文章目录
- 周赛355
- [2788. 按分隔符拆分字符串](https://leetcode.cn/problems/split-strings-by-separator/)
- 模拟(注意转义)
- [2789. 合并后数组中的最大元素](https://leetcode.cn/problems/largest-element-in-an-array-after-merge-operations/)
- 贪心
- [2790. 长度递增组的最大数目](https://leetcode.cn/problems/maximum-number-of-groups-with-increasing-length/)
- [2791. 树中可以形成回文的路径数](https://leetcode.cn/problems/count-paths-that-can-form-a-palindrome-in-a-tree/)
周赛355
2788. 按分隔符拆分字符串
难度简单2
你一个字符串数组 words 和一个字符 separator ,请你按 separator 拆分 words 中的每个字符串。
返回一个由拆分后的新字符串组成的字符串数组,不包括空字符串 。
注意
separator用于决定拆分发生的位置,但它不包含在结果字符串中。- 拆分可能形成两个以上的字符串。
- 结果字符串必须保持初始相同的先后顺序。
示例 1:
输入:words = ["one.two.three","four.five","six"], separator = "."
输出:["one","two","three","four","five","six"]
解释:在本示例中,我们进行下述拆分:
"one.two.three" 拆分为 "one", "two", "three"
"four.five" 拆分为 "four", "five"
"six" 拆分为 "six"
因此,结果数组为 ["one","two","three","four","five","six"] 。
示例 2:
输入:words = ["$easy$","$problem$"], separator = "$"
输出:["easy","problem"]
解释:在本示例中,我们进行下述拆分:
"$easy$" 拆分为 "easy"(不包括空字符串)
"$problem$" 拆分为 "problem"(不包括空字符串)
因此,结果数组为 ["easy","problem"] 。
示例 3:
输入:words = ["|||"], separator = "|"
输出:[]
解释:在本示例中,"|||" 的拆分结果将只包含一些空字符串,所以我们返回一个空数组 [] 。
提示:
1 <= words.length <= 1001 <= words[i].length <= 20words[i]中的字符要么是小写英文字母,要么就是字符串".,|$#@"中的字符(不包括引号)separator是字符串".,|$#@"中的某个字符(不包括引号)
模拟(注意转义)
class Solution {
public List<String> splitWordsBySeparator(List<String> words, char separator) {
List<String> ans = new ArrayList<>();
for(String w : words){
String[] strs = w.split("\\" + separator + "");
for(String str : strs){
if(str.length() > 0)
ans.add(str);
}
}
return ans;
}
}
2789. 合并后数组中的最大元素
难度中等5
给你一个下标从 0 开始、由正整数组成的数组 nums 。
你可以在数组上执行下述操作 任意 次:
- 选中一个同时满足
0 <= i < nums.length - 1和nums[i] <= nums[i + 1]的整数i。将元素nums[i + 1]替换为nums[i] + nums[i + 1],并从数组中删除元素nums[i]。
返回你可以从最终数组中获得的 最大 元素的值。
示例 1:
输入:nums = [2,3,7,9,3]
输出:21
解释:我们可以在数组上执行下述操作:
- 选中 i = 0 ,得到数组 nums = [5,7,9,3] 。
- 选中 i = 1 ,得到数组 nums = [5,16,3] 。
