万丈高楼,平地起。
计算机世界的信息化软件工程,是构筑于计算机硬件之上的。
由于信息的流转依托于计算机不同的部件,所以计算机系统的内部设计、各类应用架构无不受部件之间速度差异的影响。
本文,主要先介绍存储体系,再量化展示这种速度的差异,最后简单说一下对上层系统的影响。你就理解为什么用了缓存,会快~~
计算机存储体系
如图,从下到上,单位金钱获得的容量组件减少,但是响应的速度增大。
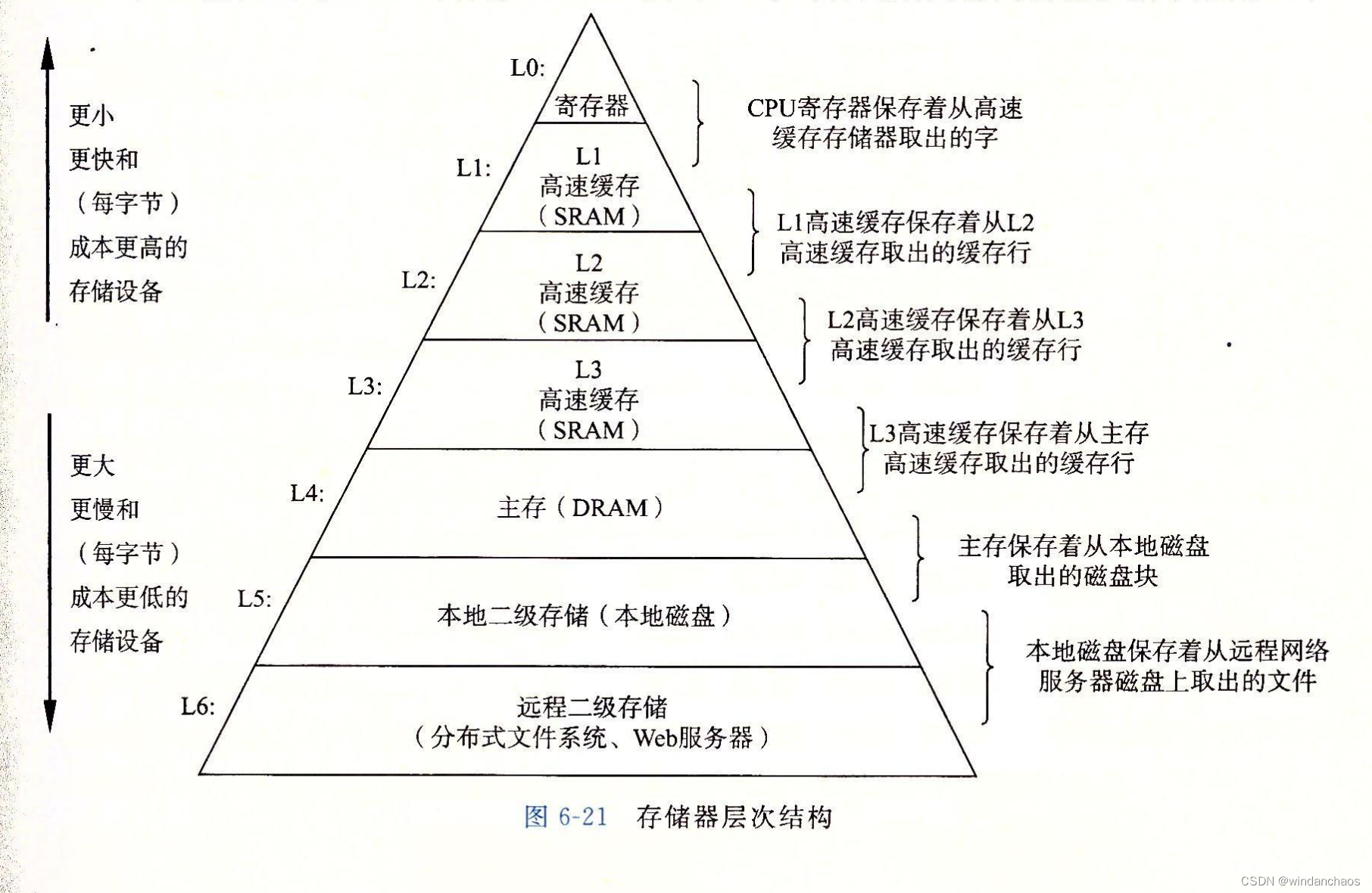
图:《深入理解计算机系统》
计算机各层次速度量化
存储体系代表了层级,是大的方向。具体落实到机器的速度,我们还要看具体指标和数值,以作参考。具体硬件的速度自然不是下表所示的值,所以最多算个示意,但内部的相对关系还是比较稳定的。
| 序号 | 存储英文名称 | 存储中文名称 | 容量 | 时间(纳秒) | 微秒 | 毫秒 | CPU时钟周期数 |
|---|---|---|---|---|---|---|---|
| 1 | CPU寄存器 | CPU寄存器 | 几十~几百KB | 0.5 | 1 | ||
| 2 | L1 cache reference | 读取CPU一级缓存 | 几十~几百KB | 0.5 | 1 | ||
| 3 | Branch mispredict | (转移、分支预测) 比如:if | 5 | 10 | |||
| 4 | L2 cache reference | 读取CPU的二级缓存 | 几百KB~几MB | 7 | 14 | ||
| 5 | Mutex lock/unlock | 互斥锁\解锁 | 25 | 50 | |||
| 6 | Main memory reference | 内存引用(找到内存地址) | 几百MB~几GB | 100 | 0.1 | 200 | |
| 7 | Compress 1K bytes with Zippy | 使用Zippy压缩1K字节数据 | 3000 | 3 | 6000 | ||
| 8 | Send 1K bytes over 1 Gbps network | 在1Gbps的网络上发送1k字节 | 10,000 | 10 | 0.01 | 40000 | |
| 9 | Read 4K randomly from SSD | SSD磁盘随机读4k | 150,000 | 150 | 0.15 | 300,000 | |
| 10 | Read 1 MB sequentially from memory | 从内存顺序读取1MB | 250,000 | 250 | 0.25 | 500000 | |
| 11 | Round trip within same datacenter | 从一个数据中心往返一次,ping一下 | 500,000 | 500 | 0.5 | 1000,000 | |
| 12 | Disk seek | 磁盘搜索 | 几百GB~几TB | 10,000,000 | 10,000 | 1 | 20,000,000 |
| 13 | Read 1 MB sequentially from network | 从网络上顺序读取1兆的数据 | 10,000,000 | 10,000 | 1 | 20,000,000 | |
