文章目录
- 一.双端队列——deque
- 1.deque的优点与缺点
- 2.deque的原理
- 二.优先队列——priority_queue
- 1.什么是优先队列?
- 2.优先队列的基本使用
- 3.什么是仿函数?
- 4.优先队列的模拟实现
一.双端队列——deque
在上一章stack、queue的模拟实现中,我们使用的是vector 来作为底层容器。但是,在标准库中,都是使用deque来作为底层容器的,那么deque究竟为何能受到青睐呢?
1.deque的优点与缺点
deque对标的是vector与list,我们可以认为deque是vector与list的结合并且取其精华去其糟粕。
vector的优缺点
- 尾插尾删效率高,头插头删效率低
- 支持随机访问
- 扩容代价高
list的优缺点
- 头删头插效率高
- 尾插尾删效率高
- 不支持随机访问
- 不需要扩容
deque的优点
- 头删头插效率高
- 尾插尾删效率高
- 支持随机访问
- 扩容代价低(相比
vector)
deque看起来挺不错的,完美的继承了vector与list的优点。但是,既然deque这么优秀,为什么我们又好像没怎么学习过它呢?答案是,它也有它的缺点。
deque的缺点
- 中间插入或删除效率低
- 没有
vector与list的优点那么极致
deque的产生就像是什么呢?就例如,我继承了爱因斯坦的高智商,又继承了泰森的力量,但是继承的过程有一些损耗,所以我既没有爱因斯坦极致的智商,又没有泰森极致的力量,我只是个普通人。所以我们说,deque相当于vector与list的结合产品。
