一、说明
二、谷歌的问答和搜索
它显示,Google 最初在 1.6 秒内搜索并排名了 1 亿个页面,然后执行了额外的处理步骤以从页面中找到答案片段。第一个任务是谷歌作为搜索引擎的核心产品。第二个处理步骤(从网页中查找问题的答案)是问答 (QA) NLP 问题。QA NLP 系统是一种 NLP 系统,旨在回答以自然语言(如英语或中文)提出的问题。这些系统使用自然语言理解和知识表示技术的组合来分析问题并提供相关且准确的响应。这些系统通常用于搜索引擎、客户服务聊天机器人和虚拟助手等应用程序。
在QA NLP系统中,问题和上下文被传递给模型,模型从上下文中提取答案。此方法可用于构建企业级 QA 系统。例如,文档搜索引擎(如弹性搜索)可用于对获得问题答案概率最高的文档进行排名,并使用 QA 模型在该文档中查找答案。这些系统通常被称为读者检索器系统,其中文档搜索是检索器的任务,找到问题的答案是阅读的任务。由专注于NLP的德国公司Deepset开发的Haystack库可用于构建企业级的读取器检索器系统。但是,本文将只关注系统的QA回答(读者)部分,我们有一个上下文和一个问题,并希望得到答案。

图 2,使用 Haystack 库的 QA 系统(取自 Haystack GitHub 存储库)
图 3 显示了用于问答 NLP 系统的读取器-检索器架构示例。
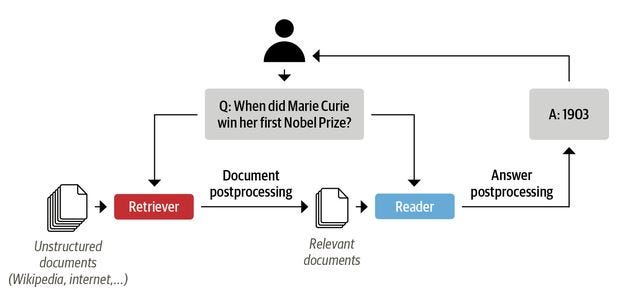
图 3:问答系统的读取器-检索器架构
2.1 带变压器的 QA NLP
现代自然语言处理(NLP)应用程序通常使用Google研究人员在2017年提出的转换器架构构建。1 这些架构优于递归神经网络(RNN)和长短期记忆(LSTM)网络,并使NLP领域的迁移学习成为可能。为大多数NLP应用提供动力的两种最流行的变压器架构是生成式预训练变压器(GPT)2和来自变压器的双向编码器表示(BERT)。3
最初的转换器论文基于编码器和解码器架构,通常用于机器翻译等任务,其中单词序列从一种语言到另一种语言(图 4)。后来,编码器和解码器模块在许多NLP模型中被改编为独立模型。仅编码器模型将输入标记转换为丰富的数字表示形式,非常适合文本分类或命名实体识别等问题。BERT,RoBERTa和DistilBERT是一些使用仅编码器变压器块的型号。仅解码器模型(即 GPT 模型)通常用于文本生成或自动完成任务,其中每个任务的表示形式取决于左侧上下文。
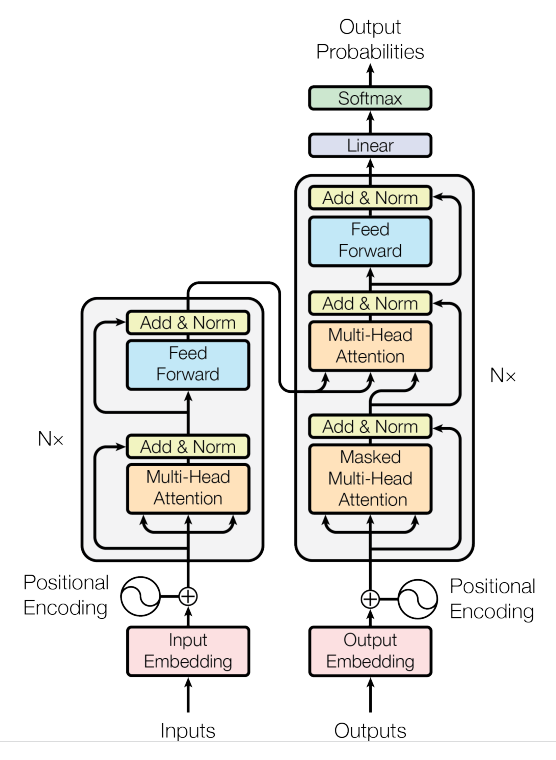
图4 变压器架构(摘自变压器原文))
变压器还使NLP领域的迁移学习成为可能。迁移学习是计算机视觉中的一种普遍实践,其中卷积神经网络在一项任务上进行训练,然后在新任务上进行微调和采用。在架构上,这涉及将模型拆分为主体和头部,其中头部是特定于任务的网络。在训练期间,体重从大规模数据集(如 ImageNet)中学习广泛的特征,这些数据集用于为新任务初始化新模型。这种方法成为计算机视觉的标准方法。生产中的大多数计算机视觉模型都是使用迁移学习技术进行训练的。
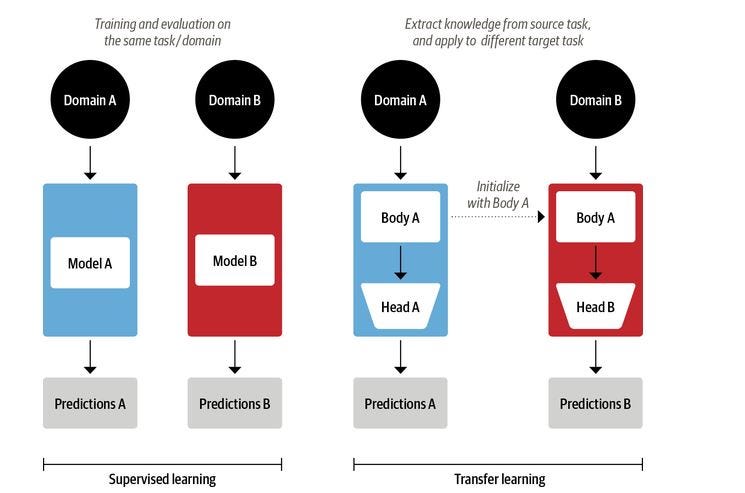
图 5 迁移学习,其中一个域的主体用于另一个域。
