Java基础教程之IO操作 · 中
- 🔹本节学习目标
- 1️⃣ 转换流
- 2️⃣ 案例:文件复制
- 3️⃣ 字符编码
- 4️⃣ 内存流
- 5️⃣ 打印流
- 5.1 打印流设计思想——装饰设计模式
- 5.2 打印流
- 5.3 PrintStream 类的改进
- 🌾 总结

🔹本节学习目标
- 掌握内存操作流、转换流、打印流的使用;
- 掌握文件复制操作;
- 掌握字符的主要编码类型以及乱码问题产生的原因;
1️⃣ 转换流
虽然字节流与字符流表示两种不同的数据流操作,但是这两种流彼此间是可以实现互相转换的,而要实现这样的转换可以通过 InputStreamReader、OutputStreamWriter 两个类。首先介绍这两个类的继承结构以及构造方法。
| 名称 | InputStreamReader | OutputStreamWriter |
|---|---|---|
| 定义结构 | public class InputStreamReader extends Reader | public class OutputStreamWriter extends Writer |
| 构造方法 | public InputStreamReader(InputStream in) | public OutputStreamWriter(OutputStream out) |
可以发现:
InputStreamReader类的构造方法中接收InputStream类的对象,而InputStreamReader是Reader的子类,该类对象可以直接向上转型为Reader类对象,这样就表示可以将接收到的字节输入流转换为字符输入流;OutputStreamWriter类的构造方法接收OutputStream类的对象,而OutputStreamWriter是Writer的子类,该类对象可以直接向上转型为Writer类对象,这样就表示可以将接收到的字节输出流转换为字符输出流,Writer类中也提供了直接输出字符串的操作。
// 范例 1: 实现输出流转换
package com.xiaoshan.demo;
import java.io.File;
import java.io.FileOutputStream;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
import java.io.Writer;
public class TestDemo {
public static void main(String[] args) throws Exception{
File file = new File("d:" + File.separator + "demo" + File.separator + "xiaoshan.txt"); //1.定义要输出文件的路径
if (!file.getParentFile().exists()){ //判断父路径是否存在
file.getParentFile().mkdirs(); //创建父路径
}
OutputStream output = new FileOutputStream(file); //将OutputStream 类对象传递给OutputStreamWriter类的构造方法而后向上转型为 Writer
Writer out = new OutputStreamWriter(output);
out.write("更多知识请访问:https://lst66.blog.csdn.net"); //Writer 类的方法
out.flush();
out.close();
}
}
运行结果:

此程序利用 OutputStreamWriter 类将字节输出流转换为字符输出流,这样就可以方便地实现字符串数据的输出。
从实际的开发来讲,转换流的使用情况并不多,并且JDK随着版本的提高会扩充越来越多方便的类库,所以这种转换流的意义大部分也只会停留在理论分析上。
通过之前的讲解可以发现,四个流的操作类如果要操作文件都要求分别使用不同的子类(FileXxx)。而 FileOutputStream、FilelnputStream、FileWriter、 FileReader 四个类的继承结构如图所示。