deque看似很中庸,实际用处不大,但是,作为stack与queue的底层容器却又刚好合适,因为栈和队列的性质完美的避开了deque的缺点,只用到了deque的优点——栈和队列只对头部或者尾部进行操作。
2.deque的原理
对于deque,我们只需要大致认识它的底层结构即可。
deque(双端队列):是一种双开口的“连续”空间的数据结构,双开口的含义是:可以在头尾两端进行插入和删除操作,且时间复杂度为O(1),与vector比较,头插效率高,不需要搬移元素;与list比较,空间利用率比较高。
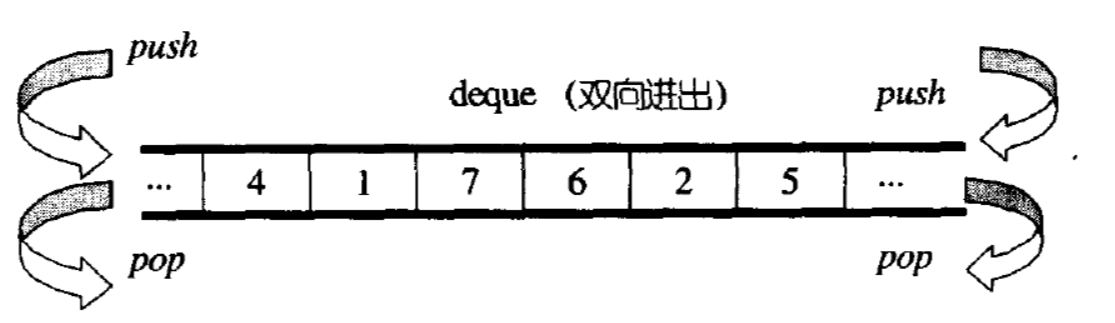
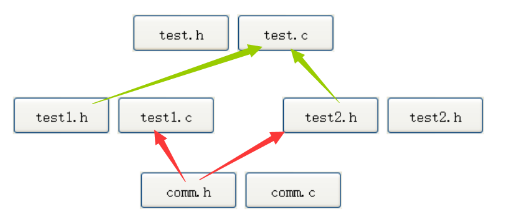
deque并不是真正连续的空间,而是由一段段连续的小空间拼接而成的,实际deque类似于一个动态的二维数组,其底层结构如下图所示:
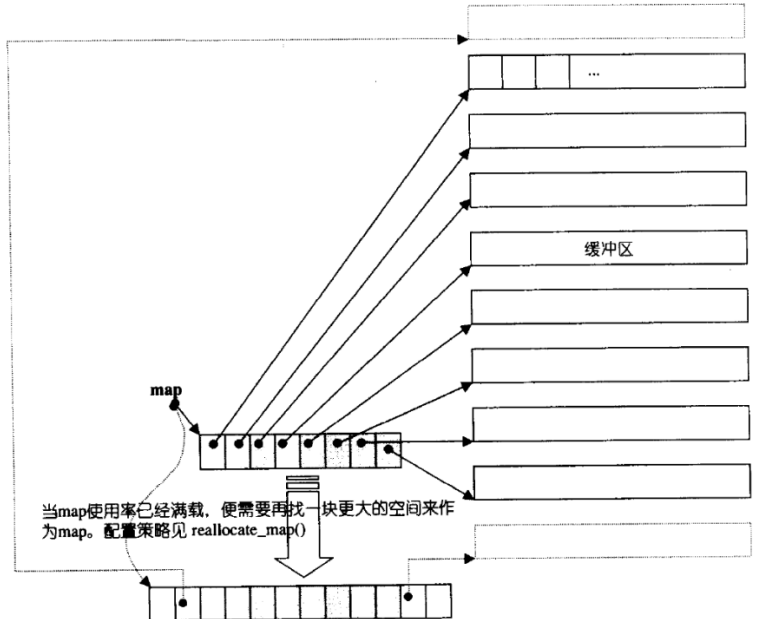
双端队列底层是一段假象的连续空间,实际是分段连续的,为了维护其“整体连续”以及随机访问的假象,落在了deque的迭代器身上,因此deque的迭代器设计就比较复杂,如下图所示:
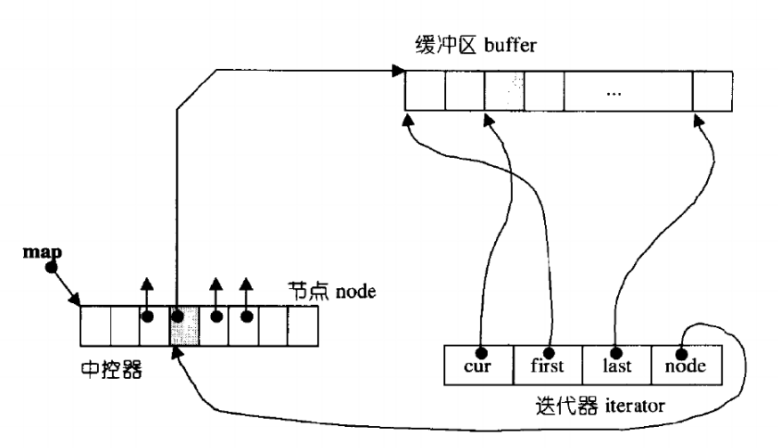
那deque是如何借助其迭代器维护其假想连续的结构呢?
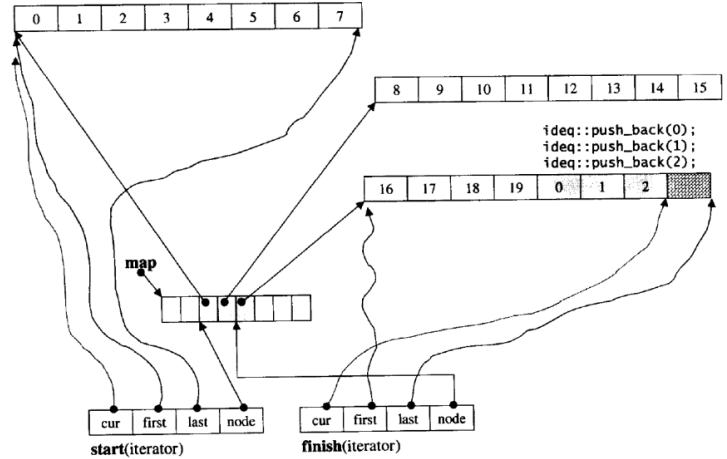
对于deque我们只需做到了解就可以。
二.优先队列——priority_queue
1.什么是优先队列?
