首页最近被chatGPT刷屏,但翔二博主左看右看发现很多想法似乎都是一脉相通的,于是连夜从存档中找了一些文章尝试理一理它的理论路线。
- 具身智能综述和应用(Embodied AI)
- 多模态中的指令控制
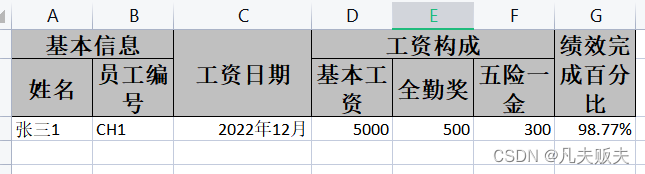
同时想到今年在智源人工智能前沿报告(2021-2022年度)中其实就有说道:
“未来三年,基于虚拟世界、实时时空环境训练的具身模型会取得较大的发展,如自动驾驶、机器人、游戏中数字人等······未来五到十年,超大规模预训练模型(信息模型)和具身模型将会结合,成为‘数字超人’,在知识能力以及跟环境的互动程度上,将比以往的人类都要强······具身模型和机器人也将结合,在物理世界出现能力比人类还要强的无人系统,即‘具身超人’。乐观估计,在未来三十年,数字超人和具身超人可能会结合,最终诞生超级人工智能。”
测了测chatGPT的性能后,好像这一切来的稍快了一点?
博主个人理解,它以更为embodied AI形式的指令作为输入,以训练/微调大规模的信息模型,并基于强化学习与真实世界做持续交互,已经很接近此处所提到的“数字超人”了。
关于chatGPT的基础介绍和使用本文不做过多介绍,可以参考各种报道文和知乎等等,此处推荐几份解读。
- 视频讲解chatGPT
- 张俊林大佬的理解
本篇博文先简要整理一下跟chatGPT相关Instruction Tuning的几篇论文。