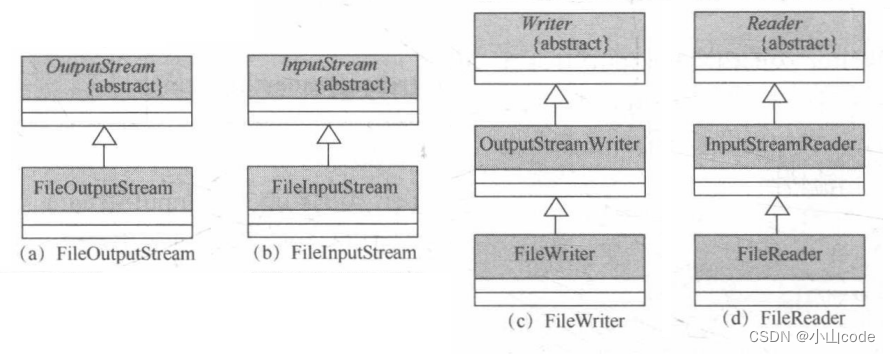
通过继承结构可以发现,FileWriter与 FileReader 都是转换流的子类,也就证明所有要读取的文件数据都是字节数据,所有的字符都是在内存中处理后形成的。
2️⃣ 案例:文件复制
在 命令行工具中,可以利用copy 实现文件的复制操作。此命令的语法为:“copy 源文件路径 目标文件路径”。在文件复制过程中,如果源文件不存在或参数个数不足,都会产生错误,而本案例将模拟copy命令实现一个与之功能相同的程序。
同时对于此部分的程序也属于InputStream与OutputStream的应用总结,并且本处讲解的代码,在实际的开发中也会使用到。
现在要求实现一个文件的复制操作,在复制的过程中利用初始化参数设置复制的源路径与目标路径,同时在本程序执行时可以复制任何文件,例如:图片、视频、文本等。
对于此程序的要求,首先必须确认要使用何种数据流进行操作。由于程序要求可以复制任意类型的文件,所以很明显必须利用字节流 (InputStream、OutputStream) 类完成。而具体的复制操作实现, 有以下两种做法。
(1)做法一:将所有的文件内容先一次性读取到程序中,再一次性输出。这种实现方式有一个缺陷: 如果要读取的文件量过大,就会造成程序的内存崩溃;
(2)做法二:采用边读取边输出的操作方式,每次从源文件输入流中读取部分数据,而后将这部分数据交给输出流输出,这样的做法不会占用较大的内存空间,但是会适当损耗一些时间,当然也可以通过限制文件大小来避免此类问题。
如果要想完成本操作,实际上需要使用InputStream与 OutputStream类的两个操作方法。
InputStream类:public int read(byte[] b) throws IOException,将内容读取到字节数组中,如果没有数据则返回 -1,否则就是读取长度;OutputStream类:public void write(byte[] b, int off, int len) throws IOException,要设置的字节数组实际上就是在read()方法里面使用的数组,数据输出一定是从字节数组的第0个元素开始,输出读取到的数据长度的数据。
在实际的开发中,最常见的是这两个方法的结合使用。
// 范例 2: 实现文件复制操作
package com.xiaoshan.demo;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
public class CopyDemo{
public static void main(String[] args) throws Exception{
long start = System.currentTimeMillis(); //取得复制开始的时间
if (args.length != 2){ //初始化参数不足2位
System.out.println("命令执行错误!");
System.exit(1); //程序退出执行
}
//如果输入参数正确,应该进行源文件有效性的验证
File inFile = new File(args[0]); //第一个为源文件路径
if (!inFile.exists()){ //源文件不存在
System.out.println("源文件不存在,请确认执行路径。");
System.exit(1); //程序退出
}
//如果此时源文件正确,就需要定义输出文件,同时要考虑到输出文件有目录
File outFile = new File(args[1]);
if(!outFile.getParentFile().exists()){ //输出文件路径不存在
outFile.getParentFile().mkdirs(); //创建目录
}
//实现文件内容的复制,分别定义输出流与输入流对象
InputStream input = new FileInputStream(inFile);
OutputStream output = new FileOutputStream(outFile);
int temp = 0; //保存每次读取的数据长度