- 选中 i = 0 ,得到数组 nums = [21,3] 。
最终数组中的最大元素是 21 。可以证明我们无法获得更大的元素。
示例 2:
输入:nums = [5,3,3]
输出:11
解释:我们可以在数组上执行下述操作:
- 选中 i = 1 ,得到数组 nums = [5,6] 。
- 选中 i = 0 ,得到数组 nums = [11] 。
最终数组中只有一个元素,即 11 。
提示:
1 <= nums.length <= 1051 <= nums[i] <= 106
贪心
从最后开始合并,当前大于等于前面 都能合并
因此,我们考虑以每个数为结尾,往前合并构成的最长区间,则这样的区间是不相交的,要么包含,要么分离(否则结束点更晚的区间总能合并到更前面的区间的开头)。
于是,我们只需要把数组进行分组,求每一组和的最大值。
由于是从后往前合并,因此只需要从后往前遍历数组即可。
class Solution {
public long maxArrayValue(int[] nums) {
int n = nums.length;
long ans = nums[n-1], cur = nums[n-1];
for(int i = n-2; i >= 0; i--){
if(nums[i] <= cur){
cur += nums[i];
ans = Math.max(ans, cur);
}else{
cur = nums[i];
ans = Math.max(ans, cur);
}
}
return ans;
}
}
2790. 长度递增组的最大数目
难度困难15
给你一个下标从 0 开始、长度为 n 的数组 usageLimits 。
你的任务是使用从 0 到 n - 1 的数字创建若干组,并确保每个数字 i 在 所有组 中使用的次数总共不超过 usageLimits[i] 次。此外,还必须满足以下条件:
- 每个组必须由 不同 的数字组成,也就是说,单个组内不能存在重复的数字。
- 每个组(除了第一个)的长度必须 严格大于 前一个组。
在满足所有条件的情况下,以整数形式返回可以创建的最大组数。
示例 1:
输入:usageLimits = [1,2,5]
输出:3
解释:在这个示例中,我们可以使用 0 至多一次,使用 1 至多 2 次,使用 2 至多 5 次。
一种既能满足所有条件,又能创建最多组的方式是:
组 1 包含数字 [2] 。
组 2 包含数字 [1,2] 。
组 3 包含数字 [0,1,2] 。
可以证明能够创建的最大组数是 3 。
所以,输出是 3 。
示例 2:
输入:usageLimits = [2,1,2]
输出:2
解释:在这个示例中,我们可以使用 0 至多 2 次,使用 1 至多 1 次,使用 2 至多 2 次。
一种既能满足所有条件,又能创建最多组的方式是:
组 1 包含数字 [0] 。
组 2 包含数字 [1,2] 。
可以证明能够创建的最大组数是 2 。
所以,输出是 2 。
示例 3:
输入:usageLimits = [1,1]
输出:1
解释:在这个示例中,我们可以使用 0 和 1 至多 1 次。
一种既能满足所有条件,又能创建最多组的方式是:
组 1 包含数字 [0] 。
可以证明能够创建的最大组数是 1 。
所以,输出是 1 。
提示:
1 <= usageLimits.length <= 1051 <= usageLimits[i] <= 109
题解:
倒序填入列,先递增排序保证了同一行的数不会重复,再使用剩余量计算出列个数,得到最终答案
class Solution {
/**
* 先对usageLimits排序
* 贪心,每新增一个group, 最优的策略:group[i + 1].size() = group[i].size() + 1;
* 从小到大遍历usageLimits, 每新增一个group, 必须要新增一个元素,
* 且 新增元素值 和 缓存未用完的值 必须要大于当前分组的值。若满足,说明可以新增一个group,未使用完的值加入缓存。
*
* 举例说明:[2, 2, 2]
* group[0]: 0
* group[1]: 2 1
* group[2]: 2 1 0
*
* 从i开始遍历(倒序看上面这个过程,填充"列"),而且排序后递增顺序能保证相同的数不在同一行(下面被新数填充)
* i == 0时,使用一个0放入group[2][2]即可,剩余一个0可以加入缓存,这个缓存的值在后续的i都是可以使用的。
* i == 1时,使用两个1, 分别放在group[1][1], group[2][1].
* i == 2时,使用两个2和缓存里的0, 分别放在group[0][0], group[1][0], group[2][0]的位置。
*/
public int maxIncreasingGroups(List<Integer> usageLimits) {
Collections.sort(usageLimits);
long available = 0;
int group = 0;
for(int limit : usageLimits){
available += limit;
if(available > group){
group += 1;
available -= group;
}
}
return group;
}
}
2791. 树中可以形成回文的路径数
难度困难18
给你一棵 树(即,一个连通、无向且无环的图),根 节点为 0 ,由编号从 0 到 n - 1 的 n 个节点组成。这棵树用一个长度为 n 、下标从 0 开始的数组 parent 表示,其中 parent[i] 为节点 i 的父节点,由于节点 0 为根节点,所以 parent[0] == -1 。
另给你一个长度为 n 的字符串 s ,其中 s[i] 是分配给 i 和 parent[i] 之间的边的字符。s[0] 可以忽略。
找出满足 u < v ,且从 u 到 v 的路径上分配的字符可以 重新排列 形成 回文 的所有节点对 (u, v) ,并返回节点对的数目。
如果一个字符串正着读和反着读都相同,那么这个字符串就是一个 回文 。
示例 1:
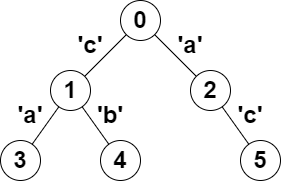
输入:parent = [-1,0,0,1,1,2], s = "acaabc"
输出:8
解释:符合题目要求的节点对分别是:
- (0,1)、(0,2)、(1,3)、(1,4) 和 (2,5) ,路径上只有一个字符,满足回文定义。
- (2,3),路径上字符形成的字符串是 "aca" ,满足回文定义。
- (1,5),路径上字符形成的字符串是 "cac" ,满足回文定义。
- (3,5),路径上字符形成的字符串是 "acac" ,可以重排形成回文 "acca" 。
示例 2:
输入:parent = [-1,0,0,0,0], s = "aaaaa"
输出:10
解释:任何满足 u < v 的节点对 (u,v) 都符合题目要求。
提示:
n == parent.length == s.length1 <= n <= 105- 对于所有
i >= 1,0 <= parent[i] <= n - 1均成立 parent[0] == -1parent表示一棵有效的树s仅由小写英文字母组成
题解:https://leetcode.cn/problems/count-paths-that-can-form-a-palindrome-in-a-tree/solution/yong-wei-yun-suan-chu-li-by-endlesscheng-n9ws/
class Solution:
"""
1. 从 u 到 v 的路径上分配的字符可以 重新排列 形成回文串
==> 至多一个字母出现奇数次,其余字母出现偶数次
2. 偶数次用0表示,奇数次用 1 表示
==> 用长为 26 的bool数组 => 用一个int表示
3. 用异或来处理字母出现的异或性,计算的是从根到某个点的路径上的边异或值
从 lca 到 b 的异或 = 根到 b 的异或值 ^ 根到 lca 的异或值
==> a 到 b 的路径异或性 = XOR_a ^ XOR_lca ^ XOR_b ^ XOR_lca = XOR_a ^ XOR_b
==> 什么时候a和b可以形成回文串? XOR_a ^ XOR_b = 0 或者 二进制表示只有一位是1,其他都是0
用一次 DFS 求出所有的 XOR_a
4. 问题变成,给你一个长为 n-1 的数组,有多少个“两数异或”是 0,是1 << 0,是 1<< 1 ... 1<<25
"""
def countPalindromePaths(self, parent: List[int], s: str) -> int:
n = len(s)
g = [[] for _ in range(n)]
for i in range(1, n):
bit = 1 << (ord(s[i]) - ord('a')) # s[i]-'a'
g[parent[i]].append((i, bit)) # 保存parent[i]指向i有条边,边对应字母的二进制信息bit
ans = 0
cnt = Counter()
def dfs(v: int, xor: int) -> None:
nonlocal ans
# 计算 v点 和 其他点的异或和
ans += cnt[xor] # xor ^ xor = 0
for i in range(26):
ans += cnt[xor ^ (1 << i)] # xor 是1 << 0,是 1<< 1 ... 1<<25
cnt[xor] += 1
for to, wt in g[v]:
dfs(to, xor ^ wt)
dfs(0, 0)
return ans