一、简介
Solr是一个高性能、基于Lucene的全文检索服务器。Solr对Lucene进行了扩展,提供了比Lucene更为丰富的查询语言,并实现了强大的全文检索功能、高亮显示、动态集群,具有高度的可扩展性。同时从Solr 4.0版本开始,支持SolrCloud模式,该模式下能够进行集中式的配置信息、近实时搜索、自动容错等功能:
- 利用ZooKeeper作为协同服务,启动时可以指定把Solr的相关配置文件上传ZooKeeper,多机器共用。这些ZooKeeper中的配置不会再拿到本地缓存,Solr直接读取ZooKeeper中的配置信息。配置文件的变动,所有机器都可以感知到。
- 自动容错,SolrCloud对索引(collection)进行分片(shard),并对每个分片创建多个Replica。一个Replica出现异常并不会影响整个索引搜索服务,每个Replica都可以独立对外提供服务。
- 索引和查询时的自动负载均衡,SolrCloud索引(collection)的多个Replica可以分布在多台机器上,均衡索引和查询压力。如果索引和查询压力大,可以通过扩展机器,增加Replica来减缓压力。因此,下面的介绍主要是围绕SolrCloud展开描述的。
- Solr索引数据存储方法有多种,利用HDFS作为其索引文件的存储系统,提供高可靠性、高性能、可伸缩、准实时的全文检索系统;存放到本地磁盘,提供了更加快速的索引和查询速度。
Solr集群方案SolrCloud由多个SolrServer进程组成,如下图所示,模块说明如下表所示。
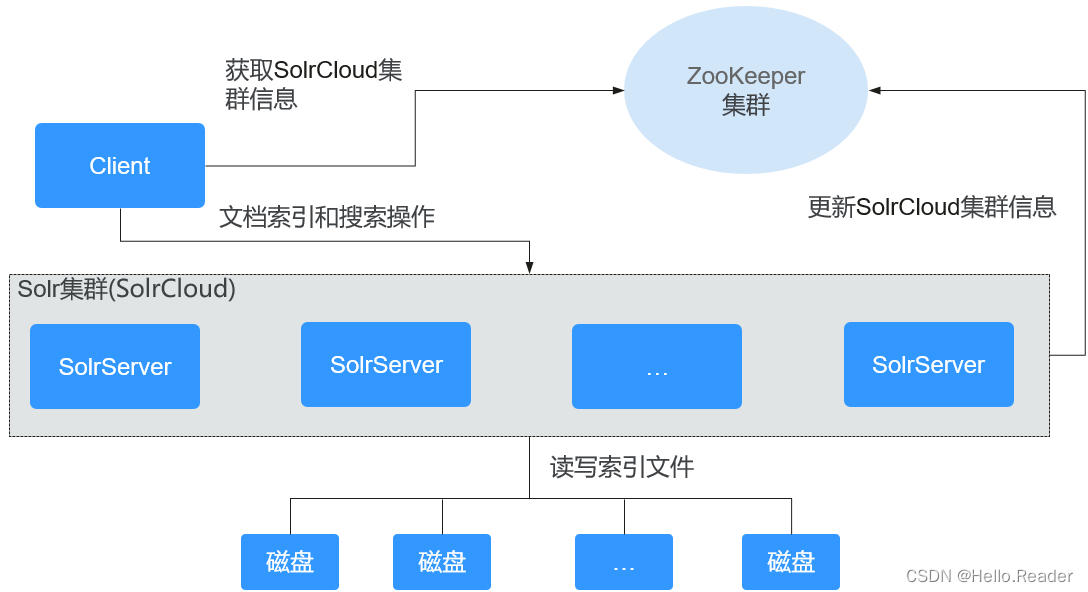
| 名称 | 说明 |
|---|---|
| Client | Client使用HTTP或HTTPS协议同Solr集群(SolrCloud)中的SolrServer进行通信,进行分布式索引和分布式搜索操作。 |
| SolrServer | SolrServer负责提供创建索引和全文检索等服务,是Solr集群中的数据计算和处理单元。 |
| ZooKeeper集群 | ZooKeeper为Solr集群中各进程提供分布式协作服务。各SolrServer将自己的信息(collection配置信息、SolrServer健康信息等)注册到ZooKeeper中,Client据此感知各个SolrServer的健康状态来决定索引和搜索请求的分发。 |
二、Solr基本概念
- Collection:在SolrCloud集群中逻辑意义上的完整的索引。它可以被划分为一个或者多个Shard,它们使用相同的Config