byte data[] = new byte[1024]; //每次读取1024个字节
//将每次读取进来的数据保存在字节数组里面,并且返回读取的个数
while((temp = input.read(data)) != -1){ //循环读取数据
output.write(data, 0, temp); //输出数组
}
input.close(); //关闭输入流
output.close(); //关闭输出流
long end = System.currentTimeMillis(); //取得操作结束时间
System.out.println("复制所花费的时间:" + (end-start));
}
}
设置初始化参数: java d:\demo\xiaoshan.txt d:\demo\xiaoshan-copy.txt
程序执行结果:
复制所花费的时间:15


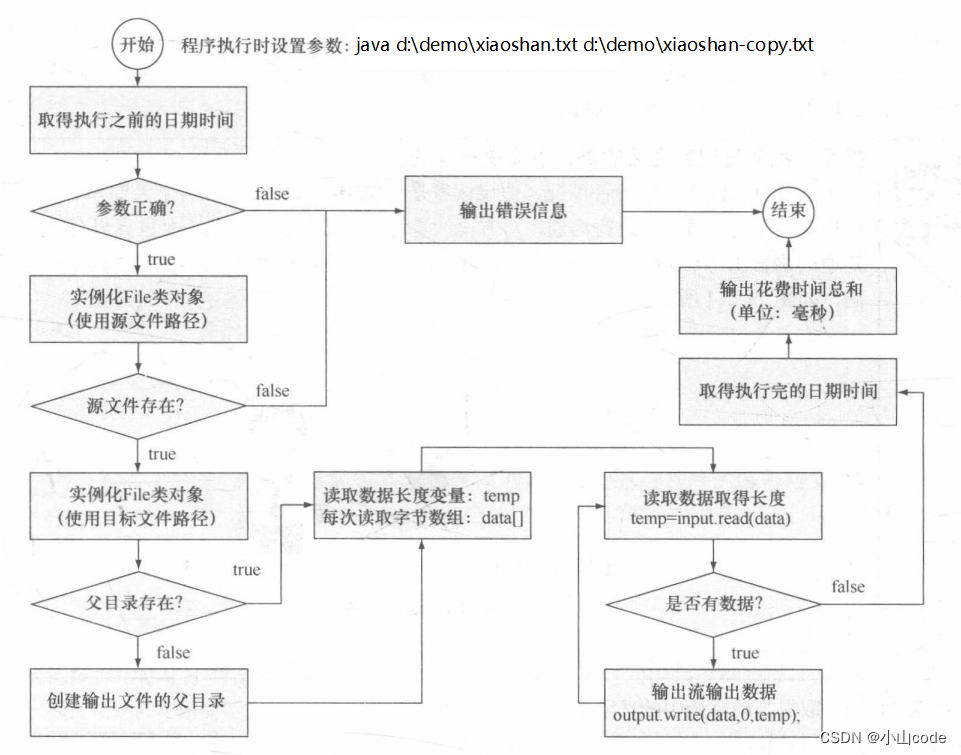
此程序实现了完整的开发要求,同时程序的执行效率较高,整体操作只花费了300毫秒左右的时间。 文件复制程序的流程如下图所示:
3️⃣ 字符编码
计算机中所有信息都是由二进制数据组成的,因此所有能够描述出的中文文字都是经过处理后的结果。在计算机的世界里,所有的语言文字都会使用编码来进行描述,例如:最常见的编码是 ASCⅡ 码。在实际的工作里面最为常见的4种编码如下。
GBK、GB2312:中文的国标编码,其中GBK包含简体中文与繁体中文两种,而GB2312只包含简体中文;ISO8859-1:国际编码,可以描述任何文字信息(中文需要转码);UNICODE:是十六进制编码,但是在传递字符信息时会造成传输的数据较大;UTF 编码 (Unicode Transformation Format):是一种UNICODE的可变长度编码,常见的编码为UTF-8编码。
实际上对于编码问题,在实际的项目开发过程中,往往都会以 UTF-8编码为主,所以在编写代码时建议将文件编码都统一设置为UTF-8的形式。
既然计算机世界中存在这么多编码,在实际项目的开发中就有可能在数据传输中出现编码与解码所使用的字符集不统一的问题,而这样就会产生乱码。我们可以利用 System 类取得当前系统中的环境属性,从而知道当前系统所使用的默认编码。
// 范例 3: 取得当前系统中的环境属性中的文件编码
package com.xiaoshan.demo;
public class TestDemo {
public static void main(String[] args) throws Exception{
System.getProperties().list(System.out); // 列出全部系统属性
}
}
程序执行结果:
file.encoding=GBK
……
此程序的功能是列出全部的系统属性,其中会发现一个"file.encoding" 的属性名称,此属性定义的是文件的默认编码,可以发现编码方式为GBK。
System类中定义的取得系统属性的方法为:public static Properties getProperties(), 此方法返回的是一个 Properties类对象,此类将在后续文章为大家讲解,在此处并不需要关注具体的代码,只需要关注程序的执行结果。
另外在系统属性输出时可以发现存在一个"file.separator=\"的信息,此处描述的就是文件的路径分隔符定义,也就是 File.separator 常量的内容。
因为默认的编码为 GBK, 所以当程序向文件中输出信息时,文件就会使用 GBK 编码,而文件的内容也应该是GBK 编码,此处如果强行修改为其他编码,就会出现乱码。所谓乱码就是指编码与解码字符集不统一所造成的问题。
// 范例 4: 程序出现乱码
package com.xiaoshan.demo;
import java.io.File;
import java.io.FileOutputStream;
import java.io.OutputStream;
public class TestDemo {
public static void main(String[] args) throws Exception{