Finetuned Language Models Are Zero-Shot Learners
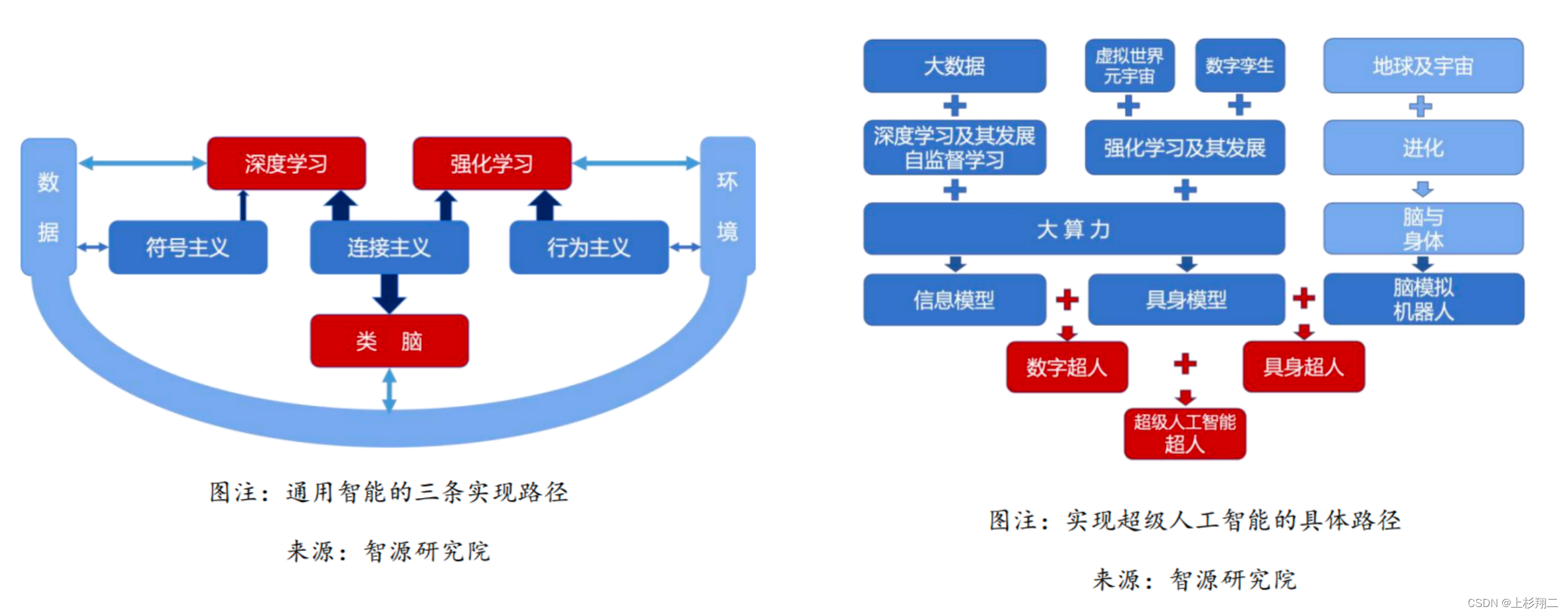
首先是ICLR22的FLAN模型,这篇文章明确提出 Instruction Tuning(指令微调)的技术,它的本质目的是想将 NLP 任务转换为自然语言指令,再将其投入模型进行训练,通过给模型提供指令和选项的方式,使其能够提升Zero-Shot任务的性能表现。
Motivation在于大规模的语言模型如GPT-3可以非常好地学习few-shot,但它在zero-shot上却不那么成功。例如, GPT-3在阅读理解、问题回答和自然语言推理等任务上的表现很一般,作者认为一个潜在的原因是,如果没有少量示例的zero-shot条件下,模型很难在与训练前数据格式(主要是prompts)维持一致。
既然如此,那么为什么不直接用自然语言指令做输入呢?如下图所示,不管是commonsense reasoning任务还是machine translation任务,都可以变为instruct的形式,然后利用大模型进行学习。在这种方式下,而当一个unseen task进入时,通过理解其自然语言语义可以轻松实现zero-shot的扩展,如natural language inference任务。
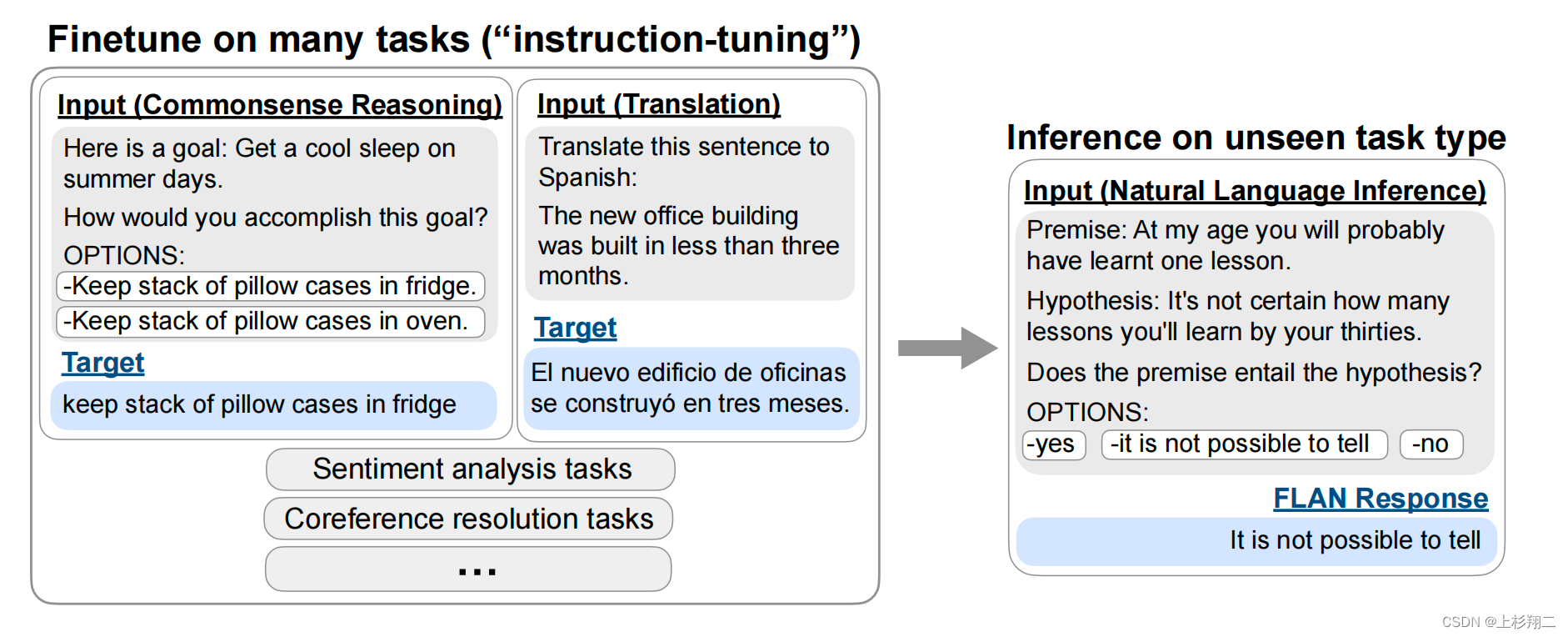
Instruction-tuning、Fine-tuning、Prompt-Tuning的区别在哪?
