大规模合作。而这里的关键就是编写可重用可推广的代码。
2.5.1 保持函数参数的集中度
在下面这段代码的计算最佳压缩比例方法 setOptimalCompressionRatio 中,传入了 compressionRatio 和 cropRatio 两个参数,但实际上只需要传入 compressionRatio 即可。这种函数参数超出需要的情况,可能会使得代码难以重用。我们可以删除 cropRatio 这个参数,让函数只取得其所必要的参数。

2.6 编写可测试的代码并适当测试
当我们在修改代码时很有可能会无意间引入 bug,因此我们需要一种手段来确保代码能够持续正常工作,测试就是提供这种保证的主要手段。
2.6.1 一次测试一个行为
我们应该确保一个用例仅测试一个行为,如果掺杂着许多行为,很有可能会导致较低的测试质量。

2.7 小结
这一小节主要通过前面所讲的图片优化工具的示例来分别介绍代码质量的六大支柱,每个支柱中都有很多具体的实现方式,因为时间的关系,在第一个支柱中举了 3 个例子来说明“编写易于理解(可读)的代码”,而在剩余的支柱中,分别仅举了 1 个例子。
03
编程范式、设计原则和设计模式
刚刚介绍了高质量代码的四大目标以及六大支柱,你可能会发现代码都采用了面向对象的风格,那是不是就只有面向对象的代码才能写出高质量的代码?下面就跟大家聊一聊编程范式以及更具体的设计原则、设计模式。
3.1 编程范式
编程范式指的是编程的风格,与具体的编程语言关系不大,比如 JavaScript 就是个多范式语言,即使像 Java 这样一直被大家所熟知的面向对象语言也加了不少函数式编程的元素。
按照《架构整洁之道》的划分,主流的编程范式主要包括 3 种,结构化编程、面向对象编程和函数式编程。
3.1.1 结构化编程
不知道你是否想过这样一个问题?面向对象编程之所以叫面向对象,是因为其中主要的设计元素是对象,而函数式编程主要的设计元素是函数。那结构化编程呢,难道它的主要设计元素是结构?这好像也不太对。其实,所谓结构化,是相对于非结构化编程而言的。