File file = new File("D:" + File.separator + "小山.txt");
OutputStream output = new FileOutputStream(file);
//强制改变文字的编码,此操作可以通过String类的getBytes(方法实现
output.write("更多文章请访问:https://lst66.blog.csdn.net".getBytes("ISO8859-1"));
output.close();
}
}
在当前系统中默认的编码应该使用 GBK, 但是在程序处理时强制性地 将内容编码转换为了“ISO8859-1”, 这样程序的编码与文件的保存编码就会发生冲突,那么保存后的文件就会出现中文乱码问题,保存后的文件内容如下所示:

4️⃣ 内存流
在流的操作中除了进行文件的输入与输出操作之外,还可以针对内存进行同样的操作。假设某一种应用需要进行 IO 操作,但是又不希望在磁盘上产生一些文件时, 就可以将内存当作一个临时文件进行操作。在 Java 中,针对内存操作提供了以下两组类。
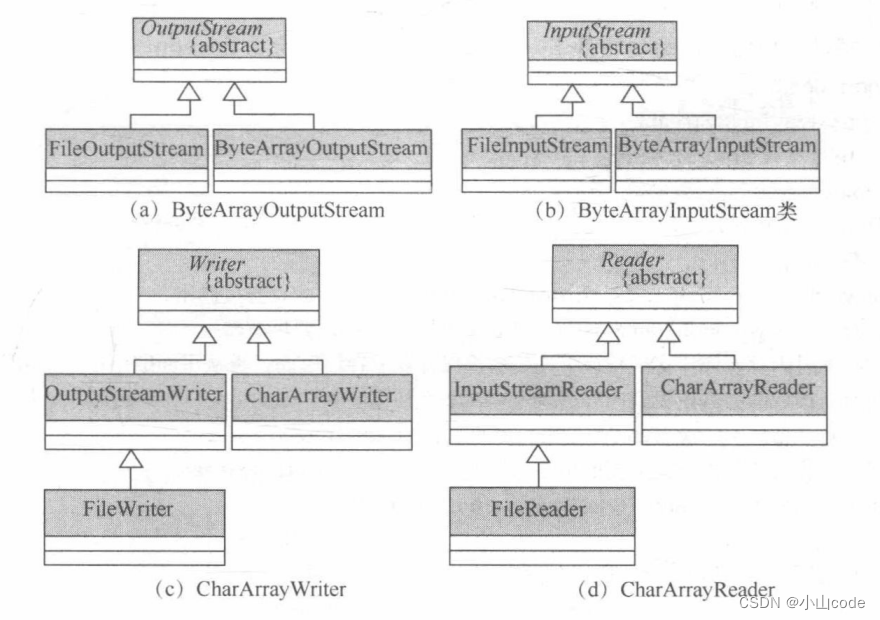
- 字节内存流:
ByteArrayInputStream(内存字节输入流)、ByteArrayOutputStream(内存字节输出流); - 字符内存流:
CharArrayReader(内存字符输入流)、CharArrayWriter(内存字符输出流)。
字节内存流与字符内存流两者唯一的区别就在于操作数据类型上,字节内存流操作使用byte数据类型,而字符内存流操作使用char数据类型。但是这两类操作的基本结构相同,考虑到实际的开发情况,本节主要讲解字节内存流的使用。
虽然清楚了内存流的操作结构,但是要想真正使用内存流还必须清楚内存流定义的构造方法(以字节内存流为例)。内存流定义的构造方法如下。
ByteArrayInputStream类构造:public ByteArrayInputStream(byte[] buf);ByteArrayOutputStream类构造:public ByteArrayOutputStream()。
通过 ByteArrayInputStream 类的构造可以发现,在内存流对象实例化时就必须准备好要操作的数据信息,所以内存流的操作实质上就是将操作数据首先保存到内存中,然后利用IO 流操作进行单个字节的处理。
下面演示通过内存流实现一个小写字母转大写字母的操作。程序不使用 String 类中提供的 toUpperCase() 方法,而是利用IO 操作,将每一个字节进行大写字母转换;为了方便地实现字母的转大写操作(避免不必要的字符也被转换)可以借助 Character 包装类的方法:
//转小写字母
public static char toLowerCase(char ch);
//转大写字母
public static char toUpperCase(char ch);
// 范例 5
package com.xiaoshan.demo;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
public class TestDemo{
public static void main(String[] args) throws Exception{
String str= "https://blog.csdn.net/LVSONGTAO1225";
//本次将通过内存操作流实现转换,先将数据保存在内存流里面,再从里面取出每一个数据
//将所有要读取的数据设置到内存输入流中,本次利用向上转型为InputStream类实例化
InputStream input = new ByteArrayInputStream(str.getBytes());
//为了能够将所有的内存流数据取出,可以使用ByteArrayOutputStream
OutputStream output = new ByteArrayOutputStream();
int temp = 0; //读取每一个字节数据
//经过此次循环后,所有的数据都将保存在内存输出流对象中
while ((temp = input.read())!= -1){ //每次读取一个数据
