一、前言
前一篇我们了解了Pod的基本概念和操作,本篇我们继续研究Pod的一些高级特性,包括Pod的生命周期,pod探针,pod的调度等。
二、生命周期
1、Pod的生命周期
Pod的生命周期示意图如下:

- 挂起(Pending),接受创建Pod指令,相关信息存入了etcd,但是还未完成调度
- 容器创建(ContainerCreating),Pod完成调度,分配到指定的Node,容器处于创建过程中,一般是镜像正在拉取。
- 运行(Running),所有的容器都已经创建完成,至少有一个容器正在运行,或者正处于启动或重启状态。
- 失败(Failed),Pod 中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非0状态退出或者被系统终止。
- 成功(Succeed),Pod 中的所有容器都被成功终止,并且不会再重启。
- 未知(Unknown),因为某些原因无法取得 Pod 的状态,通常是因为与 Pod 所在主机通信失败。
下面我们来演示下整个过程,使用kubectl get pod --watch来追踪pod状态的变化。此演示需要打开两个终端会话。
首先打开一个终端会话(A)输入:
[root@k8s-master ~]# kubectl get pod --watch然后再打开另一个终端会话(B)创建pod(使用上一篇的busybox-pod.yaml)
[root@k8s-master yaml]# kubectl apply -f busybox-pod.yaml
pod/busybox-pod created可以从终端A看到状态的变化过程
NAME READY STATUS RESTARTS AGE
busybox-pod 0/2 Pending 0 0s
busybox-pod 0/2 Pending 0 0s
busybox-pod 0/2 ContainerCreating 0 0s
busybox-pod 0/2 ContainerCreating 0 0s
busybox-pod 2/2 Running 0 17s在终端A中删除该pod
[root@k8s-master yaml]# kubectl delete pod busybox-pod
pod "busybox-pod" deleted在终端B中看到状态变化
busybox-pod 2/2 Terminating 0 3m52s至于failed状态,我们下面再看。
2、Pod Hook
K8S提供了两种生命周期钩子,PostStart和PreStop。
- PostStart:这个钩⼦在容器创建后立即执⾏。但是,并不能保证钩子将在容器 ENTRYPOINT 之前运⾏,因为没有参数传递给处理程序。主要⽤于资源部署、环境准备等。不过需要注意的是如果钩子花费太长时间以⾄于不能运⾏或者挂起, 容器将不能达到 running 状态。
- PreStop:这个钩子在容器终止之前立即被调⽤。它是阻塞的,意味着它是同步的, 所以它必须在删除容器的调⽤发出之前完成。主要⽤于优雅关闭应⽤程序、通知其他系统等。如果钩⼦在执⾏期间挂起, Pod阶段将停留在 running 状态并且永不会达到 failed 状态。
一方面,钩子执行失败, 会直接杀死容器;另一方面,钩子执行时同步阻塞过程,所以这两个钩子尽量需要轻量。
有两种⽅式来实现上⾯的钩⼦函数:
- Exec – ⽤于执⾏⼀段特定的命令,不过要注意的是该命令消耗的资源会被计⼊容器。
- HTTP – 对容器上的特定的端点执⾏ HTTP 请求。
下面我们就来用Exec演示下,创建lifecycle-pod.yaml文件,内容如下:
[root@k8s-master yaml]# cat lifecycle-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-pod
labels:
app: lifecycle
spec:
containers:
- name: lifecycle-demo
image: nginx
ports:
- name: webport
containerPort: 80
volumeMounts:
- name: message
mountPath: /usr/share/
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
preStop:
exec:
command: ['/bin/sh', '-c', 'echo Hello from the preStop Handler > /usr/share/message']
volumes:
- name: message
hostPath:
path: /tmp我们来分析下,定义了lifecycle属性,包含了postStart和preStop两个钩子函数,该函数分别往容器的/usr/share/message文件里打印一段话,为了查询文件方面,我们将这个文件挂载到节点的/tmp下(这部分内容后面存储章节我们在详细介绍)。
接下来我们执行下这个文件,创建该pod。
[root@k8s-master yaml]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
lifecycle-pod 1/1 Running 0 65m 10.244.36.86 k8s-node1 <none> <none>等到pod处于running状态时,再看下节点(k8s-node1)的/tmp目录下,已经生成了message文件,并写入了postStart钩子函数的语句。
[root@k8s-node1 tmp]# cat message
Hello from the postStart handler再手动删除该pod后,看下该文件