在变压器架构支持NLP中的变压器学习之后,许多机构发布了他们训练有素的NLP模型,供学者和从业者使用。GPT 和 BERT 是两个预先训练的模型,它们在各种 NLP 基准测试中采用了新的技术水平,并开创了变压器时代。随着时间的推移,不同的研究机构发布了转换器架构的不同变体,一些使用PyTorch,另一些使用Tensorflow,这使得从业者很难使用这些模型。HuggingFace创建了一组统一的API和一组预先训练的模型和数据集,简化了从业者采用最先进的NLP模型的过程。
2.2 用于 NLP 的 “抱面”humg-face 库
拥抱面变压器是最受欢迎的 NLP 库之一,为各种转换器模型以及代码和工具提供了标准化接口,以使这些模型适应新的用例。它还支持三个主要的深度学习框架:Pytorch,Tensorflow和JAX。Hugging Face 生态系统主要由两部分组成:一系列库和 Hub,如下所示。库提供代码,Hub 提供预先训练的模型权重、数据集、评估指标脚本等。
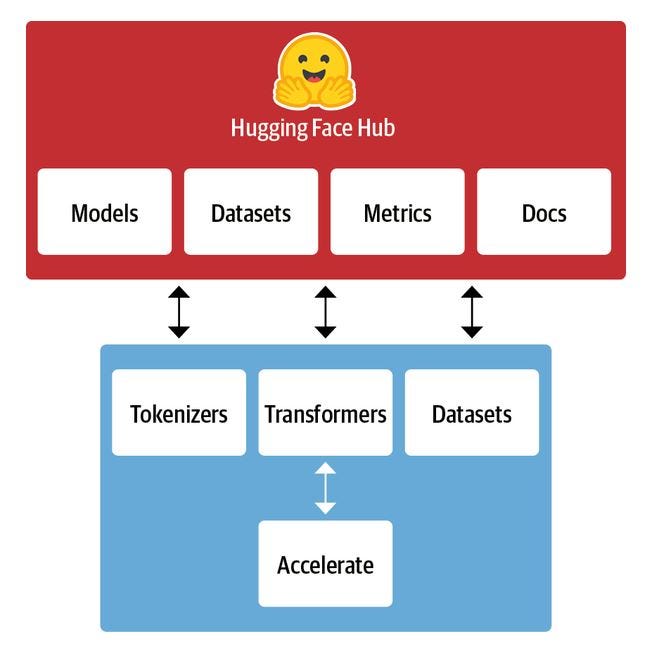
图 6 拥抱脸库的组件。
2.3 质量保证模型构建
我们使用squad_v2数据集从拥抱面模型中心微调预训练的变压器模型。Squad_v2将 SQuAD100.000 中的 1,1 个问题与众包工作者对抗性编写的 50,000 多个无法回答的问题结合起来,看起来与可回答的问题相似。系统尽可能回答问题,确定段落何时支持不回答并放弃回答。我们将使用MobileBert,流行的BERT模型的压缩版本。在 SQuAD v1.1/v2.0 问答任务中,MobileBERT 获得了 1.90/0.79 的 dev F2 分数(比 BERT_BASE 高 1.5/2.1)1。
我们将从拥抱面库中引入预先训练的模型和分词器。由于这将是一个同步的无服务器应用程序,我们将使用BERT模型(mobilebert)的小型版本来加快处理时间。以下 python 代码将在数据集上微调Squad_v2 mobilebert 模型下载到目录中。./model
from transformers import AutoModelForQuestionAnswering, AutoTokenizer
def get_model(model):
"""Loads model from Huggin face model hub into
the ./model directory"""
try:
model = AutoModelForQuestionAnswering.from_pretrained(model, use_cdn=True)
model.save_pretrained("./model")
except Exception as e:
raise (e)
get_model("mrm8488/mobilebert-uncased-finetuned-squadv2") 以下 python 代码将 mibilbert 分词器下载到目录中。./model
def get_tokenizer(tokenizer):
"""Loads tokenizer from Huggin face model hub into
the ./model directory"""
