(个人学习使用)
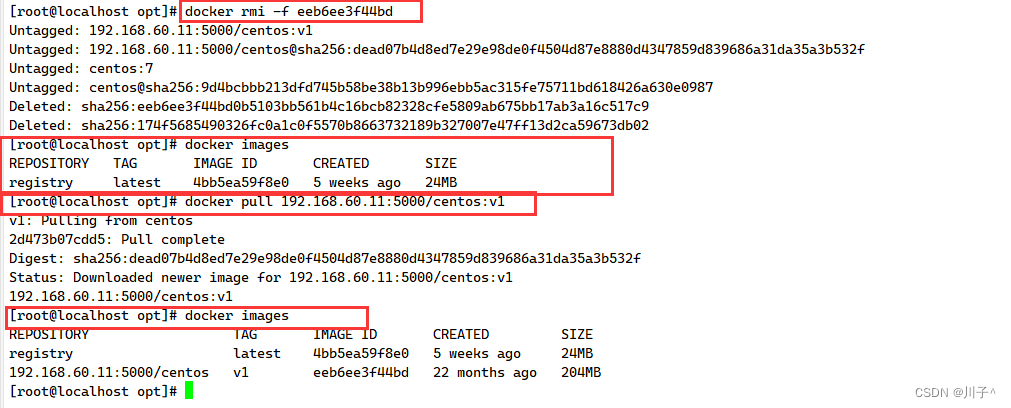
添加索引
# index是行索引,columns是列索引
pd.DataFrame(score, index=idx, columns=col)常用属性和方法
data.shape # 形状
data.index # 行索引
data.columns # 列索引
data.values # 里面的值,结果是ndarray类型数组
data.T # 进行转置
data.head(n) # 默认查看前5行的内容
data.tail(n) # 默认查看后5行索引的修改
# 修改索引
data.index = new # 必须整体修改索引,不能单独修改其中一个索引
# 重设索引
data.reset_index(drop=False) # 不写默认参数为False,及是否删除之前的索引,
# 修改新索引
data.set_index('第一天',drop=True) # 不写默认为True,及把'第一天'多为索引时,是否删除原来的'第一天'series属性方法
sr = data.iloc[1, :]
第0天 -1.272936
第1天 -0.042801
第2天 0.872491
第3天 1.688880
第4天 -0.374057
第5天 0.728194
第6天 -0.978928
第7天 0.639998
Name: 股票1, dtype: float64
sr.values # 获取值
array([-1.27293566, -0.04280051, 0.87249129, 1.6888803 , -0.37405686,
0.72819427, -0.97892826, 0.63999758])
sr.index # 获取索引值
Index(['第0天', '第1天', '第2天', '第3天', '第4天', '第5天', '第6天', '第7天'],
dtype='object')data.drop(['索引名字'], axis=0/1) # 删除某些列或者行
# 默认axis是按照行删除,所以删除时最好写上是删除行还是删除列dataframe的索引
data['列索引']['行索引'] # 注意一定是先进行列索引再进行索引 第0天 第1天 第2天 第3天 第4天 第5天 第6天 第7天
股票0 1.046882 -0.845770 1.030718 -0.992464 0.202662 0.733066 0.443001 -1.231117
股票1 -1.272936 -0.042801 0.872491 1.688880 -0.374057 0.728194 -0.978928 0.639998
股票2 -1.985832 -0.949589 -0.263581 -1.410954 0.638578 -0.401807 -0.798711 -0.070448
股票3 0.069881 0.375395 -2.242167 0.307771 0.040234 -0.097090 -1.822728 0.224412
股票4 1.648151 -1.100749 -0.946982 0.831372 -0.706177 1.475654 -0.397543 1.545838
# 按照 索引名字 进行索引
data.loc['行名','列名'] # 索引某个值
data.loc[:, :] # 索引一段值
data.loc[['股票0','股票2'], ['第1天','第3天']] # 直接使用列表
# 按照 下标 进行索引
data.iloc[1,2] # 索引某个值
data.iloc[:, :] # 索引一段值
data.iloc[[0,2],[1,2]] # 直接使用列表data.index[0:4] # 获取行索引
Index(['股票0', '股票1', '股票2', '股票3'], dtype='object')
data.columns.get_indexer(['第1天','第2天']) # 获取列索引的下标
array([1, 2], dtype=int64)dataframe值排序
data.sort_values(by=['',''], ascending=True/False)
# by后边是按照什么属性进行排序,可以是多个属性。 默认是从小到大排序,dataframe按索引排序
data.sort_index() # 将索引按照顺序排序series的值排序和索引排序
# series可以是按行取出来的,也可以是按列取出来的
data['股票0'].sort_values(ascending=) # 对值进行排序
data.iloc[1, :].sort_index(ascending=) # 对索引进行排序算数运算,逻辑运算
# 主要使用函数有
# describe,sum,prod,median,mode,abs,max,min,mean,var,std,div
# idxmin,idxmax,isin,query,add,sub,apply
# 累计统计函数
# cumsum,cummax,cummin,cumprod
# dataframe和series一样也可以直接使用+-*/运算符
# dataframe可以直接使用<,>,|,&逻辑运算符,返回布尔值
data.add(n)
data.sub(n)
# 布尔索引
data[data['a']>0]
data[(data['a']>0 & data['b']<0)]
data.query("a>0 & b<0") # 与上面的布尔索引效果一样,括号里填入查询条件
data.isin([a,b,c]) # 返回的是布尔值,满足括号里的值的返回True
data.describe() # 返回对data数据的基础统计
# count,mena,std,min,25%,50%,75%,max
# 自定义运算 apply(func, axis=)
data.apply(lambda x:x.max()-x.min(), axis=0)
pandas画图
data.plot(x="a", y="b", kind="scatter") # 还有stacked参数,是否堆叠
# x是横坐标属性,y是纵坐标属性,
# kind是图形的类型
line 折线图
bar 柱状图
barth 水平柱状图
hist 直方图
pie 饼图
scatter 散点图pandas读写文件