[root@k8s-node1 tmp]# cat message
Hello from the preStop Handler代表preStop钩子在容器停止前成功执行了。
如果有错误,可以使用describe指令,看到 FailedPostStartHook 或 FailedPreStopHook 这样的 event。
3、容器重启策略
Pod对于内部运行所有容器,通过restartPolicy指定重启策略,其值包括Always , OnFailure以及Never三种。
- Always,当容器终止退出后,总是重启容器,默认策略。
- OnFailure,仅当容器异常退出(退出状态码非0)时,重启容器。
- Never,当容器终止退出,从不重启容器。
下面分别用容器异常退出和正常退出两个场景实例,演示下这三种重启策略的效果。
(1)异常退出
首先演示异常退出的场景,创建restartpolicy-unhealthy-pod.yaml文件,容器内执行脚本,20s后退出,状态码为3(非0,表示异常退出),内容如下:
[root@k8s-master yaml]# cat restartpolicy-unhealthy-pod.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
app: restartpolicy-unhealthy-pod
name: restartpolicy-unhealthy-pod
spec:
restartPolicy: Always
containers:
- name: unhealthy
image: busybox
args:
- /bin/sh
- -c
- sleep 20; exit 3; 将restartPolicy设置为Always,容器失败退出后,Pod重启。
[root@k8s-master yaml]# kubectl apply -f restartpolicy-healthy-pod.yaml
pod/restartpolicy-healthy-pod created
[root@k8s-master yaml]# kubectl get pod --watch
NAME READY STATUS RESTARTS AGE
restartpolicy-unhealthy-pod 1/1 Running 0 12s
restartpolicy-unhealthy-pod 0/1 Error 0 22s
restartpolicy-unhealthy-pod 1/1 Running 1 (17s ago) 38s将restartPolicy设置为OnFailure,容器失败退出后,Pod重启。
[root@k8s-master ~]# kubectl get pod --watch
NAME READY STATUS RESTARTS AGE
restartpolicy-unhealthy-pod 0/1 Pending 0 0s
restartpolicy-unhealthy-pod 0/1 Pending 0 0s
restartpolicy-unhealthy-pod 0/1 ContainerCreating 0 0s
restartpolicy-unhealthy-pod 0/1 ContainerCreating 0 1s
restartpolicy-unhealthy-pod 1/1 Running 0 17s
restartpolicy-unhealthy-pod 0/1 Error 0 37s
restartpolicy-unhealthy-pod 1/1 Running 1 (1s ago) 38s将restartPolicy设置为Never,失败退出后,Pod结束。
[root@k8s-master ~]# kubectl get pod --watch
NAME READY STATUS RESTARTS AGE
restartpolicy-unhealthy-pod 0/1 Pending 0 0s
restartpolicy-unhealthy-pod 0/1 Pending 0 0s
restartpolicy-unhealthy-pod 0/1 ContainerCreating 0 0s
restartpolicy-unhealthy-pod 0/1 ContainerCreating 0 1s
restartpolicy-unhealthy-pod 1/1 Running 0 2s
restartpolicy-unhealthy-pod 0/1 Error 0 23s
restartpolicy-unhealthy-pod 0/1 Error 0 23s(2)正常退出
我们再演示一个正常退出的场景,创建restartpolicy-healthy-pod.yaml文件,容器内执行脚本,20s后退出,状态码为0(正常退出),内容如下:
[root@k8s-master yaml]# cat restartpolicy-healthy-pod.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
app: restartpolicy-healthy-pod
name: restartpolicy-healthy-pod
spec:
restartPolicy: Always
containers:
- name: healthy
image: busybox
args:
- /bin/sh
- -c
- sleep 20; exit 0; 将restartPolicy设置为Always,容器正常退出后,Pod重启。