try:
tokenizer = AutoTokenizer.from_pretrained(tokenizer)
tokenizer.save_pretrained("./model")
except Exception as e:
raise (e)
get_tokenizer("mrm8488/mobilebert-uncased-finetuned-squadv2") 一旦我们有了分词器,我们就可以对进入模型的数据进行编码,并对来自模型的响应进行解码。以下代码适用于编码器函数,该函数接受问题、上下文和分词器并返回将传递给模型的 。attention_masksinpud_ids
def encode(tokenizer, question, context):
"""encodes the question and context with a given tokenizer
that is understandable to the model"""
encoded = tokenizer.encode_plus(question, context)
return encoded["input_ids"], encoded["attention_mask"]此代码片段会将模型的答案解码为人类可读的字符串格式。
def decode(tokenizer, token):
"""decodes the tokens to the answer with a given tokenizer
to return human readable response in a string format"""
answer_tokens = tokenizer.convert_ids_to_tokens(token, skip_special_tokens=True)
return tokenizer.convert_tokens_to_string(answer_tokens)我们必须将编码器、模型预测和解码器组合在一个方法中。下面的代码首先从目录中加载模型和分词器,并通过前面定义的编码器方法传递问题和上下文。然后,输出通过模型传递,最后,答案标记通过解码方法传递,以字符串格式获取答案。./model
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, AutoConfig
import torch
def serverless_pipeline(model_path="./model"):
"""Initializes the model and tokenzier and returns a predict
function that ca be used as pipeline"""
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForQuestionAnswering.from_pretrained(model_path)
def predict(question, context):
"""predicts the answer on an given question and context.
