上期作者推出的融合正余弦和柯西变异的麻雀优化算法,效果着实不错,今天就用它来优化一下CNN-BiLSTM。CNN-BiLSTM的流程:将训练集数据输入CNN模型中,通过CNN的卷积层和池化 层的构建,用来特征提取,再经过BiLSTM模型进行序列预测。CNN-BiLSTM模型有众多参数需要调整,包括学习率,正则化参数,神经网络层数,卷积层数,BatchSize,最大训练次数等。
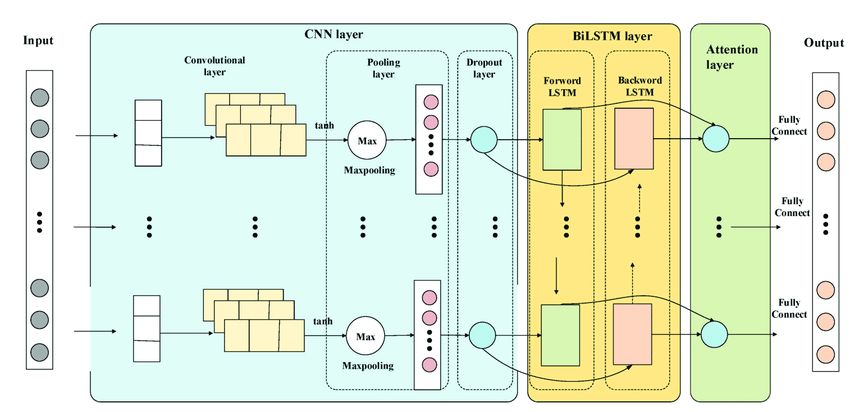
本文采用上一期推出的融合正余弦和柯西变异的麻雀优化算法,融合正余弦和柯西变异的麻雀搜索算法,并与灰狼算法,粒子群算法比较,对CNN-BiLSTM的学习率,正则化参数,BiLSTM隐含层神经元个数进行优化。
数据选用的是一段风速数据,数据较为简单,主要是方便大家后期的替换。数据处理在代码中已经处理好,数据为多输入单输出,即用前n天的数据预测第n+1天的数据。

Part 1 预测效果
优化前:

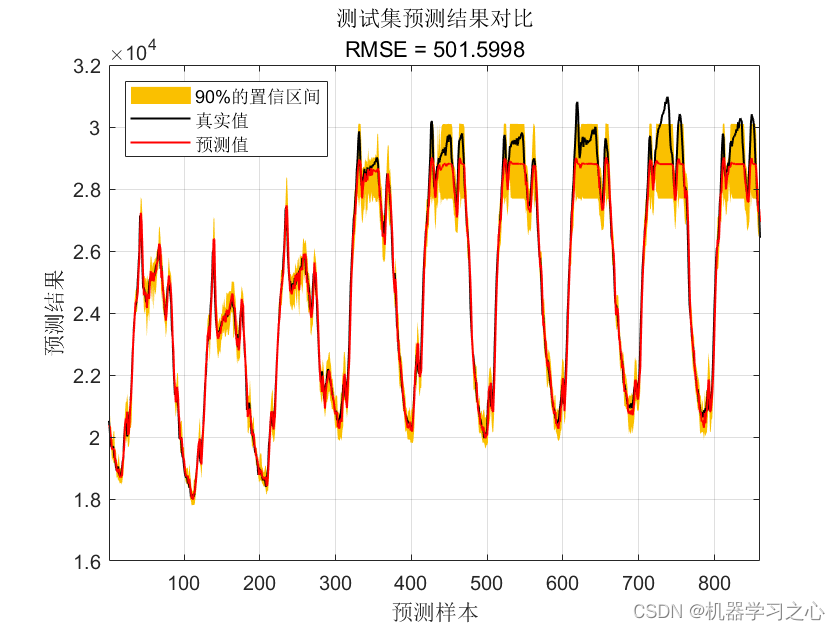
优化后:
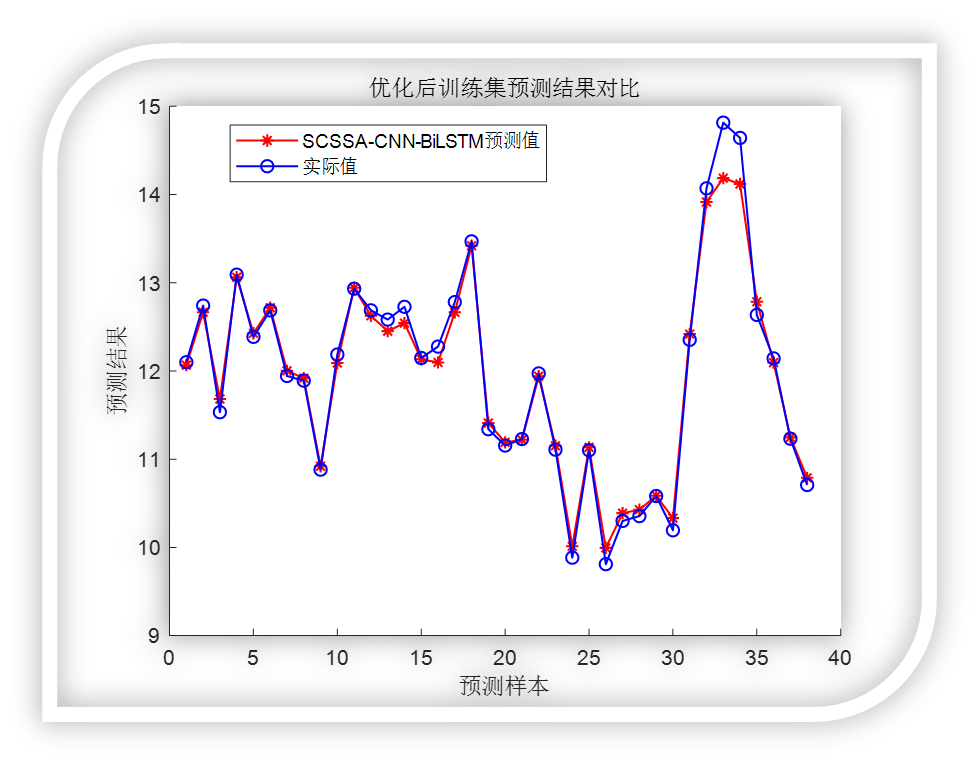
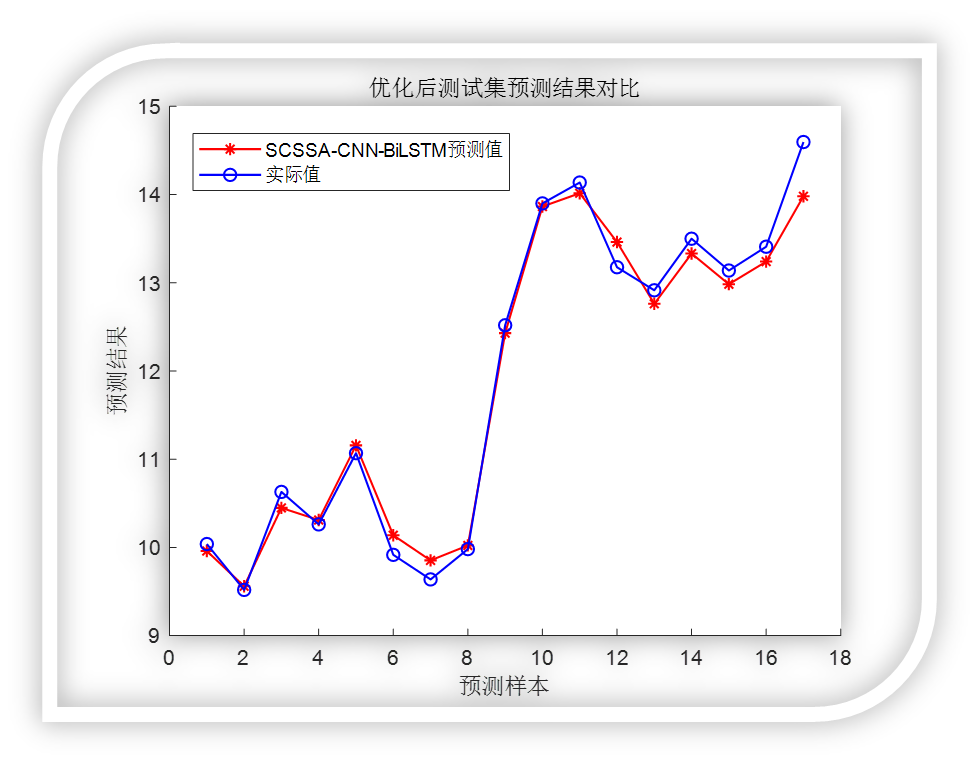
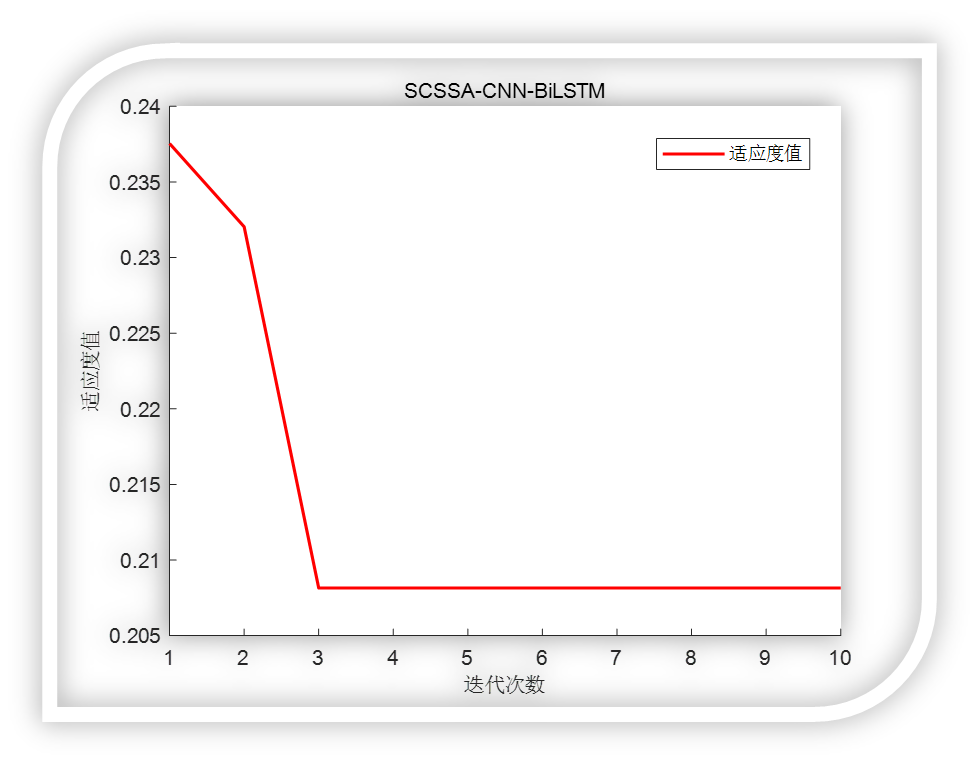