Set。 - Config Set:Solr Core提供服务必须的一组配置文件。包括solrconfig.xml和managed-schema等。
- Core:即Solr Core,一个Solr实例中包含一个或者多个Solr Core,每个Solr
Core可以独立提供索引和查询功能,每个Solr Core对应一个索引或者Collection的Shard的副本(replica)。 - Shard:Collection的逻辑分片。每个Shard都包含一个或者多个replicas,通过选举确定哪个是Leader。
- Replica:Shard的拷贝。一个Replica存在于Solr的一个Core中。
- Leader:赢得选举的Shard
replicas。当索引documents时,SolrCloud会传递它们到此Shard对应的leader,leader再分发它们到Shard的全部replicas。 - ZooKeeper:它在SolrCloud是必须的,提供分布式锁、处理Leader选举等功能。
三、Solr原理
倒排序索引
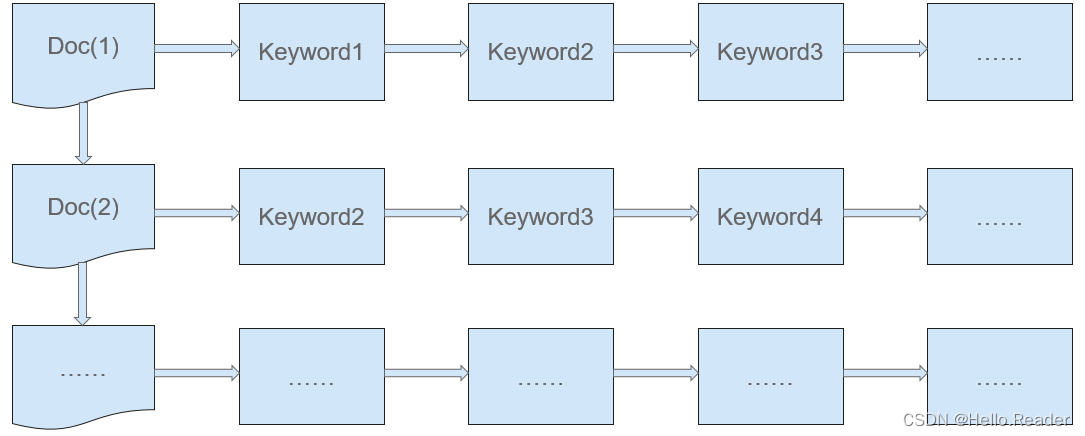
传统的搜索方式(正排序索引,如下图所示)是从关键点出发,然后再通过关键点找到关键点代表的信息中能够满足搜索条件的特定信息,即通过KEY寻找VALUE。通过正排序索引进行搜索,就是从通过文档编号找关键词。
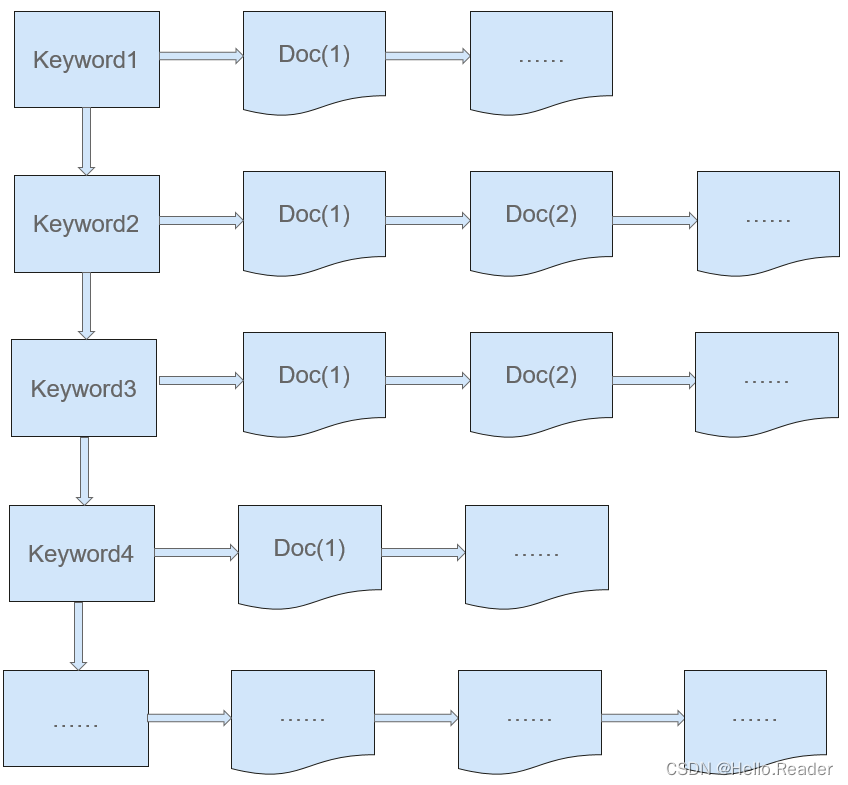
而Solr(Lucene)的搜索则是采用了倒排序索引(如下图所示)的方式,即通过VALUE找KEY。而在中文全文搜索中VALUE就是要搜索的关键词,存放所有关键词的地方叫词典。KEY是文档标号列表(通过文档标号列表可以找到出现过要搜索关键词–VALUE的文档),具体如下面的图所示:通过倒排序索引进行搜索,就是通过关键词查询相对应的文档编号,再通过文档编号找文档,类似于查字典,或通过查书目录查指定页码书的内容。
分布式索引操作流程
Solr分布式索引操作流程如下图所示。
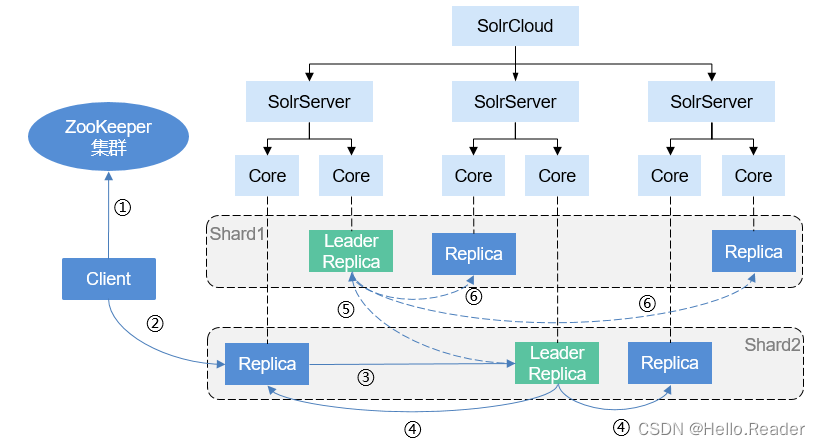
操作流程说明如下:
- 当Client发起一次文档索引请求时,首先将从ZooKeeper集群中获取SolrCloud中SolrServer的集群信息,根据请求中的collection信息,获取任意一台包含该collection信息的SolrServer;
- Client把文档索引请求发送给SolrServer中该collection对应shard中的一个Replica进行处理;