Uses encode and decode method from above"""
input_ids, attention_mask = encode(tokenizer, question, context)
start_scores, end_scores = model(
torch.tensor([input_ids]), attention_mask=torch.tensor([attention_mask])
)
ans_tokens = input_ids[
torch.argmax(start_scores) : torch.argmax(end_scores) + 1
]
answer = decode(tokenizer, ans_tokens)
return answer
return predict三、无服务器架构
图 1 显示了使用 AWS 云的 QA NLP 应用程序的无服务器架构。该应用程序的无服务器后端使用 AWS lambda、DynamoDB、API 网关和 ECR 进行容器注册表。Lambda 函数是包装在 docker 映像中并上传到 AWS ECR 的推理服务器。AWS API 网关将 POST 请求负载发送到 lambda 函数。AWS DynamoDB 存储发送到推理服务器的数据以进行监控。Lambda 可以使用仅允许对数据库进行写入访问的 IAM 角色与 DynamoDB 通信。
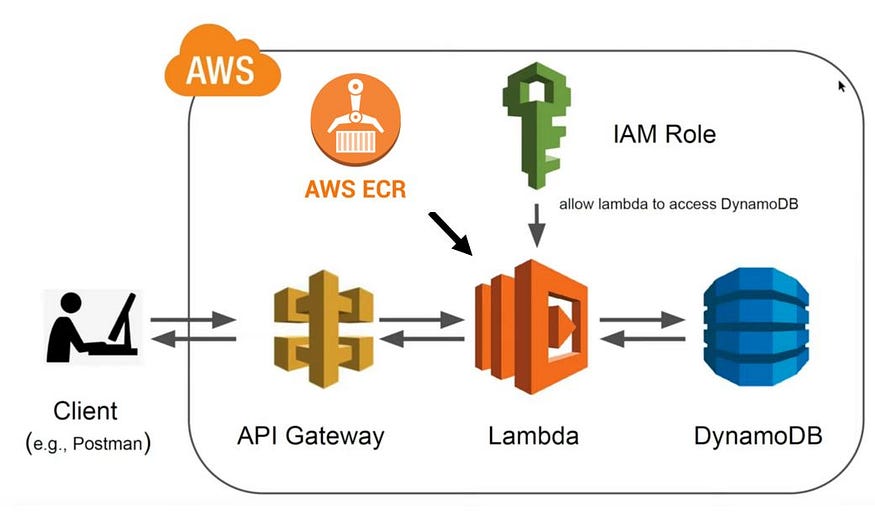
图 7 AWS 上的无服务器 QA NLP 架构
3.1 在 DynamoDB 中存储日志
DynamoDB 是一个完全托管的无服务器 NoSQL 数据库,非常适合存储模型的输入和输出,以便监控和评估模型。我们使用 boto3 库将日志放入我们的数据库中。我们将 DynamoDB 的名称保留在 Lambda 的环境变量中。我们希望将时间、有效载荷上下文和问题以及模型的答案存储在数据库中。以下代码在 DyanmoDB 中编写问题、上下文和模型答案。DYNAMO_TABLE
import boto3
import os
import uuid
import time
dynamodb = boto3.resource("dynamodb", region_name="us-east-1")
table = dynamodb.Table(os.environ["DYNAMODB_TABLE"])
timestamp = str(time.time())
item = {
"primary_key": str(uuid.uuid1()),
"createdAt": timestamp,
"context": body["context"],
"question": body["question"],
"answer": answer,
}
table.put_item(Item=item)3.2 λ函数
Lambda 是来自 AWS 的无服务器计算服务,将在其中提供推理服务。Lambda 处理程序是来自 API 请求的信息通过函数并将输出返回到 API 的地方。我们还将包括用于在函数中编写代码的 DynamoDB。
def handler(event, context):
try:
# loads the incoming event into a dictonary
body = json.loads(event["body"])
# uses the pipeline to predict the answer
answer = question_answering_pipeline(
question=body["question"], context=body["context"]
)
timestamp = str(time.time())
item = {
"primary_key": str(uuid.uuid1()),
"createdAt": timestamp,
"context": body["context"],
"question": body["question"],
"answer": answer,
}
table.put_item(Item=item)
return {
"statusCode": 200,
"headers": {
"Content-Type": "application/json",
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": True,
},
"body": json.dumps({"answer": answer}),
}
except Exception as e:
print(repr(e))
return {
"statusCode": 500,
"headers": {
"Content-Type": "application/json",
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": True,
},
"body": json.dumps({"error": repr(e)}),
}3.3 Dockerize Lambda 函数
由于 Lambda 函数现在支持 docker 映像,因此我们可以将所有内容 dockerize 并将其上传到 Amazon Elastic Container Registry (Amazon ECR) 存储库。Lambda 函数将访问此图像以进行预测。Dockerfile 使用 AWS 发布的基础映像来执行 Lambda 函数。
FROM public.ecr.aws/lambda/python:3.8
# Copy function code and models into our /var/task
COPY ./ ${LAMBDA_TASK_ROOT}/
# install our dependencies
RUN python3 -m pip install -r requirements.txt --target ${LAMBDA_TASK_ROOT}
# run get_model.py to get model weights and tokenizers
RUN python3 get_model.py
# Set the CMD to your handler (could also be done as a parameter override outside of the Dockerfile)
CMD [ "handler.handler" ]我们需要发送以构建、标记 docker 镜像并将其推送到 ECR 存储库。首先,我们必须使用 AWS CLI 登录到我们的 ECR 存储库。
aws_region=<your aws region>
aws_account_id=<your aws account>
aws ecr get-login-password --region $aws_region \
| docker login username AWS --password-stdin $aws_account_id.dkr.ecr.$aws_region.amazonaws.com然后构建、标记 docker 镜像并将其推送到 ECR 存储库。
docker build -t nlp-lambda:v1 serverless-bert/.