想要了解结构化编程,一定得回到那个古老的年代,看看非结构化编程是怎么样的。下图中左边是一段用 Java 写的代码,这是一段包了面向对象的结构化代码,屏幕的右边是对左边代码反编译后的字节码,代码从第 0 行开始执行,但执行到第 6 行时,会进行判断,如果结果是真就跳到第 14 行,11 行也是类似。大家可以看到非结构化编程的主要特点之一就是通过 Goto 进行执行逻辑的跳转。

Dijkstra 写了一篇短小精悍的论文:《Goto 是有害的》,他在这篇论文里面指出 Goto 语句会导致程序难以理解和维护,取而代之的是应该用结构化编程提供更清晰的控制流。
在此之前,有人已经证明了可以用顺序结构、分支结构、循环结构这三种结构构造出任何程序,就这样结构化编程就诞生了。结构化编程对程序执行的直接控制权进行了限制,不再允许让 Goto 随便跳转。
结构化编程应该是我们最为熟悉的编程范式,但我们在写高质量代码时很少提到结构化编程,那是因为结构化编程不能有效地隔离变化,需要与其他编程范式配合使用。
3.1.2 面向对象编程
面向对象编程可能大多数程序员都听说过,当我们代码规模逐渐膨胀,结构化编程中各模块的依赖关系很强,导致无法有效地隔离,而面向对象可以提供更好地组织代码。
说到面向对象,你可能会想到面向对象的三个特点:封装、继承和多态。封装是面向对象的根基,单元模块封装得好,就会更加稳定,从而才能构建更大的模块。继承一般可以从两个角度进行看待:如果站在子类的角度往上看,更多考虑的是代码复用,这叫“实现继承”;另一种角度,如果站在父类角度往下看,更多考虑的是多态,这叫“接口继承”。但真正让面向对象发挥能力的是它的第三个特点:多态。我们可以引用罗伯特·马丁在他的《架构整洁之道》里面的一段话:“面向对象编程就是以多态为手段来对源代码中的依赖关系进行控制的能力,这种能力让软件架构师可以构建出某种插件式架构,让高层策略性组件与底层实现性组件相分离,底层组件可以被编译成插件,实现独立于高层组件的开发和部署”。