- Fine-tuning:先在大规模语料上进行预训练,然后再在某个下游任务上进行微调,如BERT、T5;
- Prompt-tuning:先选择某个通用的大规模预训练模型,然后为具体的任务生成一个prompt模板以适应大模型进行微调,如GPT-3;
- Instruction-tuning:仍然在预训练语言模型的基础上,先在多个已知任务上进行微调(通过自然语言的形式),然后再推理某个新任务上进行zero-shot。
具体来说,作者提出的Finetuned LAnguage Net(FLAN)模型将62个NLP task分为12 cluster,同一个cluster内是相同的任务类型,如下图所示。
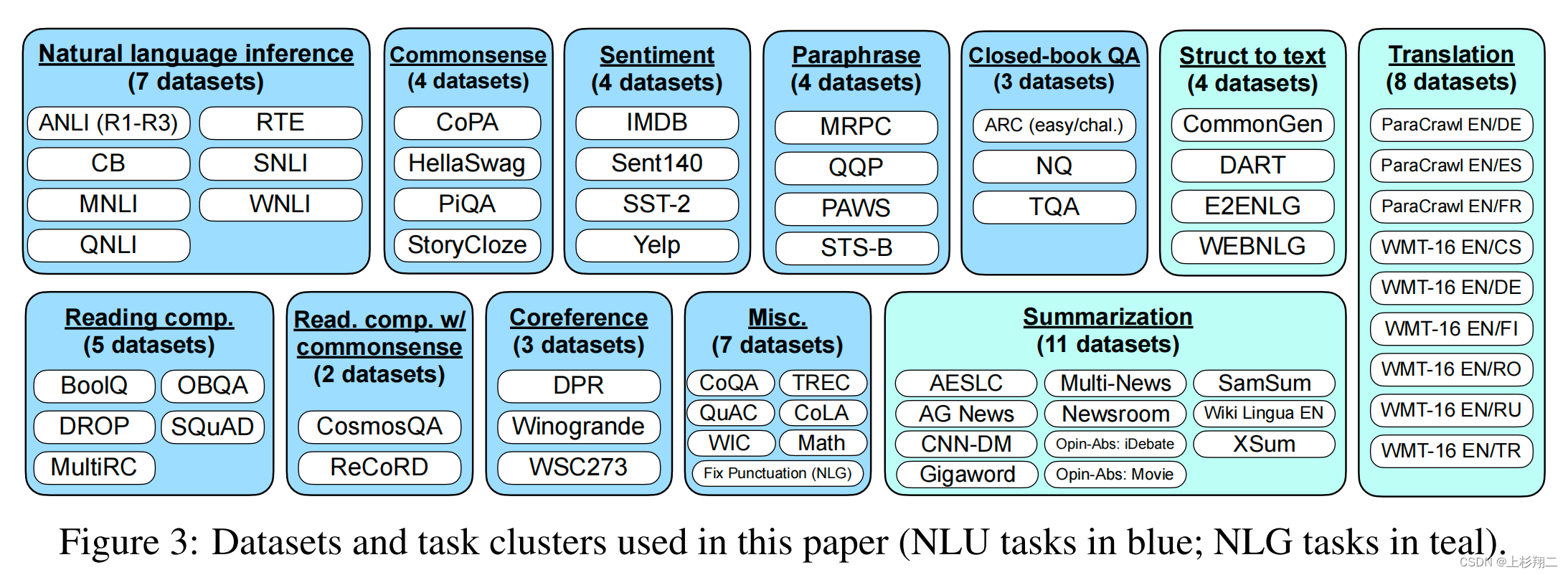
对于每个task,将为其手动构建10个独特template,作为以自然语言描述该任务的instructions。为了增加多样性,对于每个数据集,还包括最多三个“turned the task around”的模板(例如,对于情感分类,要求其生成电影评论的模板)。所有数据集的混合将用于后续预训练语言模型做instruction tuning,其中每个数据集的template都是随机选取的。如下图所示,Premise、Hypothesis、Options会被填充到不同的template中作为训练数据。
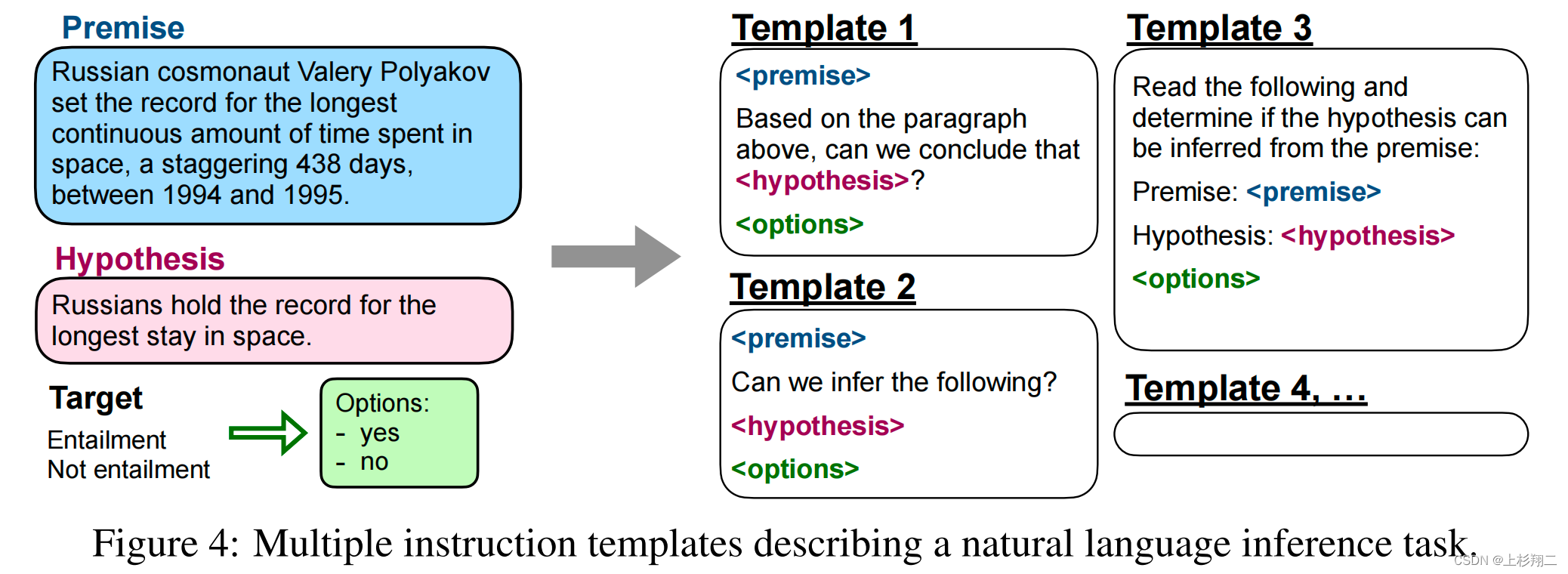
然后基于LaMDA-PT模型进行微调。LaMDA-PT是一个包含137B参数的自回归语言模型,这个模型在web文档(包括代码)、对话数据和维基百科上进行了预训练,同时有大约10%的数据是非英语数据。然后FLAN混合了所有构造的数据集在128核的TPUv3上微调60个小时。