# 常用读取文件函数及参数
pd.read_csv(path, usecols=[想读取哪些列], header=None, names=[没有列属性时指定列属性名字])
# 文件中没有列属性时使用header=None,或者使用names=[]来指定列属性名字
pd.to_csv(path,culomns=[想写入的列],index=,header=,mode=)
# index=False 写入时不把行索引写入
# header=False 写入时不把列索引写入
# mode='' 写入的模式,w,a等
pd.read_json(path, orient="records", lines=True)
# orient="recordes" 将数据存储成记录的形式
# lines=True 按行读取
pd.to_json(path, orient="records", lines=True)缺失值处理
# 表示空值的方法
pd.NA np.NaN None float('nan')# 判断是否有缺失值
data.isnull()
data.notnull()
pd.isnull(data)
pd.notnull(data)
# 上述两种方法都行
## 是np.nan类型的缺失值处理
# 删除缺失值
data.dropna(inplace= , axis=)
# inplace=True/False 来决定是否再原来的数据上直接进行删除
# axis=0/1 行删除还是列删除
# 填补缺失值
data.fillna(value, inplace=)
# value是要将缺失值替换成的数据
# inplace同缺失值的处理
## 是?或者等别的标记来代替缺失值的处理
# 1.先将标记替换成np.nan
# 2.再进行处理
data.replace(to_replace='标记符号', value=np.nan)
# 替换函数,参数名字也可以不写直接写成data.replace('标记符号', np.nan)
数据离散化
# 数据分组
pd.qcut(data, n)
pd.cut(data, [])
# 自动分组
pd.qcut(data, n, labels=[分组后的标签])
一般使用
pd.qcut(data, n)
# data是要分组的数据,n是分成几组
# 自定义分组
pd.cut(data, [分组的间隔], labels=[])
# pd.cut(data, [1,3,6,9]) 及分成三个组# one-hot编码,将非数字类型的数据转换成数字类型的,
pd.get_dummies(data, prefix="")
#
性别 年龄
0 男 12
1 男 13
2 女 89
pd.get_dummies(dt, prefix="age") # prefix是前缀,可不写
年龄 age_女 age_男
0 12 0 1
1 13 0 1
2 89 1 0dataframe合并
# 合并 pd.concat()
pd.concat([a,b], axis=)
# (a,b)需要合并的数据,axis按照什么方向# 连接 pd.merge(a, b, how="", on=[])
pd.merge(d1, d2, how="inner", on=['k1', 'k2'])
# d1 数据1,d2 数据2,
# how是使用什么方式连接 left, right, outer, inner
# on是通过什么字段来连接



交叉表与透视表
# 交叉表 pd.crosstab()
pd.crosstab(value1, value2)
# 透视表 data.pivot_table()
Month Product Sales Quantity
0 1 A 100 10
1 1 B 200 20
2 2 A 150 15
3 2 B 250 25
4 3 A 120 12
5 3 B 180 18
data.pivot_table(['Sales'], index=['Month'], columns='Product', aggfunc='mean')
# aggfunc参数名字也可以省略不写,直接写'mean'
# 某些列按照index的列进行分组
Product A B
Month
1 100 200
2 150 250
3 120 180dataframe的分组与聚合
# data.groupby([按照什么分组], as_index=) 是否将设置为索引,默认是False
ca va qu
0 A 1 10
1 A 2 20
2 B 3 30
3 B 4 40
4 C 5 50
5 C 6 60
# 返回的是迭代器,所以不能直接看结果,要使用聚合函数后才能看到结果
data.groupby(['ca'])['va']max()
data['va'].groupby(data['ca']).max()
# 上面两个效果一样
# 可以使用get_group()来查看某个分组的数据
data.groupby(['ca']).get_group('A')
ca va qu
0 A 1 10
1 A 2 20
# 因为返回的是迭代器,所以想要看到数据可以使用for
# 迭代器中有两个变量,一个是按照分组的名字,一个是数据
s = data.groupby(['ca'])['va']max()
for name,data in s:
print(name)
print(data)
ca va qu
0 A 1 10
1 A 2 20
ca va qu
2 B 3 30
3 B 4 40
ca va qu
4 C 5 50
5 C 6 60# 常用聚合函数
count(): 计算每个分组中非缺失值的数量。
sum(): 计算每个分组中数值列的总和。
mean(): 计算每个分组中数值列的均值。
median(): 计算每个分组中数值列的中位数。
min(): 计算每个分组中数值列的最小值。
max(): 计算每个分组中数值列的最大值。
std(): 计算每个分组中数值列的标准差。
var(): 计算每个分组中数值列的方差。
agg(): 自定义聚合函数,可以传递一个或多个函数进行聚合操作。
apply(): 对每个分组应用自定义函数进行聚合操作。
# agg(['min','max','mean']) 就是可以使用多个聚合函数
data.groupby(['sex'])['age'].agg(['min','max','mean'])
# 根据性别分组,算年龄的最小值,最大值,平均值