3.1.3 函数式编程
函数式编程是一种编程范式,它提供给我们的编程元素就是函数。只不过,这个函数跟高中数学的函数 f(x) 实际上是一样的,回想一下高中的函数 f(x),同样的输入一定会给出同样的输出,在函数式编程中也一样,我们要尽可能规避状态和副作用。我们平时所听说过的函数是一等公民、柯里化、管道这些都是函数式编程中所用到的技术。
函数式编程的强大之处在于不可变性,因为“所有的竞争问题、死锁问题、并发更新问题都是由可变变量导致的。如果变量永远不会被更改,那就不可能产生竞争或者并发更新问题。如果锁状态是不可变的,那就永远不会产生死锁问题”。
3.1.4 编程范式的本质
前面介绍了三种主流的编程范式。但我们有想过为什么要创造出这么些个范式,if else 一把梭不行吗?到底是 KPI 的驱使,还是行业的内卷?
我们先看一本经典的书:《算法+数据结构=程序》,这本书中将重点关注在分离算法和数据结构,算法是解决问题的方法和步骤,而数据结构是组织和存储数据的方式。
但大家可能不熟悉的是就在这本书发表3年后,又有一篇论文发布,名字就叫:《算法 = 逻辑 + 控制》。这篇论文认为,“任何算法都会有两个部分, 一个是 Logic 部分,这是用来解决实际问题的。另一个是 Control 部分,这是用来决定用什么策略来解决问题......如果将 Logic 和 Control 部分有效地分开,那么代码就会变得更容易改进和维护”。
拿一段计算阶乘的代码来具体解释一下。所谓阶乘,就是小于等于某个整数的所有正整数的乘积,我们可以用递归也可以用循环来实现,无论是哪种算法都能够得到相同的结果。因此可以说,递归或者循环是 Control,而阶乘的计算规则是 Logic。
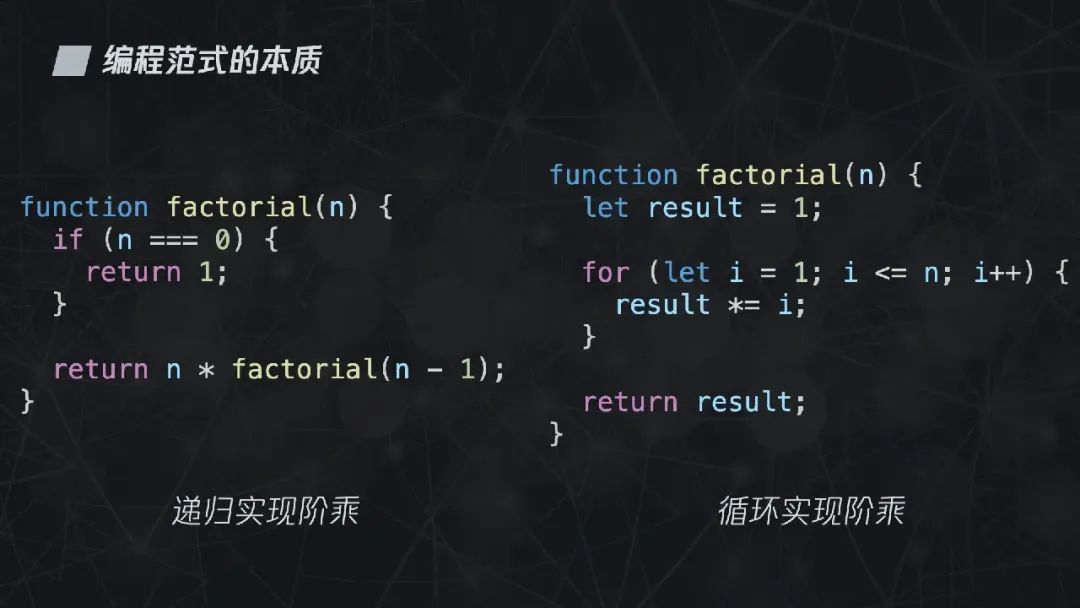
通过前面两个表达式,我们很容易得出,程序 = 逻辑 + 控制 + 数据结构,讲了那么多编程范式,其实都是围绕这三件事。因此我们可以发现,编程范式的本质就是:
|
想要写出高质量代码,有效地分离逻辑、控制和数据结构就是关键所在。
最后再回到我们图片优化工具的例子,无论是采用结构化的方式还是最终采用的面向对象方式,筛选出最合适的图片链接的业务逻辑是相同的,只是控制部分不同,随之而对应的,就是数据结构也需要标准化。
3.2 设计原则
通过编程范式,我们知道了对象、函数这些设计元素,以及编程的本质就是将逻辑、控制和数据进行分离,那具体该如何做呢?设计原则给了我们一些更详细的原则,从而帮助我们更好地达成设计的目标。
SOLID 原则是由罗伯特·马丁提出的,在他的《敏捷软件开发:原则、实践与模式》以及《架构整洁之道》中都进行了详细的阐述。SOLID 原则不仅仅在面向对象领域有指导意义,更是在软件设计领域给了我们设计应该遵循的原则,同时也给了我们一把尺子,用来衡量设计的有效性。
3.2.1 单一职责原则
单一职责原则看起来是这 5 个原则中最简单的一个,但同时也是最容易被大家误解的一个,很多人误认为单一职责就是只做一件事。罗伯特·马丁在他相隔 20年的两本书中对单一职责分别做了定义。
在《敏捷软件开发》中,罗伯特·马丁指出单一职责是指“就一个类而言,应该仅有一个引起它变化的原因”,这个与只做一件事的定义两者最大的区别是将变化纳入了考量。
20 年后,罗伯特·马丁又在《架构整洁之道》里面对单一职责做了定义,“任何一个软件模块都应该只对某一类行为者负责”。这一次,他不仅把变化纳入了考量,也把变化的来源纳入了考量。

但一个域名一条计算规则时,我们很容易就能够辨别两者之间存在差异,因此需要拆分出两个类。但实际业务是复杂多变的,在 B 域名中又区分了不同业务,每个业务又存在差异,那么 B 域名下的 X 业务和 Y 业务是否还需要分拆?如果对单一职责理解不深,很有可能觉得不需要分拆,但我们现在知道单一职责需要考虑变化以及变化的来源,那么很自然地就能够知道需要进行分拆。
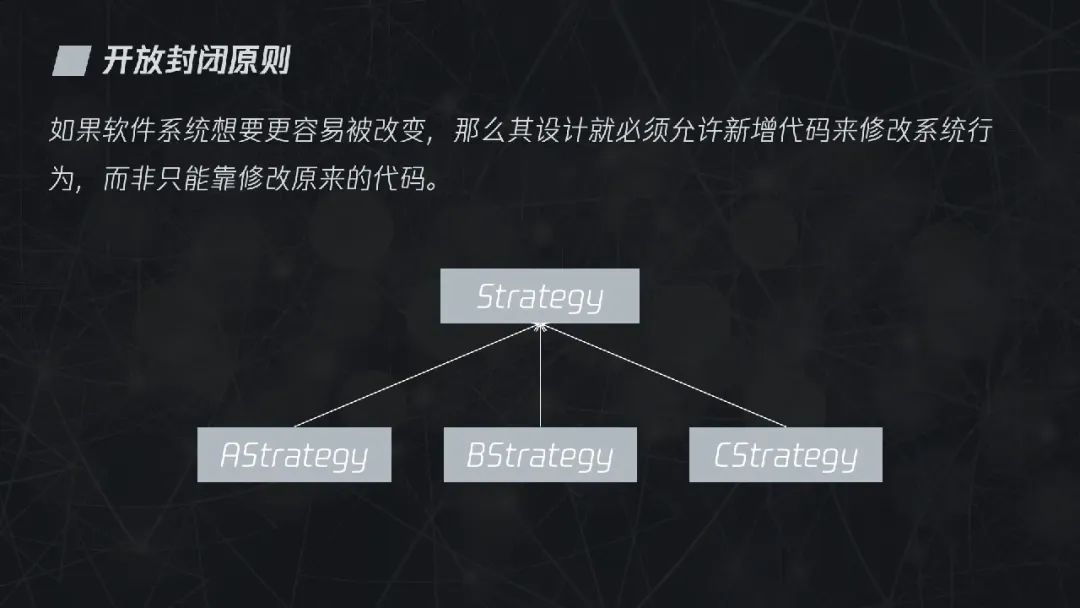
