全文索引
MySQL全文索引是一种用于快速搜索文本字符串的索引,在MySQL数据库中,它可以用来提高文本搜索的效率。全文索引不同于普通索引,普通索引只是对列值进行排序,而全文索引则会对列的内容进行分词,并且对每个分词建立索引,从而可以在文本中进行模糊搜索、部分匹配和多词搜索等操作。
创建全文索引的语法
创建全文索引的语法如下:
CREATE FULLTEXT INDEX index_name
ON table_name (column_name)
[WITH PARSER parser_name]
其中,index_name是要创建的索引的名称,table_name是要创建索引的表的名称,column_name是要在其中创建索引的列的名称。WITH PARSER子句是可选的,并且可以用于指定在创建索引时要使用的解析器。
全文索引只能用于CHAR、VARCHAR、TEXT和BLOB类型的字段。此外,在MySQL 5.6版本以前,全文索引只支持MyISAM存储引擎,而在MySQL 5.6版本以后,InnoDB存储引擎也支持全文索引。
使用全文索引进行查询
创建全文索引后,可以使用MATCH AGAINST语句来执行全文搜索查询。
SELECT * FROM table_name WHERE MATCH(column_name) AGAINST('keyword');
ngram解析器
内置的FULLTEXT解析器通过查找特定的分隔符来确定单词的开始和结束位置;例如:(空格),(逗号),和.(点号)。如果单词之间没有分隔符(例如中文),则内置的FULLTEXT解析器无法确定单词的开始或结束位置。
我们可以使用ngram解析器插件(用于中文、日文或韩文)或MeCab解析器插件(用于日文)创建FULLTEXT索引。
ngram是给定文本序列中n个字符的连续序列。ngram解析器将文本序列标记为连续的n个字符序列。例如,您可以使用ngram全文解析器将“abcd”标记为不同的n值。
n=1: 'a', 'b', 'c', 'd'
n=2: 'ab', 'bc', 'cd'
n=3: 'abc', 'bcd'
n=4: 'abcd'
这里的n事实上是ngram指定的令牌大小(token size),Ngram令牌大小可以使用ngram_token_size配置选项进行配置,该选项的最小值为1,最大值为10。
需要注意的是:
-
1.修改ngram_token_size需要重启mysql服务器。
-
2.修改了ngram_token_size之后,我们需要重建fulltext索引,一般我们采用删了重加的方式重建。
-
3.对于使用ngram解析器的FULLTEXT索引,忽略以下最小和最大字长配置选项:innodb_ft_min_token_size, innodb_ft_max_token_size, ft_min_word_len和ft_max_word_len。这些参数分别是innodb、myIsam引擎在使用非ngram分词时对应的设置令牌大小的参数。
ngram_token_size设置为要搜索的最大令牌的大小。如果我们需要只搜索单个字符,请将ngram_token_size设置为1。
比如我们要使用全文索引,查询name字段中包含“刘”字的记录。
创建使用ngram分词的全文索引:
alter table `user` add fulltext index idx_name (name) with parser ngram
使用Match Against语法进行查询:
SELECT * FROM `uuc_business_user` where MATCH(name) AGAINST('刘')
需要注意的是,我是使用单个汉字(刘)进行查询的,这个时候如果想要查询到结果,需要将ngram_token_size设置为1,如果ngram_token_size的值是大于1的数,将查询不到任何记录。如果我们要支持搜索单个字符,记住需要将ngram_token_size设置为1。
ngram_token_size设置为1之后,使用大于1个的汉字进行搜索时,mysql会将汉字拆分为多个单个汉字分别进行搜索,然后将结果进行合并。
比如使用 MATCH(name) AGAINST('刘娅')进行查询时,得到的结果,会如下所示:
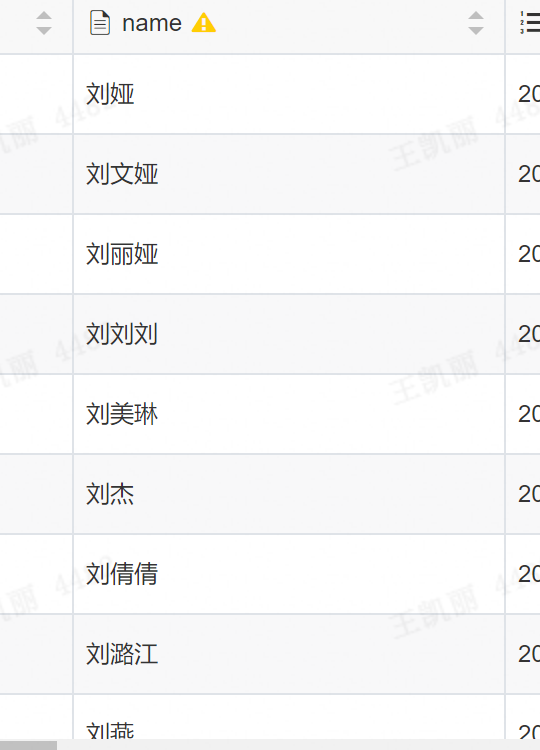
如果想要查询结果,同时包含“刘”和“娅”,可以使用如下语法进行查询:
SELECT * FROM uuc_business_user WHERE MATCH (name) AGAINST ('"刘娅"' IN BOOLEAN MODE);
上面的语句中使用了布尔模式,包含在双引号内的搜索词语“刘娅”被看作一个短语,表示必须同时包含这两个词语,即只有完全匹配“刘娅”这个词语的文档才会被返回。在布尔模式下,使用双引号括起来的搜索词语表示一个短语,这个短语必须完全匹配才能返回结果。因此,这个查询只会返回包含完整短语“刘娅”的文档,不会返回包含“刘”和“娅”这两个词语的文档。
而如果不加in BOOLEAN MODE,则默认是使用了自然语言模式,MySQL会使用内置的自然语言处理技术对搜索查询进行分词和停用词处理,并根据每个词语在文档中的重要性对文档进行打分。在自然语言模式下,使用双引号括起来的搜索词语表示一个短语,但并不要求这个短语必须完全匹配。因此,这个查询将返回包含“刘”和“娅”这两个词语的文档,不一定是完全匹配“刘娅”这个短语的文档。
自然模式和布尔模式
在MySQL中,全文搜索支持两种主要的查询模式:自然语言模式和布尔模式。这两种模式的主要区别在于它们如何处理搜索查询和返回结果。
自然模式 (IN NATURAL LANGUAGE MODE)
全文搜索中的自然语言模式是默认模式,它使用自然语言处理技术来解析搜索查询并返回最相关的结果。自然语言模式会对搜索查询进行分词和停用词处理,并根据每个词语在文档中的重要性对文档进行打分。然后,MySQL会根据文档的得分对搜索结果进行排序,并返回最相关的文档。
例如,以下查询将在自然语言模式下搜索包含“刘”和“娅”的文档,并按照相关性进行排序:
SELECT * FROM users
WHERE MATCH(name) AGAINST('刘 娅' IN NATURAL LANGUAGE MODE);
布尔模式(IN BOOLEAN MODE)
全文搜索中的布尔模式允许用户使用布尔运算符(AND、OR、NOT) 来组合搜索条件,并通过对文档进行匹配来确定文档是否符合查询条件。在布尔模式下,MySQL会将搜索查询视为布尔表达式,并使用布尔运算符来确定每个文档是否符合查询条件。
例如,以下查询将在布尔模式下搜索包含“刘”和“娅”的文档:
SELECT * FROM users
WHERE MATCH(name) AGAINST('+刘 +娅' IN BOOLEAN MODE);
在布尔模式下,“+”符号表示必须包含该词语,“-”符号表示不包含该词语,“|”符号表示或者。这个查询将返回包含“apple”和“iphone”两个词语的文档。
需要注意的是,自然语言模式和布尔模式都有各自的优点和缺点。自然语言模式通常更易于使用和理解,但可能会导致一些不准确的结果。布尔模式更灵活,可以更精确地控制搜索条件,但需要更多的查询语法知识。在使用全文搜索时,应根据具体情况选择合适的查询模式。
全文索引与 like "%%"
全文索引和LIKE "%%"是两个不同的文本搜索方法,它们在实现和性能上有很大的差异。
全文索引是一种特殊类型的索引,用于对文本字段进行全文搜索,它可以支持模糊搜索、部分匹配和多词搜索等操作。全文索引可以显著提高文本搜索的性能和效率,特别是在处理大量文本数据时。
与此不同,LIKE "%%"是一种基于通配符的模式匹配操作,可以在文本字段中查找包含指定字符串的记录。但是,LIKE "%%"操作通常会导致全表扫描,并且性能较低,特别是在处理大量数据时。
因此,全文索引通常比LIKE "%%"操作更快、更有效。在需要对文本字段进行搜索时,应该尽量使用全文索引,而不是LIKE "%%"操作,以获得更好的查询性能和效率
总结
mysql使用全文索引来提高文本搜索的效率。我们可以使用FULLTEXT关键字来声明一个全文索引列,创建全文索引后,可以使用MATCH AGAINST语句来执行全文搜索查询。 我们需要使用ngram分词器来支持中文全文搜索。ngram_token_size用来指定令牌大小。全文搜索支持两种主要的查询模式:自然语言模式和布尔模式,自然语言模式通常更易于使用和理解,但可能会导致一些不准确的结果。布尔模式更灵活,可以更精确地控制搜索条件,但需要更多的查询语法知识。
参考: https://dev.mysql.com/doc/refman/8.0/en/fulltext-fine-tuning.html
![]()
点个“赞 or 在看” 你最好看!
喜欢,就关注我吧!