//将读取进来的数据转换为大写字母,利用Character.toUpperCase()可以保证只转换字母
output.write(Character.toUpperCase(temp)); // 字节输出流
}
System.out.println(output);
input.close(); //关闭输入流
output.close(); //关闭输出流
}
}
程序执行结果:
HTTPS://BLOG.CSDN.NET/LVSONGTAO1225
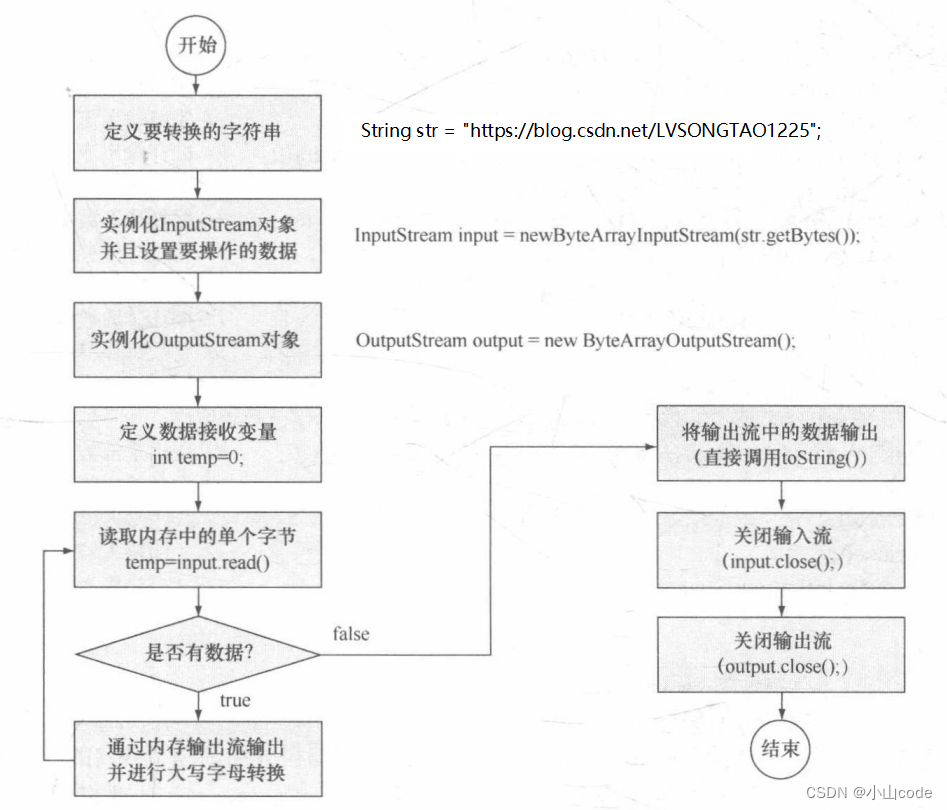
此程序分别利用 ByteArrayInputStream 与 ByteArrayOutputStream 为 InputStream 与 OutputStream 类对象实例化,同时在实例化 ByteArrayInputStream 类对象时需要设置好操作的数据,这样才可以利用 InputStream 通过内存进行读取。读取数据时采用循环的方式,并且为了防止将非字母进行转换的操作,使用了 “Character.toUpperCase()”方法操作。本程序的执行流程如下图所示。
范例5的程序是利用子类对象向上转型实现的输入流与输出流类对象的实例化操作,这样操作的好处是可以利用统一的 I0 操作标准,但是在 ByteArrayOutputStream 类里面却会存在一个重要的方法,即通过内存输出流取得全部数据:
public byte[] toByteArray()
此方法可以将所有暂时保存在内存输出流中的字节数据全部以字节数组的形式返回,而利用这样的方法,就可以实现多个文件的合并读取操作。
// 范例 6: 实现文件的合并读取
package com.xiaoshan.demo;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
public class TestDemo {
public static void main(String[] args) throws Exception{
File fileA = new File("D:" + File.separator + "a.txt"); //文件路径
File fileB = new File("D:" + File.separator + "b.txt"); //文件路径
InputStream inputA = new FileInputStream(fileA); //字节输入流
InputStream inputB = new FileInputStream(fileB); //字节输入流
ByteArrayOutputStream output = new ByteArrayOutputStream(); //内存输出流
int temp = 0; //每次读取一个字节
while ((temp = inputA.read()) != -1){ //循环读取数据
output.write(temp); //将数据保存到输出流
}
while ((temp = inputB.read()) != -1){ //循环读取数据
output.write(temp); //将数据保存到输出流
}
//现在所有的内容都保存在了内存输出流里面,所有的内容变为字节数组取出
byte data[] = output.toByteArray(); //取出全部数据
output.close(); //关闭输出流
inputA.close(); //关闭输入流
inputB.close(); //关闭输入流
System.out.println(new String(data)); //字节转换为字符串输出
}
}
查看D:\a.txt和D:\b.txt 文件内容:

程序执行结果:
小山Code:https://lst66.blog.csdn.net
Hello World
此程序首先定义了两个要读取的文件路径,并且利用这两个路径分别创建了各自的 InputStream 类实例化对象,由于需要进行文件的合并,所以将所有 InputStream 读取进来的数据都保存在 ByteArrayOutputStream 类对象中。当数据读取完毕后,可以直接利用 ByteArrayOutputStream 类中的 toByteArray() 方法将读取进来的全部数据变为字符串后输出。
