👏作者简介:大家好,我是爱敲代码的小王,CSDN博客博主,Python小白
📕系列专栏:python入门到实战、Python爬虫开发、Python办公自动化、Python数据分析、Python前后端开发
📧如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步👀
🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
🍂博主正在努力完成2023计划中:以梦为马,扬帆起航,2023追梦人
🔥🔥🔥 python入门到实战专栏:从入门到实战
🔥🔥🔥 Python爬虫开发专栏:从入门到实战
🔥🔥🔥 Python办公自动化专栏:从入门到实战
🔥🔥🔥 Python数据分析专栏:从入门到实战
🔥🔥🔥 Python前后端开发专栏:从入门到实战
目录
for循环和可迭代对象遍历
嵌套循环和综合练习
continue语句
else语句
循环代码优化
for循环和可迭代对象遍历
for循环通常用于可迭代对象的遍历。for循环的语法格式如下:
for 变量 in 可迭代对象:
循环体语句【操作】遍历一个元组或列表
for x in (20,30,40):
print(x*3)可迭代对象
Python包含以下几种可迭代对象:
1 序列。包含:字符串、列表、元组、字典、集合
2 迭代器对象(iterator)
3 生成器函数(generator)
4 文件对象
我们已经在前面学习了序列、字典等知识,迭代器对象和生成器函数将在后面进行详解。接下来,我们通过循环来遍历这几种类型的数据:
【操作】遍历字符串中的字符
for x in "sxt001":
print(x)【操作】遍历字典
d = {'name':'gaoqi','age':18,'address':'西三旗001号楼'}
for x in d: #遍历字典所有的key
print(x)
for x in d.keys():#遍历字典所有的key
print(x)
for x in d.values():#遍历字典所有的value
print(x)
for x in d.items():#遍历字典所有的"键值对"
print(x)
range对象
range对象 是一个迭代器对象,用来产生指定范围的数字序列。格式为:
range(start, end [,step])生成的数值序列从 start 开始到 end 结束(⚠️不包含 end )。若没有填写 start ,则默认从0开始。 step 是可选的步长,默认为1。如下是几种典型示例:
for i in range(10) 产生序列:0 1 2 3 4 5 6 7 8 9
for i in range(3,10) 产生序列:3 4 5 6 7 8 9
for i in range(3,10,2) 产生序列:3 5 7 9
【操作】利用for循环,计算1-100之间数字的累加和;计算1-100 之间偶数的累加和,计算1-100之间奇数的累加和。
sum_all = 0 #1-100所有数的累加和
sum_even = 0 #1-100偶数的累加和
sum_odd = 0 #1-100奇数的累加和
for num in range(101):
sum_all += num
if num%2==0:sum_even += num
else:sum_odd += num