可以看到效果还是杠杠滴!
另外本次代码文件会将“融合正余弦和柯西变异的麻雀搜索算法在CEC函数中的对比代码,也就是这一期的代码一并打包。

Part 2 核心代码
% 参数设置
options0 = trainingOptions('adam', ... % 优化算法Adam
'MaxEpochs', 300, ... % 最大训练次数
'GradientThreshold', 1, ... % 梯度阈值
'InitialLearnRate', 0.01, ... % 初始学习率
'LearnRateSchedule', 'piecewise', ... % 学习率调整
'LearnRateDropPeriod',100, ... % 训练100次后开始调整学习率
'LearnRateDropFactor',0.01, ... % 学习率调整因子
'L2Regularization', 0.002, ... % 正则化参数
'ExecutionEnvironment', 'cpu',... % 训练环境
'Verbose', 1, ... % 关闭优化过程
'Plots', 'none'); % 画出曲线
% 网络训练
net0 = trainNetwork(Train_xNorm,Train_yNorm,lgraph0,options0 );
Predict_Ynorm_Test = net0.predict(Test_xNorm);
Predict_Y_Test = mapminmax('reverse',Predict_Ynorm_Test',yopt);
Predict_Y_Test = Predict_Y_Test';
rmse = sqrt(mean((Predict_Y_Test(1,:)-(Test_y(1,:))).^2,'ALL'));
R2 = 1 - norm(Test_y - Predict_Y_Test)^2 / norm(Test_y - mean(Test_y ))^2;
disp(['优化前的RMSE:',num2str(rmse)])
% 预测集拟合效果图
figure
hold on
plot(Predict_Y_Test,'r-*','LineWidth',1.0)
plot(Test_y,'b-o','LineWidth',1.0)
legend('CNN-BiLSTM预测值','实际值')
ylabel('预测结果')
xlabel('预测样本')
title(['优化前测试集预测结果对比RMSE:',num2str(rmse)])
box off
set(gcf,'color','w')
%% 调用SSA优化CNN-BILSTM
disp('调用SSA优化CNN-BiLSTM......')