- paper:https://arxiv.org/pdf/2109.01652.pdf
- code:https://github.com/google-research/flan
在介绍instructGPT和chatGPT前,还有两份比较重要的前置工作,即Reinforcement Learning from Human Feedback (RLHF),如何从用户的明确需要中学习。
Fine-Tuning Language Models from Human Preferences
这份工作是将大模型往人类偏好进行结合的一次尝试,其使用强化学习PPO而不是监督学习来微调语言模型GPT-2。
为了弄清人类偏好,首先需要从预训练好的GPT-2 开始,并通过询问人工标注者四个生成样本中哪个样本最好来收集数据集。基于收集的数据集,尝试基于强化学习微调GPT,简要模型结构如下图,其需要训练两个模块一个是GPT模型(policy),一个是奖励模型(reward model),其中奖励模型用于模拟人类对四个样本的打分以代表其选择偏好。
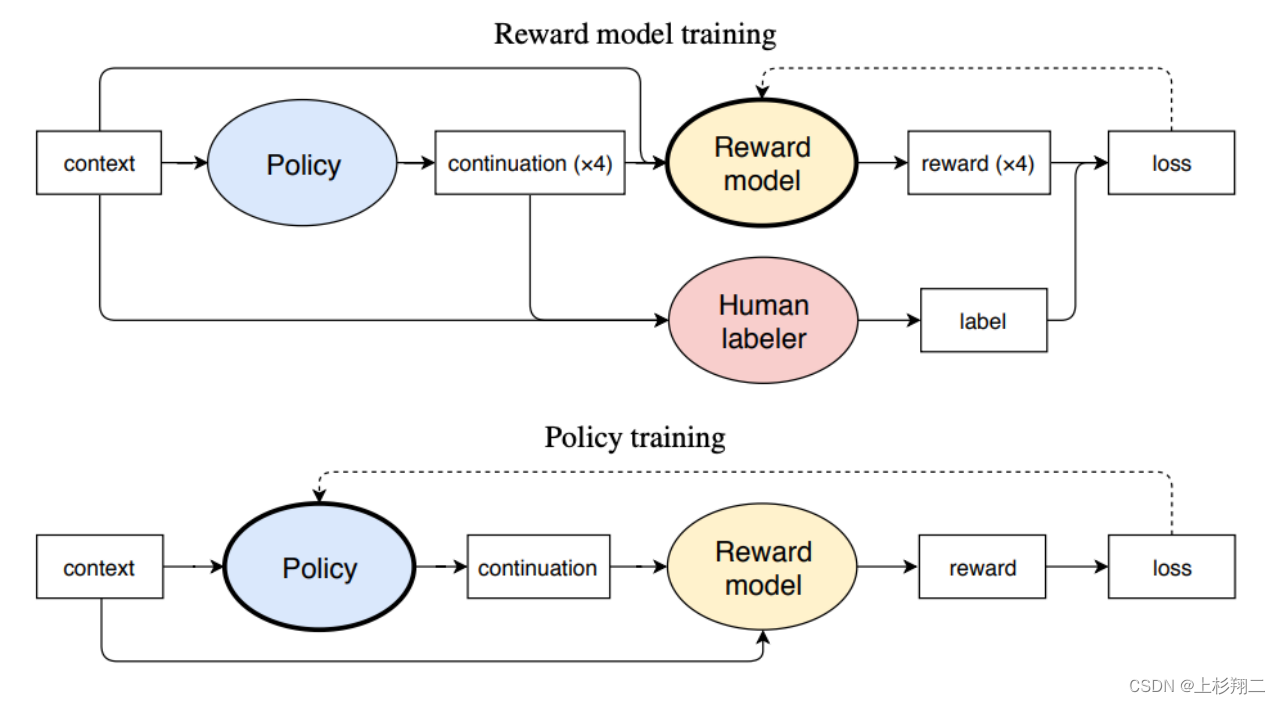
整体的训练过程是:
- 从数据集中采样context x,并使用policy网络得到4种句子,即(x、y0、y1、y2、y3),其中y的下标表示让人类的优先级排序。
