目录
go 模块与包复习(Init函数 - go mod)
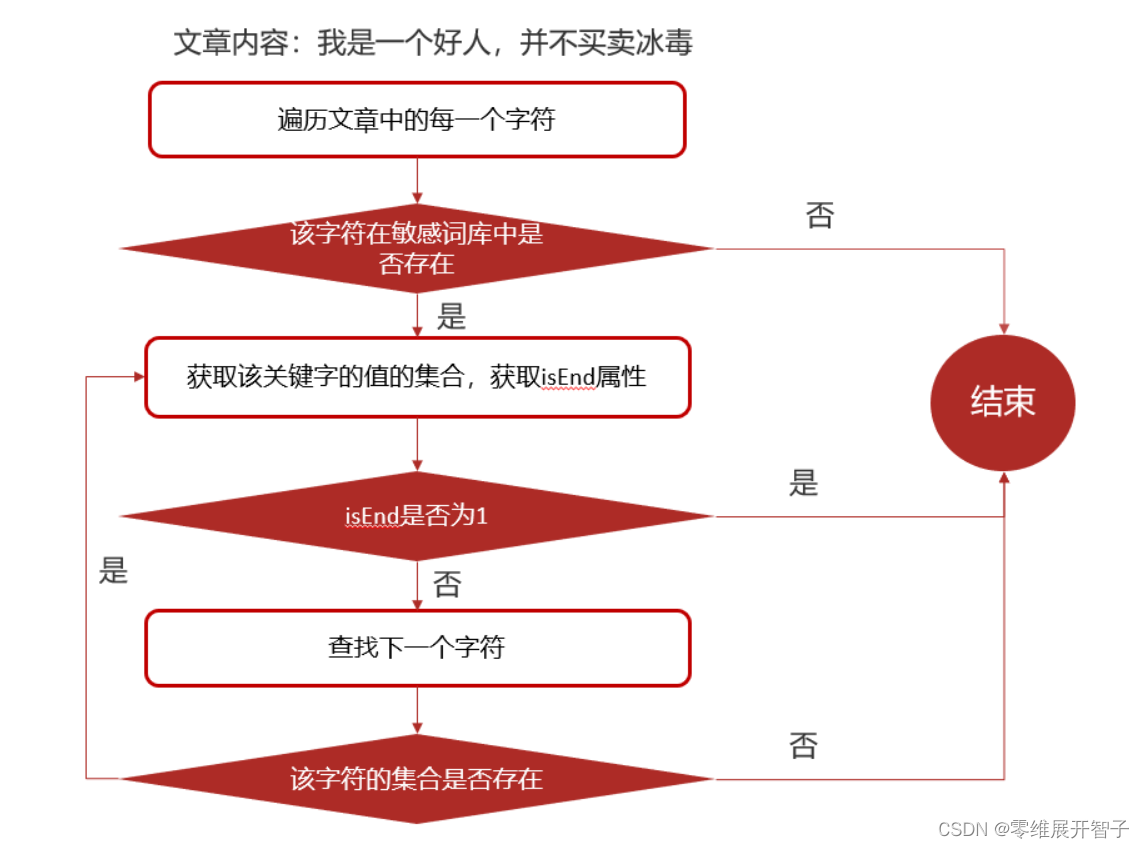
init函数有什么用?init函数是什么?
go.mod文件是什么?有什么作用?
python的模块与包
python中包的分类
1、内置模块:不需要安装,直接使用
2、三方模块:需要安装,再使用
3、自定义模块
python中自定义模块的简述
导入模块的两种方式:绝对导入、相对导入
python自定义文件实验文件包:
main.py文件(__init__.py文件、绝对导入、相对导入的实现)
GO语言问题:
1、在 Go 语言中,有以下基本数据类型:
2、GO语言中指针的作用?
3、:= 和 = 的区别是什么? :=只能使用在哪里?
4、go语言文件操作,可以使用哪些包?
5、go语言函数参数传递方式,支持默认参数传递吗?
go中的容量测试:
参考文档:go slice 扩容实现 Go 语言切片是如何扩容的?