5️⃣ 打印流
在 java.io 包中 OutputStream 是进行输出操作的最核心控制类,但是利用 OutputStream 会存在一个问题:所有的输出数据必须以字节类型的数据为主,也就是说如果现在要输出的数据是 int (Integer)、double(Double)、java.util.Date 等常用类型都需要将其转换为字节后才可以输出。为了解决这样的矛盾问题,在 java.io 包中又专门提供了一组打印流(字节打印流: PrintStream, 字符打印流 :PrintWriter) 方便用户的输出操作。
5.1 打印流设计思想——装饰设计模式
java.io.OutputStream 类主要是进行数据输出,如果要设计更加合适的打印流操作类,就必须解决 OutputStream 输出数据类型有限(只有 byte 类型)的问题。这时可以采用一种包装设计的模式,即将 OutputStream 类利用其他类进行包装,并且在这个类中提供了各种常见数据类型的输出操作,这样用户在进行输出操作时就可以回避字节数据的操作。打印流实现思想如下图所示。
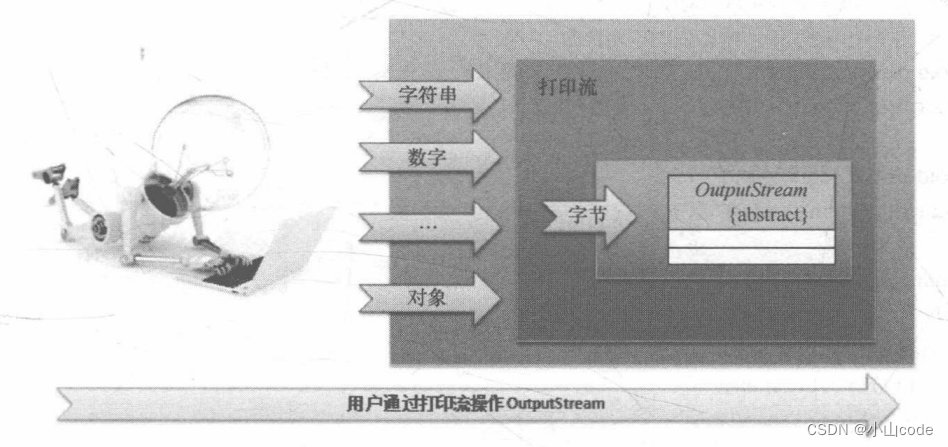
可以发现,打印流的核心思想就是首先包装一个 OutputStream 类的实例化对象,然后在打印流的内部自动帮助用户处理好各种数据类型与字节数组的转换操作。也就是说 OutputStream 的本质功能没有改变,但是操作的形式变得更加多样化,也更加方便用户使用,这样的设计就属于装饰设计模式。下面来看打印流代码的实现。
// 范例 7: 定义打印流工具类
package com.xiaoshan.demo;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
class PrintUtil { //实现专门的输出操作功能
//输出只能依靠OutputStream
private OutputStream output;
/**
*输出流的输出目标要通过构造方法传递
*@param output
*/
public PrintUtil(OutputStream output){
this.output = output;
}
public void print(int x){ //输出int型数据
this.print(String.valueOf(x)); //调用本类字符串的输出方法
}
public void print(String x)(
try { //采用OutputStream 类中定义的方法,将字符串转变为字节数组后输出
this.output.write(x.getBytes());
} catch(IOException e){
e.printStackTrace();
}
}
public void print(double x){ //输出double型数据
this.print(String.valueOf(x));
}
public void println(int x){
this.println(String.valueOf(x));
}
public void println(String x){
this.print(x.concat("\n")); //输出数据后换行
}
public void println(double x){ //输出double型数据
this.println(String.valueOf(x));
}
public void close(){ //输出流关闭
try {
this.output.close();
}catch(IOException e){
e.printStackTrace();
}
}
}
public class TestDemo{
public static void main(String[] args) throws Exception{
PrintUtil printUtil = new PrintUtil(new FileOutputStream(new File("d:"+ File.separator+ "xiaoshan.txt")));
