阿里雷扎·凯沙瓦尔兹
一、说明
自动编码器是一种学习压缩和重建输入数据的神经网络。它由一个将数据压缩为低维表示的编码器和一个从压缩表示中重建原始数据的解码器组成。该模型使用无监督学习进行训练,旨在最小化输入和重建输出之间的差异。自动编码器可用于降维、数据去噪和异常检测等任务。它们在处理未标记数据时非常有效,并且可以从大型数据集中学习有意义的表示。
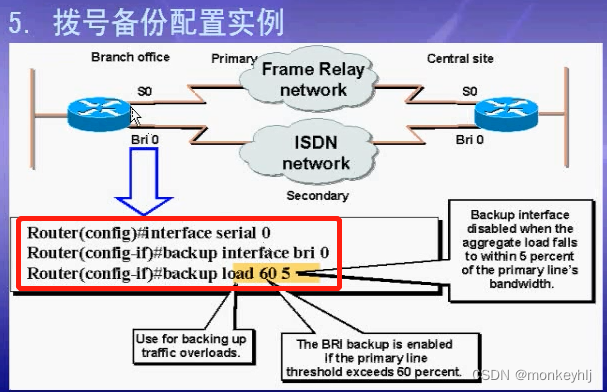
二、自动编码器的工作原理
网络提供原始图像x,以及它们的噪声版本x~。网络尝试重建其输出 x',使其尽可能接近原始图像 x。通过这样做,它学会了如何对图像进行去噪。

源
如图所示,编码器模型将输入转换为小型密集表示形式。解码器模型可以看作是能够生成特定特征的生成模型。
编码器和解码器网络通常都是作为一个整体进行训练的。损失函数惩罚网络创建与原始输入 x 不同的输出 x'。
通过这样做,编码器学会了保留潜在空间限制所需的尽可能多的相关信息,并巧妙地丢弃不相关的部分,例如噪声。解码器学习获取压缩的潜在信息并将其重建为完整的无错误输入。
三、如何实现自动编码器
让我们实现一个自动编码器来对手写数字进行降噪。输入是一个 28x28 灰度缩放的图像,构建一个 128 个元素的矢量。
编码器层负责将输入图像转换为潜在空间中的压缩表示。它由一系列卷积层和全连接层组成。这种压缩表示包含捕获其底层模式和结构的输入图像的基本特征。ReLU用作编码器层中的激活函数。它应用逐元素激活函数,将负输入的输出设置为零,并保持正输入不变。在编码器层中使用ReLU的目标是引入非线性,允许网络学习复杂的表示并从输入数据中提取重要特征。
代码中的解码器层负责从潜在空间中的压缩表示重建图像。它反映了编码器层的结构,由一系列完全连接和转置卷积层组成。解码器层从潜在空间获取压缩表示,并通过反转编码器层执行的操作来重建图像。它使用转置卷积层逐渐对压缩表示进行上采样,并最终生成与输入图像具有相同尺寸的输出图像。Sigmoid 和 ReLU 激活用于解码器层。Sigmoid 激活将输入值压缩在 0 到 1 之间,将每个神经元的输出映射到类似概率的值。在解码器层中使用 sigmoid 的目标是生成 [0, 1] 范围内的重建输出值。由于此代码中的输入数据表示二进制图像,因此 sigmoid 是重建像素值的合适激活函数。
通过在编码器层和解码器层使用适当的激活函数,自动编码器模型可以有效地学习将输入数据压缩到低维潜在空间中,然后从潜在空间重建原始输入数据。激活函数的选择取决于所解决问题的具体要求和特征。
二进制交叉熵用作损失函数,Adam 用作最小化损失函数的优化器。“binary_crossentropy”损失函数通常用于二元分类任务,适用于在这种情况下重建二元图像。它衡量预测输出与真实目标输出之间的相似性。“adam”优化器用于在训练期间更新模型的权重和偏差。Adam(自适应矩估计的缩写)是一种优化算法,它结合了 RMSprop 优化器和基于动量的优化器的优点。它单独调整每个权重参数的学习率,并使用梯度的第一和第二时刻来有效地更新参数。
通过使用二进制交叉熵作为损失函数和Adam优化器,自动编码器模型旨在最小化重建误差并优化模型的参数,以生成输入数据的准确重建。
第 1 部分:导入库和模块
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import input, dense, reshape, flatten, Conv2D, Conv2DTranspose
from tensorflow.keras.models import model from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStop在这一部分中,导入了必要的库和模块。
numpy(导入为 )是用于数值运算的库。npmatplotlib.pyplot(导入为 )是用于打印的库。pltmnist从 导入以加载 MNIST 数据集。tensorflow.keras.datasets- 从 和 导入各种层和模型。
tensorflow.keras.layerstensorflow.keras.models - 优化程序是从 导入的。
Adamtensorflow.keras.optimizers - 回调是从 导入的。
EarlyStoppingtensorflow.keras.callbacks
第 2 部分:加载和预处理数据集
(x_train, _), (x_test, _) = mnist.load_data()在这一部分中,加载 MNIST 数据集并将其拆分为训练集和测试集。相应的标签将被忽略,并且不会分配给任何变量。
第 3 部分:预处理数据集
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
x_train = np.expand_dims(x_train, axis=-1)
x_test = np.expand_dims(x_test, axis=-1)在这一部分中,数据集被预处理:
- 和 中图像的像素值通过除以 0.1 归一化为 255 到 0 的范围。
x_trainx_test - 输入数据的维度使用 展开以包括通道维度。这对于卷积运算是必需的。
np.expand_dims
第 4 部分:向训练集添加随机噪声
noise_factor = 0.5
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)在这一部分中,随机噪声被添加到训练集中:
- 选择0.5的噪声系数来控制噪声量。
- 使用平均值为 0、标准差为 1 的随机噪声样本生成,然后按噪声因子进行缩放。
np.random.normal - 噪声训练集和测试集是通过将噪声添加到原始数据中获得的。
- 对像素值进行裁剪,以确保它们保持在 0 到 1 的有效范围内。
第 5 部分:创建自动编码器模型
input_shape = (28, 28, 1)
latent_dim = 128
# Encoder
inputs = Input(shape=input_shape)
x = Conv2D(32, kernel_size=3, strides=2, activation='relu', padding='same')(inputs)
x = Conv2D(64, kernel_size=3, strides=2, activation='relu', padding='same')(x)
x = Flatten()(x)
latent_repr = Dense(latent_dim)(x)
# Decoder
x = Dense(7 * 7 * 64)(latent_repr)
x = Reshape((7, 7, 64))(x)
x = Conv2DTranspose(32, kernel_size=3, strides=2, activation='relu', padding='same')(x)
decoded = Conv2DTranspose(1, kernel_size=3, strides=2, activation='sigmoid', padding='same')(x)
# Autoencoder model
autoencoder = Model(inputs, decoded)在这一部分中,自动编码器模型是使用编码器-解码器架构创建的:
input_shape定义为 ,表示输入图像的形状。(28, 28, 1)latent_dim设置为 128,这决定了潜在空间的维数。- 编码器层定义:
- 将使用指定的 .
input_shape - 添加了两个分别具有 32 和 64 个过滤器的卷积层,内核大小为 3x3,步幅为 2,激活和填充设置为 。
'relu''same' - 卷积层的输出使用 .
Flatten() - 通过将扁平输出传递到带有神经元的完全连接层来获得潜在表示。
Denselatent_dim - 解码器层定义:
- 添加带有神经元的层以匹配编码器中最后一个特征图的形状。
Dense7 * 7 * 64 - 输出将调整为 使用 .
(7, 7, 64)Reshape - 添加了两个转置卷积层:
- 第一层有 32 个过滤器,内核大小为 3x3,步幅为 2,激活和填充设置为 。
'relu''same' - 第二层有 1 个筛选器,内核大小为 3x3,步幅为 2,激活和填充设置为 。
'sigmoid''same' - 通过指定输入和输出层来创建模型。
autoencoder
第 6 部分:编译自动编码器模型
autoencoder.compile(optimizer=Adam(lr=0.0002), loss='binary_crossentropy')在这一部分中,编译了自动编码器模型:
- 优化器的学习率为 0.0002。
Adam - 损失函数设置为 。
'binary_crossentropy'
第 7 部分:添加提前停止
early_stopping = EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True)在这一部分中,创建了一个提前停止回调:
- 它监视验证丢失 ()。
'val_loss' - 如果验证损失连续 5 个 epoch 没有改善,则停止训练。
- 恢复训练期间模型的最佳权重。
第 8 部分:训练自动编码器
epochs = 20
batch_size = 128
history = autoencoder.fit(x_train_noisy, x_train, validation_data=(x_test_noisy, x_test),
epochs=epochs, batch_size=batch_size, callbacks=[early_stopping])在这一部分中,对自动编码器模型进行了训练:
- 纪元数设置为 100,批大小设置为 128。
- 训练数据以 提供,验证数据以 提供。
(x_train_noisy, x_train)(x_test_noisy, x_test) - 训练过程以指定的周期数、批大小和提前停止回调执行。
- 训练历史记录存储在变量中。
history
第 9 部分:去噪测试图像并显示结果
denoised_test_images = autoencoder.predict(x_test_noisy)
# Display original, noisy, and denoised images
n = 10
plt.figure(figsize=(20, 4))
for i in range(n):
# Original images
ax = plt.subplot(3, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28), cmap='gray')
plt.title("Original")
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# Noisy images
ax = plt.subplot(3, n, i + 1 + n)
plt.imshow(x_test_noisy[i].reshape(28, 28), cmap='gray')
plt.title("Noisy")
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# Denoised images
ax = plt.subplot(3, n, i + 1 + n + n)
plt.imshow(denoised_test_images[i].reshape(28, 28), cmap='gray')
plt.title("Denoised")
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()在这一部分中:
- 通过使用该方法将噪声测试图像通过训练的自动编码器来获得去噪测试图像。
predict - 原始、噪点和去噪图像使用 .
matplotlib.pyplot - 将创建一个包含三行的图形来显示图像。
- 对于每一行,为每个图像创建一个子图。
- 原始图像、噪点图像和去噪图像显示在单独的子图中。
- 为每个子图设置轴标签和标题。
- 结果图使用 表示。
plt.show()
四、结果