| 14 | Read 1 MB sequentially from SSD | 从SSD磁盘顺序读出1MB | 30,000,000 | 30,000 | 3 | 60,000,000 | |
| 15 | Send packet CA->Netherlands->CA | 一个包的一次远程访问 | 150,000,000 | 150,000 | 15 | 300,000,000 |
表引自(有大的修改):https://gist.github.com/jboner/2841832
寄存器速度等于CPU时钟周期,表假设CPU的1次晶振频率0.5纳秒,对应CPU2.0GHz。
上表的主要价值在于:站在CPU时钟周期的角度来度量,各个部件之间的速度差距具体大到什么程度。
上表格,对机械磁盘的顺序读写及随机读写性能,以及SSD硬盘的顺序读写、随机读写性能,没有给出直观的数据。
业内,顺序读写性能使用容量/s来度量,随机读写性能使用IOPS(Input/Output Operations Per Second)度量。
例如SATA或M.2 SATA接口的顺序读写速度理论上可达600MB/s,而使用支持NVMe协议的M.2接口、走PCIE4.0×4通道的固态硬盘,其顺序读取速度可达7G/s。
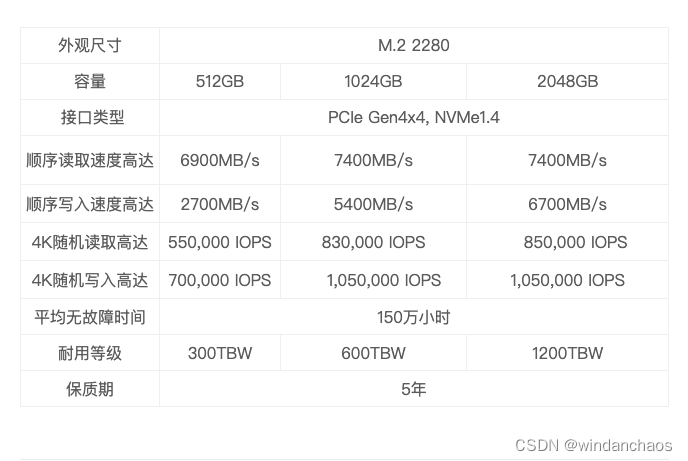
下图是国产致态 TiPro7000固态硬盘的技术指标(存储国产已崛起):
CPU内部寄存器速度和DRAM内存的速度差异来源
制造工艺和成本决定。CPU内部的寄存器使用的SRAM工艺,是6个晶体管电路原件组成的,不需要刷电,频率等同CPU时钟。而DRAM内存就没那么复杂的晶体管了,造价合适,需要定期刷电(刷新)维持存储数据,这里就消耗了大量时间,是性价比的妥协。具体可见DRAM和SRAM的区别
计算机存储结构速度差异对上层应用的影响
核心就一句话:运用时间和空间局部性原理,上一层级做下一层级的缓存。上一层没有,再去下一层拿。
所谓时间和空间局部性原理,意思就是最近使用和访问的地址及附近地址空间,大概率还会被使用。先留一份在这一层,下次再用的时候,就不用取了。
可参考:缓存技术原理
下面说几个大家可能都知道缓存场景。
客户端访问服务器,网络io的耗时是很慢的,提速有什么方案?直接把数据存在用户本地一份。背后原理是什么?读取本地磁盘耗时,比网络耗时短。
为什么很多高并发场景要加redis缓存,大家都知道redis在内存里,很快。但是有多快?上表访存200 比60,000,000,当然这里面一个是寻址,一个是读1M,没可比性。内存通常的传输速率是以G/s为单位的,比如DDR4内存读写速度大概50G每秒(50000M),固态硬盘读肯定走的是随机读,按致钛最低速度来550000 * 4k / 1024 = 2148M/s,速度差距的数量级在20倍附近,这只是理论值,实际当中有偏差,而且也不可能每一个读取单元都是4k,所以基本可以估计是10-100这个量级的速度差。
再一个CPU内部的L1 2 3级缓存的作用。
再来一个,mysql的主从复制为什么能支持实际的场景,无他,顺序读,顺序写,秒级量完全够来自网卡的流量。
又比如,磁盘内部,也存在缓存这一硬件,目的就是增强磁盘的吞吐。