- 如果该Replica不是Leader Replica,则该Replica会把文档索引请求再转发给和自己相同shard中相对应的Leader Replica;
- 该Leader Replica在本地完成文档的索引后,会再把文档索引请求路由给本Shard中的其他Replica进行处理;
- 如果该文档索引的目标shard并不是本次请求的Shard,那么该Shard的Leader Replica会将文档索引请求再次转发给目标Shard的Leader Replica;
- 目标Shard的Leader Replica在本地完成文档的索引后,会再把文档索引请求再次路由给本Shard的其他Replica进行处理。
分布式搜索操作流程:
Solr分布式搜索操作流程如下图所示。
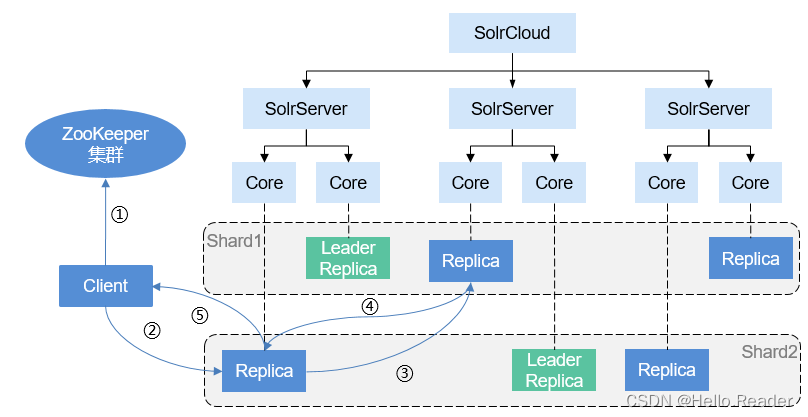
操作流程说明如下:
- 当Client发起一次搜索请求时;Client首先将通过ZooKeeper会获取到SolrServer服务器集群信息,并随机选取一个含有该collection的SolrServer;
- Client把搜索请求发送到该Collection在SolrServer上相对应Shard中的任意一个Replica(可以不为Leader
Replica)进行处理; - 该Replica再根据查询索引的方式,启动分布式查询,基于Collection的Shard个数(在上图中为2个,Shard1和Shard2),把查询转换为多个子查询,并把每个子查询分发到对应Shard的任意一个Replica(可以不为Leader
Replica)中进行处理; - 每个子查询完成查询操作后,并查询结果返回;
- 首次收到查询请求的Replica收到各个子查询的查询结果后,对各个查询结果进行合并处理,然后把最终的查询结果返回给Client。
四、Solr和HDFS的关系
Solr是Apache基金会下的项目,也是Apache Hadoop项目生态系统中重要的一员,Solr可利用HDFS作为其索引文件存储系统。Solr位于结构化存储层,HDFS为Solr提供了高可靠性的存储支持。Solr中的所有索引数据文件都可以存储在HDFS文件系统上。
五、Solr和HBase的关系
HBase提供海量数据存储功能,是一种构建在HDFS上的分布式、面向列的存储系统。Solr索引HBase数据是将HBase数据写到HDFS的同时,Solr建立相应的HBase索引数据。其中索引id与HBase数据的rowkey对应,保证每条索引数据与HBase数据的唯一,实现HBase数据的全文检索。