以下内容来自 尚硅谷,写这一系列的文章,主要是为了方便后续自己的查看,不用带着个PDF找来找去的,太麻烦!
第 7 章 FLUX查询InfluxDB
7.1 前言
1、本节内容较为重要
7.2 FLUX查询InfluxDB的语法
1、使用FLUX语言查询InfluxDB,必须以from -> range打头。range必须紧跟在from后面,不这么写的话会直接报错。
2、例如:
from(bucket: "test_init")
|> range(start: - 1 h)
7.3 表、表流以及序列
1、我们知道InfluxDB是使用序列的方式去管理数据的。而FLUX语言又企图兼容一些关系型数据库的查询,而关系型数据库里的数据结构就是一个有行有列的 table。因此对于FLUX语言来说,就需要将序列和表统一成一个东西。所以FLUX引入了表流的概念。简单来说,FLUX可以一次性查出多个序列,这个时候一个序列对应一张表,而表流其实就是多张表的集合。同时表流和表的关系其实是全表和子表的关系,子表是全表按照_field,tag_set和_measurement进行group by之后的结果。在这种情况下,如果调用聚合函数,其实只会在子表中进行聚合。
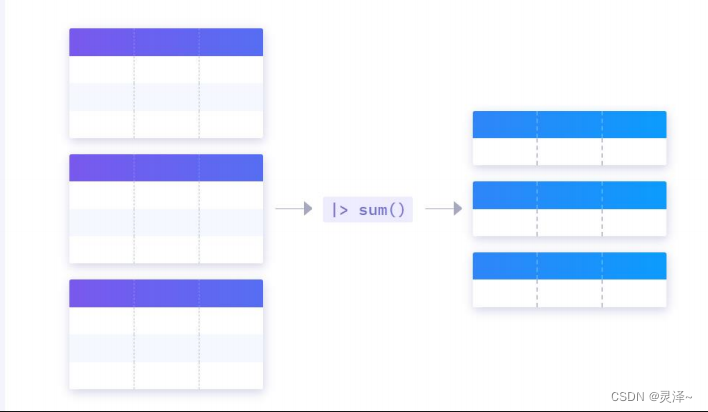
2、最后,如果一张表对应的是一个序列了,那么一张表里的一行其实就对应着序列中的一个数据点了。
7.4 filter维度过滤
1、使用filert函数可以对数据按照_measurement、标签集和字段级进行过滤,后面的课程会给大家讲解filter的性能问题。
7.5 类型转换函数与下划线字段
1、Flux语言中有很多不用指定字段名称的管道函数,比如toInt()。其实toInt()这个函数默认要求你的字段中必须要有_value字段,没有_value字段的话也会直接报错。
2、其实在我们查询出来的数据中,以下划线开头的字段其实代表了一种约定,就是FLUX中有很多函数想要正常运行时要依赖于这些下划线打头的字段的。所以原则上来说,程序员应该遵守这些约定,不要擅自更改下划线开头的字段。
7.6 map函数
1、map函数的作用是遍历表流中的每一条数据。
2、示例:
import "array"
a rray.from(rows: [{"name":"tony"},{"name":"jack"}]) |> map(fn: (r)=> {
return if r["name"] == "tony" then {"_name": "tony不是jack"} else {"_name":"jack不是tony"}
})
3、这里需要注意,map函数需要我们传递一个参数 fn,它要求传递一个单个参数输入,且输出必须是record的函数,其中输入数据的类型会是record。
7.7 自定义管道函数
1、此处,我们定义一个管道函数,它可以将表流中的_value字段的值乘上x倍。大家在接下来的示例中注意声明管道函数时所用的语法。
big100 = (table=<-,x) => {
return table |> map(fn: (r) => ({ (^) r with "_value":r["_value"]*x}))}接下来我们调用刚才声明的函数,最终整个脚本如下:big 100 = (table=<return table - ,x) => {|> map(fn: (r) => ({r with "_value":r["_value"]*x}))
}
from(bucket: "test_init")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "go_goroutines")
|> big100(x:100.00)
2、可以自行运行查看函数效果。这里需要强调的是,管道函数的第一个参数必须写成table=<-,它表示通过管道符输入进来的表流数据,需要注意,table并不一定写成table但是=<-的格式绝对不能变。
7.8 在文档中区分管道函数和普通函数
1、再次来到函数文档。
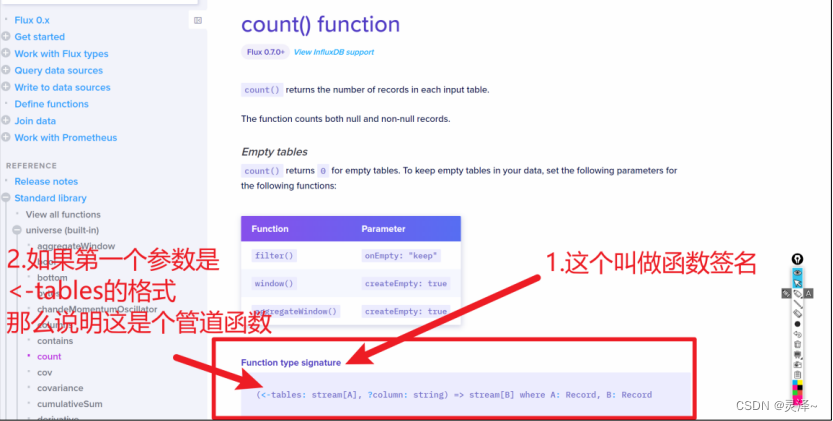
2、当我们看到一个函数文档,它会有一个区域叫做Function type Signature(函数签名),它表示着函数接收哪些参数以及会返回什么。最前面的小括号里的内容就是参数列表,如果参数列表的第一个参数是<-tables: stream[A],那就表示它是一个可以接收表流输入的管道函数。反之,如果没有<-tables: stream[A],那么它就是一个普通函数。
7.9 window和aggregateWindow函数
1、window函数和aggregateWindow函数其实代表着InfluxDB中的两种开窗方式,两者不同的地方在于,window函数会将整个表流重新分组。window开窗后,是按照序列+窗口的方式对整个表流进行分组。但是 aggregateWindow函数会保留原来的分组方式,这样一来,使用aggregateWindow函数进行开窗后的表流,仍然是按照序列的方式来分组的。
7.10 yield和join
1、当flux脚本中出现未被赋值给某个变量的表流时,InfluxDB执行FLUX脚本时会自动帮他们在管道的最后面加上|> yield(name: “_result”)函数,yield函数其实是指定了我们当前这个表流是整个 FLUX脚本最后返回的结果,而且这个结果的名字叫"_result"。当FLUX脚本中出现多个为赋值给变量的表流时,给多个表流自动补上|>yield(name:“_result”)就会出问题了,这是因为当有多个表流后面都有|>yield时,其实相当于一个FLUX脚本会返回多个结果。但是此处要求名称是不能重复的,所以当有多个未赋值的表流时,就必须显示指定yield(name:“xxx”),而且名称千万不可重复。
2、但是,在一个FLUX脚本里同时返回多个结果集并不是推荐的操作,这通常会让程序的逻辑变的很奇怪,我们之所以能在一个FLUX脚本里面写多次from函数,其实是为了方便我们进行join的。
3、再但是,我并不建议在FLUX脚本中使用join操作,这必须要谈到FLUX脚本的常见使用场景,就是每隔一段时间进行一次查询。如果这个时候,我用一个from从InfluxDB中查询数据,其中有code=01等机器编号信息。然后我再用一个from去查询mysql,得到一张机器的属性表。接下来对两张表进行 join,这在逻辑上很合理,但最大的问题就是FLUX脚本无法实现数据的缓存。如果我这个FLUX脚本是每 15 秒执行一次,那就会导致我们需要每 15 秒要去mysql上全表扫描一遍机器信息表,效率十分低下。
4、个人建议仅使用FLUX进行简单的查询,然后在应用层的程序里进行join操作。因此,本系列文章并不讲解FLUX语言的join操作。