测试代码:
运行结果:
go 模块与包复习(Init函数 - go mod)
init函数初始化文件,当导入包时,会自动执行init函数
init函数是可以重复声明的
init函数有什么用?init函数是什么?
init函数是一个用于做初始化的函数,当导入包的时候,会自动执行init函数,当运行主文件的时候,该文件的init函数会在main函数前自动执行
文件中函数的运行顺序 --》 const --》var --> init --> main
go mod init <包名> --》生成go.mod文件
go mod tidy --》自动整理依赖关系 go.sum(自动下载依赖包)
go build --》可以把go包编译成一个二进制文件,而这个二进制文件可以在没有go环境的机器上去执行go.mod文件是什么?有什么作用?
go.mod 文件是 Go 语言项目中的模块管理文件,用于定义和管理项目的依赖关系。
它用于定义模块信息、管理依赖关系和版本控制
go.mod文件中包含了当前项目的模块定义信息,包括模块名称和模块的版本
go.mod文件也用于管理项目的依赖关系。
go.mod文件支持多版本的模块依赖。
go.mod文件还可以用于自动生成和维护项目的版本号。
python的模块与包
python中包的分类
1、内置模块:不需要安装,直接使用
import os
import math
import sys
import requests2、三方模块:需要安装,再使用
# pip install <模块名> (也可以使用pip3下载)
# >pip install Flask
# 慢,timeout => 配置国内源
# pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple #配置国内源3、自定义模块
python中自定义模块的简述
模块 => python文件
包 => 目录
初始化 __init__.py => 初始化文件,当导入包的时候会自动执行
python包中的文件是独立的,(与go区分)
注意:当模块被导入的时候,模块中的代码都会被执行一次,建议每次导入模块的时候就导入模块的某个函数即可,否则很容易出现错误
导入模块的两种方式:绝对导入、相对导入
绝对导入:要内存中查找(内建) -> sys.path目录下查找目录 --》路径不理想,我们就需要添加路径: sys.path.append("路径")
相对导入:自己多层目录级别 top-level =>当前执行的主文件所在的目录
=> top-level的子孙目录才能使用相对导入
# 当前执行的文件所在的目录,被称为top-level
# top-level是不能直接被导入的
python自定义文件实验文件包:
链接:https://pan.baidu.com/s/12jZiYPEmHDpWOQMlGTGEUQ?pwd=zouh
提取码:zouh
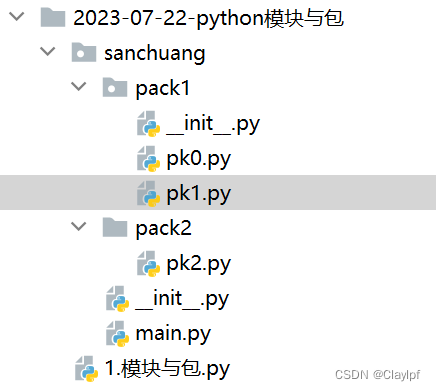
main.py文件(__init__.py文件、绝对导入、相对导入的实现)
"""
@author: wy
@file: main.py.py
@time: 2023/7/22 10:37
"""
import sys
# python模块查找路径
print(sys.path)
# 在pycharm中如果目录下有__init__.py文件,那么它就会识别成一个包,
# 会自动加到sys.path目录
# 绝对路径导入 => 内建模块 -> sys.path路径去查找
# 可以导入到包/模块/函数(变量)
# 被导入的代码都会执行一遍
import pack1
from pack1 import pk0
from pack1.pk0 import student
# student()
from pack1 import pk1
pk1.student()
from pack2 import pk2
# 相对导入
# . => 当前路径
# .. => 上级路径
# from . import pack1 #出现下面的错误
# ImportError: attempted relative import with no known parent package
# 出现错误的原因是这个. 代表的是sanchaung这个包,而sanchuang则代表的是top-level
# 当前执行的文件所在的目录,被称为top-level
# top-level是不能直接被导入的
# . => sanchuang => top-level
# top-level下面的子包才可以使用相对导入(top-level本身这一层不可以)
# 比如说我们可以在pack1包下的pk1.py文件内使用相对导入,也就是使用top-levelpack1包内的pk1.py 和 pk0.py
pk1.py 文件
# 相对导入
# . => sanchuang/pack1
# .pk0 => sanchuang/pack1/pk0
from .pk0 import test
