0.摘要
近年来,由于深度卷积神经网络(DCNNs)的发展,语义目标分割取得了显著的改进。训练这样一个DCNN通常依赖于大量具有像素级分割掩码的图像,并且在财务和人力方面标记这些图像非常昂贵。在本文中,我们提出了一个简单到复杂(STC)框架,其中只利用图像级标注来学习用于语义分割的DCNN。具体而言,我们首先使用简单图像的显著性图(即仅包含一个主要对象类别和干净背景的图像)训练一个初始分割网络,称为Initial-DCNN。这些显著性图可以通过现有的自下而上显著目标检测技术自动获得,无需监督信息。然后,基于Initial-DCNN和图像级标注,利用简单图像的预测分割掩码训练一个更好的网络,称为Enhanced-DCNN。最后,利用Enhanced-DCNN和图像级标注推断出的复杂图像(包含两个或更多类别的对象和混乱的背景)的像素级分割掩码作为监督信息,学习用于语义分割的Powerful-DCNN。我们的方法利用来自Flickr.com的40K个简单图像和来自PASCAL VOC的10K个复杂图像逐步提升分割网络。在PASCAL VOC 2012分割基准上进行的大量实验结果很好地证明了所提出的STC框架相对于其他最新技术的优越性。
索引词——语义分割、弱监督学习、卷积神经网络
1.引言
近年来,深度卷积神经网络(DCNNs)在各种计算机视觉任务中展现出了出色的能力,例如图像分类[1]–[4]、目标检测[5],[6]和语义分割[7]–[13]。这些任务中的大多数DCNN都依赖于强监督进行训练,即真实边界框和像素级分割掩码。然而,相比较方便的图像级标注,收集边界框或像素级掩码的注释成本更高。特别是对于语义分割任务,注释大量像素级掩码通常需要相当大的财务开支和人力投入。
为了解决这个问题,一些方法 [14]–[18]已经被提出,通过仅利用图像级标签作为监督信息来进行语义分割。然而,据我们所知,与完全监督的方案相比,这些方法的性能还远远不令人满意(例如,40:6%[15]对比66:4%[13])。考虑到语义分割问题的复杂性,例如高度类内变化(例如,多样的外观、视角和尺度)以及对象之间的不同交互(例如,部分可见性和遮挡),基于图像级注释的复杂损失函数(例如,基于多实例学习的损失函数)[14],[15],[18]可能对于弱监督的语义分割来说不足够,因为它们忽略了分割掩码的固有像素级属性。
值得注意的是,在过去的几年中,许多显著性目标检测方法[19]–[22]已被提出,这些方法不需要高级监督信息,可以检测图像中最显著的目标。虽然这些方法可能在包含多个对象和混乱背景的复杂图像上效果不好,但它们通常为包含单个类别对象和干净背景的图像提供令人满意的显著性图。通过自动检索大量的网络图像,并为相对简单的图像检测显著目标,我们或许能够以较低的成本获得大量的显著性图,用于训练语义分割的DCNNs。
