hive文件格式:
概述:
为Hive表中的数据选择一个合适的文件格式,对提高查询性能的提高是十分有益的。Hive表数据的存储格式,可以选择text file、orc、parquet、sequence file等。
文本文件:
文本文件就是txt文件,我们默认的文件类型就是txt文件
ORC文件:
ORC介绍:
ORC(Optimized Row Columnar)file format是Hive 0.11版里引入的一种列式存储的文件格式。ORC文件能够提高Hive读写数据和处理数据的性能。
我们文件一般都是一个二维表,行式存储就是以一行数据为一个单位,存储在相邻的位置,列示存储是以一列数据为单位,一个单位内的数据放在相邻的位置。
如下图两种方式的比较:
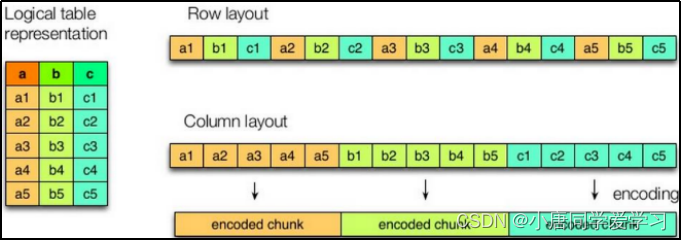
在日常使用的时候hive查询出来的大部分是大量列信息,少量使用where进行条件查询
orc格式在存储的过程中会在hive表上进行横向切分,分割成两次分别进行列式存储
对分割后的数据进行列式存储时,会把它存储到orc文件的一个strip(条带)中,剩下的数据存入其他条带中,条带中并不止存对应的列,还存有一个indexdata--索引(存放每列区(column)的最大值,最小值,行位置)(可以减少大量io操作)默认10000行记录一个索引。
在文件最后还存有一个StripeFooter(存放每个column的编码信息---在存入orc文件的时候并不会按照原表进行存储而是会进行编码存储)
在文件开头有一个header:ORC(可以用于判断文件类型)
文件的底部还有一个FileFooter(存储的有header的长度,各Strip的信息:strips的起始位置,索引长度,数据的长度,StripsFooter的长度等,还存储有各column的统计信息:最值,hashNull)
ORC文件还有一个PostScript,保存这FileFooter的长度,文件压缩的参数,文件的版本等信息。
还有一个区域用于保存Postscrip的长度(文件的最后一个字节)

读取ORC文件步骤:
一般读取ORC文件是从文件末尾开始,先进行读取最后一个字节(Postscript的长度),再通过得到的长度从倒数第二个字节进行向前推到Postscript的起始位置开始读取,从Postscript的数据中的得到File Footer的长度,再进行向前推进行访问,让后就可以根据File Footer中的内容进行定位。
建表语句:
create table orc_table
(column_specs)
stored as orc
tblproperties (property_name=property_value, ...);column_speccs是建表语句
tblproperties (property_name=property_value, ...)是一些建表的参数
| 参数 | 默认值 | 说明 |
| orc.compress | ZLIB | 压缩格式,可选项:NONE、ZLIB,、SNAPPY |
| orc.compress.size | 262,144(256kb) | 每个压缩块的大小(ORC文件是分块压缩的) |
| orc.stripe.size | 67,108,864(64MB一般与Hadoop中的块大小一致Hadoop2.x后是128MB) | 每个stripe的大小 |
| orc.row.index.stride | 10,000 | 索引步长(每隔多少行数据建一条索引) |
eg:
create table orc_table
( id int,
name string
)
stored as orc;在导入数据的时候不能从文本文件load到orc文件(因为load其实是文件的复制,是带有格式的,在导入的时候是没有关系的,但是在读的是时候是不能正确读出的)
文本文件数据如何导入到orc格式的表中?
