目录
一、URL类
1. URL类基本概念
2. 构造器
3. 常用方法
二、爬虫实例
1. 爬取网络图片(简易)
2. 爬取网页源代码
3. 爬取网站所有图片
一、URL类
1. URL类基本概念
URL:Uniform Resource Locator 统一资源定位符
- 表示统一资源定位符,指向万维网上的“资源”的指针。用于区分、定位资源
- 一个标准的URL必须包括:protocol(方案或协议)、host(主机)、port(端口)、path(路径)、parameter(查询参数)、anchor(锚点)
- 通过URL我们可以访问Internet上的各种网络资源,比如最常见的WWW,FTP站点。浏览器通过解析给定的URL可以在网络上查找相应的文件或其他资源。
- 如 :http://www.goole.com:80/index.html , 分四部分组成:协议、存放资源的主句域名、端口号、资源文件名
2. 构造器
| 构造器 | 说明 |
| URL(String spec) | 从String表示形成一个UL对象 |
3. 常用方法
| 常用方法 | 说明 |
| String getProtocol() | 获取此URL的协议名称 |
| String getHost() | 获取此URL的主机名 |
| Int getPort() | 获取此URL的端口号 |
| String getPath() | 获取此URL的路径部分 |
| String getFile() | 获取此URL的文件名 |
| String getQuery() | 获取参数 |
| String getRef() | 获取锚点 |
二、爬虫实例
1. 爬取网络图片(简易)
第一步:也是最重要的一步!首先找到一张非常man的图片然后赋值图像路径

第二步:编码
/** 通过URL对象完成简单的爬虫功能(保存网络图片) */
try {// 创建URL对象 , 将网络资源路径传递到对象进行绑定
URL url = new URL("https://pic3.zhimg.com/v2-41d65e3171d35d24f3fda527377ab2b6_r.jpg");
// 通过ur1对象打来并且激活网络流来获取该图片资源
// 同字节输入流(边读边写操作)
InputStream is = url.openStream();
// 创建爬虫后要写入的文件
FileOutputStream fos = new FileOutputStream(new File("E:\\man.jpg"));
int len = 0;
while ((len = is.read()) != -1) {
fos.write(len);
}
// 关团资源
fos.close();
is.close();
} catch (Exception e) {
e.printStackTrace();
}最后运行代码就可在指定爬到磁盘找到文件啦

2. 爬取网页源代码
第一步:先在指定磁盘新建一个txt文件用于保存爬下的资源

第二步:找到一个网站将网站路径赋值下来

第三步:编码
/** 通过URL对象完成简单的爬虫功能(保存网页源代码) */
try {
// 创建URL对象,将网络资源路径传递到该对象进行绑定
URL url2 = new URL("https://blog.csdn.net/Justw320/article/details/131817953");
// 通过ur1对象打开并且激活网络流来获取网页资源
InputStream openStream = url2.openStream();
InputStreamReader read = new InputStreamReader(openStream, "UTF-8");
BufferedReader br = new BufferedReader(read);
// 创建爬虫后要写入的文件
FileOutputStream fos = new FileOutputStream(new File("E:\\url.txt"));
OutputStreamWriter osw = new OutputStreamWriter(fos);
BufferedWriter bw = new BufferedWriter(osw);
// 定文空变量来储存爬下来的内容
String str = "";
while ((str = br.readLine()) != null) {
bw.write(str);
bw.newLine();
bw.flush();
}
// 关团资源
bw.close();
osw.close();
fos.close();
br.close();
read.close();
openStream.close();
} catch (Exception e) {
e.printStackTrace();
}最后运行代码找到之前新建的txt文件:

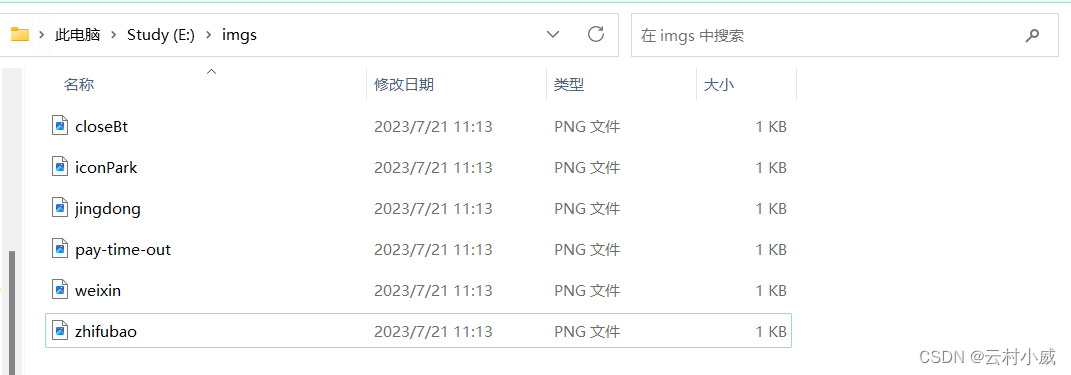
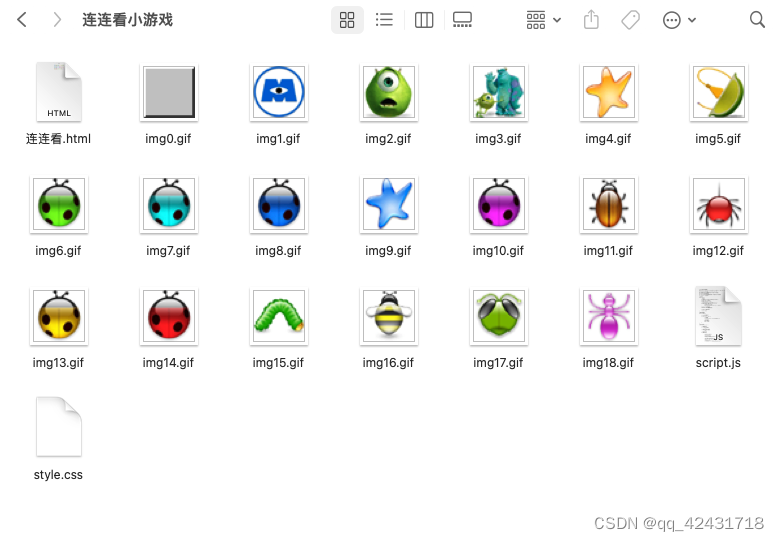
3. 爬取网站所有图片
首先找个没有动态源代码的的网页就是不是通过js传值的,很难找,小编也是找了自己的博客网站进行爬取,现在大多数网站都有反爬虫技术😭,有兴趣的可以去自行扩展都是可刑的👍,这里只是一个案例供参考!
package com.net;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
*
* @author 云村小威
*
* @2023年7月21日 上午10:48:54
*/
public class Getphoto {
public static void main(String[] args) throws Exception {
// 定义URL对象,传入网络资源路径
URL url = new URL("https://blog.csdn.net/Justw320/article/details/131817953");
// 通过url对象打开网络流来获取网络资源
InputStream openStream = url.openStream();
// 转换字符流并优化缓冲
BufferedReader br = new BufferedReader(new InputStreamReader(openStream, "UTF-8"));
// 每次读取一行,拼接到变量中
StringBuffer sb = new StringBuffer(); // 保存源码信息
String str = "";
while ((str = br.readLine()) != null) {
// 每次读取一行拼接到sb变量中
sb.append(str + "\n");
}
// 关闭流
br.close();
openStream.close();
/**
* 获取源码内容,进行正则处理 拿到源码所有img内容
*/
// 将源码信息转成字符串进行保存
String count = sb.toString();
// 定义正则表达式
//<img src="https://csdnimg.cn/identity/nocErtification.png" alt="">
String zheng = "<img\\ssrc=\"https://([^>\"]+)\">";
// 给正则表达式一个匹配模式
Pattern compile = Pattern.compile(zheng);
Matcher matcher = compile.matcher(count);
// 循环所有正则规定的表达式路径
while (matcher.find()) {
// 1.构建URL
URL imgUrl = new URL("http://" + matcher.group(1));
/* 取到子字符串中的src分组中的值(图片地址) */
String group = matcher.group(1);
/* 取到图片的名字 */
String fileName = group.substring(group.lastIndexOf("/"));
// 2.打开网络流 并将字节转成缓冲字节流
InputStream openStream2 = imgUrl.openStream();
BufferedInputStream bis = new BufferedInputStream(openStream2);
// 输出流 将图片写入到指定文件中
BufferedOutputStream bos = new BufferedOutputStream(
new FileOutputStream(new File("E:\\imgs" + fileName)));
// 每次读取一个字节数组
byte[] bytes = new byte[1024];
int len = 0;
while ((len = bis.read(bytes)) != -1) {
// 写入到文件中
bos.write(bytes);
bos.flush();
}
// 关闭资源
bos.close();
bis.close();
openStream2.close();
}
}
}
1. 通过代码打印count变量(这里就一个一个运行了,可参考代码这里的count是通过url爬取到的所有源代码)
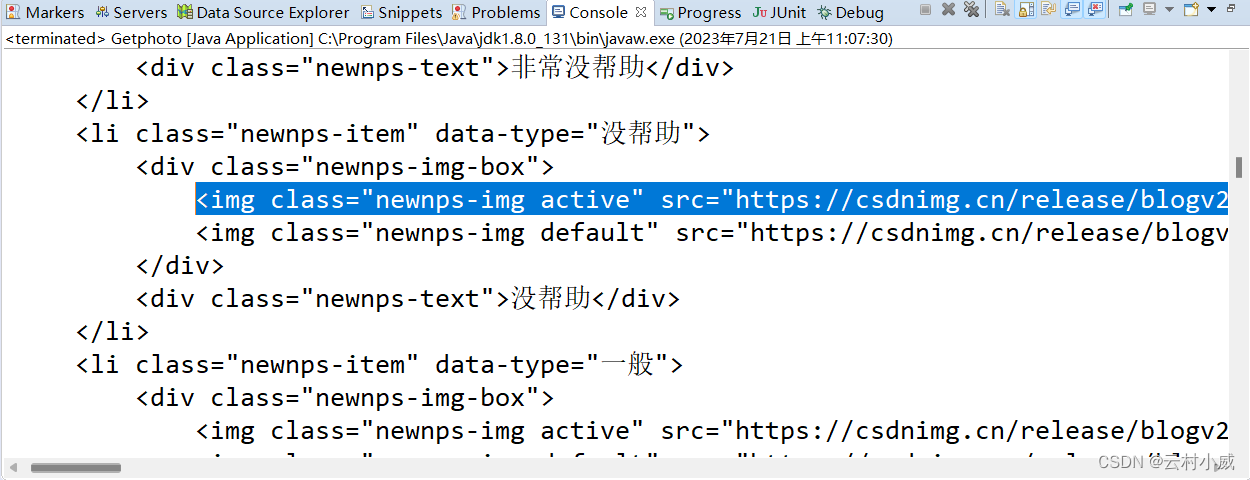
2. 找到img(图片标签), 找到它们的规律设置正则这里很重要!
最后运行代码,就可在指定爬取路径查看爬取到的图片了!