NAME READY STATUS RESTARTS AGE
restartpolicy-healthy-pod 0/1 Pending 0 0s
restartpolicy-healthy-pod 0/1 Pending 0 0s
restartpolicy-healthy-pod 0/1 ContainerCreating 0 0s
restartpolicy-healthy-pod 0/1 ContainerCreating 0 1s
restartpolicy-healthy-pod 1/1 Running 0 16s
restartpolicy-healthy-pod 0/1 Completed 0 26s
restartpolicy-healthy-pod 1/1 Running 1 (16s ago) 42s
restartpolicy-healthy-pod 0/1 Completed 1 (26s ago) 52s
restartpolicy-healthy-pod 0/1 CrashLoopBackOff 1 (13s ago) 65s
restartpolicy-healthy-pod 1/1 Running 2 (15s ago) 67s
restartpolicy-healthy-pod 0/1 Completed 2 (25s ago) 77s
将restartPolicy设置为OnFailure,容器正常退出后,Pod退出
[root@k8s-master ~]# kubectl get pod --watch
NAME READY STATUS RESTARTS AGE
restartpolicy-healthy-pod 0/1 Pending 0 0s
restartpolicy-healthy-pod 0/1 Pending 0 0s
restartpolicy-healthy-pod 0/1 ContainerCreating 0 0s
restartpolicy-healthy-pod 0/1 ContainerCreating 0 0s
restartpolicy-healthy-pod 1/1 Running 0 16s
restartpolicy-healthy-pod 0/1 Completed 0 26s
restartpolicy-healthy-pod 0/1 Completed 0 26s将restartPolicy设置为Never,容器正常退出后,Pod退出。
[root@k8s-master ~]# kubectl get pod --watch
NAME READY STATUS RESTARTS AGE
restartpolicy-healthy-pod 0/1 Pending 0 0s
restartpolicy-healthy-pod 0/1 Pending 0 0s
restartpolicy-healthy-pod 0/1 ContainerCreating 0 0s
restartpolicy-healthy-pod 0/1 ContainerCreating 0 1s
restartpolicy-healthy-pod 1/1 Running 0 17s
restartpolicy-healthy-pod 0/1 Completed 0 27s
restartpolicy-healthy-pod 0/1 Completed 0 27s综上所述,我们来总结下:
restartPolicy为Always时,无论异常还是正常退出,Pod都会重启。
restartPolicy为OnFailure时,仅异常退出时,Pod才会重启。
restartPolicy为Never时,无论异常还是正常退出,Pod都不会重启。
4、探针
上面重启策略是针对容器的运行状态,但很多情况下,容器是处于正常状态,但是容器中的应用已经异常,无法工作了,此种情况也需要Pod进行处理的。此时Pod就需要感知应用的状态,再结合重启策略,进行下一步处理。由于应用的运行状态,只有业务方才能感知和定义,所以Pod通过开放"钩子"定义,并定时执行"钩子",以便获取应用状态。这些"钩子"就是探针,根据探针的目的不同,又分为以下三种类型:
- LivenessProbe(存活探针)
- ReadinessProbe(就绪探针)
- StartupProbe(启动探针)
每次探测都将获得以下三种结果之一:
- 成功:容器通过了诊断。
- 失败:容器未通过诊断。
- 未知:诊断失败,因此不会采取任何行动。
(1)LivenessProbe(存活探针)
存活探针主要是在容器启动后,探测容器内应用的存活状态,这也是常用的检索机制,其包含三种探测类型。
- exec,在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功
- httpGet,对容器的 IP 地址上指定端口和路径执行 HTTP
GET请求。如果响应的状态码大于等于 200 且小于 400,则诊断被认为是成功的。 - tcpSocket,容器的 IP 地址上的指定端口执行 TCP 检查。如果端口打开,则诊断被认为是成功的。
其主要配置参数有:
- initialDelaySeconds,容器启动后,多长时间才开始第一次探测, 默认是 0 秒,最小值是 0。
- periodSeconds,执行探测的时间间隔(单位是秒)。默认是 10 秒。最小值是 1。
- timeoutSeconds,探测的超时后等待多少秒。默认值是 1 秒。最小值是 1。
- failureThreshold,当探测失败时,Kubernetes 的重试次数。
- successThreshold,当探针在失败后,被视为成功的最小连续成功数。默认值是 1。
下面我用一张图描述探测过程中,各个参数的作用。