3.2.2 开放封闭原则
回想一下我们的日常工作,一般都是接一个需求就改一次代码,虽然一次两次无伤大雅,但这种对代码持续性修改的行为往往会对代码造成巨大伤害,导致维护成本越来越高。既然修改行为会给代码引起很多问题,那能不能不修改呢?你可能认为我在说痴话,但开放封闭原则就给我们提供了这样一个方向。
跟以往我们通过修改代码来实现新需求相比,开放封闭原则建议我们通过拓展来实现新需求。如果在重构之前的代码中添加新域名,则需要修改原来的代码,但在重构后符合开闭原则的代码中,则只需要添加一个新的类。
其实开闭原则离我们很近,每天都陪伴在我们身边,我们所用到的 Chrome 插件、VSCode 插件等插件系统,都体现了开闭原则。
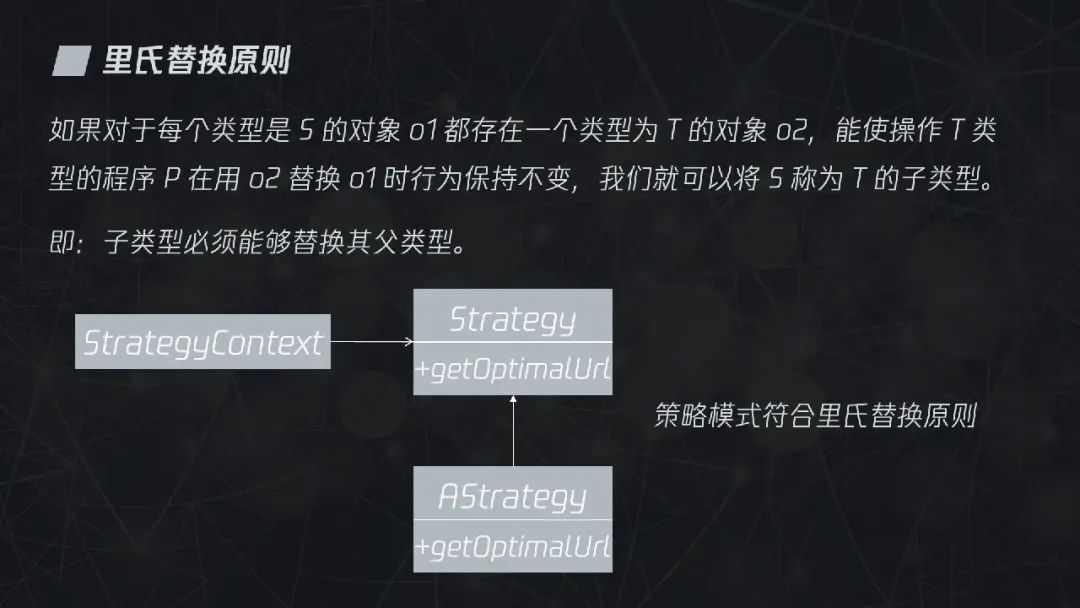
3.2.3 里氏替换原则
里氏替换原则的定义有些拗口:“如果对于每个类型是 S 的对象 o1 都存在一个类型为 T 的对象 o2,能使操作 T 类型的程序 P 在用 o2 替换 o1 时行为保持不变,我们就可以将 S 称为 T 的子类型”。如果直白一些讲,就是“子类型必须能够替换其父类型”。
长方形/正方形问题是个臭名昭著的违反里氏替换原则的设计案例。在中学课本上,老师会告诉我们正方形是个特殊的长方形。因此在软件设计中,我们会理所当然地将正方形继承于长方形。但问题来了,设置长方形需要设置长和宽两个属性,但正方形只需要设置一个。按照里氏替换原则正方形类应该能够替换长方形类,那我们应该可以对正方形设置长和宽,但实际上是不行的,我们不可以同时设置正方形的长和宽,所以这个案例不符合里氏替换原则。
在图片优化工具的案例中,每个具体的策略都是可以自由替换其父类 Strategy 的,因此符合里氏替换原则。
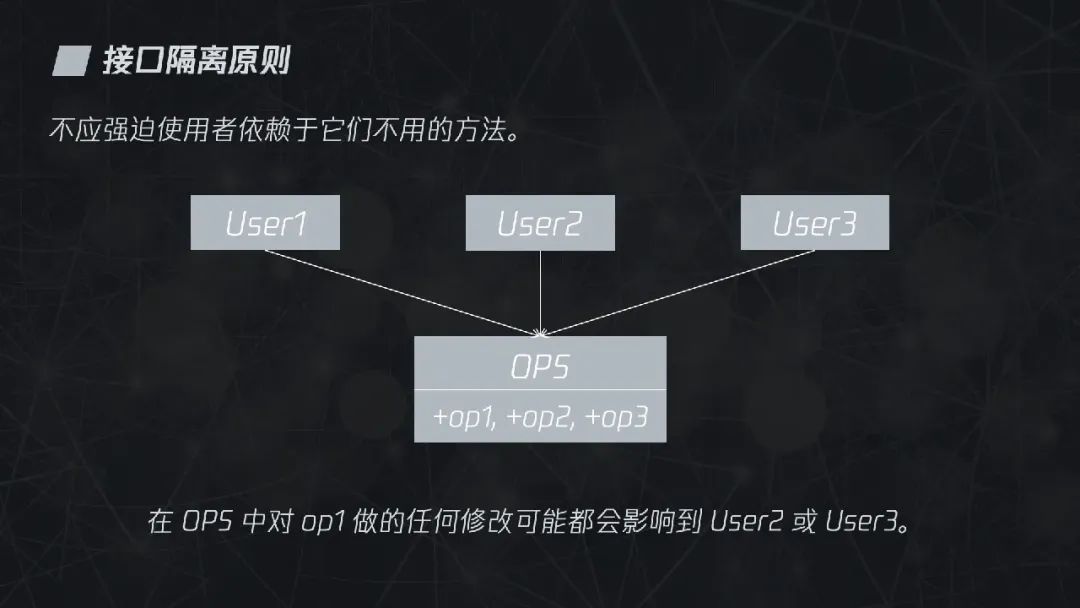
3.2.4 接口隔离原则