printUtil.print("小山的博客:");
printUtil.println("https://lst66.blog.csdn.net");
printUtil.println(1+1);
printUtil.println(1.1 + 1.5);
printUtil.close();
}
}
运行结果:

此程序利用 PrintUtil 类包装了 OutputStream类,在实例化 PrintStream 类对象时需要传递输出的位置(实际上就是传递 OutputStream 类的子类), 这样就可以利用 PrintUtil 类中提供的一系列方法实现数据的输出操作,而这样的做法对于客户端而言是比较容易的,因为客户端没有必要再去关心数据类型的转换操作。
但是从实际的开发来讲,面对的数据类型可能会有多种,如果这样的工具类全部都由用户自己来实现,那么明显是不现实的,为此 java.io 包提供了专门的打印流处理类: PrintStream、PrintWriter。
5.2 打印流
OutputStream 提供了核心的数据输出操作标准,但是为了更方便地实现输出操作, java.io 包提供了两个数据打印流的操作类: PrintStream (打印字节流)、PrintWriter(打印字符流)。以PrintStream 类为例,此类的继承结构如下所示:

下面列出了PrintStream 类的常用操作方法。
| 方法 | 类型 | 说明 |
|---|---|---|
public PrintStream(OutputStream out) | 构造方法 | 通过已有OutputStream确定输出目标 |
public void print(数据类型 参数名称) | 普通方法 | 输出各种常见数据类型 |
public void println(数据类型 参数名称) | 普通方法 | 输出各种常见数据类型,并追加一个换行 |
可以发现, PrintStream ( 或 PrintWriter) 类中提供了一系列 print()与 println() 方法,并且这些方法适合各种常见数据类型的输出 (例如: int、double、long、Object 等)。而这些方法就相当于为用户隐藏了 OutputStream 类中的 write()方法,即将原本的 OutputStream 类的功能进行包装,在保持原方法功能不变的情况下,提供更方便的操作,这就是装饰设计模式的体现。
// 范例 8: 使用 PrintStream 类实现输出
package com.xiaoshan.demo;
import java.io.File;
import java.io.FileOutputStream;
import java.io.PrintStream;
public class TestDemo {
public static void main(String[] args) throws Exception{
//实例化PrintStream类对象,本次利用FileOutputStream类实例化PrintStream类对象
PrintStream pu = new PrintStream(new FileOutputStream(new File("d:" + File.separator + "xiaoshan.txt")));
pu.print("小山的博客:");
pu.println("https://lst66.blog.csdn.net");
pu.println(1+1);
pu.println(1.1+1.5);
pu.close();
}
}
此程序在实例化 PrintStream 类对象时传递了一个 FileOutputStream 类对象,表示将进行文件内容的输出,随后调用了PrintStream 类中的 print() 与 println()两个方法进行文件内容的输出。
实际上在上一节中所讲解的内容就是 PrintStream(PrintWriter) 类的实现原理,也讲解了为什么在 PrintStream 类的对象实例化中需要使用OutputStream的子类。 本类设计属于装饰设计模式,即将原本功能不足的类使用另外一个类包装,并提供更多更方便的操作方法。