我们使用exec模式演示下面实例:
1)创建一个liveness-exec-pod.yaml文件,内容如下:
[root@k8s-master yaml]# cat liveness-exec-pod.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
app: liveness-exec-pod
name: liveness-exec-pod
spec:
containers:
- name: liveness
image: busybox
args:
- /bin/sh
- -c
- echo ok > /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
timeoutSeconds: 1
periodSeconds: 5我们先来理论分析下该过程。该容器启动后,通过脚本创建/tmp/healthy文件,并写入"ok", sleep 30s后,删除该文件,模拟业务异常。探针使用cat指令,显示文件内容,如果文件不存在,则返回非0。在容器启动5s后,首次探索,后续每个5s探测一次,当30s删除文件后,容器进程还正在运行,但是由于文件删除,导致探测失败,认为业务已经异常,将重启容器。
2) 创建pod
[root@k8s-master yaml]# kubectl apply -f liveness-exec-pod.yaml
pod/liveness-exec-pod created3)查找状态
[root@k8s-master yaml]# kubectl describe pod liveness-exec-pod这里我们在详情中查看状态,结果如下,探针检查识别后失败后(3次重试),重启容器。

4)设置restartPolicy重启策略
业务存活探针的结果对于重启策略的影响,是否和容器状态对于重启策略是一致的?
在liveness-exec-pod.yaml文件中,没有定义restartPolicy,默认为Always,探测失败后Pod重启。我们再将其设置为其他两种(OnFailure,Never)看下。
修改iveness-exec-pod.yaml,在spec中增加restartPolicy: Never,删除旧的pod,重启创建Pod
[root@k8s-master yaml]# kubectl delete pod liveness-exec-pod
pod "liveness-exec-pod" deleted
[root@k8s-master yaml]# kubectl apply -f liveness-exec-pod.yaml
pod/liveness-exec-pod created执行查看详情指令,探针重试三次识别后,停止了容器,Pod不会重启。

可以再将重启策略修改为restartPolicy: OnFailure看下,其结果与Always一致,Pod重启。

由此可知,对于重启策略的影响,存活探针的结果,等同与容器的状态。
(2)ReadinessProbe(就绪探针)
存活探针主要探针业务是否正常,就绪探针主要探测业务是否准备好提供服务了,如果探测失败,表明该业务未就绪,不会向该Pod的分发流量,当探测成功后,才认为是就绪状态,开始向 Pod 发送流量,一般与service配合使用。其探测机制与参数与LivenessProbe(存活探针)一致。其探测过程如下图描述:

下面我们采用httpGet模式示例演示下。
创建readiness-http-pod.yaml,其内容如下:
[root@k8s-master yaml]# cat readiness-http-pod.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
app: readiness-http
name: readiness-http
spec:
containers:
- name: readiness-http
image: tcy83/readiness:v1.0
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
---
apiVersion: v1
kind: Service
metadata:
name: readiness-http-svc
spec:
ports:
- port: 8080
targetPort: 8080
selector:
app: readiness-http该内容包含一个Pod对象和一个Service对象(关于service内容,K8S初级入门系列之八-Service核心概念将介绍,现在可以理解成pod网关代理,类似nginx)
我们来分析下Pod对象,其包含一个名为readiness-http容器,镜像tcy83/readiness:v1.0(已上传DockerHub)代码片段如下

请求/health的接口不超过5次,返回200状态码,超过5次则抛出异常,返回500状态码。
该容器定义readinessProbe探针,其模式为httpGet,容器启动后延迟5s,开始第一次探测,请求/health接口,后续每隔5s探测一次。
理论分析得知,readiness探针将在请求5次后失败,将无法通过service访问。我们来实验下:
(1)创建pod,并查看下pod的运行状态
[root@k8s-master yaml]# kubectl apply -f readiness-http-pod.yaml
[root@k8s-master yaml]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
readiness-http 0/1 Running 0 6m33s 10.244.36.68 k8s-node1 <none> <none>Pod运行后,我们查看下端点(endpoint),可以看到该容器的ip地址已经加入到端点的地址,说明已经处于就绪状态。
[root@k8s-master yaml]# kubectl get ep
NAME ENDPOINTS AGE
kubernetes 192.168.16.4:6443 28d
readiness-http-svc 10.244.36.68:8080 8d查看service的地址
[root@k8s-master yaml]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 28d
readiness-http-svc ClusterIP 10.99.142.12 <none> 8080/TCP 8d通过service地址访问应用
[root@k8s-master yaml]# curl http://10.99.142.12:8080/health
OK就绪状态下,通过service 的ip可以正确访问应用接口。
(2)探测失败
一段时间后(大于30s后),我们再来查看下pod的状态,探测失败