docker tag nlp-lambda:v1 $aws_account_id.dkr.ecr.$aws_region.amazonaws.com/nlp-lambda:v1
docker push $aws_account_id.dkr.ecr.$aws_region.amazonaws.com/nlp-lambda:v13.4 部署无服务器应用程序
我们将使用 Serverless 库,这是一个开源且与云无关的库,适用于所有主要的公共云提供商。使用 npm 安装无服务器(如果计算机上尚未安装)。如果您的计算机上没有 npm,请按照此处的安装说明进行操作。
npm install -g serverless下面是一个无服务器配置文件示例,用于使用 API 网关和 DynamoDB 部署 Lambda 函数,类似于图 7 中所示的架构:
service: serverless-bert-qa-lambda-docker
provider:
name: aws # provider
region: us-east-1 # aws region
memorySize: 5120 # optional, in MB
timeout: 30 # optional, in seconds
environment:
DYNAMODB_TABLE: ${self:service}-Table-${sls:stage}
iamRoleStatements:
- Effect: "Allow"
Action:
- "dynamodb:PutItem"
Resource: arn:aws:dynamodb:${aws:region}:${aws:accountId}:table/${self:service}-Table-${sls:stage}
functions:
questionanswering:
image: ${ACOUNT_NUMBER}.dkr.ecr.us-east-1.amazonaws.com/bert-lambda:v1 #ecr url
events:
- http:
path: qa # http path
method: post # http method
resources:
Resources:
CustomerTable:
Type: AWS::DynamoDB::Table
Properties:
AttributeDefinitions:
- AttributeName: primary_key
AttributeType: S
BillingMode: PAY_PER_REQUEST
KeySchema:
- AttributeName: primary_key
KeyType: HASH
TableName: ${self:service}-Table-${sls:stage}无服务器框架需要 AWS 凭证才能代表我们访问 AWS 资源。如果您没有 IAM 用户,请按照此说明创建 IAM 用户,并使用该用户设置凭证。建议使用 AWS-CLI 配置 AWS 凭证。要通过 进行设置,请先安装它,然后运行以配置 AWS-CLI 和凭证:aws-cliaws configure
$ aws configure
AWS Access Key ID [None]:
AWS Secret Access Key [None]:
Default region name [None]:
Default output format [None]: 一切准备就绪后,以下命令将使用无服务器配置文件并将基础设施部署到 AWS。确保您与配置文件位于同一目录中。
serverless deploy部署完成后,无服务器将返回可用于测试模型的 API 网关的 URL。您可以使用 Postman、javascript 或 curl 来调用模型。在此项目的 GitHub 存储库中,创建了一个使用 HTML、CSS 和 javascript 的简单前端应用程序,用于与部署的 API 网关进行交互。

图 8 QA NLP 应用程序的前端应用程序
四、总结
问答 NLP 模型通常用于搜索引擎、客户服务聊天机器人和虚拟助手等应用程序。这篇博文描述了 QA NLP 问题,并使用 HuggingFace 库和 AWS 基础设施构建和部署了一个全栈无服务器 QA NLP 应用程序。无服务器 ML 应用程序可能不是适用于所有用例的良好部署方法,但它是您将模型投入生产而无需担心底层基础设施的重要第一步。