5.3 PrintStream 类的改进
PrintStram 类在最初设计时主要是为了弥补 OutputStream 输出类的功能不足,但是从JDK 1.5开始, Java 为 PrintStream 增加了格式化输出的支持方法:
public PrintStream printf(String format, Object... args)
利用这些方法可以使用像 C 语言那样的数据标记实现内容填充,常见的输出标记为:整数 (%d)、 字符串 (%s)、小数 (%m.nf)、字符 ( %c)。
// 范例 9:格式化输出
package com.xiaoshan.demo;
import java.io.File;
import java.io.FileOutputStream;
import java.io.PrintStream;
public class TestDemo{
public static void main(String[] args) throws Exception{
String name = "小山";
int age =19;
double score = 59.95891023456;
PrintStream pu = new PrintStream(new FileOutputStream(new File("d:" + File.separator + "xiaoshan.txt")));
pu.printf("姓名:%s, 年龄:%d, 成绩:%5.2f", name, age, score);
pu.close();
}
}
运行结果:

此程序利用 printf() 进行了格式化输出操作,在输出字符串时使用了一系列占位符进行标记,由于 printf() 方法中设置的参数使用了可变参数类型,所以只需要根据参数意义依次传递数据即可,同时在格式化操作中还具备四舍五入的功能 (本次使用的是“%5.2f”, 表示整数位为3位,小数位为2位,一共5位)。
从JDK 1.5开始在String类中也提供了一个格式化字符串的方法,即格式化字符串:
public static String format(String format, Object... args)
由于format()方法使用了static进行定义,所以可以直接利用String类调用,在本方法使用中需要传递数据的标记与相应的数据才可以实现最终显示结果的拼凑。此方法在《【Java基础教程】(九)面向对象篇 · 第三讲:深入探究String类——实例化方式及其区别、字符串常量说明、享元设计模式解析、不可改变性特征以及String类的常用方法~》一文中已经详细讲解过,此处不再过多介绍。
🌾 总结
在本文中,我们深入研究了几个与文件和字符编码有关的主题。首先,我们讨论了转换流,它提供了在字节流和字符流之间进行字符编码转换的功能。通过使用InputStreamReader和 OutputStreamWriter,我们可以将字节流转换为字符流,并在不同的字符编码之间进行转换。
接下来,我们通过一个案例演示了如何使用转换流实现文件复制。这个案例展示了转换流在处理大文件时的效率优势,并且通过适当地缓冲数据提高了性能。
我们还探讨了内存流,它是基于内存操作的流类型。内存流允许我们在内存中读写数据,而无需依赖于物理存储介质。这对于一些特殊应用场景,例如内存数据交换或缓存操作非常有用。
最后,我们介绍了打印流及其设计思想——装饰设计模式。通过PrintStream类,我们可以方便地输出各种类型的数据到控制台或文件。并且我们提到了PrintStream类的改进,它提供了更多的输出选项,例如自动刷新、格式化输出和异常处理等特性。
通过学习转换流、案例:文件复制、字符编码、内存流和打印流,我们拓宽了处理文件和字符编码的技能。同时,我们了解到了装饰设计模式在打印流中的应用。这些知识可以帮助我们处理不同类型的数据和特殊场景的需求,并提高代码的可读性和灵活性。
《【Java基础教程】(四十四)IO篇 · 上:解析Java文件操作——File类、字节流与字符流,分析字节输出流、字节输入流、字符输出流和字符输入流的区别》
《【Java基础教程】(四十六)IO篇 · 下:》