查看下端点的列表,此时容器的ip地址已经从端点列表中删除
[root@k8s-master yaml]# kubectl get ep
NAME ENDPOINTS AGE
kubernetes 192.168.16.4:6443 28d
readiness-http-svc 8d再用service地址访问下应用,已经无法访问。但是pod还是处于运行状态,仅无法对外提供服务。
[root@k8s-master yaml]# curl http://10.99.142.12:8080/health
curl: (7) Failed to connect to 10.99.142.12 port 8080: Connection refused
[root@k8s-master yaml]# kubectl get pod
NAME READY STATUS RESTARTS AGE
readiness-http 0/1 Running 0 4m43s一般情况下,存活探针和就绪探针采用同样的探针接口,也就是业务失败后,就立即从service中摘除,阻止业务的继续访问,放置异常的进一步扩算。
(3)StartupProbe(启动探针)
启动探针主要指示容器中的应用是否已经启动。如果提供了启动探针,则所有其他探针都会被 禁用,直到此探针成功为止。
如果没有启动探针,那么存活探针和就绪探针都是在容器启动后就开始计时,initialDelaySeconds到期后,开始探测,如果应用的启动时间较长,而相关的参数设置不合理,就会出现以下情况。

应用的启动时间超过了initialDelaySeconds+failureThreshold*periodSeconds的时间,导致探测失败后的容器重启,重启后又探测失败,进入死循环。
要解决这个问题,一种方式就是将initialDelaySeconds设置的足够大,当然更优雅的方式就是使用启动探针,如下图所示:
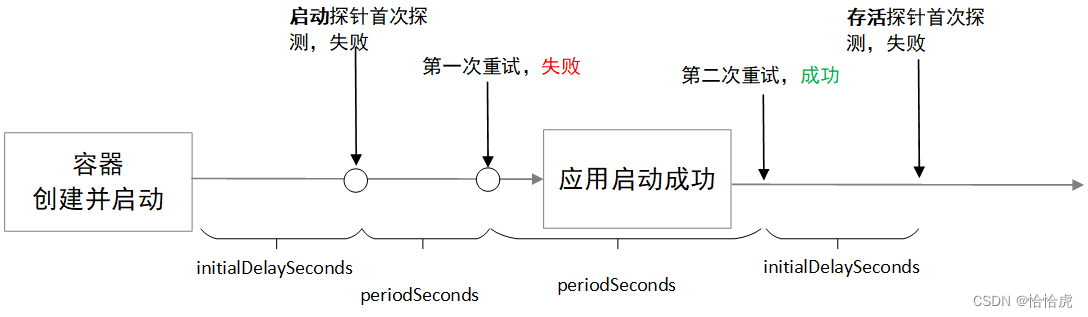
当启动探针探测成功后,存活探针和就绪探针才会接管生效,从而避免了上述问题。
我们先来演示应用启动时间过长,没有使用启动探针的场景。创建startup-exec-pod.yaml,内容如下:
[root@k8s-master yaml]# cat startup-exec-pod.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
app: startup-exec-pod
name: startup-exec-pod
spec:
containers:
- name: startup
image: busybox
args:
- /bin/sh
- -c
- sleep 60;echo ok > /tmp/healthy;sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
failureThreshold: 3
periodSeconds: 5该容器中通过指令sleep 60s,然后才创建/tmp/healthy文件,而存活探针根据是否存在该文件确认应用启动成功,其探测的最大时间initialDelaySeconds+failureThreshold*periodSeconds=5+3*5=20s,要小于60s,探测失败,容器重启,重启后,再探测失败重启,进入不断重启的死循环的状态。
我们创建pod后,跟踪一段时间看下(本例重启了6次)

下面我们修改下yaml文件,增加startupProbe
[root@k8s-master yaml]# cat startup-exec-pod.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
app: startup-exec-pod
name: startup-exec-pod
spec:
containers:
- name: startup
image: busybox
args:
- /bin/sh
- -c
- sleep 60;echo ok > /tmp/healthy;sleep 600
startupProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
failureThreshold: 30
periodSeconds: 5
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
failureThreshold: 3
periodSeconds: 5启动探测的最大探测时间:initialDelaySeconds+failureThreshold*periodSeconds=155s,大于60s,探测成功后,存活探针才生效。所以不会导致重启。我们看下:

可以看到,这次容器没有重启。
三、Pod调度
在接受到Pod的创建指令,Pod处于pending状态,接下来需要将Pod调度到Node上执行,由K8S初级入门系列之一-概述可知这个工作是由schedule模块负责的,它根据指定的一系列规则选择合适的Node进行调度,其过程大致如下:
(1)过滤,此阶段将所有满足要求的Node选择出来,形成一个节点列表,称之为可调度节点列表。如果这个列表为空,则调度失败。
(2)打分,对每个可调度节点打分,从中选择一个最合适的,即分数最高的节点,如果有多个最高分,则随机选择一个。
在这两个阶段,我们都可以设置些规则协助schedule判定,下面我们看下有哪些规则。
1、指定Node
nodeSelector是最简单的指定形式,通过指定node的标签来选择,如下图所示

下面我们来实验下,首先创建nodeselector-pod.yaml文件,其内容如下:
[root@k8s-master yaml]# cat nodeselector-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nodeselector-pod
spec:
containers:
- name: nginx
image: nginx:1.8
nodeSelector:
disk: ssd该pod需要调度到标签disk值为ssd的node上。我们来创建这个pod
[root@k8s-master yaml]# kubectl apply -f nodeselector-pod.yaml
pod/nodeselector-pod created
[root@k8s-master yaml]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nodeselector-pod 0/1 Pending 0 5s可以看到此时pod一直处于pending状态,查看下详情可知没有找到合适的pod。

因为此时我们的k8s-master,k8s-node1两个节点都没有disk=ssd的标签。
接下来,我们给k8s-node1增加标签,可以通过kubectl label node <nodename> <labelname=labelvalue>指令
[root@k8s-master yaml]# kubectl label node k8s-node1 disk=ssd
node/k8s-node1 labeled再看下pod的状态,此时已经匹配到节点,正确调度到k8s-node1上运行。
[root@k8s-master yaml]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nodeselector-pod 1/1 Running 0 8m41s 10.244.36.75 k8s-node1 <none> <none> 7m34s2、Node亲和性和反亲和性
指定Node的方式虽然简单,但是很难满足复杂的调度场景要求,此时就需要使用节点的亲和性和反亲和性配置。比如以下场景:
pod期望调度到ZoneA区域,磁盘类型优选ssd的节点,同时,又不希望调度到DB类型的节点上。最终的调度结果示意图如下:

下面我们通过实例node-affinity-pod.yaml实现调度策略的配置。
[root@k8s-master yaml]# cat node-affinity-pod.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
app: node-affinity
name: node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: zone
operator: In
values:
- ZoneA
- key: app
operator: NotIn
values:
- db
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: disk
operator: In
values:
- ssd
containers:
- name: node-affinity
image: nginx:1.8
ports:
- containerPort: 80nodeAffinity支持requiredDuringSchedulingIgnoredDuringExecution(硬亲和)以及preferredDuringSchedulingIgnoredDuringExecution(软亲和)两种模式。
requiredDuringSchedulingIgnoredDuringExecution(硬亲和),表示是必须满足的调度条件,支持多组matchExpressions,使用matchExpressions实现复杂的标签选择机制,由key,operator,values三个字段组成一个表达式,key为选择的标签名称,value表示标签的可选值列表,operator为操作符,有以下几种类型:
- In:
label的值在某个列表中 - NotIn:
label的值不在某个列表中 - Gt:
label的值大于某个值 - Lt:
label的值小于某个值 - Exists:某个
label存在 - DoesNotExist:某个
label不存在
其中NotIn,DoesNotExist可以用来表示反亲和性。
从本例看,pod需要调度到zone为ZoneA,但是不能调度到app为db的节点,所以对于前者为亲和性策略,采用In,对于后者采用反亲和性策略,采用NotIn。
preferredDuringSchedulingIgnoredDuringExecution(软亲和)是优选策略,表示在多个节点都满足硬亲和情况下,优选其中一个。由多组不同weight(权重),同样也是使用matchExpressions进行标签选择。如本例中,优选磁盘类型为ssd的节点,采用是软亲和,权重weight为1,策略为disk=ssd。
需要主要的是以下两点:
- 对于硬亲和,matchExpressions为多组时,只要一个满足即认为满足,是"or"的关系;每个matchExpressions下可以有多组选择策略,必须要同时满足才认为满足,是"and"的关系。
- 如果node的标签进行更改,对于已运行其上的pod不受影响。
3、Pod的亲和性和反亲和性
上面都是基于Node的标签属性进行判定和调度,实际上,Pod之间也存在亲疏性,比如下面的例子中,对于多有个副本的web server的pod,首先从高可用考虑,要避免多个副本调度到同一个节点上;其次,为了提升资源的利用率,需要与大数据离线处理任务的pod部署在一起;最后,避免延迟大,希望能与redis部署在一个节点上(优选策略)。如下图所示:

编写实例pod-affinity-pod.yaml来实现下
[root@k8s-master yaml]# cat pod-affinity-pod.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
app: web
name: pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- bigdata
topologyKey: kubernetes.io/hostname
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- redis
topologyKey: kubernetes.io/hostname
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- web
topologyKey: kubernetes.io/hostname
containers:
- name: node-affinity
image: nginx:1.8
ports:
- containerPort: 80其结构和属性与Node的类似,但也有以下几点差别:
(1)matchExpressions表达式中的选择的是pod的标签。
(1)pod的反亲和性可以独立设置,采用podAntiAffinity属性配置,内容和结构与podAffinity类似。
(2)增加了topologyKey字段,表示拓扑域,理论上节点,机架,区域都是拓扑范围,比如本例的kubernetes.io/hostname表示的是节点拓扑,实际上topologyKey可以是任何合法的标签建,当然我们也可以自行定义。K8S会给节点打上一些默认的标签,可以使用如下指令查看:
[root@k8s-master ~]# kubectl get node --show-labels
NAME STATUS ROLES AGE VERSION LABELS
k8s-master Ready control-plane,master 36d v1.23.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-master,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,node.kubernetes.io/exclude-from-external-load-balancers=
k8s-node1 Ready <none> 35d v1.23.0 app=db,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disk=ssd,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node1,kubernetes.io/os=linux,zone=ZoneA出于性能和安全原因,topologyKey有一些限制:
- 对于 Pod 亲和性而言,在
requiredDuringSchedulingIgnoredDuringExecution和preferredDuringSchedulingIgnoredDuringExecution中,topologyKey不允许为空。 - 对于
requiredDuringSchedulingIgnoredDuringExecution要求的 Pod 反亲和性, 准入控制器LimitPodHardAntiAffinityTopology要求topologyKey只能是kubernetes.io/hostname。如果你希望使用其他定制拓扑逻辑, 你可以更改准入控制器或者禁用之。
4、污点与容忍度
亲和性表示是相吸性,即pod被吸引到同一类的节点上,而污点(traint)恰好相反,它使得pod排斥某一类型的节点,如果想要不排斥,就需要配置这个污点的容忍度(Toleration)。污点和容忍度相互配合使用。
我们先来看下示例,首先在k8s-node1节点上加个污点
[root@k8s-master ~]# kubectl taint nodes k8s-node1 key1=value1:NoSchedule
node/k8s-node1 tainted其中key1是污点的键名,键值是value1,效果是NoSchedule,即对该污点没有容忍度的pod无法调度到该节点。
创建pod,其yaml文件如下,暂不配置容忍度看下结果。
[root@k8s-master yaml]# cat taint-pod.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
app: web
name: taint-pod
spec:
containers:
- name: taint-pod
image: nginx:1.8
ports:
- containerPort: 80执行创建命令,并看下状态
[root@k8s-master yaml]# kubectl get pod
NAME READY STATUS RESTARTS AGE
taint-pod 0/1 Pending 0 41m该pod一直pending状态,再查看该pod的详情
![]()
可以看到,目前的两个node(k8s-master,k8s-node1)都存在污点,而该pod没有容忍度,所以无法调度成功。我们再来修改下yaml文件,配置上述污点的容忍度。
[root@k8s-master yaml]# cat taint-pod.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