print("1-100累加总和{0},奇数和{1},偶数和{2}".format(sum_all,sum_odd,sum_even))实时效果反馈
1. 如下代码,空白处的代码是:
sum_all = 0 #1-100所有数的累加和
__________________:
sum_all += num
print("1-100累加总和{0}".format(sum_all))A for i in range(101)
B for i in range(100)
C for num in range(101)
D for num in range(100)
嵌套循环和综合练习

一个循环体内可以嵌入另一个循环,一般称为“嵌套循环”,或者“多重循环”。
【操作】打印如下图案

for x in range(5):
for y in range(5):
print(x,end="\t")
print() #仅用于换行【操作】利用嵌套循环打印九九乘法表
for m in range(1,10):
for n in range(1,m+1):
print("{0}*{1}={2}".format(m,n, (m*n)),end="\t")
print()九九乘法表:

【操作】用列表和字典存储下表信息,并打印出表中工资高于15000的数据
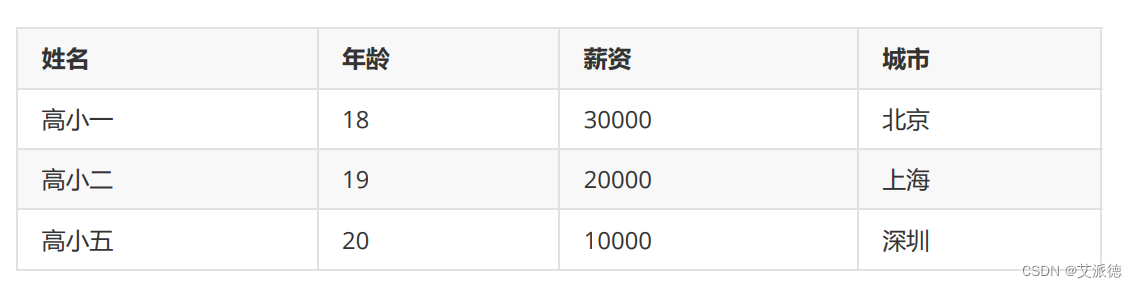
r1= dict(name="高小一",age=18,salary=30000,city="北京")
r2= dict(name="高小二",age=19,salary=20000,city="上海")
r3= dict(name="高小三",age=20,salary=10000,city="深圳")
tb = [r1,r2,r3]
for x in tb:
if x.get("salary")>15000:
print(x)break语句
break语句可用于while和for循环,用来结束整个循环。当有嵌套循环时,break语句只能跳出最近一层的循环。
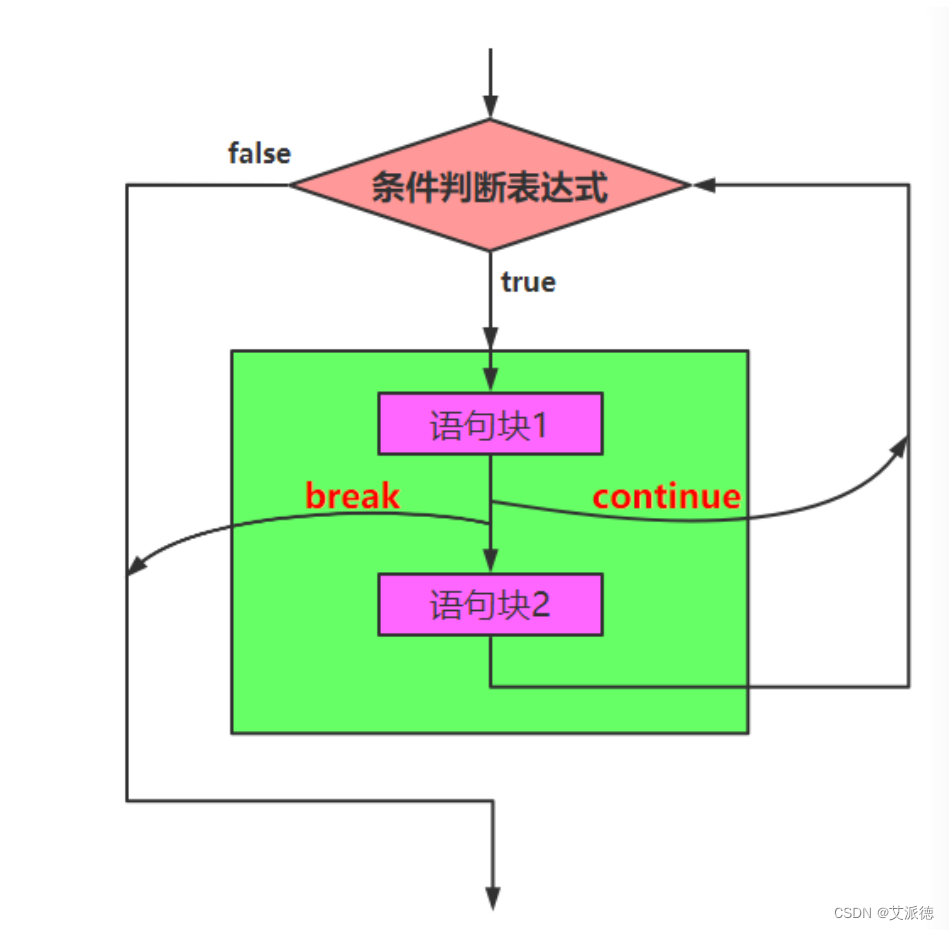
【操作】使用break语句结束循环
while True:
a = input("请输入一个字符(输入Q或q结束)")
if a.upper()=='Q':
print("循环结束,退出")
break
else:
print(a)
实时效果反馈
1. 循环结构中,break的作用是:
A 用来结束整个循环
B 用来结束本次循环,继续下一次循环
C 用来暂停整个循环
D 休息一下
continue语句
continue语句用于结束本次循环,继续下一次。多个循环嵌套时, continue也是应用于最近的一层循环。
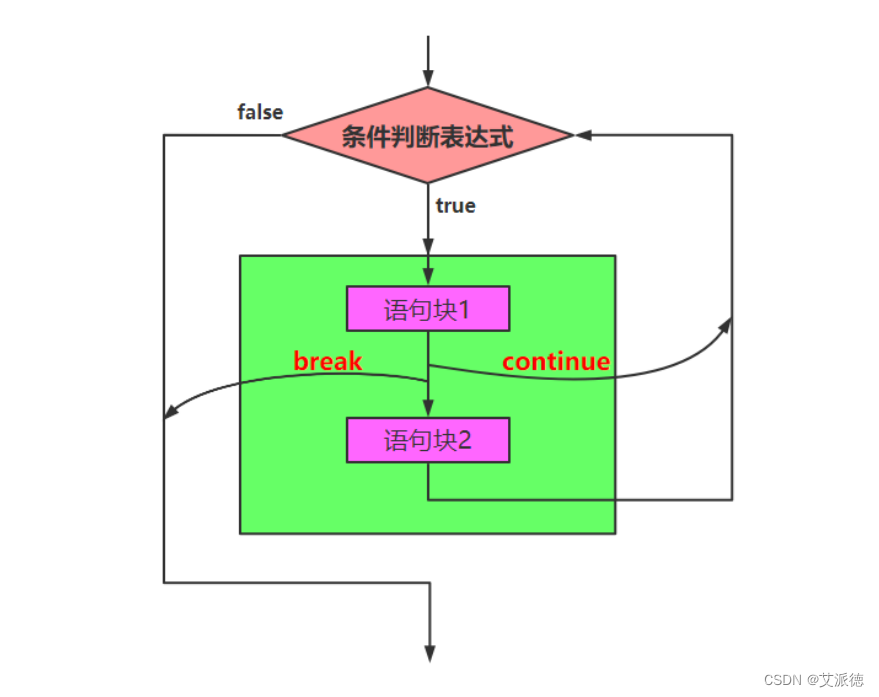
【操作】要求输入员工的薪资,若薪资小于0则重新输入。最后打印出录入员工的数量和薪资明细,以及平均薪资
empNum = 0
salarySum= 0
salarys = []
while True:
s = input("请输入员工的薪资(按Q或q结束)")
if s.upper()=='Q':
print("录入结束")
break
if float(s)<0:
print("无效!继续录入!")