接口隔离原则指的是“不应强迫使用者依赖于它们不用的方法”。这个表述看上去很容易理解,尤其是站在使用者的角度,我不需要的接口当然不需要依赖。但作为模块的设计者,都会有将接口设计得过胖的冲动。在下图中,OPS 类提供了 op1、op2、op3 方法分别供 User1、User2、User3 使用,在 OPS 中对 op1 做的任何修改可能都会影响到 User2 或 User3。
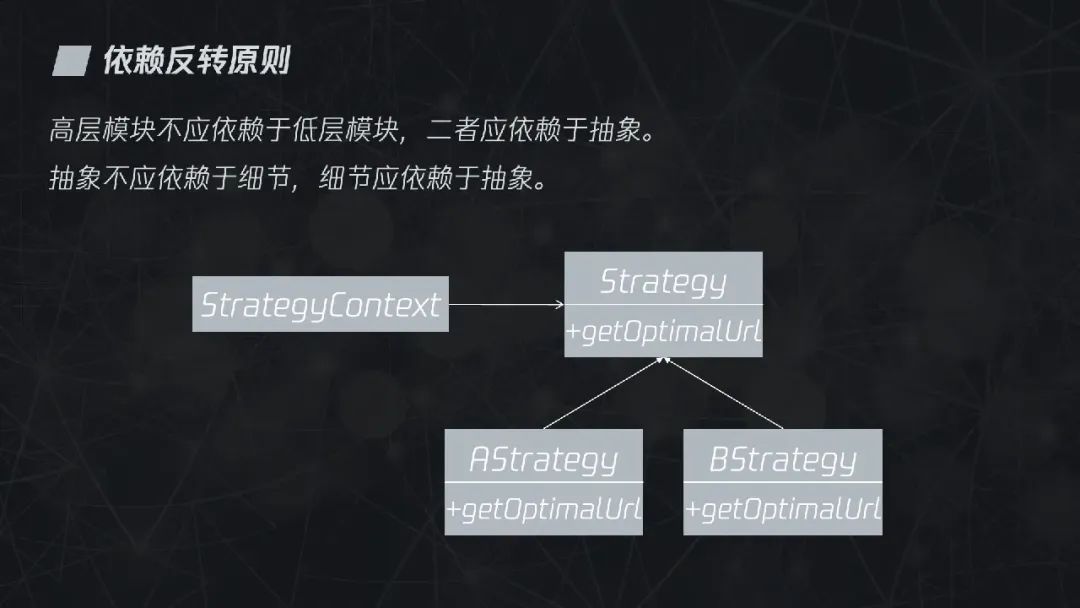
3.2.5 依赖反转原则
依赖反转原则指的是“高层模块不应依赖于底层模块,二者应该依赖于抽象”。换句话说,就是“抽象不应依赖于细节,细节应依赖于抽象”。具体的例子在前面解释依赖注入时也介绍过了,这里就不赘述了。
但是要提一句,这里说推荐采用依赖反转原则,并不是说要把这个原则当做金科玉律,因为实际开发中会不可避免地依赖一些具体的实现。
3.3 设计模式
SOLID 给了我们 5 个在设计时需要遵循的原则,我们还需要具体的方法落地,那就是设计模式。
所谓的模式就是针对一些普遍存在的问题给出的解决方案,模式这个概念最早是在建筑行业提出来的,但确实墙内开花墙外香,模式在软件领域大放异彩。软件领域的设计模式是指:“设计模式是对被用来在特定场景下解决一般设计问题的类和相互通信的对象的描述。”
《设计模式》中提供了 23 种设计模式,其实就是 SOLID 原则在 23 种场景下的应用。
记得之前在学校学习设计模式时老师跟我们讲过,很多人可能在运用设计模式但不自知,这是有可能的,前提条件就是要对 SOLID 原则比较熟悉,但如果说既不熟悉 SOLID 原则,又没有特地学过设计模式,却说自己可能在运用设计模式大概率就是吹牛了。
这里我不想过多地介绍设计模式,因为它们本质上都是 SOLID 原则在不同场景下的应用。
04
技术债、代码坏味道和重构
讲了这么多设计,那是不是就意味着好代码就只是设计出来的呢?
从实际情况来看,虽然我们在写代码初期进行了不少设计,留下了不少拓展点,但仍然会发现代码在逐渐腐烂。这种的情况是如何发生的,又该如何解决呢?