app: web
name: taint-pod
spec:
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
containers:
- name: taint-pod
image: nginx:1.8
ports:
- containerPort: 80这样,该pod对于键名为key1,键值为value1,效果为NoSchedule的污点存在容忍度,也就是可以调度具有该污点的节点(k8s-node1)上。接下来,我们重新创建该pod,查看下运行状态
[root@k8s-master yaml]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
taint-pod 1/1 Running 0 4m3s 10.244.36.76 k8s-node1 <none> <none>结果也如图所示,正确调度到k8s-node1上运行。
综上所述,当一个节点配置了污点,所有的pod都无法调度到该节点,除非该pod配置了该污点的容忍度,相当于配置了一些白名单pod。那么污点和容忍度有哪些使用场景呢?
(1)专用的节点,这些节点专门给一些特点的应用使用。
(2)具有特殊硬件设备的节点,比如金融领域的加解密都是通过物理加密卡,对于带有类加密卡的节点,是不希望运行其他的应用的。
(3)Pod驱逐行为,节点出现问题时,就会自动增加相应类型的污点,从而驱逐其上运行的但没有配置相应容忍度的pod。比如网络不可用,节点自动增加node.kubernetes.io/network-unavailable污点。
不过要达到对其上pod达到驱逐目的,其效果值不能是NoSchedule,而应该是NoExecute。NoSchedule仅对于还未调度的pod有效,而对于前期已经调度到节点的Pod,不会产生驱逐效果。NoExecute对于没有配置其污点容忍度的所有运行pod立即驱逐,当前也可以通过配置tolerationSeconds时间,来延迟驱逐的时间。
事实上,K8S会给一些特点节点加上污点标识,比如我们实验环境的master节点k8s-master。
[root@k8s-master ~]# kubectl describe node k8s-master
....
Taints: node-role.kubernetes.io/master:NoSchedule
....一般情况下,pod不允许调度到master节点,除非能容忍这个污点。比如将上面例子中的pod调度到master节点,我们修改下容忍度配置。
[root@k8s-master yaml]# cat taint-pod.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
app: web
name: taint-pod
spec:
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: taint-pod
image: nginx:1.8
ports:
- containerPort: 80执行下该文件,创建pod,看下运行的节点
[root@k8s-master yaml]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP
taint-pod 1/1 Running 0 77s 10.244.235.196 k8s-master <none> <none>可以看到,确实调度到k8s-master节点上了。
当然,我们也可以通过指令把主节点上的污点给删了,kubectl taint node <nodename> <key>-
比如:
[root@k8s-master yaml]# kubectl taint node k8s-master node-role.kubernetes.io/master-四、总结
本章节的内容较多,我们来总结下:
1、Pod的生命周期包括挂起(Pending),容器创建(ContainerCreating),运行(Running),失败(Failed),成功(Succeed),未知(Unknown)几种状态,在容器创建后以及销毁前,可以使用postStart,preStop两个钩子使用诸如环境准备,优雅停机等工作。
2、容器的重启策略有三种类型,Always,OnFailure和Never。对于Always,无论异常还是正常退出,Pod都会重启;对于OnFailure时,仅异常退出时,Pod才会重启;对于Never时,无论异常还是正常退出,Pod都不会重启。
3、探针类型包括LivenessProbe(存活探针),ReadinessProbe(就绪探针),StartupProbe(启动探针),存活探针主要探测业务是否异常,就绪探针主要探测业务是否就绪,能对外提供服务,启动探针主要探测业务是否启动。
4、Pod调度的策略,包括指定node,node亲和性和反亲和性,pod的亲和性和反亲和性,污点与容忍度。
附:
K8S初级入门系列之一-概述
K8S初级入门系列之二-集群搭建
K8S初级入门系列之三-Pod的基本概念和操作
K8S初级入门系列之四-Namespace/ConfigMap/Secret
K8S初级入门系列之五-Pod的高级特性
K8S初级入门系列之六-控制器(RC/RS/Deployment)
K8S初级入门系列之七-控制器(Job/CronJob/Daemonset)
K8S初级入门系列之八-网络
K8S初级入门系列之九-共享存储
K8S初级入门系列之十-控制器(StatefulSet)
K8S初级入门系列之十一-安全
K8S初级入门系列之十二-计算资源管理