在这项工作中,我们提出了一个基于以下直觉的弱监督分割的简单到复杂的框架。对于具有混乱背景和两个或多个类别对象的复杂图像,仅仅利用图像级标签作为监督往往很难推断语义标签和像素之间的关系。然而,对于具有干净背景和单个主要对象类别的简单图像,可以基于显著目标检测技术[20]–[23]轻松地将前景和背景像素分割开来。在图像级标签的指示下,自然可以推断出属于前景的像素可以被赋予相同的语义标签。因此,可以根据简单图像的前景/背景掩码和图像级标签来学习一个初始的分割器。此外,基于初始分割器,可以对复杂图像中的更多对象进行分割,以便持续学习更强大的分割器用于语义分割。
具体而言,首先使用语义标签作为查询在图像托管网站(例如Flickr.com)上检索图像。从前几页检索到的图像通常符合简单图像的定义。利用最先进的显著性检测技术[22]生成高质量的显著性图。基于图像级标签的监督,我们可以轻松地为每个前景像素分配一个语义标签,并通过使用多标签交叉熵损失函数来学习一个由生成的显著性图监督的语义分割DCNN,其中根据显著性图中嵌入的预测概率,每个像素被分类为前景类和背景类。然后,利用简单到复杂的学习过程逐步提高DCNN的能力,其中通过最初学习的DCNN预测的简单图像的分割掩码依次用作学习增强DCNN的监督。最后,利用增强的DCNN进一步利用来自复杂图像的更难和更多样的掩码来学习一个更强大的DCNN。特别地,这项工作的贡献总结如下:
• 我们提出了一个简单到复杂(STC)的框架,可以以弱监督的方式有效地训练分割DCNN(即,只提供图像级标签)。所提出的框架是通用的,可以将任何最先进的全监督网络结构纳入到学习分割网络中。
• 引入了多标签交叉熵损失函数,基于显著性图来训练分割网络,其中每个像素可以以不同的概率适应性地对前景类和背景做出贡献。
• 我们在PASCAL VOC 2012分割基准[24]上评估了我们的方法。实验结果充分证明了STC框架的有效性,达到了最先进的性能水平。
2.相关工作
2.1.弱监督语义分割
为了减轻像素级掩码注释的负担,一些弱监督的方法已经被提出用于语义分割。例如,Dai等人[8]和Papandreou等人[14]提出通过利用标注的边界框来估计语义分割掩码。例如,通过结合来自Pascal VOC[24]的像素级掩码和来自COCO[25]的标注边界框,[8]在PASCAL VOC 2012基准测试上取得了最先进的结果。为了进一步减轻边界框收集的负担,一些工作[14]–[16],[18],[26]–[28]提出仅使用图像级标签来训练分割网络。Pathak等人[16]和Pinheiro等人[15]提出利用多实例学习(MIL)[29]框架来训练用于分割的DCNN。在[14]中,提出了一种基于期望最大化(EM)算法的替代训练过程,用于动态预测前景(具有语义)/背景像素。