- 训练policy网络。从人类标注数据中进行训练,其中r是奖励模型的分数,该loss尝试让人类更喜欢的句子得分更高,从而来微调policy生成更符合人类偏好的句子。 l o s s ( r ) = E ( x , { y i } i , b ) − S [ l o g x r ( x , y b ) ∑ i x r ( x , y i ) ] loss(r)=E_{(x,\{y_i\}_i,b)-S}[log \frac{x^{r(x,y_b)}}{\sum_i x^{r(x,y_i)}}] loss(r)=E(x,{yi}i,b)−S[log∑ixr(x,yi)xr(x,yb)]
- 训练奖励模型, 其中为了分布变化太远,会额外添加一个带有期望KL惩罚。 R ( x , y ) = r ( x , y ) − β l o g π ( y ∣ x ) ρ ( y ∣ x ) R(x,y)=r(x,y)-\beta log \frac{\pi(y|x)}{\rho(y|x)} R(x,y)=r(x,y)−βlogρ(y∣x)π(y∣x)
- 在online模式中,可以继续收集额外的样本,并定期重新训练奖励模型r。
paper:https://arxiv.org/abs/1909.08593
code:https://github.com/openai/lm-human-preferences
这篇论文的主要启发在于,人类偏好的约束、使用PPO的训练方法可以使模型在online的过程中持续学习。
Learning to Summarize with Human Feedback
随后的这份工作会更为贴近instructGPT和chatGPT,其提出主要按照人类偏好的summarization场景中。其模型框架架构如下图所示,和instructGPT类似,主要分为三步:先收集人类在成对摘要上偏好的数据集,然后通过监督学习训练一个奖励模型(RM)来预测人类偏好的摘要。最后,利用奖励模型RM给出的分数去微调生成摘要的大模型,以上模型都基于GPT-3进行微调。