4.1 技术债
所谓技术债,就是“指开发人员为了加速软件开发,在应该采用最佳方案时进行了妥协,改用了短期内能加速软件开发的方案,从而在未来给自己带来的额外开发负担”。
这种技术上的选择,就像一笔债务一样,虽然眼前看起来可以得到好处,但必须在未来偿还。我们知道,要是我们平时一直借债生活,前期可能还能拆东墙补西墙得过且过,但越来越到后期,随着债务滚雪球般的增加,个人的破产也随之而来,生活便将难以为继。生活的道理在技术项目中同样适用,如果欠下的技术债越来越多,最终项目也将失败。
《重构》的作者马丁·福勒按照有意无意和草率慎重两个维度将技术债分为了四个象限,简称“技术债象限(Technical Debt Quadrant)”。慎重的债务都是经过深思熟虑的,他们知道自己欠下了债务,但在项目早日上线和还清债务之间做了评估后,发现前者的收益远远大于后者的成本,因此选择先上线,这种技术债便是慎重有意的。草率的债务可能不是无意的,也有可能有意为之,项目团队知道良好的设计也有能力进行实践,但却认为无法承担得起清偿技术债所需的时间成本。但其实对于大多数没有学习过软件工程或者进行过优秀实践的开发人员来说,大多欠下的是草率无意的技术债。最后是慎重无意的,我们在进行项目开发时,常常一边开发一边学习,你可能需要花一年甚至更长时间才能明白这个系统的最佳实践。
《人月神话》作者 Fred Brooks 建议也许可以花一年时间设计一个专门用来学习的系统,然后废弃并且重建,这样才能设计出一个最佳实践的系统。这建议对于绝大多数的人来说是无法接受的,因此我们应该认识到,在当前我们进行我们所认为的最佳实践时,实际上已经在欠下了技术债,这便是慎重无意的技术债。

4.2 代码坏味道
那该如何识别技术债呢,我们可以通过代码坏味道来识别。
敏捷宣言发起者之一 Kent Beck 提出了 Code Smell 代码异味,“在程序开发领域,代码中的任何可能导致深层次问题的症状都可以叫做代码异味”。
Kent 的奶奶也说过一句饱含哲理的话,“如果尿布臭了,就换掉它”。同样的道理,如果我们发现代码中存在坏味道,那我们换掉它。
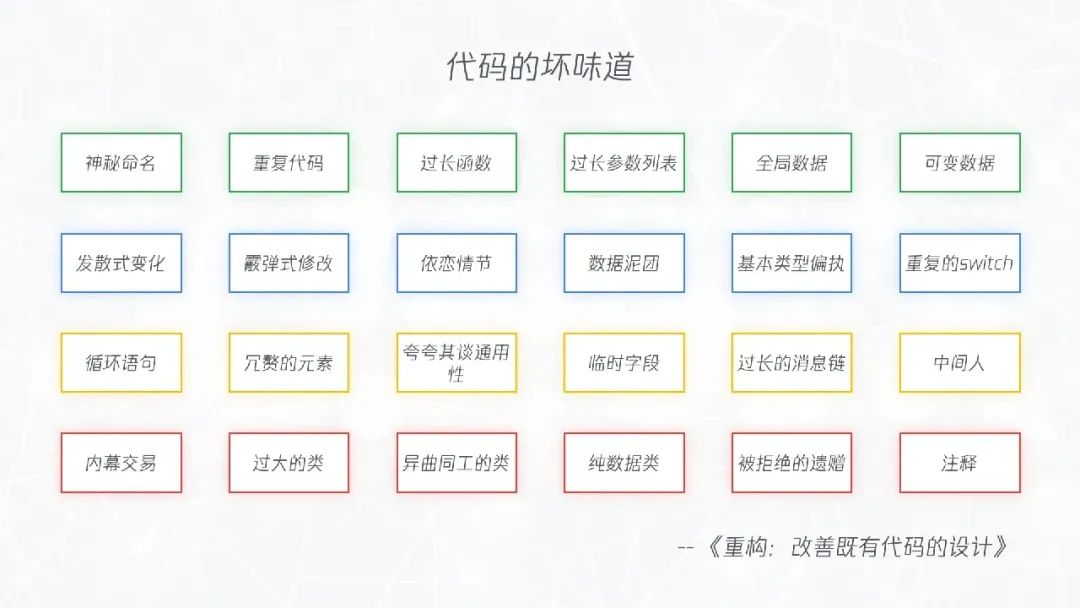
对此,马丁·福勒在《重构》一书中枚举了 24 种代码异味,这样我们识别代码异味便有了抓手,也就可以识别技术债。
4.3 重构
认识了代码坏味道,识别出了技术债,那下面就该还债了,这里还债的方式就是重构。
《重构》这本书中对重构的定义是:“所谓重构(refactoring)是这样一个过程:在不改变代码外在行为的前提下,对代码做出修改,以改进程序的内部结构。重构是一种经千锤百炼形成的有条不紊的程序整理方法,可以最大限度地减小整理过程中引入错误的概率。本质上说,重构就是在代码写好之后改进它的设计。”
举一个坏味道之一“神秘命名”的例子。