Pathak等人[18]引入了用于弱监督分割的约束卷积神经网络。具体而言,通过利用物体大小作为额外的监督,[18]取得了显著的改进。最近,在[28]中利用了三种损失函数,即种子、扩展和边界约束,来训练分割网络。Saleh等人[27]还提出了一种使用前景/背景先验进行学习分割的相关方法,证明了我们框架的有效性。
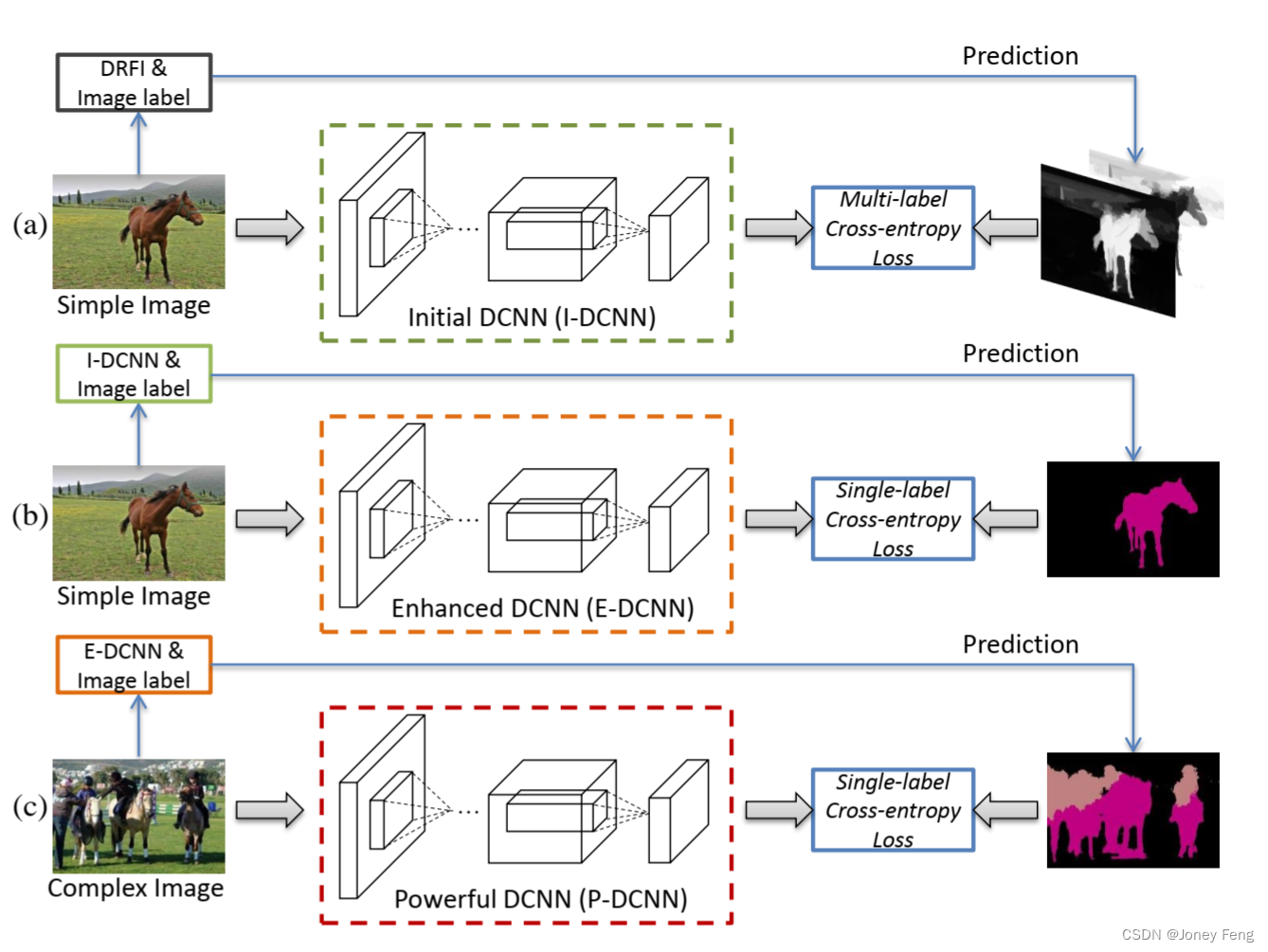
图1.所提出的简单到复杂(STC)框架的示意图。(a)首先,利用DRFI [22]生成简单图像的高质量显著性图作为监督的前景/背景掩码,用于使用所提出的损失函数训练Initial-DCNN。(b)然后,通过Initial-DCNN预测的分割掩码来监督学习一个更好的Enhanced-DCNN。(c)最后,预测更多复杂图像的掩码来训练一个更强大的网络,称为Powerful-DCNN。
2.2.自适应学习(Self-paced Learning)
我们的框架首先从简单图像中学习,然后将学习到的网络应用于复杂图像,这与自适应学习[30]相关。最近,基于自适应学习的各种计算机视觉应用[31]–[33]已经被提出。具体而言,Tang等人[31]通过从简单样本开始,将从图像中学习到的目标检测器适应到视频中。Jiang等人[32]解决了数据多样性的问题。在[33]中,只使用很少的样本作为种子来训练一个弱目标检测器,然后通过迭代积累更多的实例来增强目标检测器,这可以被视为一种轻微监督的自适应学习方法。然而,与自适应学习不同的是,在本文中,在训练之前,简单或复杂的样本是根据它们的外观(例如,单个/多个对象或清晰/混杂的背景)进行定义的,而不是每次迭代自动选择用于训练的样本。
此外,还有许多其他的工作[17],[34]–[37]也解决了这个任务。这些方法通常应用于简单或小规模的数据集,如MSRA [38]和SIFT-flow [39]。具体而言,Liu等人[35]提出了一种图传播方法,将图像级别的标注标签自动分配给上下文推导出的语义区域。Xu等人[34]提出了一个潜在结构化预测框架,其中图模型编码了类别的存在和缺失,以及语义标签对超像素的分配。Vezhnevets等人[37]提出了一个最大期望一致性模型选择原则,用于评估语义分割结构模型参数家族中模型的质量。
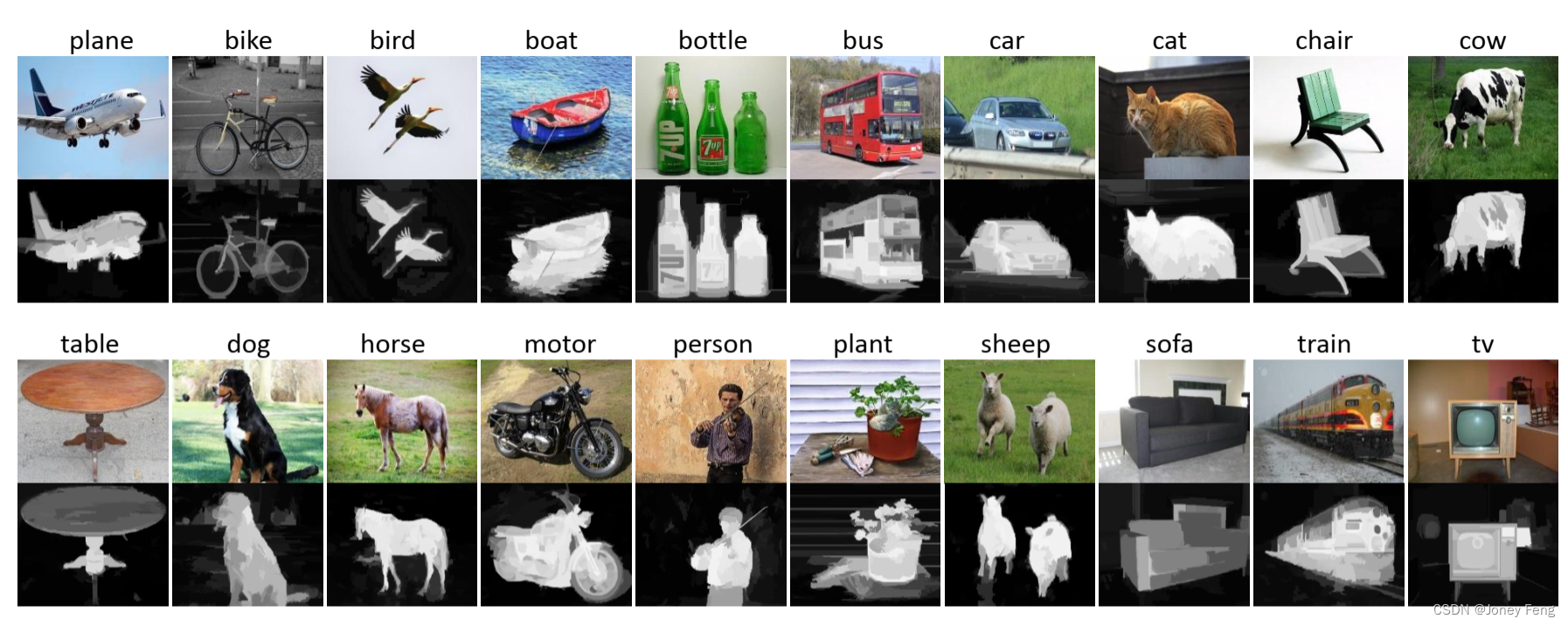
图2.简单图像示例及其在20个PASCAL VOC类别上由DRFI生成的相应显著性图。
3.提出的方法(PROPOSED METHOD)
图1显示了所提出的简单到复杂(STC)框架的架构。我们利用最先进的显著性检测方法,即具有区域判别特征集成(DRFI)[22],生成简单图像的显著性图。产生的显著性图首先被用来训练一个初始的DCNN,使用多标签交叉熵损失函数。然后,提出了简单到复杂的框架,逐步改进分割DCNN的能力。
3.1.初始深度卷积神经网络(Initaial Deep Convolution Neural Network)
对于每个图像生成的显著性图,像素值越大意味着该像素更有可能属于前景。图2展示了一些简单图像的示例以及由DRFI生成的相应显著性图。可以观察到前景像素与语义对象之间存在明确的关联。由于每个简单图像都附带有语义标签,很容易推断出前景候选像素可以被赋予相应的图像级别标签。然后,提出了一个多标签交叉熵损失函数,通过显著性图来监督训练分割网络。假设训练集中有C个类别。我们分别将OI =f1;2;···;Cg和OP =f0;1;2;···;Cg表示为图像级别标签和像素级别标签的类别集合,其中0表示背景类。我们用f(·)表示分割网络的滤波器,其中所有的卷积层都对给定的图像I进行滤波。f(·)产生一个h×w×(C +1)维的激活输出,其中h和w分别是每个通道特征图的高度和宽度。我们利用softmax函数计算I中每个像素属于第k(k 2 OP)类的后验概率,其数学公式如下所示,

具体而言,对于每个简单图像,我们假设只包含一个语义标签。假设简单图像I由第c(c 2 OI)类别注释,并且从显著性图中取得归一化值作为每个像素属于类别c的概率。我们将显著性图调整为与DCNN的输出特征图大小相同,然后可以重新定义公式(2)如下:
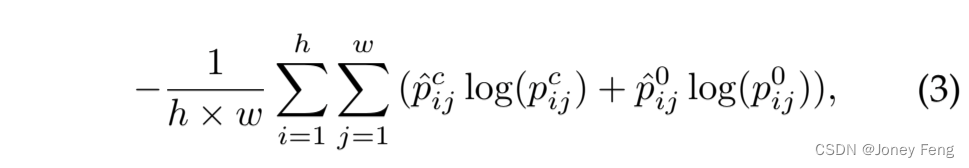
其中p0ij表示位于位置(i,j)的像素属于背景的概率(p0ij = 1−pcij)。我们将在这个阶段学到的分割网络称为初始DCNN(简称为I-DCNN)。需要注意的是,我们还可以利用Saliency Cut [20]基于生成的显著性图生成前景/背景分割掩码。然后,可以使用单标签交叉熵损失进行训练。我们将此方案与我们提出的方法进行比较,并发现在VOC 2012验证集上的性能会下降3%。原因是一些显著性检测结果不准确。因此,直接应用Saliency Cut [20]生成分割掩码会引入许多噪声,这对于训练I-DCNN是有害的。然而,基于提出的多标签交叉熵损失,正确的语义标签仍然会对优化产生贡献,这可以降低低质量显著性图带来的负面影响。
3.2.简单到复杂的框架
在本节中,提出了一种渐进训练策略,通过将更复杂的图像与图像级别标签结合起来,增强DCNN的分割能力。基于训练好的I-DCNN,可以预测图像的分割掩码,进一步提高DCNN的分割能力。类似于第3.1节中的定义,我们将位置(i,j)处第k类别的预测概率表示为pkij。然后,通过分割DCNN预测的像素位置(i,j)的估计标签gij可以表示为:
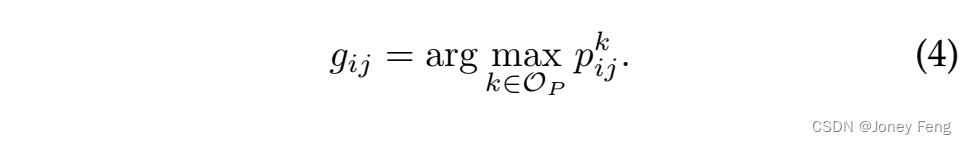
3.2.1.增强深度卷积神经网络(Enhanced-DCNN)
然而,当将I-DCNN的错误预测用作训练DCNN的监督时,可能会导致语义分割的漂移。幸运的是,在训练集中的每个简单图像都有图像级别标签,可以用来优化预测的分割掩码。具体而言,如果简单图像I的标签为c(其中c∈OI),则像素的估计标签可以重新定义为:
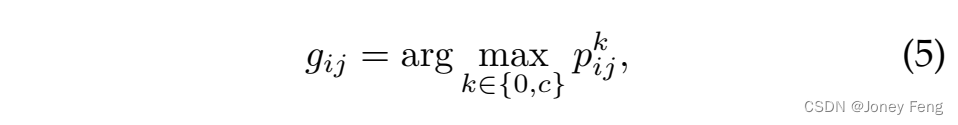
其中0表示背景的类别。通过这种方式,可以消除训练集中简单图像的一些错误预测。然后,利用预测的分割掩码作为监督信息,训练一个更强大的分割DCNN,称为增强DCNN(简称为E-DCNN)。我们使用单标签交叉熵损失函数来训练E-DCNN,这是全监督方案中广泛使用的损失函数[11]。
3.2.2.强大的卷积神经网络(Powerfu-DCNN)
在这个阶段,利用具有图像级别标签的复杂图像来训练分割DCNN,其中包含更多的语义对象和杂乱的背景。与I-DCNN相比,E-DCNN由于使用了大量的预测分割掩码,具有更强大的语义分割能力。尽管E-DCNN是通过简单图像进行训练的,但这些图像中的语义对象在外观、尺度和视角上具有较大的变化,这与复杂图像中的外观变化是一致的。因此,我们可以应用E-DCNN来预测复杂图像的分割掩码。类似于公式(5),为了消除错误预测,对于图像I的每个像素,估计的标签可以表示为: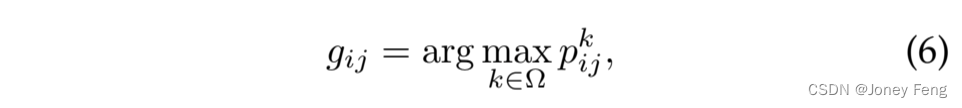
其中Ω表示每个图像I的真实语义标签(包括背景)的集合。我们将在这个阶段训练的分割网络称为强大DCNN(简称为P-DCNN)。在这项工作中,我们使用了两种交叉熵损失函数来训练分割网络。特别地,完全卷积网络中的交叉熵损失是像素级别的,对于完全监督的方案,每个像素只能被分配给一个类别,相应的交叉熵损失是单标签的。这与E-DCNN和P-DCNN的目标相匹配。因此,我们使用单标签损失来训练这两个网络。对于训练I-DCNN,每个像素的类别信息无法准确获得。为了解决这个问题,根据生成的显著性图和图像级别标签,每个像素根据不同的概率与两个类别(一个是背景,另一个是20个前景类别中的一个)进行软关联。我们将这种方案的损失函数视为多标签交叉熵损失。为了说明每个步骤的有效性,图3显示了由I-DCNN、E-DCNN和P-DCNN生成的一些分割结果。可以看出,基于提出的从简单到复杂的框架,分割结果逐渐变得更好。
4.实验结果
4.1.数据集
Flickr-Clean:我们构建了一个名为Flickr-Clean的新数据集,用于训练I-DCNN的分割网络。我们使用与PASCAL VOC语义一致的关键词作为查询,在图像托管网站Flickr.com上检索图像。我们爬取前几页的搜索结果中的图像,并使用最先进的显著性检测方法,即区域特征一致性整合(DRFI),生成爬取图像的显著性图。为了确保图像是简单的,我们采用类似于[40]、[41]中提出的方法来过滤爬取的图像。我们按照[40]中的方法,衡量给定图像I的Saliency Cut [20]分割的不准确性和不完整性。将给定图像I的像素数记为NI,对应分割掩码的前景像素数记为Nf。我们保留那些前景区域满足0.3NI < Nf < 0.5NI的图像。如果不对训练集进行这样的过滤,使用全部10万张爬取图像进行训练会导致I-DCNN的性能下降4%。最终,我们收集了41625张图像用于训练分割网络。
PASCAL VOC 2012:所提出的弱监督方法在PASCAL VOC 2012分割基准测试上进行评估。原始的训练数据包含1464张图像。在[42]中,额外标注了10582张图像(train aug)进行训练。在我们的实验中,使用了10582张仅具有图像级别标签的图像作为复杂图像集进行训练。验证集和测试集分别包含1449张和1456张图像。对于验证集和测试集,我们只使用了来自Flickr-Clean的简单图像和train aug的复杂图像进行训练。性能是以像素交并比(IoU)在21个类别(20个对象和一个背景)上平均计算的。弱监督方法的广泛评估主要在验证集上进行,我们还通过将结果提交到官方的PASCAL VOC 2012服务器上,报告了测试集的结果(其真实掩码未发布)。

图3. 分别由I-DCNN、E-DCNN和P-DCNN在PASCAL VOC 2012验证集上生成的分割结果示例。
4.2.训练策略
我们采用了提出的从简单到复杂的框架来学习DeepLab-CRF模型[13]的DCNN组件,其参数由在ImageNet [43]上预训练的VGG-16模型[2]进行初始化。对于分割DCNNs(I-DCNN,E-DCNN和P-DCNN)的训练,我们使用每批8张图像。每个训练图像被调整为330×n,并在训练阶段随机裁剪大小为321×321的补丁。初始学习率设置为0.001(最后一层为0.01),在大约每5个epoch后除以10。动量和权重衰减设置为0.9和0.0005。训练进行大约15个epoch。为了与[14],[18]的结果进行公平比较,采用稠密CRF推理来对预测结果进行后处理。每个分割DCNN都是基于NVIDIA GeForce Titan GPU进行训练,具有6GB的内存。所有实验都使用DeepLab代码[13]进行,该代码是基于公开可用的Caffe框架[44]实现的。
表1:在VOC 2012验证集上使用不同显著性图训练的I-DCNN模型的比较(mIoU以%表示)。

表2:在VOC 2012验证集上使用不同数量图像训练的I-DCNN模型的比较(mIoU以%表示)。