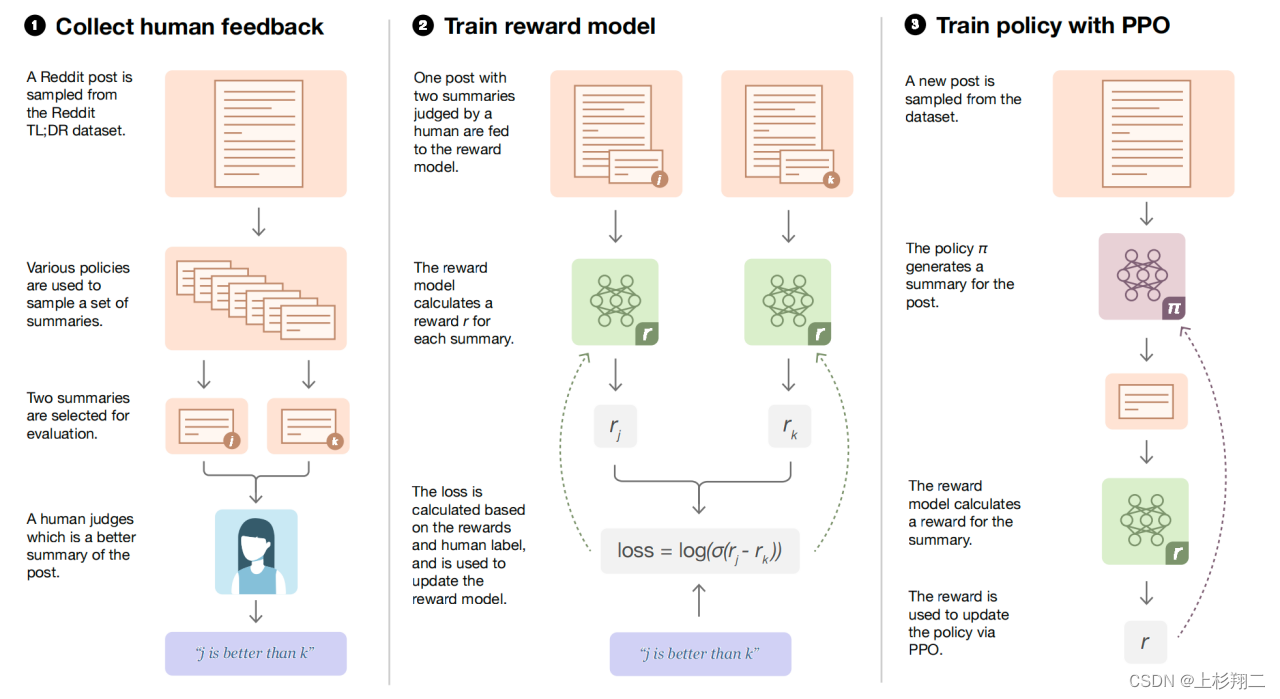
- Collect human feedback。来自reddit.com的300万篇不同主题的文章以及由原海报撰写的文章摘要,然后由人工标注摘要的顺序。
- Train reward model。奖励函数预测摘要之间谁更好,因此利用成对损失函数进行监督训练即可。 l o s s ( r θ ) = − E ( x , y 0 , y 1 , i ) − D [ l o g ( σ ( r θ ( x , y i ) − r θ ( x , y 1 − i ) ) ) ] loss(r_{\theta})=-E_{(x,y_0,y_1,i)}-D[log(\sigma(r_{\theta}(x,y_i)-r_{\theta}(x,y_{1-i})))] loss(rθ)=−E(x,y0,y1,i)−D[log(σ(rθ(x,yi)−rθ(x,y1−i)))]
- Train policy with PPO。和前一篇文章一样,利用奖励模型得到一种偏好策略以产生更高质量的摘要结果。 R ( x , y ) = r θ ( x , y ) − β l o g [ π p h i R L ( y ∣ x ) / π S F T ( y ∣ x ) ] R(x,y)=r_{\theta}(x,y)-\beta log[\pi^{RL}_{phi}(y|x)/\pi^{SFT}(y|x)] R(x,y)=rθ(x,y)−βlog[πphiRL(y∣x)/πSFT(y∣x)]其中KL惩罚由两个作用,一是阻止模型崩溃为单一模式。其次,它确保了模型不会因为太追求学习偏好而偏离原本的摘要模型太远。
