reduceByKey算子,聚合
列表中存放二元元组,元组中第一个为key,此算子按key聚合,传入计算逻辑
from pyspark import SparkConf, SparkContext
import os
os.environ["PYSPARK_PYTHON"] = "D:/dev/python/python3.10.4/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
准备RDD
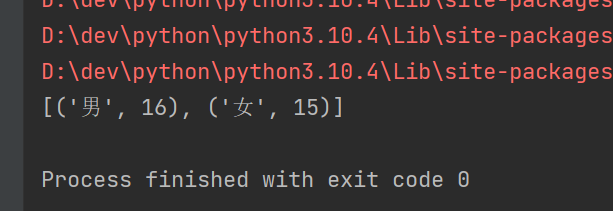
rdd = sc.parallelize([('男', 9), ('女', 9), ('男', 7), ('女', 6)])
reduceByKey()
rdd_2 = rdd.reduceByKey(lambda a, b: a + b)
使用collect方法收集结果
print(rdd_2.collect())
关闭pyspark
sc.stop()
案例1,单词计数
数据准备
from pyspark import SparkConf, SparkContext
import os
os.environ["PYSPARK_PYTHON"] = "D:\\dev\\python\\python3.10.4\\python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
使用textFile()读取文件,使用flatMap()算子,按空格分割单词
rdd = sc.textFile("D:/abc.txt")
rdd_2 = rdd.flatMap(lambda x: x.split(" "))
print(rdd_2.collect())

使用map算子将元素改造为(word,1)形式,便于使用reduceByKey;无法使用for循环

计数
rdd_4 = rdd_3.reduceByKey(lambda a, b: a + b)
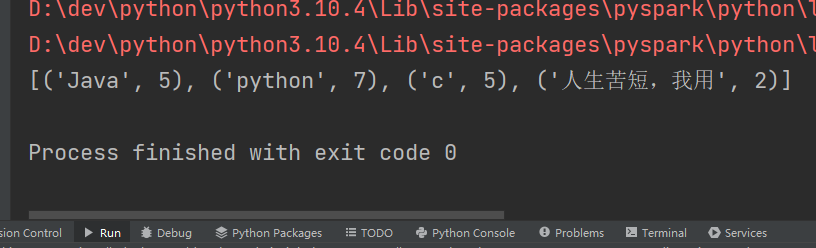
print(rdd_4.collect())
# 关闭
sc.stop()
filter方法,过滤
from pyspark import SparkConf, SparkContext
import os
os.environ["PYSPARK_PYTHON"] = "D:/dev/python/python3.10.4/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
准备RDD对象
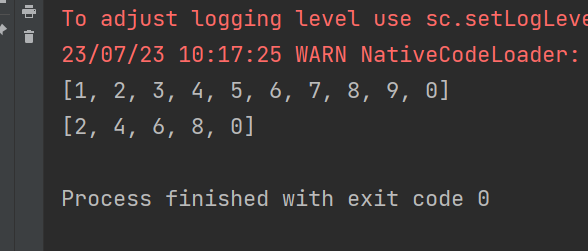
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9, 0])
filter()算子过滤,传入逻辑表达式,True留下
rdd_2 = rdd.filter(lambda x: x % 2 == 0)
print(rdd.collect())
print(rdd_2.collect())
sc.stop()
distinct算子,去重,无需传参
**from pyspark import SparkConf, SparkContext
import os
os.environ["PYSPARK_PYTHON"] = "D:/dev/python/python3.10.4/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_pyspark")
sc = SparkContext(conf=conf)**
准备RDD对象
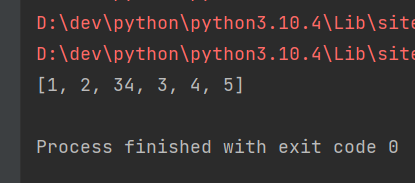
rdd = sc.parallelize([1, 1, 1, 2, 2, 2, 3, 3, 3, 3, 34, 4, 4, 5, 5])
distinct算子去重
print(rdd.distinct().collect())
sc.stop()
sortBy算子,排序,按谁排序就返回谁
from pyspark import SparkConf, SparkContext
import os
os.environ["PYSPARK_PYTHON"] = "D:/dev/python/python3.10.4/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
准备RDD对象
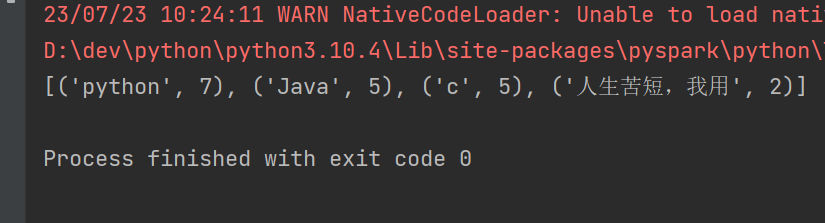
rdd = sc.parallelize([('Java', 5), ('python', 7), ('c', 5), ('人生苦短,我用', 2)])
sortBy算子,ascending为True升序,False降序

rdd_2 = rdd.sortBy(lambda x: x[1], ascending=False, numPartitions=1)
print(rdd_2.collect())
sc.stop()