continue
print("录入成功!")
empNum +=1
salarys.append(float(s))
salarySum += float(s)
print("员工数{0}".format(empNum))
print("录入薪资:",salarys)
print("总发薪资:",salarySum)
print("平均薪资{0}".format(salarySum/empNum))
执行结果:
请输入员工的薪资(按Q或q结束)2000
请输入员工的薪资(按Q或q结束)3000
请输入员工的薪资(按Q或q结束)4000
请输入员工的薪资(按Q或q结束)5000
请输入员工的薪资(按Q或q结束)Q
录入完成,退出
员工数4
录入薪资: [2000.0, 3000.0, 4000.0, 5000.0]
平均薪资3500.0实时效果反馈
1. 循环结构中,continue的作用是:
A 用来结束整个循环
B 用来结束本次循环,继续下一次循环
C 用来暂停整个循环
D 休息一下
else语句
while、for循环可以附带一个else语句(可选)。如果for、while语 句没有被break语句结束,则会执行else子句,否则不执行。语法格式如下:
while 条件表达式:
循环体
else:
语句块
或者:
for 变量 in 可迭代对象:
循环体
else:
语句块【操作】员工一共4人。录入这4位员工的薪资。全部录入后,打印 提示“您已经全部录入4名员工的薪资”。最后,打印输出录入的薪资和平均薪资
salarySum= 0
salarys = []
for i in range(4):
s = input("请输入一共4名员工的薪资(按Q或q中途结束)")
if s.upper()=='Q':
print("录入完成,退出")
break
if float(s)<0:
continue
salarys.append(float(s))
salarySum += float(s)
else:
print("您已经全部录入4名员工的薪资")
print("录入薪资:",salarys)
print("平均薪资{0}".format(salarySum/4))
实时效果反馈
1. 循环结构中,else的作用是:
A 碰到break语句,则会执行else子句
B 无论有无continue,一定会执行else子句
C 无论有无break,一定会执行else子句
D 如果for、while语句没有被break语句结束,则会执行else子 句,否则不执行
循环代码优化
虽然计算机越来越快,空间也越来越大,我们仍然要在性能问题上 “斤斤计较”。编写循环时,遵守下面三个原则可以大大提高运行效率,避免不必要的低效计算:
1 尽量减少循环内部不必要的计算
2 嵌套循环中,尽量减少内层循环的计算,尽可能向外提
3 局部变量查询较快,尽量使用局部变量
#循环代码优化测试
import time
start = time.time()
for i in range(1000):
result = []
for m in range(10000):
c = i * 1000 #提到外部循环
#result = result + [m * 100] #不使用拼接,会产生大量新对象
result.append(c+m*100)
end = time.time()
print("耗时:{0}".format((end-start)))
print("简单循环优化后...")
start2 = time.time()
for i in range(1000):
result = []
c = i*1000
for m in range(10000):
result.append(c+m*100)
end2 = time.time()
print("耗时:{0}".format((end2-start2)))其他优化手段
1 连接多个字符串,使用join()而不使用+
2 列表进行元素插入和删除,尽量在列表尾部操作
实时效果反馈
1. 编写循环时,代码优化规则说法错误的是:
A 嵌套循环中,尽量减少内层循环的计算,尽可能向外提
B 局部变量查询较快,尽量使用局部变量
C 连接多个列表,使用+而不使用join()
D 列表进行元素插入和删除,尽量在列表尾部操作
使用zip()并行迭代多个序列
我们可以通过zip()函数对多个序列进行并行迭代,zip()函数在最短 序列“用完”时就会停止。
【操作】测试zip()并行迭代
names = ("高童","高老二","高老三","高老四")
ages = (18,16,20,25)
jobs = ("老师","程序员","公务员")
for name,age,job in zip(names,ages,jobs):
print("{0}--{1}--{2}".format(name,age,job))#不适用zip,也可以并行迭代多个序列
for i in range(min(len(names),len(ages),len(jobs))):
print("{0}--{1}--{2}".format(names[i],ages[i],jobs[i]))
执行结果:
高童--18--老师
高老二--16--程序员
高老三--20--公务员