这份工作虽然局限于摘要,但在训练框架是为后续的instructGPT打下了基础,即人工标注+强化学习。
instructGPT
instructGPT从模型结构上与上一篇文章几乎一摸一样,但它通向了更为宽广的领域。通过收集带有更多人类instruct的自然语言文本句子,使其可以完成各种nlp任务,正式进化为一个全能模型。
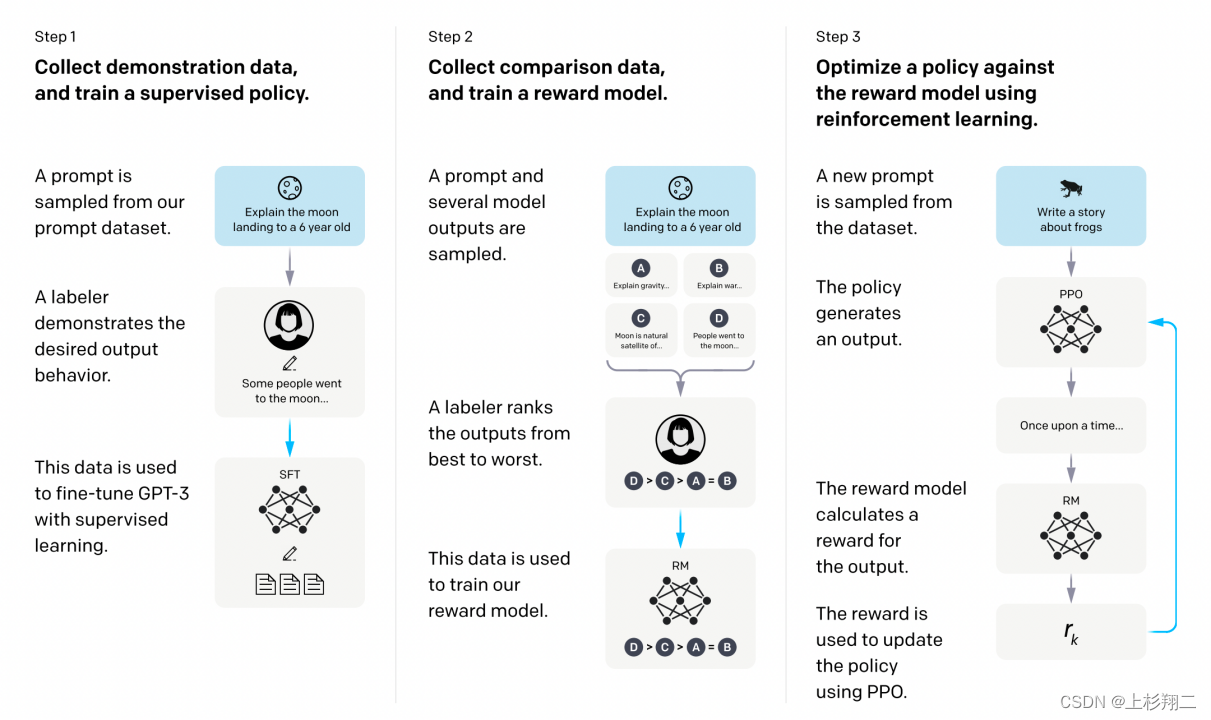
实现上仍然分为三个步骤,
- 监督学习。收集人工编写的期望模型如何输出的数据集,并使用其来训练GPT3。
- 奖励模型。收集人工标注的模型多个输出之间的排序数据集。并训练一个奖励模型,以预测用户更喜欢哪个模型输出。 l o s s ( θ ) = − 1 ( K ; 2 ) E ( x , y w , y l ) − D [ l o g ( σ ( r θ ( x , y w ) − r θ ( x , y l ) ) ) ] loss(\theta)=-\frac{1}{(K;2)}E_{(x,y_w,y_l)}-D[log(\sigma(r_{\theta}(x,y_w)-r_{\theta}(x,y_{l})))] loss(θ)=−(K;2)1E(x,yw,yl)−D[log(σ(rθ(x,yw)−rθ(x,yl)))]
