文章目录
- 【可更换其他算法,`获取资源`请见文章第5节:资源获取】
- 1. 原始COA算法
- 1.1 开发阶段
- 1.2 探索阶段
- 2. 多阈值Otsu原理
- 3. 部分代码展示
- 4. 仿真结果展示
- 5. 资源获取
【可更换其他算法,获取资源请见文章第5节:资源获取】
1. 原始COA算法
长鼻浣熊优化算法(Cоati Optimization Algorithm,COA)是一种启发式优化算法,灵感来源于长鼻浣熊(Coati)的行为策略。长鼻浣熊优化算法基于长鼻浣熊在觅食过程中的特性和行为模式。长鼻浣熊是一种树栖动物,具有长而灵活的鼻子,用于觅食和捕食。它们通过嗅觉感知周围环境,利用敏锐的视觉和协调的运动能力来寻找食物。
1.1 开发阶段
这个阶段模拟的是浣熊对鬣蜥的攻击策略,对搜索空间中的种群更新的第一个阶段进行建模。在这个策略中,一群浣熊会爬上树,对着一只鬣蜥,并吓唬它,其他几个浣熊会在树下等待鬣蜥掉下来。当鬣蜥掉下来之后,浣熊就会攻击并猎杀它。这个策略使得COA在搜索空间中移动到不同的位置,说明COA在问题解决空间中的全局搜索能力。
在COA的设计中,种群中的最佳位置被假定为鬣蜥的位置。此外,还假设有一般的浣熊能爬上树,另一半在地上等待鬣蜥掉下来。因此,浣熊在树上的位置可以用以下公式描述:

鬣蜥落地后,将其放置在搜索空间中的任意位置。基于这种随机位置,地面上的浣熊可以在搜索空间中移动,用下列公式来描述:

对于每个浣熊计算的新位置,如果它改善了目标函数的值,那么就会被接受,否则,浣熊将保持原先的位置,此过程用以下公式来表示。这个可以被视为贪婪法则。

这里
x
i
P
1
x_{i}^{P1}
xiP1是计算第
i
i
i个浣熊的新位置,
x
i
,
j
P
1
x_{i,j}^{P1}
xi,jP1是它的第
j
j
j维,
F
i
P
1
F_{i}^{P1}
FiP1是它的目标函数值,
r
r
r是
[
0
,
1
]
[0,1]
[0,1]区间内的随机实数。
I
g
u
a
n
a
Iguana
Iguana代表鬣蜥在搜索空间中的位置,这实际上是指种群中最佳个体的位置;
I
g
u
a
n
a
j
Iguana_{j}
Iguanaj是它的第
j
j
j维,
j
j
j是一个整数,从集合{1,2}中随机选择,
I
g
u
a
n
a
G
Iguana^{G}
IguanaG是在地面上的位置,它是随机生成的。
I
g
u
a
n
a
j
G
Iguana_{j}^{G}
IguanajG蠢晰是它的第
j
j
j维,
F
I
g
u
a
n
a
G
F_{Iguana}^{G}
FIguanaG是它的目标函数值。
1.2 探索阶段
在第二阶段即探索阶段的过程中,位置更新模拟的是浣熊在遇到捕食者和逃避捕食者的行为。当食肉动物攻击浣熊时,浣熊就会从它的位置上逃走。浣熊在该策略中的移动使其处于接近其当前位置的安全位置,这代表这COA的局部开发能力。为了模拟这种行为,COA在每个长鼻浣熊个体附近生成一个随机位置,公式如下所示:

与开发阶段中类似,同样使用贪婪选择来决定是替换还是保留原先的位置。
2. 多阈值Otsu原理
ostu方法使用最大化类间方差(intra-class variance, ICV)作为评价准则,利用对图像直方图的计算,可以得到最优的一组阈值组合。
ostu方法不仅适用于单阈值的情况,它可以扩展到多阈值。假设有k个分类,c1,c2,…,ck时,他们之间的类间方差定义为:

比如,k=3时,将原图像的灰度区间分为3个类,此时需要两个阈值,定义类间方差如下:

上面式子中,k1和k2为待确定的两个阈值,使得类间方差最大化的k1和k2就是最优的一组阈值。
对于多阈值的情况,可以采用群智能优化算法来寻找最优的阈值,本篇博客利用蜣螂优化算法来寻找最优的阈值。
3. 部分代码展示
%% 清空环境
clc
clear
close all
%%
img = imread('1.JPG');
%绘制原图
figure
imshow(img);
title('原图')
img_ori=rgb2gray(img);
img=rgb2gray(img);
figure
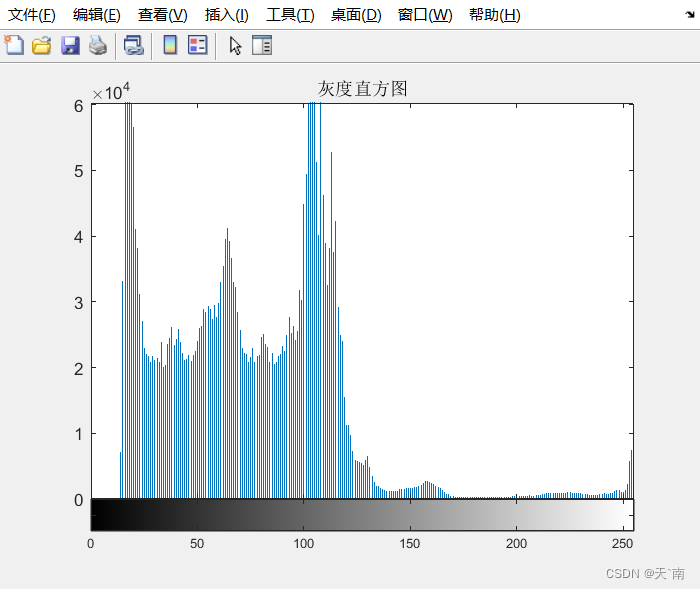
%灰度直方图
imhist(img)
title('灰度直方图')
%目标函数
