可优化语句执行
- 概述
- 物理代数与处理模型
- 物理操作符的数据结构
- 执行器的运行
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了《PostgresSQL数据库内核分析》一书
概述
可优化语句的共同特点是它们被查询编译器处理后都会生成查询计划树,这一类语句由执行器(Executor)处理。该模块对外提供了三个接口:ExecutorStart、ExecutorRun和ExecutorEnd,其输入是包含查询计划树的数据结构QueryDesc,输出则是相关执行信息或结果数据。如果希望执行某个计划树,仅需构造包含此计划树的QueryDesc,并依次调用ExecutorStart、ExecutorRun、ExecutorEnd三个过程即能完成相应的处理过程。从图6-6可以看到,执行器的三个接口函数都是在Portal的相关函数中调用的,分别负责执行器的初始化、执行和清理工作,Portal在处理时也使用了同样的方式,这样可以把资源分配回收工作与执行过程独立开,能够简化执行过程,更是一种很好的资源管理方式。
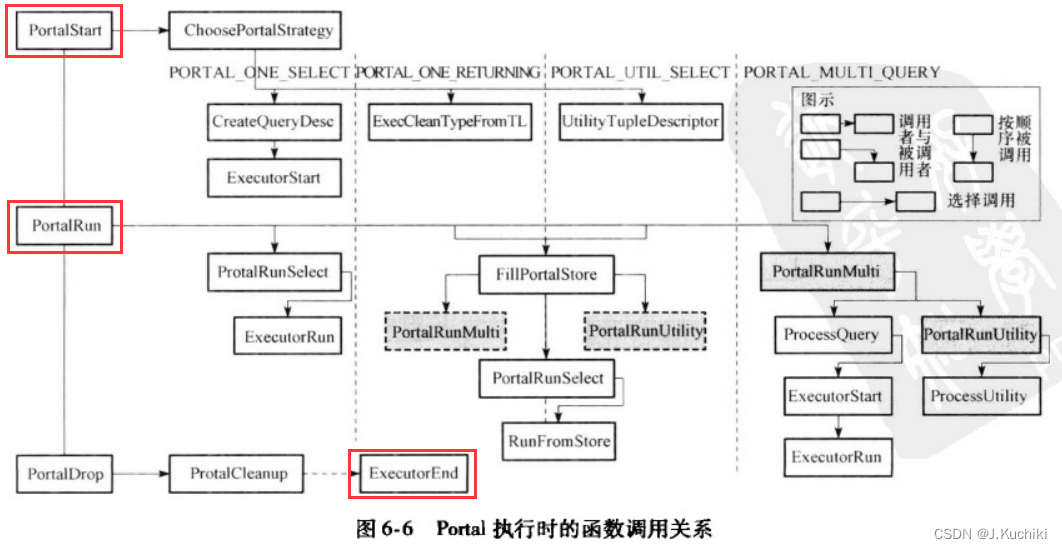
执行器对于查询计划树的处理,最终被转换为针对计划树上每一个节点的处理。每种节点表示一种物理代数(Physical Algebra)操作,PostgreSQL对其进行初始化、处理、清理的过程。节点的处理被设计为需求驱动模式,父节点使用孩于节点提供的数据作为输入,并向其上层节点返回处理结果。实际执行时,从根节点开始处理,每个节点的执行过程会根据需求自动调节用孩子节点的执行过程来获取输入数据(一般为元组),从而层层递归执行,实现整个计划树的遍历执行过程。初始化和清理也采用相同的设计模式,这种设计模式使得节点处理的代码结构简洁统一、语义明确,且实现方式简单有效。
物理代数与处理模型
数据库的查询逻辑使用逻辑代数(例如:关系代数)来表示。例如,PostgreSQL中使用SQL语句,然而执行时需要使用物理代数( Physical Algebra),例如,PostgreSQL 中的查询计划。对于一个可优化语句,PostgreSQL 在执行前会给出与之等价的用物理代数表示的查询计划,然后按照查询计划进行执行。
下面来稍微解释一下什么是逻辑代数和物理代数:
物理代数和逻辑代数是数据库领域中两种不同的查询优化技术,它们用于优化和执行数据库查询的过程。它们之间的区别如下:
- 定义层次:
- 逻辑代数:逻辑代数是对数据进行抽象和描述的一种数学表达方式,用于描述查询的逻辑结构和操作。它关注查询的逻辑关系而不关心具体的物理实现。
- 物理代数:物理代数是对数据进行具体实现和执行的一种表达方式,用于描述查询的具体执行计划和物理操作。它关注查询的具体执行过程和物理存储结构。
- 抽象级别:
- 逻辑代数:逻辑代数是高层次的抽象,用于描述查询的逻辑操作,例如选择、投影、连接等。
- 物理代数:物理代数是低层次的抽象,用于描述查询的物理操作,例如索引扫描、排序、哈希等。
- 应用领域:
- 逻辑代数:逻辑代数主要应用于查询优化阶段,通过对查询的逻辑结构进行优化,生成更高效的执行计划。
- 物理代数:物理代数主要应用于查询执行阶段,通过对查询的物理操作进行优化,实际执行查询并返回结果。
- 关注点:
- 逻辑代数:逻辑代数关注于查询的结果集、逻辑关系和数据的组合操作,是查询的逻辑规划。
- 物理代数:物理代数关注于查询的执行计划、物理操作和访问路径,是查询的具体实现。
《数据库系统实现》一书中提到:“物理查询计划由操作符构造,每一个操作符实现计划中的一步。物理操作符常常是一个关系代数操作符的特定实现。但是,我们也需要用物理操作符来完成另一些与关系代数操作符无关的任务。”
- 逻辑操作符:选择(Selection)、投影(Projection)、连接(Join)、并集(Union)、交集(Intersection)。
- 物理操作符:索引扫描(Index Scan)、散列连接(Hash Join)、排序(Sort)、聚合(Aggregation)、哈希(Hash)。
在PostgreSQL中“逻辑操作符与物理操作符并不是简单的一一对应关系”,它们之间的转换过程实际就是查询编译器所做的工作,本章主要介绍各种物理操作符的实现和执行。
PostgreSQL 中的物理操作符被定义为有 0 ~ 2 个输入和一个输出,这是为了在实现中能够对应二叉树结构:所有的物理操作符被组织为一个二叉树,每一个物理操作符对应于树中的一个节点,下层节点的输出作为上层节点输入。数据(元组)从底层节点向上层节点流动,直至根节点,而根节点的输出即为整个查询的结果。如图6-11所示,Join类型操作符有两个输入,Sort 操作符仅有一个输入,Scan操作符则没有输入。元组被Scan操作符取出后经过连接操作,然后排序后获得结果。
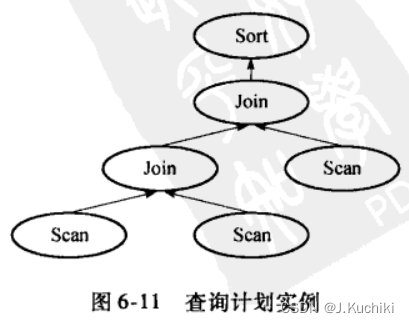
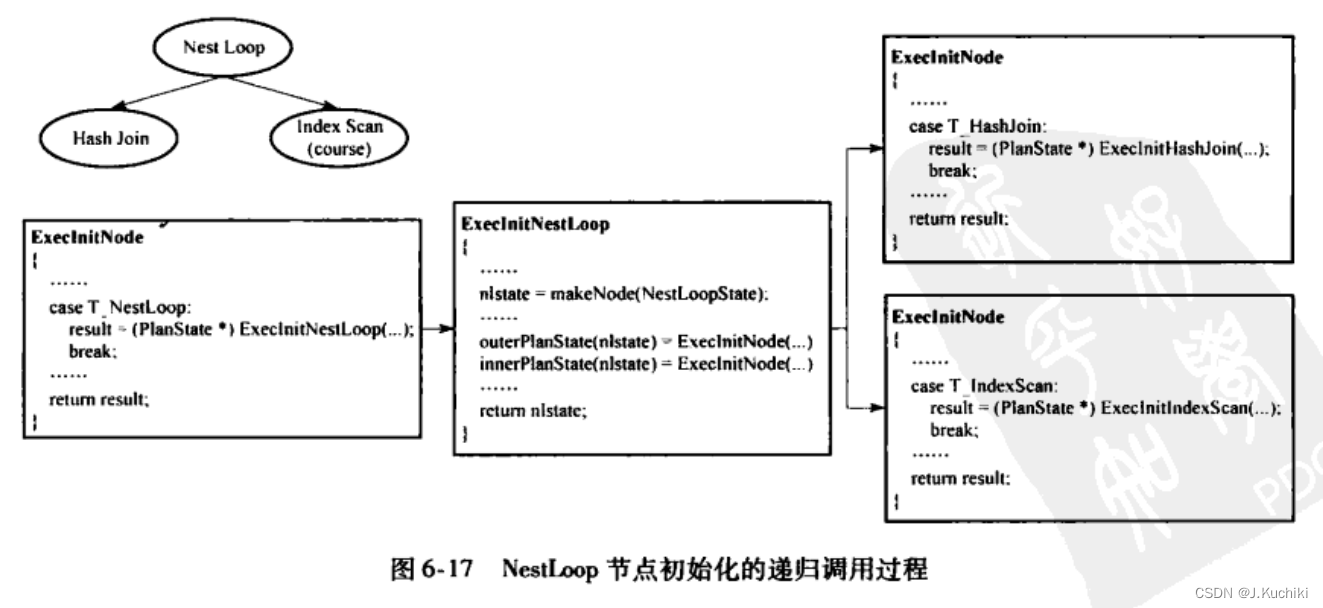
在PostgreSQL的实现中,上层函数通过ExecInitNode 、ExecProcNode、ExecEndNode三个接口函数来统一对节点进行初始化、执行和清理,这三个函数会根据==所处理节点的实际类型==调用相应的初始化、执行、清理函数,例如,若ExecInitNode处理的是SeqScan节点,则调用SeqScan节点的初始化函数ExecInitSe-qScan 来实际完成该节点的初始化工作。这三个函数也是递归执行的:对根节点的初始化会递归地对下层的节点进行初始化;在根节点调用ExecProcNode获取结果时,也会递归地对下层节点进行执行以获取上层节点所需的输人数据;执行完成后只需对根节点进行清理,下层节点也会被递归地清理。
ExecInitNode函数源码如下:(路径:src/backend/executor/execProcnode.c)
/* ------------------------------------------------------------------------
* ExecInitNode
*
* Recursively initializes all the nodes in the plan tree rooted
* at 'node'.
*
* Inputs:
* 'node' is the current node of the plan produced by the query planner
* 'estate' is the shared execution state for the plan tree
* 'eflags' is a bitwise OR of flag bits described in executor.h
*
* Returns a PlanState node corresponding to the given Plan node.
* ------------------------------------------------------------------------
*/
PlanState *
ExecInitNode(Plan *node, EState *estate, int eflags)
{
PlanState *result;
List *subps;
ListCell *l;
/*
* do nothing when we get to the end of a leaf on tree.
*/
if (node == NULL)
return NULL;
/*
* Make sure there's enough stack available. Need to check here, in
* addition to ExecProcNode() (via ExecProcNodeFirst()), to ensure the
* stack isn't overrun while initializing the node tree.
*/
check_stack_depth();
switch (nodeTag(node))
{
/*
* control nodes
*/
case T_Result:
result = (PlanState *) ExecInitResult((Result *) node,
estate, eflags);
break;
case T_ProjectSet:
result = (PlanState *) ExecInitProjectSet((ProjectSet *) node,
estate, eflags);
break;
case T_ModifyTable:
result = (PlanState *) ExecInitModifyTable((ModifyTable *) node,
estate, eflags);
break;
case T_Append:
result = (PlanState *) ExecInitAppend((Append *) node,
estate, eflags);
break;
case T_MergeAppend:
result = (PlanState *) ExecInitMergeAppend((MergeAppend *) node,
estate, eflags);
break;
case T_RecursiveUnion:
result = (PlanState *) ExecInitRecursiveUnion((RecursiveUnion *) node,
estate, eflags);
break;
case T_BitmapAnd:
result = (PlanState *) ExecInitBitmapAnd((BitmapAnd *) node,
estate, eflags);
break;
case T_BitmapOr:
result = (PlanState *) ExecInitBitmapOr((BitmapOr *) node,
estate, eflags);
break;
/*
* scan nodes
*/
case T_SeqScan:
result = (PlanState *) ExecInitSeqScan((SeqScan *) node,
estate, eflags);
break;
case T_SampleScan:
result = (PlanState *) ExecInitSampleScan((SampleScan *) node,
estate, eflags);
break;
case T_IndexScan:
result = (PlanState *) ExecInitIndexScan((IndexScan *) node,
estate, eflags);
break;
case T_IndexOnlyScan:
result = (PlanState *) ExecInitIndexOnlyScan((IndexOnlyScan *) node,
estate, eflags);
break;
case T_BitmapIndexScan:
result = (PlanState *) ExecInitBitmapIndexScan((BitmapIndexScan *) node,
estate, eflags);
break;
case T_BitmapHeapScan:
result = (PlanState *) ExecInitBitmapHeapScan((BitmapHeapScan *) node,
estate, eflags);
break;
case T_TidScan:
result = (PlanState *) ExecInitTidScan((TidScan *) node,
estate, eflags);
break;
case T_SubqueryScan:
result = (PlanState *) ExecInitSubqueryScan((SubqueryScan *) node,
estate, eflags);
break;
case T_FunctionScan:
result = (PlanState *) ExecInitFunctionScan((FunctionScan *) node,
estate, eflags);
break;
case T_TableFuncScan:
result = (PlanState *) ExecInitTableFuncScan((TableFuncScan *) node,
estate, eflags);
break;
case T_ValuesScan:
result = (PlanState *) ExecInitValuesScan((ValuesScan *) node,
estate, eflags);
break;
case T_CteScan:
result = (PlanState *) ExecInitCteScan((CteScan *) node,
estate, eflags);
break;
case T_NamedTuplestoreScan:
result = (PlanState *) ExecInitNamedTuplestoreScan((NamedTuplestoreScan *) node,
estate, eflags);
break;
case T_WorkTableScan:
result = (PlanState *) ExecInitWorkTableScan((WorkTableScan *) node,
estate, eflags);
break;
case T_ForeignScan:
result = (PlanState *) ExecInitForeignScan((ForeignScan *) node,
estate, eflags);
break;
case T_CustomScan:
result = (PlanState *) ExecInitCustomScan((CustomScan *) node,
estate, eflags);
break;
/*
* join nodes
*/
case T_NestLoop:
result = (PlanState *) ExecInitNestLoop((NestLoop *) node,
estate, eflags);
break;
case T_MergeJoin:
result = (PlanState *) ExecInitMergeJoin((MergeJoin *) node,
estate, eflags);
break;
case T_HashJoin:
result = (PlanState *) ExecInitHashJoin((HashJoin *) node,
estate, eflags);
break;
/*
* materialization nodes
*/
case T_Material:
result = (PlanState *) ExecInitMaterial((Material *) node,
estate, eflags);
break;
case T_Sort:
result = (PlanState *) ExecInitSort((Sort *) node,
estate, eflags);
break;
case T_Group:
result = (PlanState *) ExecInitGroup((Group *) node,
estate, eflags);
break;
case T_Agg:
result = (PlanState *) ExecInitAgg((Agg *) node,
estate, eflags);
break;
case T_WindowAgg:
result = (PlanState *) ExecInitWindowAgg((WindowAgg *) node,
estate, eflags);
break;
case T_Unique:
result = (PlanState *) ExecInitUnique((Unique *) node,
estate, eflags);
break;
case T_Gather:
result = (PlanState *) ExecInitGather((Gather *) node,
estate, eflags);
break;
case T_GatherMerge:
result = (PlanState *) ExecInitGatherMerge((GatherMerge *) node,
estate, eflags);
break;
case T_Hash:
result = (PlanState *) ExecInitHash((Hash *) node,
estate, eflags);
break;
case T_SetOp:
result = (PlanState *) ExecInitSetOp((SetOp *) node,
estate, eflags);
break;
case T_LockRows:
result = (PlanState *) ExecInitLockRows((LockRows *) node,
estate, eflags);
break;
case T_Limit:
result = (PlanState *) ExecInitLimit((Limit *) node,
estate, eflags);
break;
default:
elog(ERROR, "unrecognized node type: %d", (int) nodeTag(node));
result = NULL; /* keep compiler quiet */
break;
}
/*
* Add a wrapper around the ExecProcNode callback that checks stack depth
* during the first execution.
*/
result->ExecProcNodeReal = result->ExecProcNode;
result->ExecProcNode = ExecProcNodeFirst;
/*
* Initialize any initPlans present in this node. The planner put them in
* a separate list for us.
*/
subps = NIL;
foreach(l, node->initPlan)
{
SubPlan *subplan = (SubPlan *) lfirst(l);
SubPlanState *sstate;
Assert(IsA(subplan, SubPlan));
sstate = ExecInitSubPlan(subplan, result);
subps = lappend(subps, sstate);
}
result->initPlan = subps;
/* Set up instrumentation for this node if requested */
if (estate->es_instrument)
result->instrument = InstrAlloc(1, estate->es_instrument);
return result;
}
ExecProcNode函数源码如下:(路径:src/include/executor/executor.h)
/* ----------------------------------------------------------------
* ExecProcNode
*
* Execute the given node to return a(nother) tuple.
* ----------------------------------------------------------------
*/
#ifndef FRONTEND
static inline TupleTableSlot *
ExecProcNode(PlanState *node)
{
if (node->chgParam != NULL) /* something changed? */
ExecReScan(node); /* let ReScan handle this */
return node->ExecProcNode(node);
}
#endif
ExecEndNode函数源码如下:(路径:src/backend/executor/execProcnode.c)
/* ----------------------------------------------------------------
* ExecEndNode
*
* Recursively cleans up all the nodes in the plan rooted
* at 'node'.
*
* After this operation, the query plan will not be able to be
* processed any further. This should be called only after
* the query plan has been fully executed.
* ----------------------------------------------------------------
*/
void
ExecEndNode(PlanState *node)
{
/*
* do nothing when we get to the end of a leaf on tree.
*/
if (node == NULL)
return;
/*
* Make sure there's enough stack available. Need to check here, in
* addition to ExecProcNode() (via ExecProcNodeFirst()), because it's not
* guaranteed that ExecProcNode() is reached for all nodes.
*/
check_stack_depth();
if (node->chgParam != NULL)
{
bms_free(node->chgParam);
node->chgParam = NULL;
}
switch (nodeTag(node))
{
/*
* control nodes
*/
case T_ResultState:
ExecEndResult((ResultState *) node);
break;
case T_ProjectSetState:
ExecEndProjectSet((ProjectSetState *) node);
break;
case T_ModifyTableState:
ExecEndModifyTable((ModifyTableState *) node);
break;
case T_AppendState:
ExecEndAppend((AppendState *) node);
break;
case T_MergeAppendState:
ExecEndMergeAppend((MergeAppendState *) node);
break;
case T_RecursiveUnionState:
ExecEndRecursiveUnion((RecursiveUnionState *) node);
break;
case T_BitmapAndState:
ExecEndBitmapAnd((BitmapAndState *) node);
break;
case T_BitmapOrState:
ExecEndBitmapOr((BitmapOrState *) node);
break;
/*
* scan nodes
*/
case T_SeqScanState:
ExecEndSeqScan((SeqScanState *) node);
break;
case T_SampleScanState:
ExecEndSampleScan((SampleScanState *) node);
break;
case T_GatherState:
ExecEndGather((GatherState *) node);
break;
case T_GatherMergeState:
ExecEndGatherMerge((GatherMergeState *) node);
break;
case T_IndexScanState:
ExecEndIndexScan((IndexScanState *) node);
break;
case T_IndexOnlyScanState:
ExecEndIndexOnlyScan((IndexOnlyScanState *) node);
break;
case T_BitmapIndexScanState:
ExecEndBitmapIndexScan((BitmapIndexScanState *) node);
break;
case T_BitmapHeapScanState:
ExecEndBitmapHeapScan((BitmapHeapScanState *) node);
break;
case T_TidScanState:
ExecEndTidScan((TidScanState *) node);
break;
case T_SubqueryScanState:
ExecEndSubqueryScan((SubqueryScanState *) node);
break;
case T_FunctionScanState:
ExecEndFunctionScan((FunctionScanState *) node);
break;
case T_TableFuncScanState:
ExecEndTableFuncScan((TableFuncScanState *) node);
break;
case T_ValuesScanState:
ExecEndValuesScan((ValuesScanState *) node);
break;
case T_CteScanState:
ExecEndCteScan((CteScanState *) node);
break;
case T_NamedTuplestoreScanState:
ExecEndNamedTuplestoreScan((NamedTuplestoreScanState *) node);
break;
case T_WorkTableScanState:
ExecEndWorkTableScan((WorkTableScanState *) node);
break;
case T_ForeignScanState:
ExecEndForeignScan((ForeignScanState *) node);
break;
case T_CustomScanState:
ExecEndCustomScan((CustomScanState *) node);
break;
/*
* join nodes
*/
case T_NestLoopState:
ExecEndNestLoop((NestLoopState *) node);
break;
case T_MergeJoinState:
ExecEndMergeJoin((MergeJoinState *) node);
break;
case T_HashJoinState:
ExecEndHashJoin((HashJoinState *) node);
break;
/*
* materialization nodes
*/
case T_MaterialState:
ExecEndMaterial((MaterialState *) node);
break;
case T_SortState:
ExecEndSort((SortState *) node);
break;
case T_GroupState:
ExecEndGroup((GroupState *) node);
break;
case T_AggState:
ExecEndAgg((AggState *) node);
break;
case T_WindowAggState:
ExecEndWindowAgg((WindowAggState *) node);
break;
case T_UniqueState:
ExecEndUnique((UniqueState *) node);
break;
case T_HashState:
ExecEndHash((HashState *) node);
break;
case T_SetOpState:
ExecEndSetOp((SetOpState *) node);
break;
case T_LockRowsState:
ExecEndLockRows((LockRowsState *) node);
break;
case T_LimitState:
ExecEndLimit((LimitState *) node);
break;
default:
elog(ERROR, "unrecognized node type: %d", (int) nodeTag(node));
break;
}
}
由此可见,查询计划树上的节点就构成了物理元组到执行结果的管道,因此查询计划树的执行过程可以看成是拉动元组穿过管道的过程。PostgreSQL采用了一次一元组的执行模式,每个节点执行一次仅向上层节点返回一条元组。因此,对于整个查询计划树的执行也是一次一元组的模式。
这种模式有很多的优点:
- 减少了返回元组的延迟。
- 对于某些操作(例如游标、LIMIT子句等)不需要一次性获取所有的元组,节省了开销。
- 减少了实现过程中缓存结果带来的代码复杂性和执行过程中临时存储的开销。
物理操作符的数据结构
从前面的介绍我们已经看到查询计划树是由各种物理操作符(也简称为计划节点)构成,那么在 PostgreSQL中是如何存储和表示各类节点的呢?图6-12给出了Hash连接(HashJoin)点的数据结构表示。
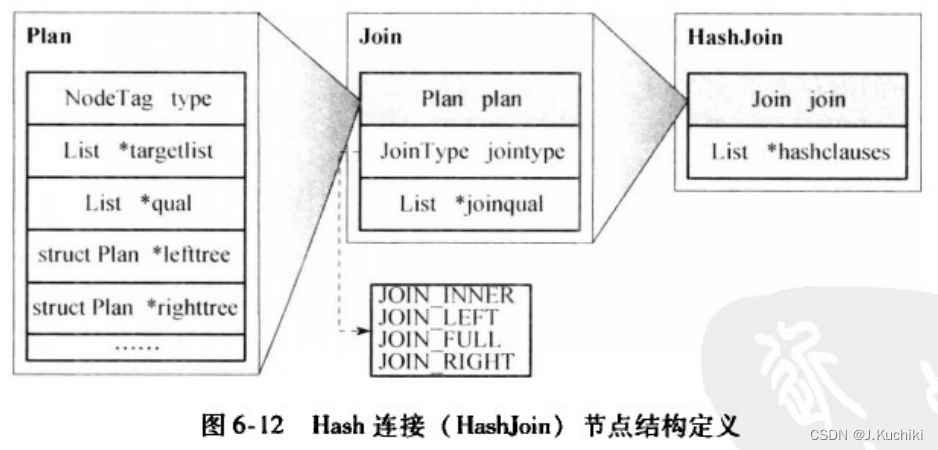
所有物理操作符节点的数据结构都以一个 Plan 类型的字段开头,这有点像类的继承:把 Plan看成一个父类,其他物理操作符节点都是它的直接或者间接子类。如图6-12所示,Join 节点是Plan的子类,从 Plan中继承了左右子树指针(leftree,righttree)、节点类型(type)、选择表达式( qual)、投影链表( targetlist)等公共字段,并有自己的扩展字段连接类型(jointype)和连接条件( joinqual);HashJoin节点则是Join节点的子类,有自己的扩展字段 hashclauses。
PostgreSQL 系统中将所有的计划节点按功能分为四类:控制节点( control node)、扫描节点(scan node)、连接节点(join node)和物化节点(materialization node),并分别为扫描、连接节点类型定义了公共父类Scan、Join。Hash连接属于连接节点,因此Hash连接继承于Join节点。连接节点类型的公共父类定义了连接的类型以及连接的条件。作为Hash 连接节点,需要使用Hash函数,所以HashJoin节点扩展定义了hashclauses字段来存储相关信息,其中包括需要做Hash的属性以及使用的Hash函数等。
看了一大堆概念,不如一个实际的案例来得直接:
案例:当执行一个复杂的 SQL 查询时,PostgreSQL 会生成一个查询计划树来决定查询的执行顺序和方式。假设有以下两个表:orders 表和 order_items 表,它们的结构如下:
- orders 表:
order_id | customer_id | order_date
---------+-------------+------------
1 | 101 | 2023-01-01
2 | 102 | 2023-01-02
- order_items 表:
item_id | order_id | product_name | quantity
--------+----------+--------------+---------
101 | 1 | Product A | 2
102 | 1 | Product B | 1
103 | 2 | Product A | 3
现在,我们执行以下 SQL 查询:
SELECT o.order_id, o.order_date, oi.product_name, oi.quantity
FROM orders o
JOIN order_items oi ON o.order_id = oi.order_id
WHERE o.customer_id = 101;
查询计划树的生成过程如下:
- 扫描节点(Scan Nodes):
- 为 orders 表创建扫描节点,用于执行表的顺序扫描。
- 为 order_items 表创建扫描节点,用于执行表的顺序扫描。
- 连接节点(Join Nodes):
- 创建连接节点,用于将 orders 表和 order_items 表连接起来。这个连接节点将扫描节点的结果按照指定的连接条件进行匹配。
- 控制节点(Control Node):
- 创建控制节点,将连接节点作为根节点,并定义查询的输出列,即 SELECT 子句中的列。
- 控制节点将连接节点的结果作为输入,并按照 SELECT 子句中指定的列进行投影,得到最终的查询结果。
整个查询计划树的结构如下:
Control Node
|
Join Node (连接 orders 和 order_items 表)
/ \
Scan Node Scan Node
(扫描 orders 表) (扫描 order_items 表)
Plan的众多子类节点通过lefttree和righttree字段构成了整个查询计划树,其根节点指针被保存在PlannedStmt类型的数据结构中,其中包含了语句的类型(commandType)、查询计划树根节点(planTree)、查询涉及的范围表(rtable)、结果关系表(result-Relation)。PlannedStmt结构则被放在QueryDesc中,QueryDesc结构的基本定义如图6-13所示。
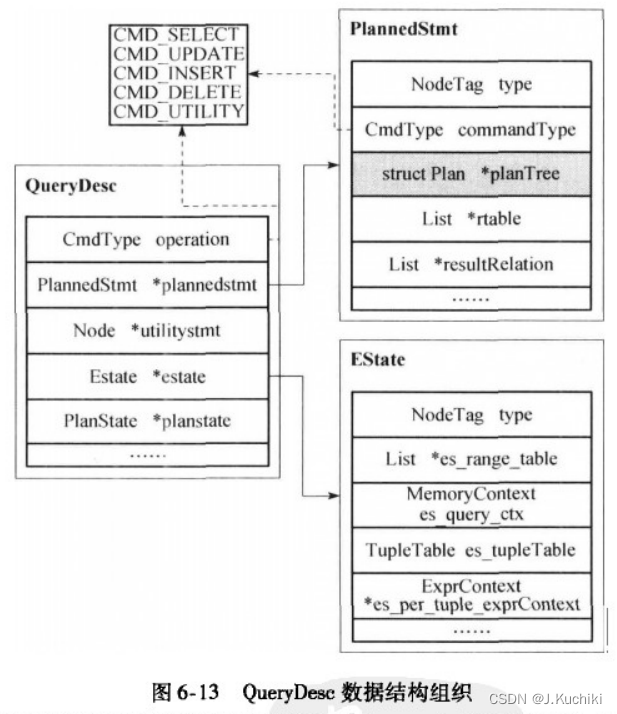
QueryDesc结构体源码如下所示:(路径:src/include/executor/execdesc.h)
typedef struct QueryDesc
{
/* These fields are provided by CreateQueryDesc */
CmdType operation; /* CMD_SELECT, CMD_UPDATE, etc. */
PlannedStmt *plannedstmt; /* planner's output (could be utility, too) */
const char *sourceText; /* source text of the query */
Snapshot snapshot; /* snapshot to use for query */
Snapshot crosscheck_snapshot; /* crosscheck for RI update/delete */
DestReceiver *dest; /* the destination for tuple output */
ParamListInfo params; /* param values being passed in */
QueryEnvironment *queryEnv; /* query environment passed in */
int instrument_options; /* OR of InstrumentOption flags */
/* These fields are set by ExecutorStart */
TupleDesc tupDesc; /* descriptor for result tuples */
EState *estate; /* executor's query-wide state */
PlanState *planstate; /* tree of per-plan-node state */
/* This field is set by ExecutorRun */
bool already_executed; /* true if previously executed */
/* This is always set NULL by the core system, but plugins can change it */
struct Instrumentation *totaltime; /* total time spent in ExecutorRun */
} QueryDesc;
作为执行器的输入,QueryDesc中包含查询计划树(plannedstmt字段)、功能语句相关执行计划(utilitystmt字段)、执行器全局状态( estate字段)以及计划节点执行状态(planstate字段)等。从图6-13可以看出,执行器全局状态estate 中保存了查询涉及的范围表( es_range_ta-ble)、Estate所在的内存上下文(es_query_ctx,也是执行过程中一直保持的内存上下文)、用于在节点间传递元组的全局元组表(es_tupleTable)和每获取一个元组就会回收的内存上下文(es_per_tuple_exprContext)。

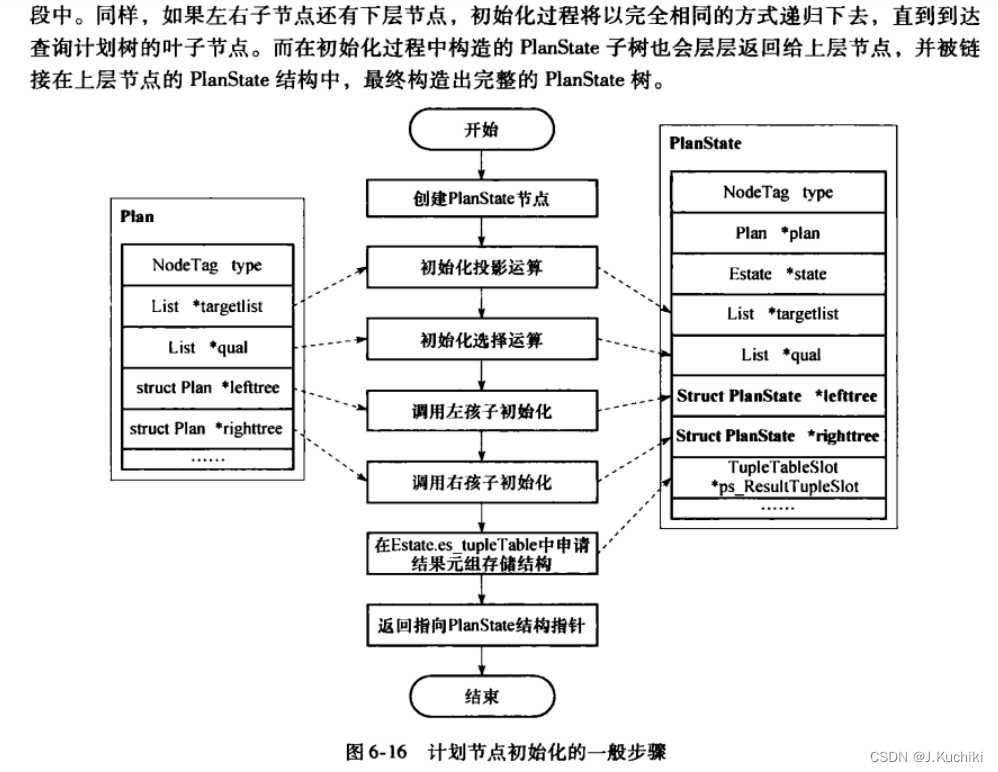
图6-14给出了PostgreSQL 中用于计划节点执行状态记录的数据结构与计划节点之间的对应关系。与图6-12类似,PostgreSQL为每种计划节点定义了–种状态节点。所有的状态节点均继承于PlanState节点,其中包含辅助计划节点指针(Plan)、执行器全局状态结构指针(state)、投影运算相关信息(targetlist)、选择运算相关条件(qual),以及左右子状态节点指针(lefttree、righttree)。
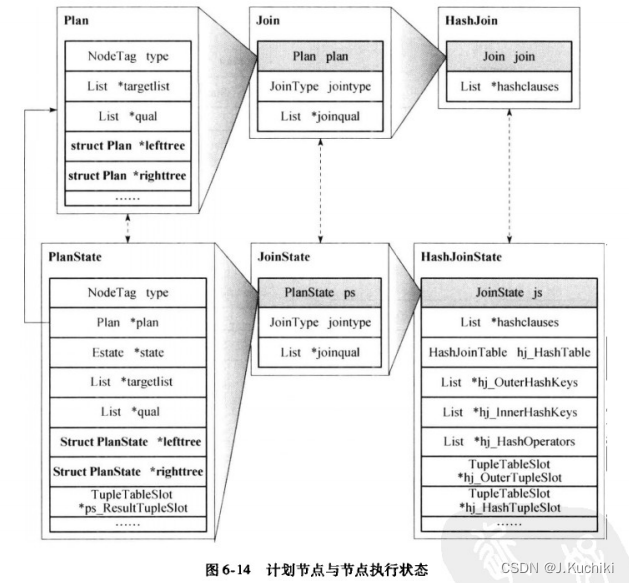
至此,执行器执行过程中涉及的主要各种数据结构已经介绍完毕。执行器的输入是QueryDesc,它包含了存储查询计划树根节点指针的PlannedStmt结构。执行器执行时,首先构造全局状态记录Estate结构,并为每个计划节点(Plan)构造对应的状态节点(PlanState),然后在执行中使用相关结构存储执行状态,执行完毕后释放相关的数据结构。
执行器的运行
在PostgreSQL 中提供了三个接口函数用于调用执行器,分别为ExecutorStart、ExecutorRun、ExecutorEnd。当需要使用执行器来处理查询计划时,仅需依次调用三个函数即可完成执行器的整个执行过程。
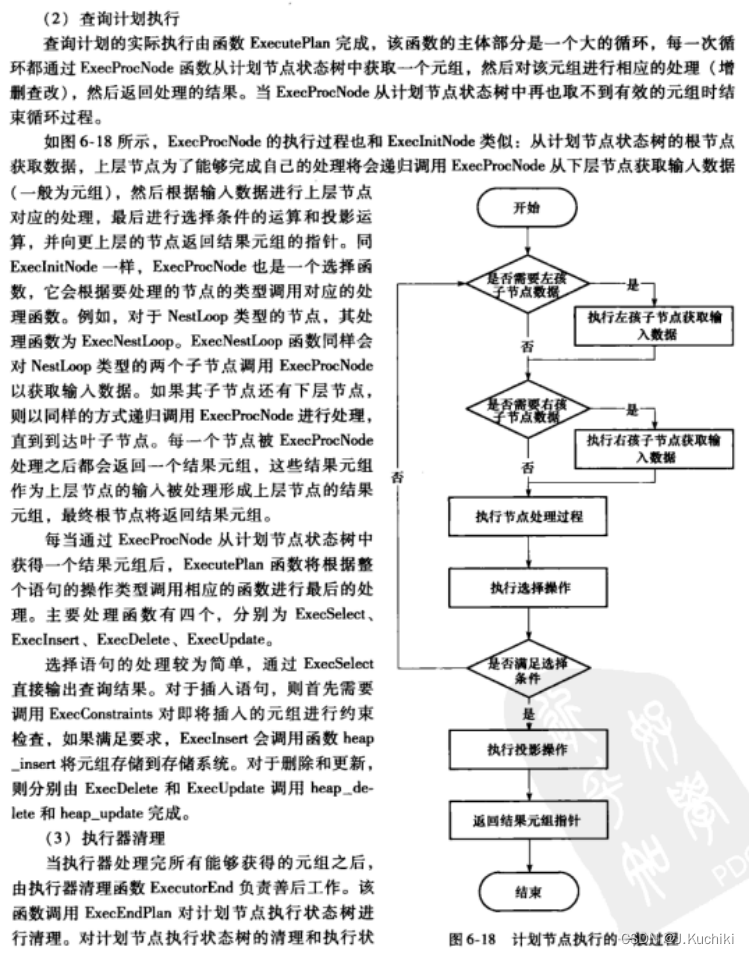
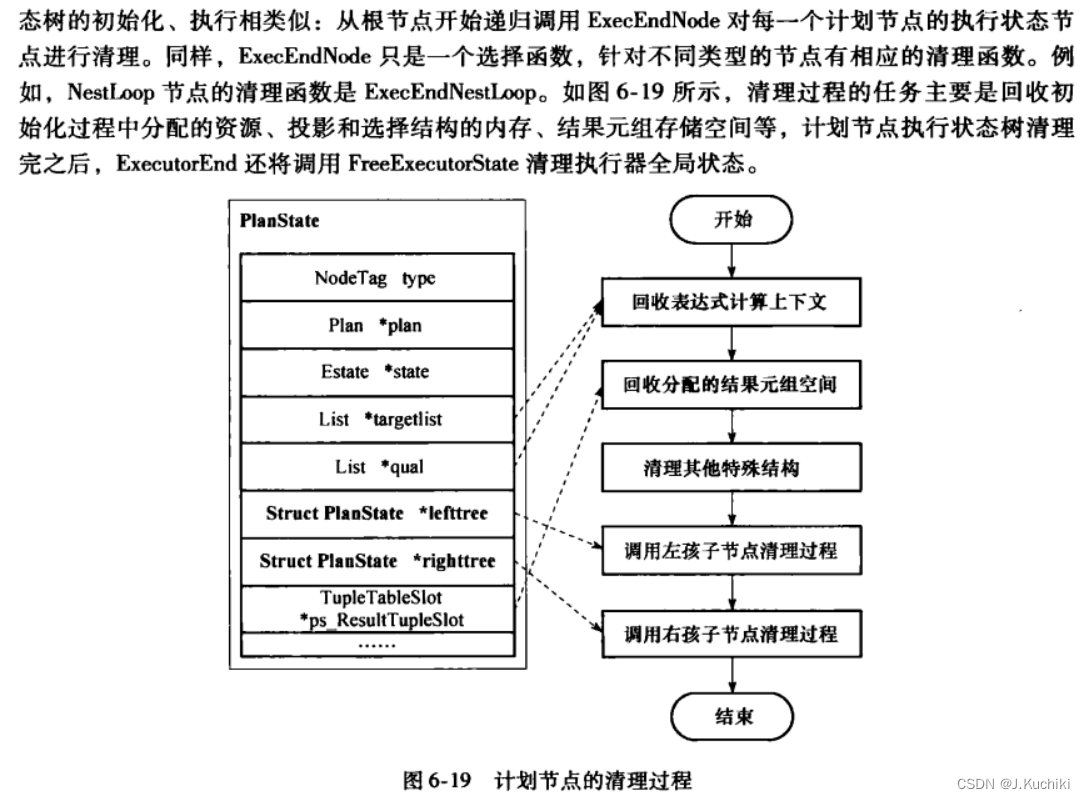
执行器运行时的函数调用关系如图6-15所示,ExecutorStart通过调用standard_ExecutorStart对执行器进行必要的初始化,主要工作包括构造EState结构和查询计划树的初始化(即构造对应的PlanState树,由InitPlan函数完成)。ExecutorRun的功能由standard_ExecutorRun 实现,在执仃过栓中会调用ExecutePlan完成查询计划的执行。ExecutorEnd由standard_ExecutorEnd 函数完成,通过调用ExecEndPlan处理执行状态树根节点释放已分配的资源,最后释放执行器全局状态EState完成整个执行过程。
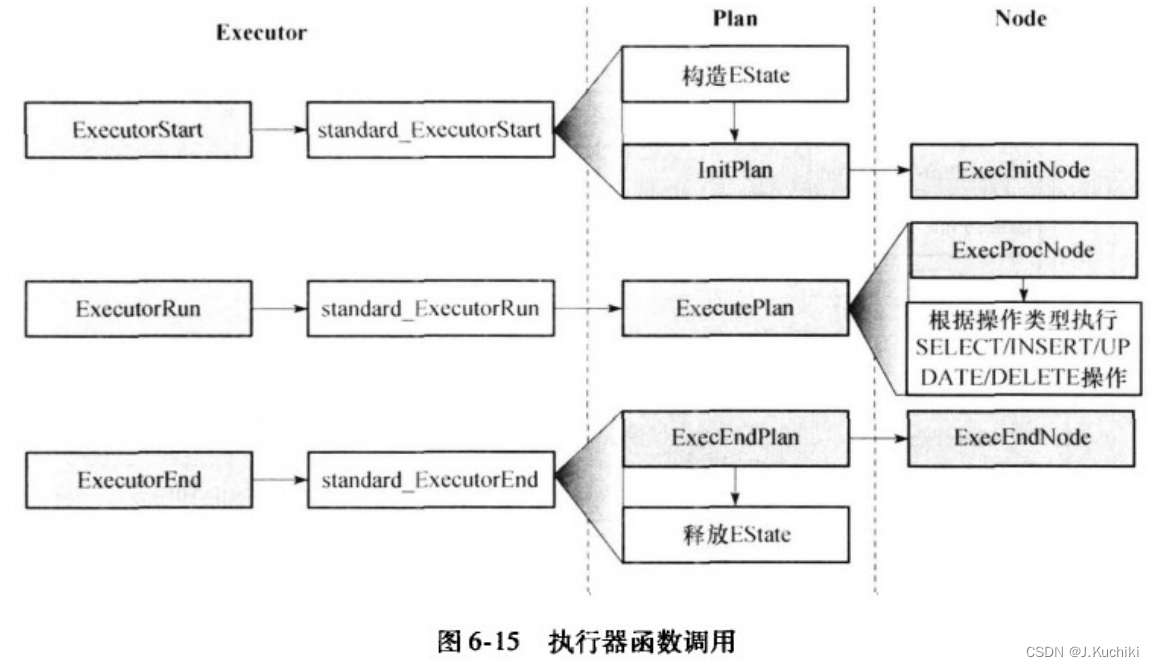
这里书中给出了大量的描述,为了方便整理,后续内容通过截图的方式呈现。

ExecutorStart函数和standard_ExecutorStart函数的源码如下所示:(路径:src/backend/executor/execMain.c)
/* ----------------------------------------------------------------
* ExecutorStart
*
* This routine must be called at the beginning of any execution of any
* query plan
*
* Takes a QueryDesc previously created by CreateQueryDesc (which is separate
* only because some places use QueryDescs for utility commands). The tupDesc
* field of the QueryDesc is filled in to describe the tuples that will be
* returned, and the internal fields (estate and planstate) are set up.
*
* eflags contains flag bits as described in executor.h.
*
* NB: the CurrentMemoryContext when this is called will become the parent
* of the per-query context used for this Executor invocation.
*
* We provide a function hook variable that lets loadable plugins
* get control when ExecutorStart is called. Such a plugin would
* normally call standard_ExecutorStart().
*
* ----------------------------------------------------------------
*/
void
ExecutorStart(QueryDesc *queryDesc, int eflags)
{
if (ExecutorStart_hook)
(*ExecutorStart_hook) (queryDesc, eflags);
else
standard_ExecutorStart(queryDesc, eflags);
}
void
standard_ExecutorStart(QueryDesc *queryDesc, int eflags)
{
EState *estate;
MemoryContext oldcontext;
/* sanity checks: queryDesc must not be started already */
Assert(queryDesc != NULL);
Assert(queryDesc->estate == NULL);
/*
* If the transaction is read-only, we need to check if any writes are
* planned to non-temporary tables. EXPLAIN is considered read-only.
*
* Don't allow writes in parallel mode. Supporting UPDATE and DELETE
* would require (a) storing the combocid hash in shared memory, rather
* than synchronizing it just once at the start of parallelism, and (b) an
* alternative to heap_update()'s reliance on xmax for mutual exclusion.
* INSERT may have no such troubles, but we forbid it to simplify the
* checks.
*
* We have lower-level defenses in CommandCounterIncrement and elsewhere
* against performing unsafe operations in parallel mode, but this gives a
* more user-friendly error message.
*/
if ((XactReadOnly || IsInParallelMode()) &&
!(eflags & EXEC_FLAG_EXPLAIN_ONLY))
ExecCheckXactReadOnly(queryDesc->plannedstmt);
/*
* Build EState, switch into per-query memory context for startup.
*/
estate = CreateExecutorState();
queryDesc->estate = estate;
oldcontext = MemoryContextSwitchTo(estate->es_query_cxt);
/*
* Fill in external parameters, if any, from queryDesc; and allocate
* workspace for internal parameters
*/
estate->es_param_list_info = queryDesc->params;
if (queryDesc->plannedstmt->nParamExec > 0)
estate->es_param_exec_vals = (ParamExecData *)
palloc0(queryDesc->plannedstmt->nParamExec * sizeof(ParamExecData));
estate->es_sourceText = queryDesc->sourceText;
/*
* Fill in the query environment, if any, from queryDesc.
*/
estate->es_queryEnv = queryDesc->queryEnv;
/*
* If non-read-only query, set the command ID to mark output tuples with
*/
switch (queryDesc->operation)
{
case CMD_SELECT:
/*
* SELECT FOR [KEY] UPDATE/SHARE and modifying CTEs need to mark
* tuples
*/
if (queryDesc->plannedstmt->rowMarks != NIL ||
queryDesc->plannedstmt->hasModifyingCTE)
estate->es_output_cid = GetCurrentCommandId(true);
/*
* A SELECT without modifying CTEs can't possibly queue triggers,
* so force skip-triggers mode. This is just a marginal efficiency
* hack, since AfterTriggerBeginQuery/AfterTriggerEndQuery aren't
* all that expensive, but we might as well do it.
*/
if (!queryDesc->plannedstmt->hasModifyingCTE)
eflags |= EXEC_FLAG_SKIP_TRIGGERS;
break;
case CMD_INSERT:
case CMD_DELETE:
case CMD_UPDATE:
estate->es_output_cid = GetCurrentCommandId(true);
break;
default:
elog(ERROR, "unrecognized operation code: %d",
(int) queryDesc->operation);
break;
}
/*
* Copy other important information into the EState
*/
estate->es_snapshot = RegisterSnapshot(queryDesc->snapshot);
estate->es_crosscheck_snapshot = RegisterSnapshot(queryDesc->crosscheck_snapshot);
estate->es_top_eflags = eflags;
estate->es_instrument = queryDesc->instrument_options;
/*
* Set up an AFTER-trigger statement context, unless told not to, or
* unless it's EXPLAIN-only mode (when ExecutorFinish won't be called).
*/
if (!(eflags & (EXEC_FLAG_SKIP_TRIGGERS | EXEC_FLAG_EXPLAIN_ONLY)))
AfterTriggerBeginQuery();
/*
* Initialize the plan state tree
*/
InitPlan(queryDesc, eflags);
MemoryContextSwitchTo(oldcontext);
}
CreateExecutorState函数源码如下:(路径:src/backend/executor/execUtils.c)
/* ----------------------------------------------------------------
* Executor state and memory management functions
* ----------------------------------------------------------------
*/
/* ----------------
* CreateExecutorState
*
* Create and initialize an EState node, which is the root of
* working storage for an entire Executor invocation.
*
* Principally, this creates the per-query memory context that will be
* used to hold all working data that lives till the end of the query.
* Note that the per-query context will become a child of the caller's
* CurrentMemoryContext.
* ----------------
*/
EState *
CreateExecutorState(void)
{
EState *estate;
MemoryContext qcontext;
MemoryContext oldcontext;
/*
* Create the per-query context for this Executor run.
*/
qcontext = AllocSetContextCreate(CurrentMemoryContext,
"ExecutorState",
ALLOCSET_DEFAULT_SIZES);
/*
* Make the EState node within the per-query context. This way, we don't
* need a separate pfree() operation for it at shutdown.
*/
oldcontext = MemoryContextSwitchTo(qcontext);
estate = makeNode(EState);
/*
* Initialize all fields of the Executor State structure
*/
estate->es_direction = ForwardScanDirection;
estate->es_snapshot = InvalidSnapshot; /* caller must initialize this */
estate->es_crosscheck_snapshot = InvalidSnapshot; /* no crosscheck */
estate->es_range_table = NIL;
estate->es_plannedstmt = NULL;
estate->es_junkFilter = NULL;
estate->es_output_cid = (CommandId) 0;
estate->es_result_relations = NULL;
estate->es_num_result_relations = 0;
estate->es_result_relation_info = NULL;
estate->es_root_result_relations = NULL;
estate->es_num_root_result_relations = 0;
estate->es_leaf_result_relations = NIL;
estate->es_trig_target_relations = NIL;
estate->es_trig_tuple_slot = NULL;
estate->es_trig_oldtup_slot = NULL;
estate->es_trig_newtup_slot = NULL;
estate->es_param_list_info = NULL;
estate->es_param_exec_vals = NULL;
estate->es_queryEnv = NULL;
estate->es_query_cxt = qcontext;
estate->es_tupleTable = NIL;
estate->es_rowMarks = NIL;
estate->es_processed = 0;
estate->es_lastoid = InvalidOid;
estate->es_top_eflags = 0;
estate->es_instrument = 0;
estate->es_finished = false;
estate->es_exprcontexts = NIL;
estate->es_subplanstates = NIL;
estate->es_auxmodifytables = NIL;
estate->es_per_tuple_exprcontext = NULL;
estate->es_epqTuple = NULL;
estate->es_epqTupleSet = NULL;
estate->es_epqScanDone = NULL;
estate->es_sourceText = NULL;
estate->es_use_parallel_mode = false;
/*
* Return the executor state structure
*/
MemoryContextSwitchTo(oldcontext);
return estate;
}
源码如下:(路径:src/backend/executor/execProcnode.c)
/* ------------------------------------------------------------------------
* ExecInitNode
*
* Recursively initializes all the nodes in the plan tree rooted
* at 'node'.
*
* Inputs:
* 'node' is the current node of the plan produced by the query planner
* 'estate' is the shared execution state for the plan tree
* 'eflags' is a bitwise OR of flag bits described in executor.h
*
* Returns a PlanState node corresponding to the given Plan node.
* ------------------------------------------------------------------------
*/
PlanState *
ExecInitNode(Plan *node, EState *estate, int eflags)
{
PlanState *result;
List *subps;
ListCell *l;
/*
* do nothing when we get to the end of a leaf on tree.
*/
if (node == NULL)
return NULL;
/*
* Make sure there's enough stack available. Need to check here, in
* addition to ExecProcNode() (via ExecProcNodeFirst()), to ensure the
* stack isn't overrun while initializing the node tree.
*/
check_stack_depth();
switch (nodeTag(node))
{
/*
* control nodes
*/
case T_Result:
result = (PlanState *) ExecInitResult((Result *) node,
estate, eflags);
break;
case T_ProjectSet:
result = (PlanState *) ExecInitProjectSet((ProjectSet *) node,
estate, eflags);
break;
case T_ModifyTable:
result = (PlanState *) ExecInitModifyTable((ModifyTable *) node,
estate, eflags);
break;
case T_Append:
result = (PlanState *) ExecInitAppend((Append *) node,
estate, eflags);
break;
case T_MergeAppend:
result = (PlanState *) ExecInitMergeAppend((MergeAppend *) node,
estate, eflags);
break;
case T_RecursiveUnion:
result = (PlanState *) ExecInitRecursiveUnion((RecursiveUnion *) node,
estate, eflags);
break;
case T_BitmapAnd:
result = (PlanState *) ExecInitBitmapAnd((BitmapAnd *) node,
estate, eflags);
break;
case T_BitmapOr:
result = (PlanState *) ExecInitBitmapOr((BitmapOr *) node,
estate, eflags);
break;
/*
* scan nodes
*/
case T_SeqScan:
result = (PlanState *) ExecInitSeqScan((SeqScan *) node,
estate, eflags);
break;
case T_SampleScan:
result = (PlanState *) ExecInitSampleScan((SampleScan *) node,
estate, eflags);
break;
case T_IndexScan:
result = (PlanState *) ExecInitIndexScan((IndexScan *) node,
estate, eflags);
break;
case T_IndexOnlyScan:
result = (PlanState *) ExecInitIndexOnlyScan((IndexOnlyScan *) node,
estate, eflags);
break;
case T_BitmapIndexScan:
result = (PlanState *) ExecInitBitmapIndexScan((BitmapIndexScan *) node,
estate, eflags);
break;
case T_BitmapHeapScan:
result = (PlanState *) ExecInitBitmapHeapScan((BitmapHeapScan *) node,
estate, eflags);
break;
case T_TidScan:
result = (PlanState *) ExecInitTidScan((TidScan *) node,
estate, eflags);
break;
case T_SubqueryScan:
result = (PlanState *) ExecInitSubqueryScan((SubqueryScan *) node,
estate, eflags);
break;
case T_FunctionScan:
result = (PlanState *) ExecInitFunctionScan((FunctionScan *) node,
estate, eflags);
break;
case T_TableFuncScan:
result = (PlanState *) ExecInitTableFuncScan((TableFuncScan *) node,
estate, eflags);
break;
case T_ValuesScan:
result = (PlanState *) ExecInitValuesScan((ValuesScan *) node,
estate, eflags);
break;
case T_CteScan:
result = (PlanState *) ExecInitCteScan((CteScan *) node,
estate, eflags);
break;
case T_NamedTuplestoreScan:
result = (PlanState *) ExecInitNamedTuplestoreScan((NamedTuplestoreScan *) node,
estate, eflags);
break;
case T_WorkTableScan:
result = (PlanState *) ExecInitWorkTableScan((WorkTableScan *) node,
estate, eflags);
break;
case T_ForeignScan:
result = (PlanState *) ExecInitForeignScan((ForeignScan *) node,
estate, eflags);
break;
case T_CustomScan:
result = (PlanState *) ExecInitCustomScan((CustomScan *) node,
estate, eflags);
break;
/*
* join nodes
*/
case T_NestLoop:
result = (PlanState *) ExecInitNestLoop((NestLoop *) node,
estate, eflags);
break;
case T_MergeJoin:
result = (PlanState *) ExecInitMergeJoin((MergeJoin *) node,
estate, eflags);
break;
case T_HashJoin:
result = (PlanState *) ExecInitHashJoin((HashJoin *) node,
estate, eflags);
break;
/*
* materialization nodes
*/
case T_Material:
result = (PlanState *) ExecInitMaterial((Material *) node,
estate, eflags);
break;
case T_Sort:
result = (PlanState *) ExecInitSort((Sort *) node,
estate, eflags);
break;
case T_Group:
result = (PlanState *) ExecInitGroup((Group *) node,
estate, eflags);
break;
case T_Agg:
result = (PlanState *) ExecInitAgg((Agg *) node,
estate, eflags);
break;
case T_WindowAgg:
result = (PlanState *) ExecInitWindowAgg((WindowAgg *) node,
estate, eflags);
break;
case T_Unique:
result = (PlanState *) ExecInitUnique((Unique *) node,
estate, eflags);
break;
case T_Gather:
result = (PlanState *) ExecInitGather((Gather *) node,
estate, eflags);
break;
case T_GatherMerge:
result = (PlanState *) ExecInitGatherMerge((GatherMerge *) node,
estate, eflags);
break;
case T_Hash:
result = (PlanState *) ExecInitHash((Hash *) node,
estate, eflags);
break;
case T_SetOp:
result = (PlanState *) ExecInitSetOp((SetOp *) node,
estate, eflags);
break;
case T_LockRows:
result = (PlanState *) ExecInitLockRows((LockRows *) node,
estate, eflags);
break;
case T_Limit:
result = (PlanState *) ExecInitLimit((Limit *) node,
estate, eflags);
break;
default:
elog(ERROR, "unrecognized node type: %d", (int) nodeTag(node));
result = NULL; /* keep compiler quiet */
break;
}
/*
* Add a wrapper around the ExecProcNode callback that checks stack depth
* during the first execution.
*/
result->ExecProcNodeReal = result->ExecProcNode;
result->ExecProcNode = ExecProcNodeFirst;
/*
* Initialize any initPlans present in this node. The planner put them in
* a separate list for us.
*/
subps = NIL;
foreach(l, node->initPlan)
{
SubPlan *subplan = (SubPlan *) lfirst(l);
SubPlanState *sstate;
Assert(IsA(subplan, SubPlan));
sstate = ExecInitSubPlan(subplan, result);
subps = lappend(subps, sstate);
}
result->initPlan = subps;
/* Set up instrumentation for this node if requested */
if (estate->es_instrument)
result->instrument = InstrAlloc(1, estate->es_instrument);
return result;
}
ExecutorRun函数和standard_ExecutorRun函数的源码如下所示:(路径:src/backend/executor/execMain.c)
/* ----------------------------------------------------------------
* ExecutorRun
*
* This is the main routine of the executor module. It accepts
* the query descriptor from the traffic cop and executes the
* query plan.
*
* ExecutorStart must have been called already.
*
* If direction is NoMovementScanDirection then nothing is done
* except to start up/shut down the destination. Otherwise,
* we retrieve up to 'count' tuples in the specified direction.
*
* Note: count = 0 is interpreted as no portal limit, i.e., run to
* completion. Also note that the count limit is only applied to
* retrieved tuples, not for instance to those inserted/updated/deleted
* by a ModifyTable plan node.
*
* There is no return value, but output tuples (if any) are sent to
* the destination receiver specified in the QueryDesc; and the number
* of tuples processed at the top level can be found in
* estate->es_processed.
*
* We provide a function hook variable that lets loadable plugins
* get control when ExecutorRun is called. Such a plugin would
* normally call standard_ExecutorRun().
*
* ----------------------------------------------------------------
*/
void
ExecutorRun(QueryDesc *queryDesc,
ScanDirection direction, uint64 count,
bool execute_once)
{
if (ExecutorRun_hook)
(*ExecutorRun_hook) (queryDesc, direction, count, execute_once);
else
standard_ExecutorRun(queryDesc, direction, count, execute_once);
}
void
standard_ExecutorRun(QueryDesc *queryDesc,
ScanDirection direction, uint64 count, bool execute_once)
{
EState *estate;
CmdType operation;
DestReceiver *dest;
bool sendTuples;
MemoryContext oldcontext;
/* sanity checks */
Assert(queryDesc != NULL);
estate = queryDesc->estate;
Assert(estate != NULL);
Assert(!(estate->es_top_eflags & EXEC_FLAG_EXPLAIN_ONLY));
/*
* Switch into per-query memory context
*/
oldcontext = MemoryContextSwitchTo(estate->es_query_cxt);
/* Allow instrumentation of Executor overall runtime */
if (queryDesc->totaltime)
InstrStartNode(queryDesc->totaltime);
/*
* extract information from the query descriptor and the query feature.
*/
operation = queryDesc->operation;
dest = queryDesc->dest;
/*
* startup tuple receiver, if we will be emitting tuples
*/
estate->es_processed = 0;
estate->es_lastoid = InvalidOid;
sendTuples = (operation == CMD_SELECT ||
queryDesc->plannedstmt->hasReturning);
if (sendTuples)
(*dest->rStartup) (dest, operation, queryDesc->tupDesc);
/*
* run plan
*/
if (!ScanDirectionIsNoMovement(direction))
{
if (execute_once && queryDesc->already_executed)
elog(ERROR, "can't re-execute query flagged for single execution");
queryDesc->already_executed = true;
ExecutePlan(estate,
queryDesc->planstate,
queryDesc->plannedstmt->parallelModeNeeded,
operation,
sendTuples,
count,
direction,
dest,
execute_once);
}
/*
* shutdown tuple receiver, if we started it
*/
if (sendTuples)
(*dest->rShutdown) (dest);
if (queryDesc->totaltime)
InstrStopNode(queryDesc->totaltime, estate->es_processed);
MemoryContextSwitchTo(oldcontext);
}
ExecutePlan函数源码如下:(路径:src/backend/executor/execMain.c)
/* ----------------------------------------------------------------
* ExecutePlan
*
* Processes the query plan until we have retrieved 'numberTuples' tuples,
* moving in the specified direction.
*
* Runs to completion if numberTuples is 0
*
* Note: the ctid attribute is a 'junk' attribute that is removed before the
* user can see it
* ----------------------------------------------------------------
*/
static void
ExecutePlan(EState *estate,
PlanState *planstate,
bool use_parallel_mode,
CmdType operation,
bool sendTuples,
uint64 numberTuples,
ScanDirection direction,
DestReceiver *dest,
bool execute_once)
{
TupleTableSlot *slot;
uint64 current_tuple_count;
/*
* initialize local variables
*/
current_tuple_count = 0;
/*
* Set the direction.
*/
estate->es_direction = direction;
/*
* If the plan might potentially be executed multiple times, we must force
* it to run without parallelism, because we might exit early. Also
* disable parallelism when writing into a relation, because no database
* changes are allowed in parallel mode.
*/
if (!execute_once || dest->mydest == DestIntoRel)
use_parallel_mode = false;
estate->es_use_parallel_mode = use_parallel_mode;
if (use_parallel_mode)
EnterParallelMode();
/*
* Loop until we've processed the proper number of tuples from the plan.
*/
for (;;)
{
/* Reset the per-output-tuple exprcontext */
ResetPerTupleExprContext(estate);
/*
* Execute the plan and obtain a tuple
*/
slot = ExecProcNode(planstate);
/*
* if the tuple is null, then we assume there is nothing more to
* process so we just end the loop...
*/
if (TupIsNull(slot))
{
/* Allow nodes to release or shut down resources. */
(void) ExecShutdownNode(planstate);
break;
}
/*
* If we have a junk filter, then project a new tuple with the junk
* removed.
*
* Store this new "clean" tuple in the junkfilter's resultSlot.
* (Formerly, we stored it back over the "dirty" tuple, which is WRONG
* because that tuple slot has the wrong descriptor.)
*/
if (estate->es_junkFilter != NULL)
slot = ExecFilterJunk(estate->es_junkFilter, slot);
/*
* If we are supposed to send the tuple somewhere, do so. (In
* practice, this is probably always the case at this point.)
*/
if (sendTuples)
{
/*
* If we are not able to send the tuple, we assume the destination
* has closed and no more tuples can be sent. If that's the case,
* end the loop.
*/
if (!((*dest->receiveSlot) (slot, dest)))
break;
}
/*
* Count tuples processed, if this is a SELECT. (For other operation
* types, the ModifyTable plan node must count the appropriate
* events.)
*/
if (operation == CMD_SELECT)
(estate->es_processed)++;
/*
* check our tuple count.. if we've processed the proper number then
* quit, else loop again and process more tuples. Zero numberTuples
* means no limit.
*/
current_tuple_count++;
if (numberTuples && numberTuples == current_tuple_count)
{
/* Allow nodes to release or shut down resources. */
(void) ExecShutdownNode(planstate);
break;
}
}
if (use_parallel_mode)
ExitParallelMode();
}
ExecProcNode函数源码如下:(路径:src/include/executor/executor.h)
/* ----------------------------------------------------------------
* ExecProcNode
*
* Execute the given node to return a(nother) tuple.
* ----------------------------------------------------------------
*/
#ifndef FRONTEND
static inline TupleTableSlot *
ExecProcNode(PlanState *node)
{
if (node->chgParam != NULL) /* something changed? */
ExecReScan(node); /* let ReScan handle this */
return node->ExecProcNode(node);
}
#endif
ExecReScan函数源码如下:(路径:src/backend/executor/execAmi.c)
/*
* ExecReScan
* Reset a plan node so that its output can be re-scanned.
*
* Note that if the plan node has parameters that have changed value,
* the output might be different from last time.
*/
void
ExecReScan(PlanState *node)
{
/* If collecting timing stats, update them */
if (node->instrument)
InstrEndLoop(node->instrument);
/*
* If we have changed parameters, propagate that info.
*
* Note: ExecReScanSetParamPlan() can add bits to node->chgParam,
* corresponding to the output param(s) that the InitPlan will update.
* Since we make only one pass over the list, that means that an InitPlan
* can depend on the output param(s) of a sibling InitPlan only if that
* sibling appears earlier in the list. This is workable for now given
* the limited ways in which one InitPlan could depend on another, but
* eventually we might need to work harder (or else make the planner
* enlarge the extParam/allParam sets to include the params of depended-on
* InitPlans).
*/
if (node->chgParam != NULL)
{
ListCell *l;
foreach(l, node->initPlan)
{
SubPlanState *sstate = (SubPlanState *) lfirst(l);
PlanState *splan = sstate->planstate;
if (splan->plan->extParam != NULL) /* don't care about child
* local Params */
UpdateChangedParamSet(splan, node->chgParam);
if (splan->chgParam != NULL)
ExecReScanSetParamPlan(sstate, node);
}
foreach(l, node->subPlan)
{
SubPlanState *sstate = (SubPlanState *) lfirst(l);
PlanState *splan = sstate->planstate;
if (splan->plan->extParam != NULL)
UpdateChangedParamSet(splan, node->chgParam);
}
/* Well. Now set chgParam for left/right trees. */
if (node->lefttree != NULL)
UpdateChangedParamSet(node->lefttree, node->chgParam);
if (node->righttree != NULL)
UpdateChangedParamSet(node->righttree, node->chgParam);
}
/* Call expression callbacks */
if (node->ps_ExprContext)
ReScanExprContext(node->ps_ExprContext);
/* And do node-type-specific processing */
switch (nodeTag(node))
{
case T_ResultState:
ExecReScanResult((ResultState *) node);
break;
case T_ProjectSetState:
ExecReScanProjectSet((ProjectSetState *) node);
break;
case T_ModifyTableState:
ExecReScanModifyTable((ModifyTableState *) node);
break;
case T_AppendState:
ExecReScanAppend((AppendState *) node);
break;
case T_MergeAppendState:
ExecReScanMergeAppend((MergeAppendState *) node);
break;
case T_RecursiveUnionState:
ExecReScanRecursiveUnion((RecursiveUnionState *) node);
break;
case T_BitmapAndState:
ExecReScanBitmapAnd((BitmapAndState *) node);
break;
case T_BitmapOrState:
ExecReScanBitmapOr((BitmapOrState *) node);
break;
case T_SeqScanState:
ExecReScanSeqScan((SeqScanState *) node);
break;
case T_SampleScanState:
ExecReScanSampleScan((SampleScanState *) node);
break;
case T_GatherState:
ExecReScanGather((GatherState *) node);
break;
case T_GatherMergeState:
ExecReScanGatherMerge((GatherMergeState *) node);
break;
case T_IndexScanState:
ExecReScanIndexScan((IndexScanState *) node);
break;
case T_IndexOnlyScanState:
ExecReScanIndexOnlyScan((IndexOnlyScanState *) node);
break;
case T_BitmapIndexScanState:
ExecReScanBitmapIndexScan((BitmapIndexScanState *) node);
break;
case T_BitmapHeapScanState:
ExecReScanBitmapHeapScan((BitmapHeapScanState *) node);
break;
case T_TidScanState:
ExecReScanTidScan((TidScanState *) node);
break;
case T_SubqueryScanState:
ExecReScanSubqueryScan((SubqueryScanState *) node);
break;
case T_FunctionScanState:
ExecReScanFunctionScan((FunctionScanState *) node);
break;
case T_TableFuncScanState:
ExecReScanTableFuncScan((TableFuncScanState *) node);
break;
case T_ValuesScanState:
ExecReScanValuesScan((ValuesScanState *) node);
break;
case T_CteScanState:
ExecReScanCteScan((CteScanState *) node);
break;
case T_NamedTuplestoreScanState:
ExecReScanNamedTuplestoreScan((NamedTuplestoreScanState *) node);
break;
case T_WorkTableScanState:
ExecReScanWorkTableScan((WorkTableScanState *) node);
break;
case T_ForeignScanState:
ExecReScanForeignScan((ForeignScanState *) node);
break;
case T_CustomScanState:
ExecReScanCustomScan((CustomScanState *) node);
break;
case T_NestLoopState:
ExecReScanNestLoop((NestLoopState *) node);
break;
case T_MergeJoinState:
ExecReScanMergeJoin((MergeJoinState *) node);
break;
case T_HashJoinState:
ExecReScanHashJoin((HashJoinState *) node);
break;
case T_MaterialState:
ExecReScanMaterial((MaterialState *) node);
break;
case T_SortState:
ExecReScanSort((SortState *) node);
break;
case T_GroupState:
ExecReScanGroup((GroupState *) node);
break;
case T_AggState:
ExecReScanAgg((AggState *) node);
break;
case T_WindowAggState:
ExecReScanWindowAgg((WindowAggState *) node);
break;
case T_UniqueState:
ExecReScanUnique((UniqueState *) node);
break;
case T_HashState:
ExecReScanHash((HashState *) node);
break;
case T_SetOpState:
ExecReScanSetOp((SetOpState *) node);
break;
case T_LockRowsState:
ExecReScanLockRows((LockRowsState *) node);
break;
case T_LimitState:
ExecReScanLimit((LimitState *) node);
break;
default:
elog(ERROR, "unrecognized node type: %d", (int) nodeTag(node));
break;
}
if (node->chgParam != NULL)
{
bms_free(node->chgParam);
node->chgParam = NULL;
}
}
ExecutorEnd函数和standard_ExecutorEnd函数的源码如下所示:(路径:src/backend/executor/execMain.c)
/* ----------------------------------------------------------------
* ExecutorEnd
*
* This routine must be called at the end of execution of any
* query plan
*
* We provide a function hook variable that lets loadable plugins
* get control when ExecutorEnd is called. Such a plugin would
* normally call standard_ExecutorEnd().
*
* ----------------------------------------------------------------
*/
void
ExecutorEnd(QueryDesc *queryDesc)
{
if (ExecutorEnd_hook)
(*ExecutorEnd_hook) (queryDesc);
else
standard_ExecutorEnd(queryDesc);
}
void
standard_ExecutorEnd(QueryDesc *queryDesc)
{
EState *estate;
MemoryContext oldcontext;
/* sanity checks */
Assert(queryDesc != NULL);
estate = queryDesc->estate;
Assert(estate != NULL);
/*
* Check that ExecutorFinish was called, unless in EXPLAIN-only mode. This
* Assert is needed because ExecutorFinish is new as of 9.1, and callers
* might forget to call it.
*/
Assert(estate->es_finished ||
(estate->es_top_eflags & EXEC_FLAG_EXPLAIN_ONLY));
/*
* Switch into per-query memory context to run ExecEndPlan
*/
oldcontext = MemoryContextSwitchTo(estate->es_query_cxt);
ExecEndPlan(queryDesc->planstate, estate);
/* do away with our snapshots */
UnregisterSnapshot(estate->es_snapshot);
UnregisterSnapshot(estate->es_crosscheck_snapshot);
/*
* Must switch out of context before destroying it
*/
MemoryContextSwitchTo(oldcontext);
/*
* Release EState and per-query memory context. This should release
* everything the executor has allocated.
*/
FreeExecutorState(estate);
/* Reset queryDesc fields that no longer point to anything */
queryDesc->tupDesc = NULL;
queryDesc->estate = NULL;
queryDesc->planstate = NULL;
queryDesc->totaltime = NULL;
}
ExecEndPlan函数源码如下:(路径:src/backend/executor/execMain.c)
/* ----------------------------------------------------------------
* ExecEndPlan
*
* Cleans up the query plan -- closes files and frees up storage
*
* NOTE: we are no longer very worried about freeing storage per se
* in this code; FreeExecutorState should be guaranteed to release all
* memory that needs to be released. What we are worried about doing
* is closing relations and dropping buffer pins. Thus, for example,
* tuple tables must be cleared or dropped to ensure pins are released.
* ----------------------------------------------------------------
*/
static void
ExecEndPlan(PlanState *planstate, EState *estate)
{
ResultRelInfo *resultRelInfo;
int i;
ListCell *l;
/*
* shut down the node-type-specific query processing
*/
ExecEndNode(planstate);
/*
* for subplans too
*/
foreach(l, estate->es_subplanstates)
{
PlanState *subplanstate = (PlanState *) lfirst(l);
ExecEndNode(subplanstate);
}
/*
* destroy the executor's tuple table. Actually we only care about
* releasing buffer pins and tupdesc refcounts; there's no need to pfree
* the TupleTableSlots, since the containing memory context is about to go
* away anyway.
*/
ExecResetTupleTable(estate->es_tupleTable, false);
/*
* close the result relation(s) if any, but hold locks until xact commit.
*/
resultRelInfo = estate->es_result_relations;
for (i = estate->es_num_result_relations; i > 0; i--)
{
/* Close indices and then the relation itself */
ExecCloseIndices(resultRelInfo);
heap_close(resultRelInfo->ri_RelationDesc, NoLock);
resultRelInfo++;
}
/* Close the root target relation(s). */
resultRelInfo = estate->es_root_result_relations;
for (i = estate->es_num_root_result_relations; i > 0; i--)
{
heap_close(resultRelInfo->ri_RelationDesc, NoLock);
resultRelInfo++;
}
/* likewise close any trigger target relations */
ExecCleanUpTriggerState(estate);
/*
* close any relations selected FOR [KEY] UPDATE/SHARE, again keeping
* locks
*/
foreach(l, estate->es_rowMarks)
{
ExecRowMark *erm = (ExecRowMark *) lfirst(l);
if (erm->relation)
heap_close(erm->relation, NoLock);
}
}
ExecEndNode函数源码如下:(路径src/backend/executor/execProcnode.c)
/* ----------------------------------------------------------------
* ExecEndNode
*
* Recursively cleans up all the nodes in the plan rooted
* at 'node'.
*
* After this operation, the query plan will not be able to be
* processed any further. This should be called only after
* the query plan has been fully executed.
* ----------------------------------------------------------------
*/
void
ExecEndNode(PlanState *node)
{
/*
* do nothing when we get to the end of a leaf on tree.
*/
if (node == NULL)
return;
/*
* Make sure there's enough stack available. Need to check here, in
* addition to ExecProcNode() (via ExecProcNodeFirst()), because it's not
* guaranteed that ExecProcNode() is reached for all nodes.
*/
check_stack_depth();
if (node->chgParam != NULL)
{
bms_free(node->chgParam);
node->chgParam = NULL;
}
switch (nodeTag(node))
{
/*
* control nodes
*/
case T_ResultState:
ExecEndResult((ResultState *) node);
break;
case T_ProjectSetState:
ExecEndProjectSet((ProjectSetState *) node);
break;
case T_ModifyTableState:
ExecEndModifyTable((ModifyTableState *) node);
break;
case T_AppendState:
ExecEndAppend((AppendState *) node);
break;
case T_MergeAppendState:
ExecEndMergeAppend((MergeAppendState *) node);
break;
case T_RecursiveUnionState:
ExecEndRecursiveUnion((RecursiveUnionState *) node);
break;
case T_BitmapAndState:
ExecEndBitmapAnd((BitmapAndState *) node);
break;
case T_BitmapOrState:
ExecEndBitmapOr((BitmapOrState *) node);
break;
/*
* scan nodes
*/
case T_SeqScanState:
ExecEndSeqScan((SeqScanState *) node);
break;
case T_SampleScanState:
ExecEndSampleScan((SampleScanState *) node);
break;
case T_GatherState:
ExecEndGather((GatherState *) node);
break;
case T_GatherMergeState:
ExecEndGatherMerge((GatherMergeState *) node);
break;
case T_IndexScanState:
ExecEndIndexScan((IndexScanState *) node);
break;
case T_IndexOnlyScanState:
ExecEndIndexOnlyScan((IndexOnlyScanState *) node);
break;
case T_BitmapIndexScanState:
ExecEndBitmapIndexScan((BitmapIndexScanState *) node);
break;
case T_BitmapHeapScanState:
ExecEndBitmapHeapScan((BitmapHeapScanState *) node);
break;
case T_TidScanState:
ExecEndTidScan((TidScanState *) node);
break;
case T_SubqueryScanState:
ExecEndSubqueryScan((SubqueryScanState *) node);
break;
case T_FunctionScanState:
ExecEndFunctionScan((FunctionScanState *) node);
break;
case T_TableFuncScanState:
ExecEndTableFuncScan((TableFuncScanState *) node);
break;
case T_ValuesScanState:
ExecEndValuesScan((ValuesScanState *) node);
break;
case T_CteScanState:
ExecEndCteScan((CteScanState *) node);
break;
case T_NamedTuplestoreScanState:
ExecEndNamedTuplestoreScan((NamedTuplestoreScanState *) node);
break;
case T_WorkTableScanState:
ExecEndWorkTableScan((WorkTableScanState *) node);
break;
case T_ForeignScanState:
ExecEndForeignScan((ForeignScanState *) node);
break;
case T_CustomScanState:
ExecEndCustomScan((CustomScanState *) node);
break;
/*
* join nodes
*/
case T_NestLoopState:
ExecEndNestLoop((NestLoopState *) node);
break;
case T_MergeJoinState:
ExecEndMergeJoin((MergeJoinState *) node);
break;
case T_HashJoinState:
ExecEndHashJoin((HashJoinState *) node);
break;
/*
* materialization nodes
*/
case T_MaterialState:
ExecEndMaterial((MaterialState *) node);
break;
case T_SortState:
ExecEndSort((SortState *) node);
break;
case T_GroupState:
ExecEndGroup((GroupState *) node);
break;
case T_AggState:
ExecEndAgg((AggState *) node);
break;
case T_WindowAggState:
ExecEndWindowAgg((WindowAggState *) node);
break;
case T_UniqueState:
ExecEndUnique((UniqueState *) node);
break;
case T_HashState:
ExecEndHash((HashState *) node);
break;
case T_SetOpState:
ExecEndSetOp((SetOpState *) node);
break;
case T_LockRowsState:
ExecEndLockRows((LockRowsState *) node);
break;
case T_LimitState:
ExecEndLimit((LimitState *) node);
break;
default:
elog(ERROR, "unrecognized node type: %d", (int) nodeTag(node));
break;
}
}