% SSA优化参数设置
SearchAgents = 30; % 种群数量 30
Max_iterations = 20; % 迭代次数 20
lowerbound = [0.0001 0.0001 10 10 10]; %五个参数的下限分别是正则化参数,学习率,BiLSTM的三个隐含层个数
upperbound = [0.01 0.01 500 30 30]; %五个参数的上限
dimension = length(lowerbound);%数量,即要优化的LSTM参数个数
[fMin,Best_pos,Convergence_curve,bestnet] = SCSSAforCNNBILSTM(SearchAgents,Max_iterations,lowerbound,upperbound,dimension,Train_xNorm,Train_yNorm,Test_xNorm,Test_y,yopt,n);
L2Regularization = Best_pos(1,1); % 最佳L2正则化系数
InitialLearnRate = Best_pos(1,2) ;% 最佳初始学习率
NumOfUnits1= fix(Best_pos(1,3)); % 最佳神经元个数
NumOfUnits2= fix(Best_pos(1,4)); % 最佳神经元个数
NumOfUnits3= fix(Best_pos(1,5)); % 最佳神经元个数
disp('优化结束,将最佳net导出并用于测试......')
%% 对训练集的测试
setdemorandstream(pi);
Predict_Ynorm_Train = bestnet.predict(Train_xNorm); %对训练集的测试
Predict_Y_Train = mapminmax('reverse',Predict_Ynorm_Train',yopt); %反归一化
Predict_Y_Train = Predict_Y_Train';
% 适应度曲线
figure
plot(Convergence_curve,'r-', 'LineWidth', 1.5);
title('SCSSA-CNN-BiLSTM', 'FontSize', 10);
legend('适应度值')
xlabel('迭代次数', 'FontSize', 10);
ylabel('适应度值', 'FontSize', 10);
box off
set(gcf,'color','w')
%训练集拟合效果图
figure
hold on
plot(Predict_Y_Train,'r-*','LineWidth',1.0)
plot(Train_y,'b-o','LineWidth',1.0);
ylabel('预测结果')
xlabel('预测样本')
legend('SCSSA-CNN-BiLSTM预测值','实际值')
title('优化后训练集预测结果对比')
box off
set(gcf,'color','w')
%% 对测试集的测试
Predict_Ynorm = bestnet.predict(Test_xNorm);
Predict_Y = mapminmax('reverse',Predict_Ynorm',yopt);
Predict_Y = Predict_Y';
figure
hold on
plot(Predict_Y,'r-*','LineWidth',1.0)
plot(Test_y,'b-o','LineWidth',1.0)
legend('SCSSA-CNN-BiLSTM预测值','实际值')
ylabel('预测结果')
xlabel('预测样本')
title('优化后测试集预测结果对比')
box off
set(gcf,'color','w')
%% 回归图与误差直方图
figure;
plotregression(Test_y,Predict_Y,['优化后回归图']);
set(gcf,'color','w')
figure;
ploterrhist(Test_y-Predict_Y,['误差直方图']);
set(gcf,'color','w')
%% 打印出评价指标
% 预测结果评价
ae= abs(Predict_Y - Test_y);
rmse = (mean(ae.^2)).^0.5;
mse = mean(ae.^2);
mae = mean(ae);
mape = mean(ae./Predict_Y);
R = corr(Test_y,Predict_Y);
R2 = 1 - norm(Test_y - Predict_Y)^2 / norm(Test_y-mean(Test_y ))^2;
disp('预测结果评价指标:')
disp(['RMSE = ', num2str(rmse)])
disp(['MSE = ', num2str(mse)])
disp(['MAE = ', num2str(mae)])
disp(['MAPE = ', num2str(mape)])
disp(['相关系数R = ', num2str(R)])
disp(['决定系数R^2为:',num2str(R2)])
disp(['BiLSTM的最佳神经元个数为:', num2str(NumOfUnits1), ',',num2str(NumOfUnits2), ',',num2str(NumOfUnits3)])
disp(['最佳初始学习率为:', num2str(InitialLearnRate)])
disp(['最佳L2正则化系数为:', num2str(L2Regularization)])代码获取方式,后台回复关键词:
TGDM825