fitness=@(X)OTSU(img,X);
%阈值个数,优化下边界,上边界,最大迭代次数,种群数量。
num_Threshold=3;
lb=0;
ub=255;
max_iter=100;
sizepop=20;
%调用优化算法
%调用COA对阈值寻优
4. 仿真结果展示
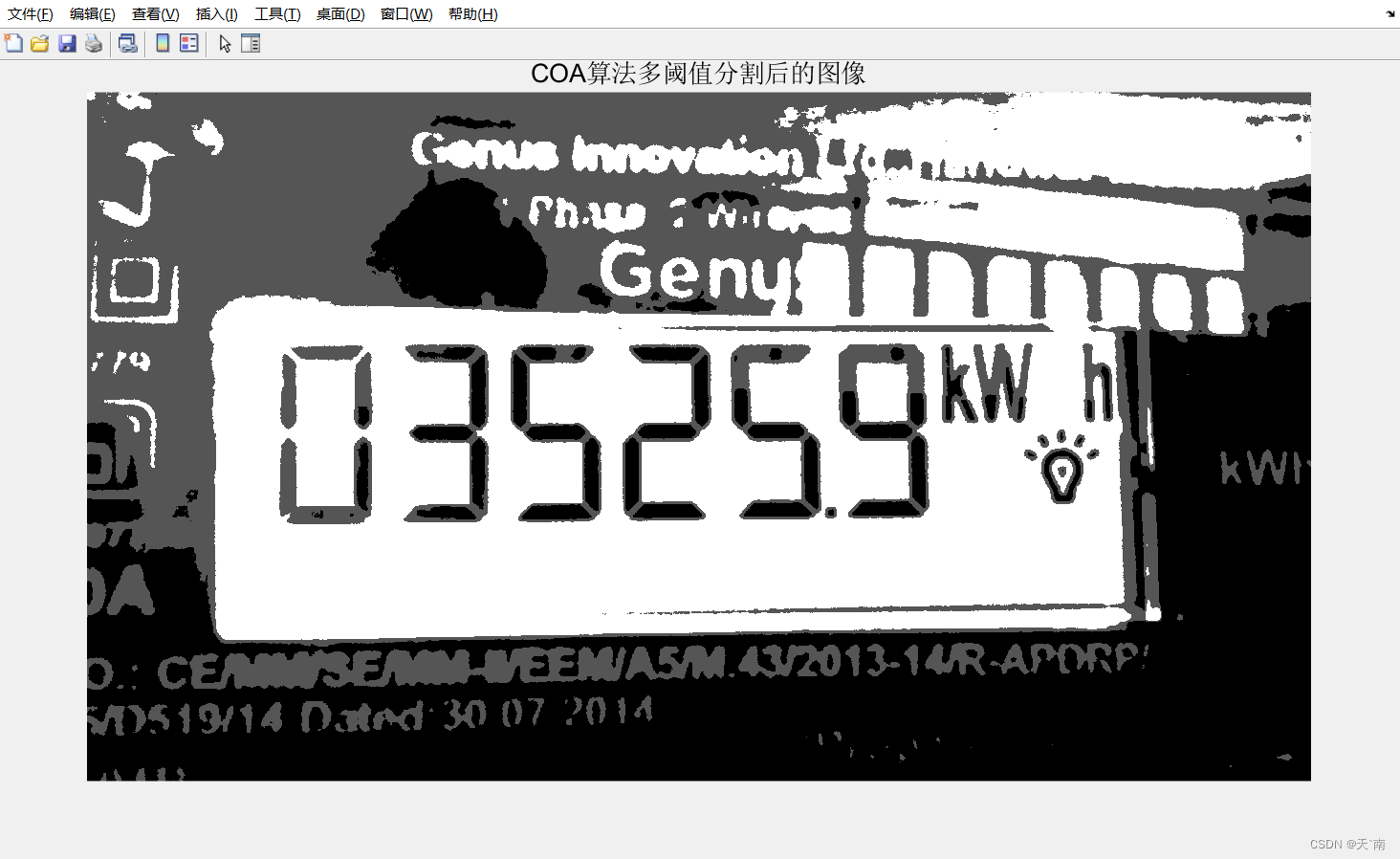
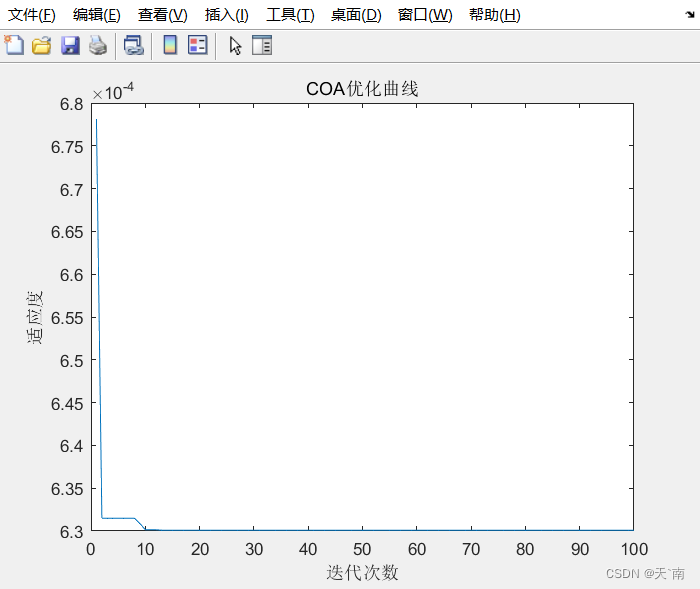
最大类间方差为:1587.0666
COA优化算法优化得到的阈值分别为:148 87 47
5. 资源获取
可以获取完整代码资源



![【PWN · ret2libc】[BJDCTF 2020]babyrop](https://img-blog.csdnimg.cn/6bad9733a9de4563ac38b5d76f946d8a.png)