我们可以建立一个临时表,把文本文件中的数据导入到临时表中,通过insert+select的方式进行导入。(走计算)
Parquet文件:
Parquet文件是Hadoop生态中的一个通用的文件格式,它也是一个列式存储的文件格式。
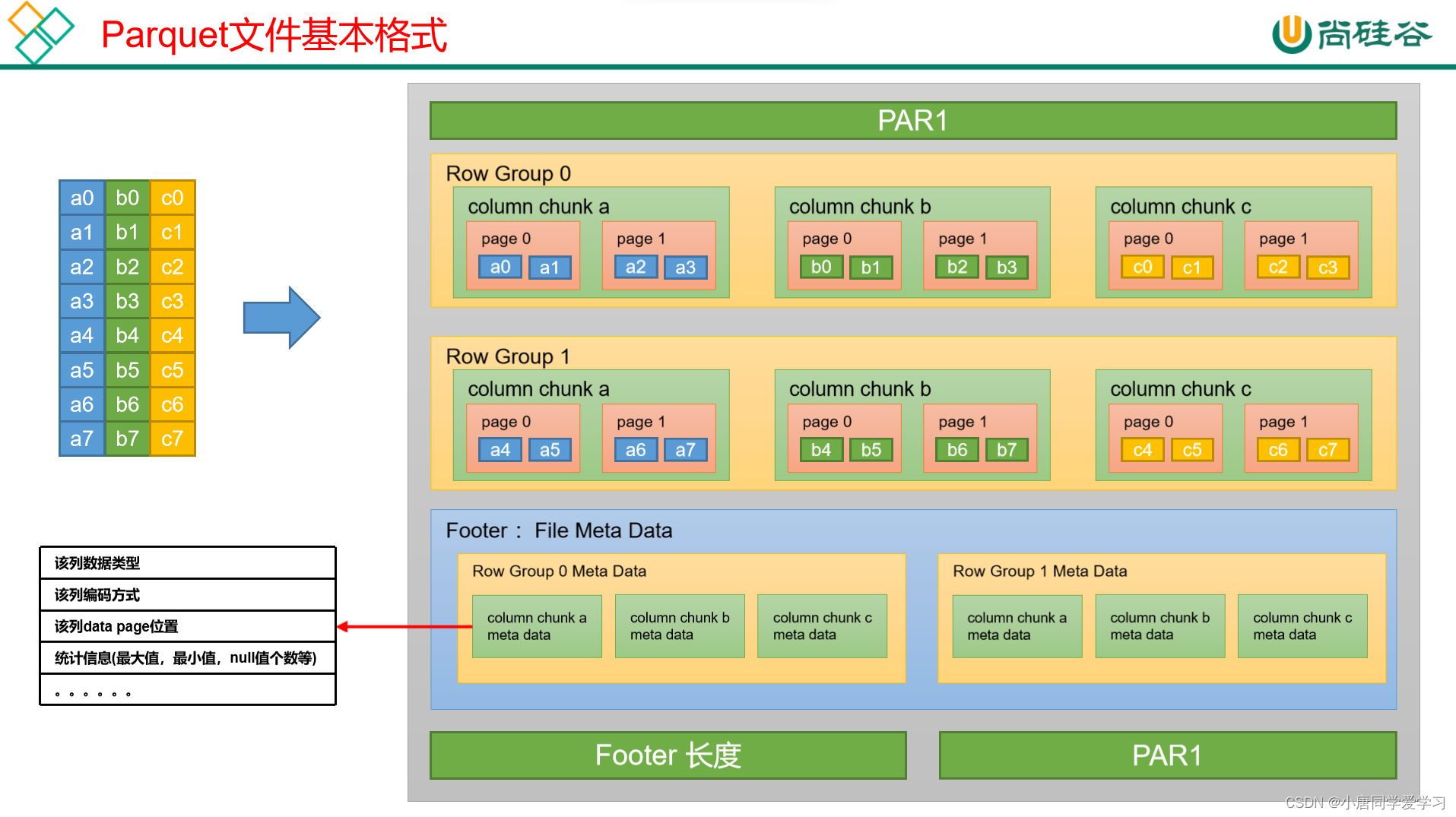
Parquet文件也会对表进行横向切分,切分后会存入到行组中(Row Group),在行组中的数据的每个列都形成一个列块(column chunk)列块中的数据会再分为页块(page)。
最后还有Footer(File Meta Data)中存储了每个行组(Row Group)中的每个列快(Column Chunk)的元数据信息,元数据信息包含了该列的数据类型、该列的编码方式、该类的Data Page位置等信息。File Meta Data中的Row Group的数量是与上边Row Group进行一一对应的。
在Parquet文件的开头与结尾都会占用4个字节进行存储 PAR1 (是Parquet的简写+版本号)
还会在下边保存Footer的长度
详细如图:
Parquet文件基本语法:
Create table parquet_table
(column_specs)
stored as parquet
tblproperties (property_name=property_value, ...);支持的参数如下:
| 参数 | 默认值 | 说明 |
| parquet.compression | uncompressed | 压缩格式,可选项:uncompressed,snappy,gzip,lzo,brotli,lz4 |
| parquet.block.size | 134217728 (128mb) | 行组大小,通常与HDFS块大小保持一致 |
| parquet.page.size | 1048576(1m) | 页大小 |
eg:
create table parquet_table
( id int,
name string
)
stored as parquet ;
压缩:
Hive表数据进行压缩:
在Hive表中和计算过程中,保持数据的压缩,对磁盘空间的有效利用和提高查询性能都是十分有益的。
注:在Hive中,不同文件类型的表,声明数据压缩的方式是不同的。
1)TextFile
若一张表的文件类型为TextFile,若需要对该表中的数据进行压缩,多数情况下,无需在建表语句做出声明。直接将压缩后的文件导入到该表即可,Hive在查询表中数据时,可自动识别其压缩格式,进行解压。
我们怎么让我们的hive表是压缩的那?
(1)我们使用load语句,load的原表就是一个压缩的文件,可以直接进行压缩
(2)使用insert into 语句,如果使用这种方式就需要进行设置参数。
需要注意的是,在执行往表中导入数据的SQL语句时,用户需设置以下参数,来保证写入表中的数据是被压缩的。
--SQL语句的最终输出结果是否压缩
set hive.exec.compress.output=true;
--输出结果的压缩格式(以下示例为snappy)
set mapreduce.output.fileoutputformat.compress.codec =org.apache.hadoop.io.compress.SnappyCodec;2)ORC
若一张表的文件类型为ORC,若需要对该表数据进行压缩,需在建表语句中声明压缩格式如下:
create table orc_table
(column_specs)
stored as orc
tblproperties ("orc.compress"="snappy");3)Parquet
若一张表的文件类型为Parquet,若需要对该表数据进行压缩,需在建表语句中声明压缩格式如下:
create table orc_table
(column_specs)
stored as parquet
tblproperties ("parquet.compression"="snappy");计算过程中使用压缩:
计算过程就是mapreduce的过程。
1)单个MR的中间结果进行压缩:
这个就是在map阶段后(shuffer)的数据进行压缩,压缩后可以 降低shuffle阶段的网络IO
参数如下:
--开启MapReduce中间数据压缩功能
set mapreduce.map.output.compress=true;
--设置MapReduce中间数据数据的压缩方式(以下示例为snappy)
set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;2)单条SQL语句的中间结果进行压缩:
这里指的是有些SQL语句是比较复杂的需要多个MR阶段,则会对两个MR之间的临时数据进行压缩
可通过以下参数进行配置:
--是否对两个MR之间的临时数据进行压缩
set hive.exec.compress.intermediate=true;
--压缩格式(以下示例为snappy)
set hive.intermediate.compression.codec= org.apache.hadoop.io.compress.SnappyCodec;