下图中左边是充满坏味道的代码,当你阅读这段代码时,首先是 getThem,你肯定很困惑,them 是什么?继续阅读,参数 list 又是什么?再看函数体,list1 是什么?item[0] 是什么?4 又是什么?瞧瞧,一段数行的代码,已经给我们带来了那么多的困惑,这代码还怎么读。
如果仅仅把命名改一下,getThem 换成 getFlaggedCells,获取标记的单元格,list 改成 gameBoard,哦原来是个棋盘呀,下面就不用读了,你已然清楚这段代码是用来读取棋盘中已经被标记的棋盘格了。
通过这个简单的小例子,相信你了解了识别坏味道到重构的过程。

05
总结
回到本次分享一开始的问题:“好代码是设计还是演化而来的?”我相信大家应该都有了答案。
首先我们介绍了图片优化工具的例子,从一开始最普通的流水账形式的毫无设计的代码,再到运用了一些重构措施后相对简洁的代码,最后到应用了策略模式和模板方法模式后的代码。通过这个例子带大家粗略认识了如何通过设计和重构写出高质量代码,但这还不是结束,而是继续将这个例子贯穿本文的始终。
接着解释了什么是好代码,当我们在谈论代码质量时又在谈论什么。借用《好代码,坏代码》的话,好代码应该能够实现 4 个高层目标,与之对应的是 6 项原则,我们不断回过头用我们一开始的例子来说明它是如何符合这 6 项原则的。
我们在例子中重点采用了面向对象范式,无论是面向对象还是函数式,它们都是编程范式,也就是不同的代码风格,本质都是要将逻辑、控制和数据进行有效地分离。知道了编程的本质,我们需要一些更具体的原则来指导我们的行为,因此紧接着我介绍了 SOLID 设计原则,很多人把 SOLID 仅仅当做面向对象中的设计原则,这很片面,实际上可以作为通用的设计原则。在设计原则的基础上,我们还介绍了设计模式实际上就是 23 种应用了设计原则的具体案例。
好代码离不开设计,如果完全不懂得设计,好代码将会无从谈起。但随着项目的推进,无论是开发者有意还是无意的,慎重还是草率的,都会逐渐积累技术债。跟人欠债过多会破产一样,技术债达到一定程度就会导致项目无法继续进行下去,因此我们要时不时地偿还债务。偿还债务的方式就是要识别坏味道,然后有针对性地进行重构。
本文内容集合了前人在软件工程领域总结的切实有效经验。我将这些熟悉又陌生的概念通过一个例子串在了一起,以期让各位对这些概念有宏观认识。如果觉得文章对你有帮助,欢迎你转发分享。
-End-
原创作者|billpchen
技术责编|williamzheng

你都维护过哪些令人抓狂的代码?你是如何评价代码的质量的,避免写出烂代码你有什么样的技巧呢?欢迎在评论区分享,我们将选取1则最有意义的评论,送出腾讯云开发者-毛毯1个(见下图)。8月1日中午12点开奖。





关注并星标腾讯云开发者
第一时间看鹅厂技术