# 如果我们在pack1包的目录下上运行pk1.py 会出现错误:ImportError: attempted relative import with no known parent package
# 因此我们不能直接在pk1上直接运行程序,因为如果它运行了,就代表他现在是top-level, 而top-level不能在本层包中使用相对导入的,必须要在子孙目录才能使用相对导入
# top-level => pack1
# . => pack1
# 因此不能再pk1上直接运行相对导入,而需要父文件调用pk1才能运行pk1.py内的程序
# .. => sanchuang => top-level
# from ..pack2 import pk2
def student():
print("this is pack1.pk0.student")
print(test())
=======================
pk0.py 文件
A = 100
sc_num = 50
print("this is pack1.pk0 file")
def student():
print("this is pack1.pk0.student")
def test():
print("this is pack1.pk0.test")pack2包中的pk2.py
def download_pic():
print("this is pack2.pk2.download_pic")
print(__name__)
print(__file__)
# 直接运行当前文件
# 当文件被直接运行的时候 => __name__ => __main__
# 当文件被其他文件导入的时候 => __name__ => 包名.文件名
if __name__ == "__main__": #目的就是当该文件被直接运行的时候,会运行下面的语句,因为__name__ == "__main__"
# 当该文件作为模块导入的时候,不希望调用语句被执行的!!
# 我们通过使用__name__ 可以使自己运行该文件的时候能运行download_pic()语句,
# 但是当pk2被调用的时候,download_pic()不会被执行
download_pic()GO语言问题:
1、在 Go 语言中,有以下基本数据类型:
值类型(Value Types):(存放的是数据)
bool:布尔类型,表示真或假。int、int8、int16、int32、int64:整数类型,分别表示不同位数的有符号整数。uint、uint8、uint16、uint32、uint64:整数类型,分别表示不同位数的无符号整数。float32、float64:浮点数类型,分别表示单精度和双精度浮点数。complex64、complex128:复数类型,分别表示具有 64 位实部和虚部、128 位实部和虚部的复数。string:字符串类型,表示文本字符串值。byte:别名类型,表示uint8。rune:别名类型,表示int32,用于表示 Unicode 码点。uintptr:整数类型,用于存储指针地址。引用类型(Reference Types):(引用的是对象的地址)
slice:切片类型,用于动态数组的管理。map:映射类型,用于存储键值对的集合。chan:通道类型,用于协程之间的通信。func:函数类型,表示函数的类型。interface:接口类型,用于定义一组方法的集合。
2、GO语言中指针的作用?
Go 语言中,指针(pointer)是一种特殊的数据类型,用于存储变量的内存地址。指针可以让我们直接访问和修改变量所在内存地址上的数据,而不是通过值拷贝。
函数可以利用指针来传递数据,实现在函数修改数据的同时影响原数据的效果
指针的作用如下:
- 传递引用:通过将指针作为参数传递给函数,可以在函数内部修改指针指向的变量的值。这样可以避免对大型数据结构进行复制,提高了性能。
- 动态分配内存:使用指针可以在程序运行时动态地分配内存,创建灵活的数据结构,如链表、树等。
- 与底层系统交互:指针常用于与 C 语言库进行交互,通过指针可以直接访问底层数据结构。
- 避免副本:有些情况下,将变量传递给函数会生成该变量的副本,占用额外的内存和时间。使用指针可以避免这种情况,节省资源。
在 Go 中,使用 & 运算符可以获取一个变量的地址,使用 * 运算符可以获取指针指向的值,也可以修改指针指向的值。
下面是一个简单的示例代码,展示了指针的使用:
func main() {
x := 10
fmt.Println("x =", x) // 输出:x = 10
p := &x
fmt.Println("p =", p) // 输出:p = 内存地址
*p = 20
fmt.Println("x =", x) // 输出:x = 20
}在这个示例中,&x 获取了变量 x 的地址,并将其赋值给指针变量 p。然后,通过 *p 可以修改指针 p 指向的变量的值。
要小心在使用指针时避免出现空指针(nil pointer)错误,确保在使用指针之前进行有效的初始化。
3、:= 和 = 的区别是什么? :=只能使用在哪里?
