通过上一章的Spring,我们基本实现了Spring 的读取与存储,但是在操作过程中,读取与存储并没有那么得“简单” 一套流程还是很复杂,所以,本章来介绍更加简单得读取与存储。
在 Spring 中想要更简单的存储和读取对象的核⼼是使⽤注解,也就是我们接下来要学习 Spring 中的相关注解,来存储和读取 Bean。
更简单的存
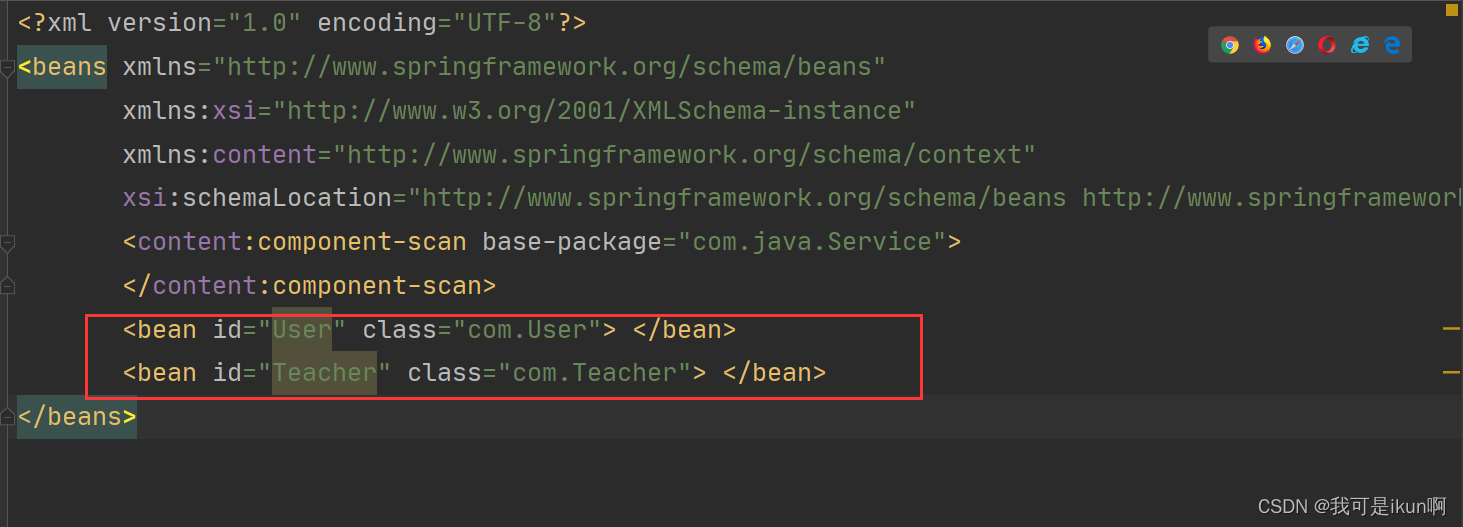
我们现在可以通过写一行注解就代替一行 配置。
配置扫描路径
如果这缺少了这个前置工作,那么整个项目的操作都操作不起来。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:content="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd">
<content:component-scan base-package="com.java.Repository">
</content:component-scan>
</beans>
这个扫描路径就是去扫描 该路径底下是否加了 “五大” 注解,一经发现注解,就给他添加到 Spring(容器) 中。
如果不是在该扫描路径底下,即使是加了扫描路径,也不会加入到Spring 中。
所以,这个配置的扫描路径需要格外注意,不能太大,太大就会导致项目启动的很慢,太小又会导致添加不到。
添加注解存储 Bean 对象
- 类注解:@Controller、@Service、@Repository、@Component、@Configuration。
- ⽅法注解:@Bean。
举个栗子:

通过这个 注解就可以 将对象存储到 Spring 中
当然,存储的前提是 路径配置正确。
其他的四个注解也一样,这里就不一一举例了。
看看结果:

这里首字母小写不完全正确,到获取的 部分再来讲解。
为什么要这么多类注解?
- @Controller:表示的是业务逻辑层;
- @Servie:服务层;
- @Repository:持久层;
- @Configuration:配置层

类注解之间的关系
我们通过查看源码可以知道:

Bean注解

更简单的取
这个取,主要就是针对这个 Bean 来取
上述过程中,这个通过默认名去取的会产生问题,

现在这个方法名叫做 UUUU 我们再来使用刚刚首字母小写的方式,看看能不能拿到:

我们发现它找不到这个 对象了。为啥呢?
我们来看看Bean生成名称的源码:
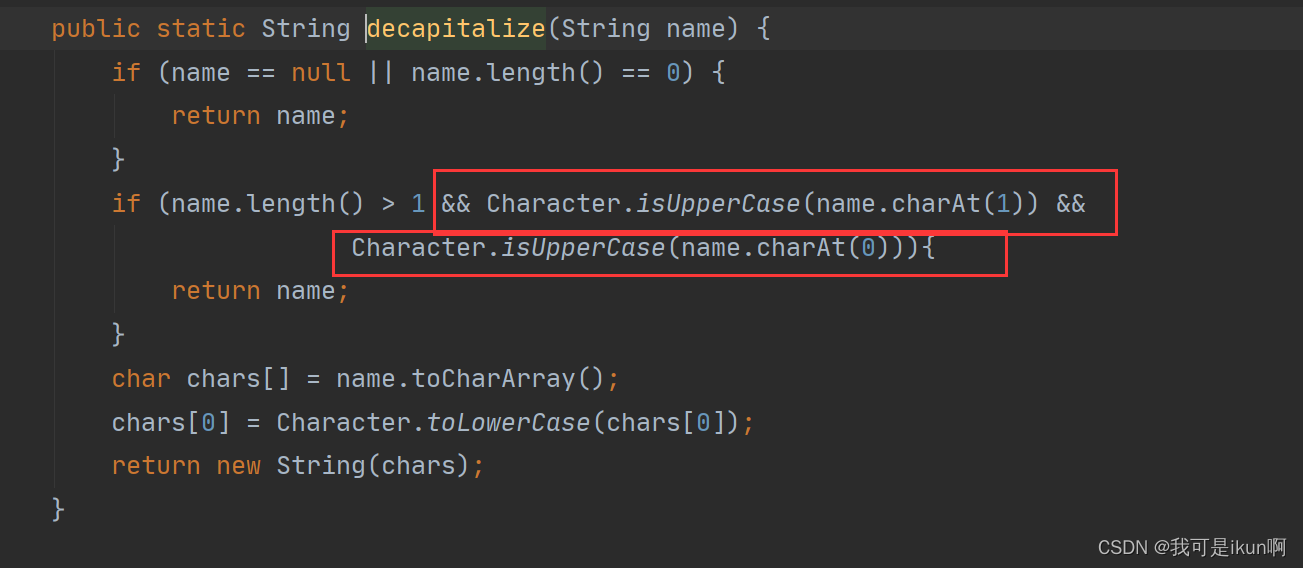
我们可以发现,如果是首字母和第二个字母都大写的话 需要直接返回它的原名。
当然,我们在Bean 注解之后还可以加上名字:

获取 Bean 对象
获取 bean 对象也叫做对象装配,是把对象取出来放到某个类中,有时候也叫对象注⼊
- 属性注⼊
- 构造⽅法注⼊
- Setter 注⼊
属性注入
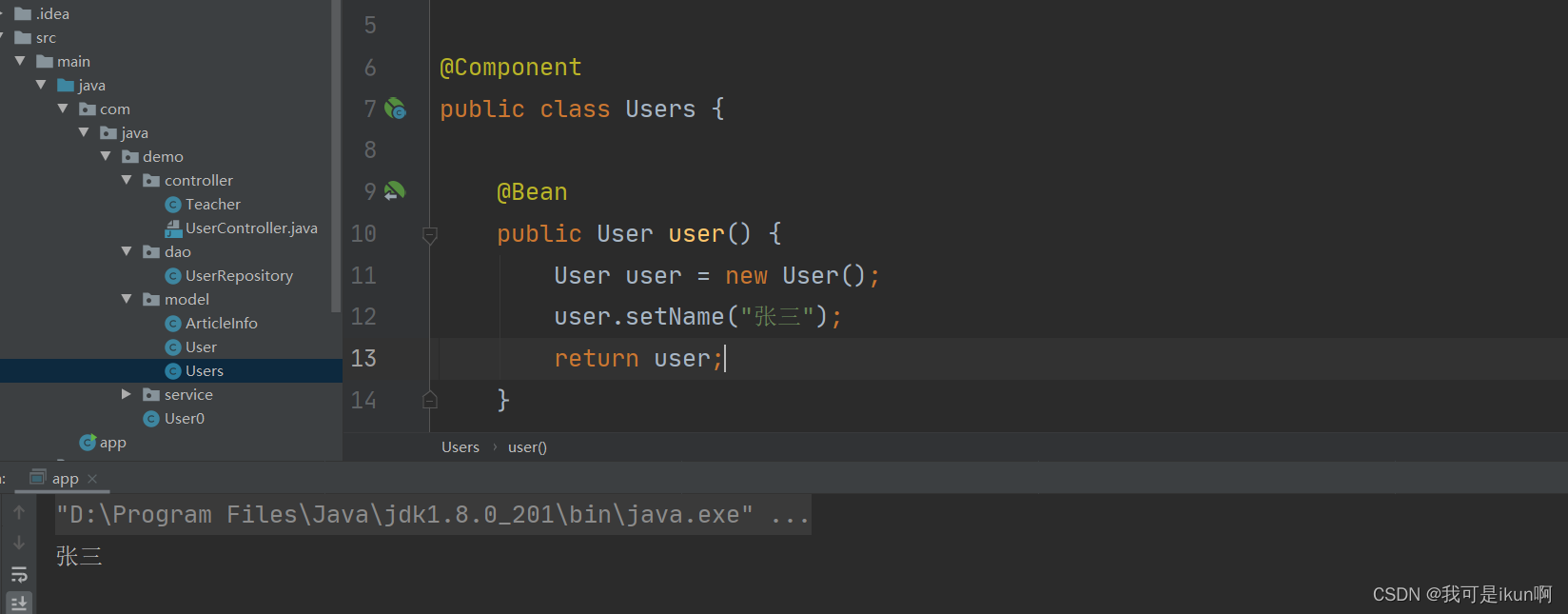
举个例子
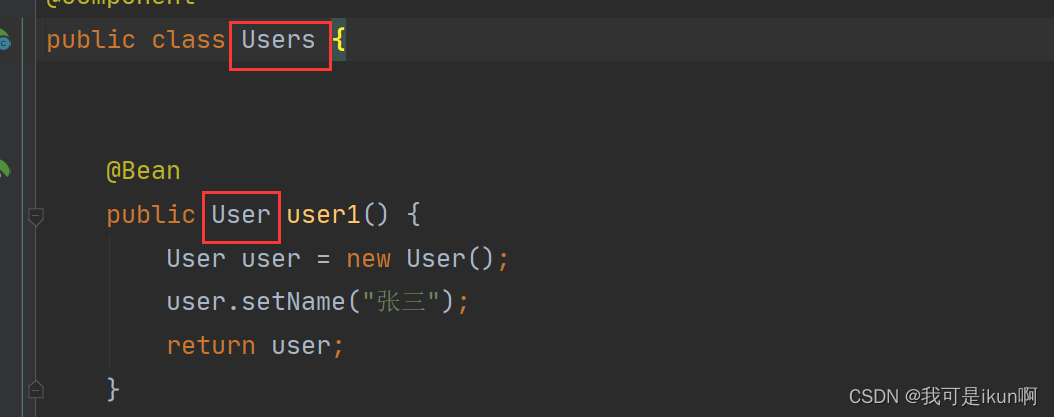
在Users 类中添加了 user1 的方法,返回值是User。