- 微调GPT3。使用这个奖励模型作为奖励函数,以PPO的方式,微调监督学习得到的GPT3。 o b j e c t ( ϕ ) = E ( x , y ) − D π R L [ r θ ( x , y ) − β l o g ( π p h i R L ( y ∣ x ) / π S F T ( y ∣ x ) ) ] + γ E x − D p r e t r a i n [ l o g ( π ϕ R L ( x ) ) ] object(\phi)=E_{(x,y)-D_{\pi RL}}[r_{\theta}(x,y)-\beta log(\pi^{RL}_{phi}(y|x)/\pi^{SFT}(y|x))]+\gamma E_{x-D_{pretrain}[log(\pi^{RL}_{\phi}(x))]} object(ϕ)=E(x,y)−DπRL[rθ(x,y)−βlog(πphiRL(y∣x)/πSFT(y∣x))]+γEx−Dpretrain[log(πϕRL(x))]KL惩罚仍然是为了对减轻奖励模型的过度优化。此外还会将训练前的梯度混合到PPO梯度中,以维持模型在更多通用NLP任务上的性能。
更多细节可以见开头的讲解视频。
chatGPT
目前只知道chatGPT基于instructGPT进行训练,但具体细节没有更多的披露,但是从以上几份工作中,可以窥见一些技术路线。
如chatGPT可以轻轻松松根据人类的语言完成从对话、写诗、编故事、写代码等等等等等各种任务,大概率就是基于FLAN模型这种迁移任务的方式,从而能够满足各位用户老爷们的奇怪需要。而instructGPT则应该是chatGPT用于训练的主要架构,包括数据集构建、模型框架和训练目标等等。
最后想再放一次这张图,博主也需要再好好悟一悟。