:=赋值操作符:
:=是用于声明和初始化变量的简写方式。它会根据右侧表达式的类型自动推断出变量的类型,并将变量的作用域限定在当前代码块内。:=只能用于函数内部,用于声明和初始化局部变量,不能用于全局变量的声明。
=赋值操作符:
=是普通的赋值操作符,用于给已经声明的变量赋新的值或修改变量的值。=可以在任何地方使用,不仅限于函数内部,包括全局变量的赋值和变量的重新赋值。
下面是使用 := 和 = 的示例代码:
func main() {
x := 10 // 使用 := 声明并初始化局部变量 x
y := 20 // 使用 := 声明并初始化局部变量 y
fmt.Println(x, y) // 输出:10 20
x = 30 // 使用 = 给变量 x 赋新值
fmt.Println(x) // 输出:30
z := "hello" // 使用 := 声明并初始化局部变量 z
fmt.Println(z) // 输出:hello
z = "world" // 使用 = 给变量 z 赋新值
fmt.Println(z) // 输出:world
}需要注意的是,:= 只能用于声明新的变量,如果想要对已经存在的变量赋值,则必须使用 =。
4、go语言文件操作,可以使用哪些包?
在 Go 语言中,可以使用以下几个包进行文件操作:
os包:提供了与操作系统交互的函数和类型,用于创建、打开、读取、写入和关闭文件等基本的文件操作。常用函数有:Create、Open、Read、Write、Close等。
io包:提供了基本的 I/O 操作,包括读取和写入数据到文件。常用函数有:Copy、CopyN、ReadAll、WriteFile等。
ioutil包:提供了一些方便的 I/O 函数,用于简化文件操作。常用函数有:ReadFile、WriteFile、ReadDir、TempFile等。
filepath包:提供了对文件路径的各种操作,比如获取文件扩展名、获取文件名、判断路径是否为绝对路径等。常用函数有:Base、Ext、Join、Abs等。
go语言怎么处理异常,有异常类型吗?如何自定义异常呢?
go语言错误处理通常是通过返回值的方式,把处理权交给用户
Go 语言中没有像其他语言一样的异常类型,而是使用了内置的 error 接口类型作为错误的表示。标准库包中的很多函数都会返回一个 error 类型的值,用于指示函数是否执行成功。
通常情况下,一个函数在执行过程中如果发生了错误,会将错误信息封装在一个 error 类型的值中返回。调用该函数的代码负责根据返回的错误值进行判断和处理。
package main
import (
"fmt"
"os"
)
func main() {
file, err := os.Open("test.txt")
if err != nil {
fmt.Println("打开文件出错:", err)
return
}
defer file.Close()
// 使用 file 进行文件操作
// ...
}在上面的代码中,我们打开了一个名为 test.txt 的文件,如果打开过程中发生错误,就会返回一个非空的 error 值。通过判断 err 是否为 nil 来确定函数是否执行成功,如果不为 nil,则表示发生了错误,可以通过 err.Error() 方法获取详细的错误信息。
除了使用标准库提供的错误类型,你也可以自定义错误类型。只需定义一个实现了 error 接口的结构体即可,该结构体需要实现 Error() string 方法来返回错误信息。
Panic 错误 --》 defer+recover
--》defer --》延迟执行 --》通常出现在可能出现错误的位置的前面
--》recover --》 获取并处理panic信息,其实就相当于python中的except一样
以下是一个自定义错误类型的示例代码:
package main
import (
"errors"
"fmt"
)
type MyError struct {
ErrMsg string
}
func (e *MyError) Error() string {
return e.ErrMsg
}
func main() {
err := &MyError{ErrMsg: "自定义错误"}
fmt.Println(err.Error())
}在上面的代码中,我们定义了一个名为 MyError 的结构体,并实现了 Error() 方法。然后,创建一个 MyError 类型的实例并打印出错误信息。
通过自定义错误类型,可以给错误信息添加更多的上下文和可读性。
5、go语言函数参数传递方式,支持默认参数传递吗?
