前言:
最左匹配的基础是联合索引
联合索引
联合索引也称为符合索引,适用于多条件查询。
简单说,它是按多个列建立起来的索引,此外联合索引也是有顺序的。
如下图,以A列和B列建立复合索引,某一层节点,记录了从索引(5, 8)到(8, 3),这个值可能来自哈希映射。也可能本身就是代表一定含义。
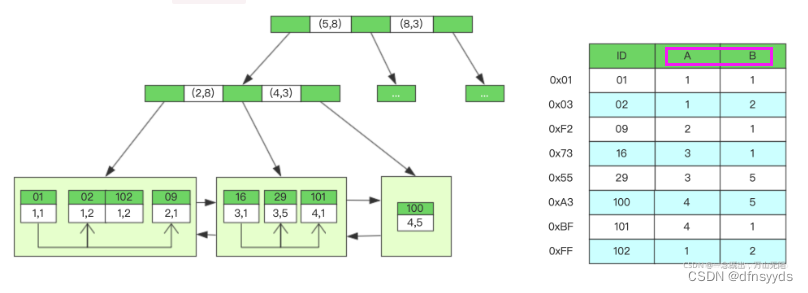
InnoDB会使用主键索引B+树维护索引和数据文件,同样联合索引(A, B)也会生成一个B+树。对于建立的索引,如右图,按从左到右建立的索引内部排序是先以A有序,当A数值相等,再根据B排序。
所以会有如下规律:
- 因为A才有序,所以用B=1,或单纯用B作为查询条件无法使用索引,因为联合索引按最左匹配原则,以左边A开始建立索引。
- 当最左匹配原则遇上范围查询,就会停止,比如A=1,B=2,A,B都可以使用索引,而A>1 and B = 2,A可以用索引,而B不行,因为A值是范围,而这个范围内的B无序。所以索引会失效。
- 当A值相等的情况下,B值是按值排序的,这种顺序是局部的,但是A > 1 and B = 2,A 字段可以匹配上索引,但 B 值不可以,因为 A 的值是一个范围,在这个范围中 B 是无序的。
联合索引查询流程
InnoDB会使用主键索引,同样联合索引(A, B)也会生成B+树,只不过
联合索引B+树的data存储的是联合索引所在行的主键值。
所以**涉及回表*。
最左匹配原则
最左优先,以最左边为起点任何连续的索引都能匹配上,但遇到范围查询,就会停止匹配。这和联合索引的构建方式即存储结构有关系。
简答说,问最左匹配就讲联合索引的构建规则
最左匹配原则说明:
· 如果查询A =1,A字段能用上索引,根据最左匹配原则,即索引是按A列构建的,数据自然全局有序
· 如果查询A=1,and B=2,A,B字段都能用索引,MySQL查询优化器会判断纠正这条SQL语句应该以什么顺序执行效率最高,最终还是会使用到最左匹配原则。
· 若查B=2,也能用到索引,用explain()结果中的type字段是一个index,与all区别在于它只遍历索引树,这也比单纯的全表扫描要快,但是远不如上面三种,而上述的type字段是ref。
索引下堆
需求:检索出表中名字第一个字是张,而且没有删除的信息(is_del = 1)
select * from t_user where name like '张%' and is_del=1
mysql5.6之前,非聚簇或者联合索引也属于非聚簇索引,最后找到的索引B+树节点对应值只是某一行的主键,所以还需要再去根据当前主键去寻找,这个过程是回表。而索引下堆能够解决联合索引的回表问题。
其实张开头的这种模糊查询,找到所有张后,每条张的数据都回表一次,使用索引下堆,会先检查索引字段中是否包含了查询过程中的字段,如果不符合,就先去掉,这样就减少了回表次数。