priority_queue与stack和queue相同,都是一种容器适配器。默认使用vector作为其底层存储数据的容器,在vector上又使用了堆算法将vector中元素构造成堆的结构,因此priority_queue就是堆。
优先级队列允许你以任意顺序插入元素,并且每次弹出的元素是当前优先级最高(及最大或最小)的元素。在priority_queue中,元素的插入顺序不影响元素的优先级,而是根据其优先级属性进行排序。
2.优先队列的基本使用
- 包含头文件
< queue >
#include <queue>
- 定义一个
priority_queue对象
priority_queue<int> pq;
- 向队列中插入一个元素
pq.push(1);
pq.push(5);
pq.push(2);
- 从队列中弹出一个元素(该元素为队列内优先级最高的元素)
pq.pop();
- 返回队列中优先级最高的元素(及堆顶的元素)
cout << pq.top() << endl;
- 返回队列中的元素数量
cout << pq.size() << endl;
- 判断队列是否为空
//empty()
if (pq.empty())
{
cout << "Queue is empty" << endl;
}
else
{
cout << "Queue is not empty" << endl;
}
特别注意
优先级队列默认是建大堆,也就是元素的值越大,优先级越高。我们可以通过一个传递模板参数来控制优先级的判别。所以,优先级队列在设计的时候用到了3个模板参数,而我们上一章所学习的stack与queue则是2个模板参数,如图:



// 默认情况下,创建的是大堆,其底层按照小于号比较
priority_queue<int> pq1;
// 如果要创建小堆,将第三个模板参数换成greater比较方式
// 记得包含greater算法的头文件——#include <functional>
priority_queue<int, vector<int>, greater<int>> pq2;
第三个模板参数仅仅只有比较大小的作用,我们也可以自己实现这样一个模板类来传递。像图中Compare这样的类所创建的对象,我们通常称它为——仿函数。因为该类的对象可以像函数一样使用。
3.什么是仿函数?
仿函数(functor)是一种行为类似于函数的对象,它可以像函数一样被调用。在C++中,仿函数通常是一个类,它重载了函数调用运算符operator(),并且可以像函数一样使用。
仿函数可以被用来封装一些操作或算法,它们可以被传递给其他函数或算法作为参数,或者作为返回值返回给调用者。由于仿函数是一个对象,因此可以在调用它们的过程中保持状态信息,这使得它们可以非常灵活地实现不同的行为。
例如上述的优先级队列又或是库中的sort函数,sort()函数可以接受一个仿函数对象作为第三个参数,这个仿函数对象将被用来比较两个元素的大小关系,这样我们就可以灵活的运用sort函数排序数列为升序或者降序了。
关于仿函数,我们点到为止。
4.优先队列的模拟实现
关于堆的结构前面已经详细讲解过点我
#include <iostream>
#include <vector>
using namespace std;
namespace dianxia
{
// 小于
template<class T>
class less
{
public:
bool operator()(const T& x, const T& y)
{
return x < y;
}
};
// 大于
template<class T>
class greater
{
public:
bool operator()(const T& x, const T& y)
{
return x > y;
}
};
// priority_queue类
template<class T, class Container = vector<T>,class Compare=less<T>>
class priority_queue
{
// 比较的对象
Compare com;
// 向上调整
void adjust_up(int child)
{
size_t parent = (child - 1) / 2;
while (child > 0)
{
if (com(_con[parent] ,_con[child]))
{
swap(_con[parent], _con[child]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
// 向下调整
void adjust_down(int parent)
{
int child = parent * 2 + 1;
while (child < _con.size())
{
// 确保child是两个孩子中大/小的那一个
if (child + 1 < _con.size() && com(_con[child], _con[child + 1]))
{
++child;
}
if (com(_con[parent], _con[child]))
{
swap(_con[parent], _con[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
public:
void push(const T& data)
{
_con.push_back(data);
adjust_up(_con.size()-1);
}
void pop()
{
// 堆顶元素与堆尾元素互换
swap(_con[0],_con[_con.size() - 1]);
_con.pop_back();
adjust_down(0);
}
const T& top()
{
return _con[0];
}
size_t size()
{
return _con.size();
}
bool empty()
{
return _con.empty();
}
private:
Container _con;
};
}
本文到此结束,码文不易,还请多多支持哦!!!