在 Go 语言中,函数参数的传递方式是值传递(pass by value)。这意味着函数调用时,实参的值会被复制到形参中,函数内对形参的修改不会影响到实参。
默认参数传递是指在函数定义时为参数提供默认值,在函数调用时可以省略该参数。然而,Go 语言并不支持原生的默认参数传递的语法,但可以通过函数重载和可变参数来模拟实现一种类似的行为。
以下是一个使用函数重载和可变参数模拟默认参数传递的示例代码:
package main
import "fmt"
func PrintNameWithAge(name string, age ...int) {
if len(age) > 0 {
fmt.Printf("Name: %s, Age: %d\n", name, age[0])
} else {
fmt.Printf("Name: %s\n", name)
}
}
func main() {
// 调用函数时只传递 name 参数
PrintNameWithAge("Alice")
// 调用函数时传递 name 和 age 参数
PrintNameWithAge("Bob", 25)
}在上面的代码中,PrintNameWithAge 函数定义了一个名为 name 的必需参数和一个名为 age 的可变参数。如果调用函数时只传递了 name 参数,则 age 参数被省略,默认为零值。如果同时传递了 name 和 age 参数,则按照传入的值进行输出。
在 main 函数中,我们分别调用了 PrintNameWithAge 函数,一次只传递了 name 参数,一次同时传递了 name 和 age 参数。结果会根据参数的情况进行输出。
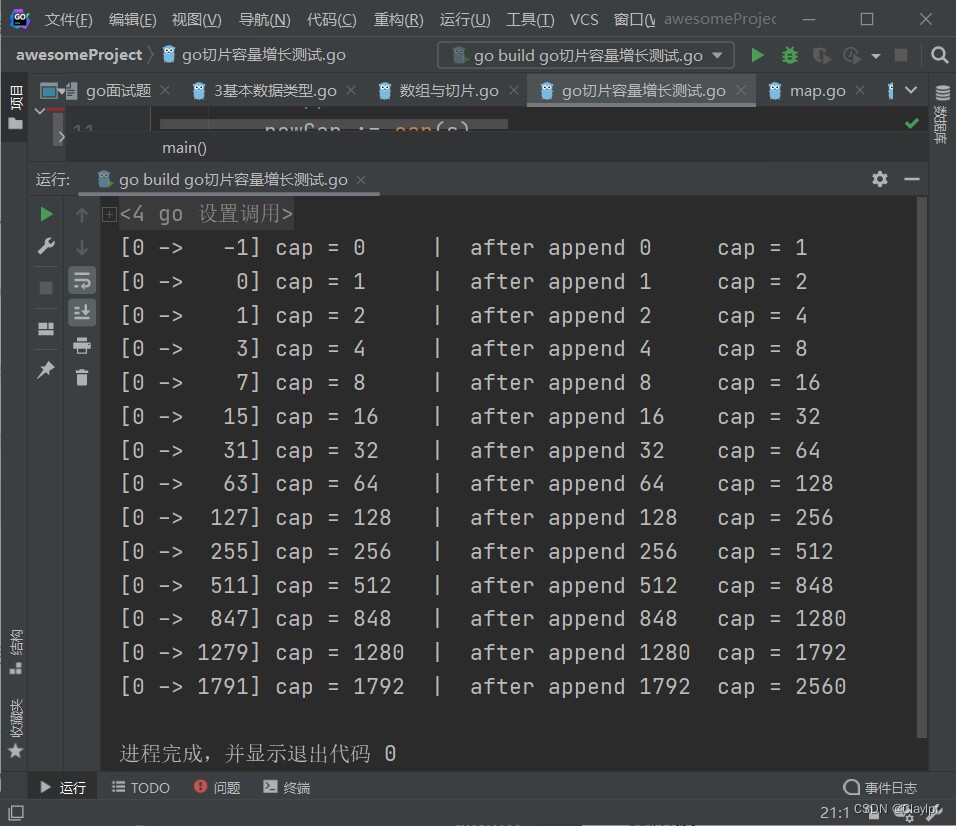
go中的容量测试:

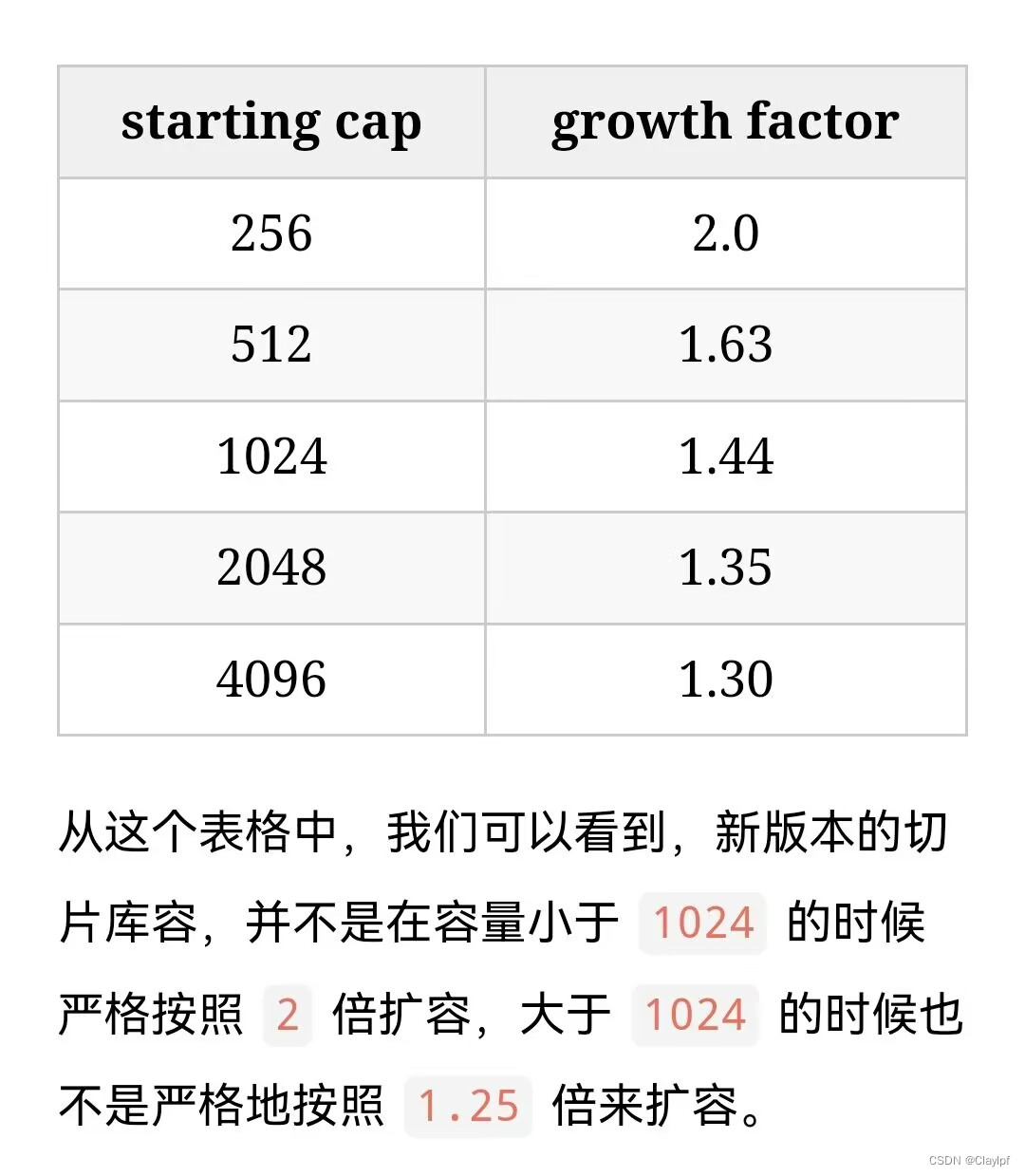
参考文档:go slice 扩容实现 Go 语言切片是如何扩容的?
测试代码:
package main
import "fmt"
func main() {
// 定义了一个切片,长度为0
s := make([]int, 0)
// 底层数组长度
oldCap := cap(s)
for i := 0; i < 2048; i++ {
s = append(s, i)
// append之后底层数组长度
newCap := cap(s)
// 条件成立表示数组增长了
if newCap != oldCap {
fmt.Printf("[%d -> %4d] cap = %-4d | after append %-4d cap = %-4d\n", 0, i-1, oldCap, i, newCap)
oldCap = newCap
}
}
}
// 源代码 :src/runtime/slice.go
// 1. 计算newCap
// a.如果期望的容器大于当前cap的2倍,newcap = 期望容器值
// b.
// c.
// 2. 内存优化运行结果: