解决执行python"ImportError: No module named requests"问题
#切换到python的安装目录执行如下命令
D:\Python27>pip install requests
ImportError: No module named bs4错误解决方法
运行脚本时提示ImportError: No module named bs4错误,原因:未找到名为Beautifulsoup4的模块。
解决办法:
下载BS4模块,并安装
下载地址:https://www.crummy.com/software/BeautifulSoup/bs4/download/
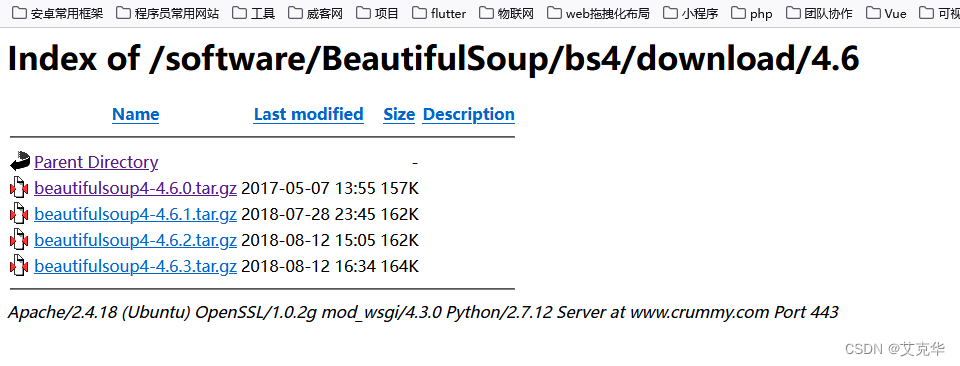 要注意版本,我这里的Python是2.7版本,下载最新的会报错,所以下载了4.6版本
要注意版本,我这里的Python是2.7版本,下载最新的会报错,所以下载了4.6版本
下载完解压这个文件,把它放在python的安装目录下
进入到beautifulsoup4-4.6.0目录下边, 打开DOS命令窗口,如下图:
输入安装命令“python setup.py install”安装即可。
ImportError: No module named lxml
进入python安装目录的Scripts目录
D:\Python27\Scripts>pip install lxml
ImportError: No module named openpyxl.workbook
python -m pip install openpyxl
ImportError: No module named pandas
进入python安装目录的Scripts目录
D:\Python27\Scripts>pip install pandas
print打印中文乱码问题
转换成unicode对象
将字符串转换成unicode对象常用的3种方法:
1、字符串前面加u
s1=u’国道图层’
print (‘s1:’+s1)
u将字符串以unicode格式存储。python头部声明的utf-8编码识别字符串,然后转换成unicode对象。
也就是说不加u就是某种编码的字符串,这里是utf-8编码的字符串。
如果加u就是一个unicode对象。
可以用type()函数查看数据类型。
XPath常用规则
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
| * | 通配符,选择所有元素节点与元素名 |
| @* | 选取所有属性 |
| [@attrib] | 选取具有给定属性的所有元素 |
| [@attrib=‘value’] | 选取给定属性具有给定值的所有元素 |
| [tag] | 选取所有具有指定元素的直接子节点 |
| [tag=‘text’] | 选取所有具有指定元素并且文本内容是text节点 |
![[附源码]计算机毕业设计基于vue的软件谷公共信息平台Springboot程序](https://img-blog.csdnimg.cn/7e9adac22bd1411d9326b648d1a0eae5.png)




![[Java EE初阶] 进程调度的基本过程](https://img-blog.csdnimg.cn/3fe0f4e75b224ad6a872df911f3b7d46.png)

![[附源码]Python计算机毕业设计SSM基于的智慧校园安防综合管理系统(程序+LW)](https://img-blog.csdnimg.cn/f0497cd276534b64a07acad68025c3fb.png)