最终是可以获取到User对象。
解释:这里将 Users 这个类注入到了 Spring 容器中,并且还将 user1 这个方法注入到了容器中,它返回的对象 是 User 这个类。 所以可以在后续拿到 User 对象。怎么拿的,就是通过 Autowrid 这个注解(这就是属性注入)。
假设,我们给他再次注入一个 User 对象至容器中,看看还能不能再次属性注入成功

反而还报错,容器中注入了 两个 返回对象为 User 的,它并不知道你具体需要哪个。
我们大致可以推测 Spring 容器存储Bean 对象的逻辑:

@Bean 对象注意事项
如果多个Bean 对象使用相同的名称,那么程序就会报错,但是第一个 Bean 对象之后的对象不会被放到容器中,也就是只有在第一次创建Bean 对象的时候,会将对称和 Bean 名称关联起来,后续在有相同的名称的 Bean 存储的时候,容器会自动忽略。
那么要如何来拿到呢?
我们有如下几种方法:
方法一:在容器中存储不以默认的名字为主,给他手动添加一个 名字,此后就用手动添加的名字

方法二:使用 Qualifier 这个注解,指定 需要找的User 对象
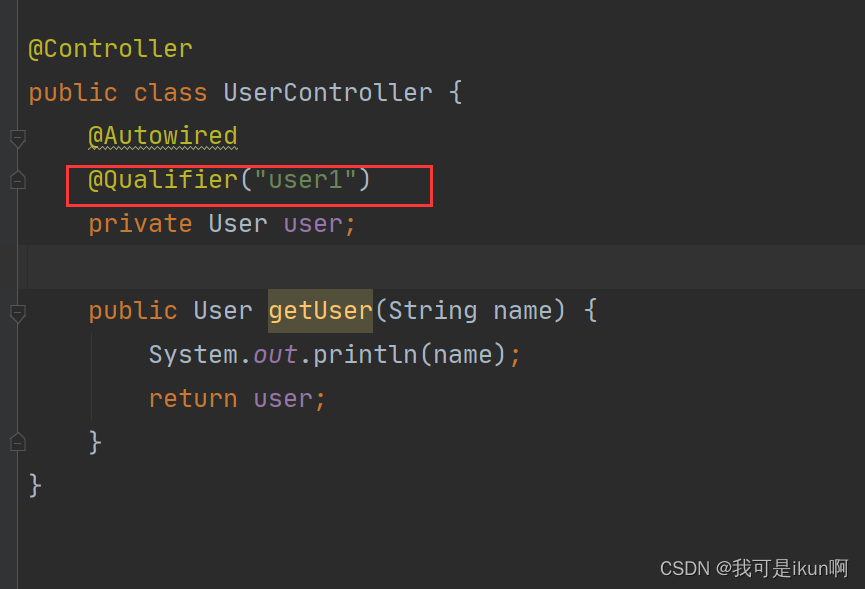
属性注入的特点:
优点:
- 使用简单,直接就可以通过 Autowried 注入
缺点:
- 无法注入 final 修饰的类,final 的特征:要么直接复制,要么在构造方法中赋值
- 通用性问题:只能适用于 IoC容器,如果是非 IoC 容器,只有在使用时才会报 空指针异常。
- 更容易违背单一设计原则,因为使用起来比较方便
Setter 注入
Setter 注入不过就是将 之前的属性改成了一个 set 方法:


Setter注入的特点:
优点:
- 通常 Setter 只 Set 一个属性,所以 Setter 注入 更加符合单一设计原则
缺点:
- Setter 注入 的对象可以被修改,setter 本来就是一个方法,既然时一个方法,那么就可能被多次调用和修改
构造方法注入
构造方法注入是 Spring 4.0 之后推荐的注入方法
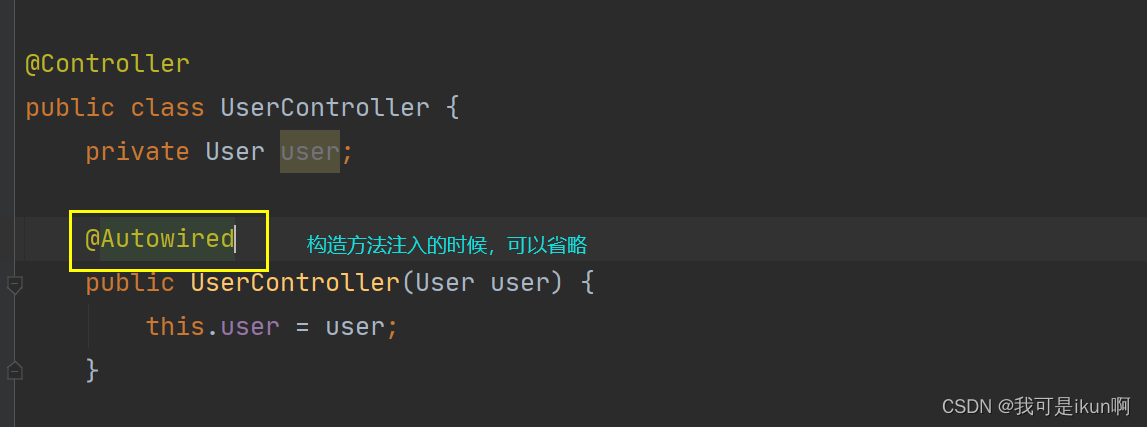
构造方法注入的特点:
优点:
- 可以注入一个final 修饰的变量
- 注入的对象不会被修改,因为 构造方法只加载一次
- 构造方法注入可以保证诸如对象完全初始化
- 构造方法注入通用性更好
缺点
- 写法比属性注入复杂
- 使用构造方法注入无法解决循环依赖的问题(这里涉及到 Spring 三级缓存,以后再说)
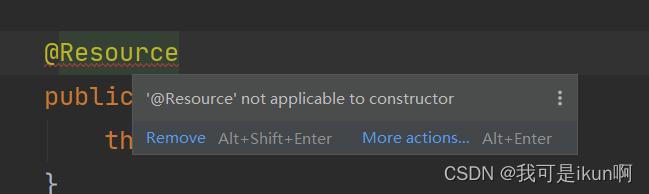
@Resource 另一种关键字
除了 @Autowired 还有一个 注解
 我们可以看到它来自于 Java 拓展类
我们可以看到它来自于 Java 拓展类
并且它不能作用在构造方法上:
@Autowired 和 @Resource 的区别
- 出身不同:@Autowired 来⾃于 Spring,⽽ @Resource 来⾃于 JDK 的注解;
- 使⽤时设置的参数不同:相⽐于 @Autowired 来说,@Resource ⽀持更多的参数设置,例如name 设置,根据名称获取 Bean。
- @Autowired 可⽤于 Setter 注⼊、构造函数注⼊和属性注⼊,⽽ @Resource 只能⽤于 Setter 注⼊和属性注⼊,不能⽤于构造函数注⼊
总结
1. 将对象存储到 Spring 中:
- a. 使⽤类注解:@Controller、@Service、@Repository、@Configuration、@Component【它们之间的关系】
- b. 使⽤⽅法注解:@Bean【注意事项:必须配合类注解⼀起使⽤】
2. Bean 的命名规则:
- ⾸字⺟和第⼆个字⺟都⾮⼤写,⾸字⺟⼩写来获取 Bean,如果⾸字⺟和第⼆个字⺟都是⼤写,那么直接使⽤原 Bean 名来获取 Bean。
3. 从 Spring 中获取对象:
- a. 属性注⼊
- b. Setter 注⼊
- c. 构造函数注⼊(推荐)
4. 注⼊的关键字有:
- a. @Autowired
- b. @Resource
5. @Autowired 和 @Resource 区别:
出身不同; 使⽤时设置参数不同 @Resource ⽀持更多的参数,⽐如 name