Linux消息中间件-RabbitMQ
消息中间件
MQ简介
MQ 全称为Message Queue, 消息队列。是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信。队列的使用除去了接收和发送应用程序同时执行的要求。
在项目中,将一些无需即时返回且耗时的操作提取出来,进行了异步处理,而这种异步处理的方式大大的节省了服务器的请求响应时间,从而提高了系统的吞吐量。
核心功能
1、解耦(将不同的系统分离开)
2、冗余(存储)
3、扩展性
4、削峰
5、可恢复性
6、顺序保证
7、缓冲
8、异步通信
工作模式
P2P模式
P2P模式包含三个角色:消息队列(Queue)、发送者(Sender)、接收者(Receiver)。每个消息都被发送到一个特定的队列,接收者从队列中获取消息。队列保留着消息,直到它们被消费或超时。P2P的特点如下:
• 每个消息只有一个消费者(Consumer),即一旦被消费,消息就不再在消息队列中
• 发送者和接收者之间在时间上没有依赖性,也就是说当发送者发送了消息之后,不管接收者有没有正在运行它不会影响到消息被发送到队列
• 接收者在成功接收消息之后需向队列应答成功
• 如果希望发送的每个消息都会被成功处理的话,那么需要P2P模式
Pub/Sub模式
Pub/Sub模式包含三个角色:主题(Topic)、发布者(Publisher)、订阅者(Subscriber) 。多个发布者将消息发送到Topic,系统将这些消息传递给多个订阅者。Pub/Sub的特点如下:
• 每个消息可以有多个消费者
• 发布者和订阅者之间有时间上的依赖性。针对某个主题(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息
• 为了消费消息,订阅者必须保持运行的状态
• 如果希望发送的消息可以不被做任何处理、或者只被一个消息者处理、或者可以被多个消费者处理的话,那么可以采用Pub/Sub模型
同类产品
1、Kafka
Kafka是LinkedIn开源的分布式发布-订阅消息系统,目前归属于Apache顶级项目。Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输。0.8版本开始支持复制,不支持事务,对消息的重复、丢失、错误没有严格要求,适合产生大量数据的互联网服务的数据收集业务。一般应用在大数据日志处理或对实时性(少量延迟),可靠性(少量丢数据)要求稍低的场景使用,比如ELK日志收集。
2、RabbitMQ
RabbitMQ是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。AMQP协议更多用在企业系统内对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次。RabbitMQ比Kafka可靠
3、RocketMQ
RocketMQ是阿里开源的消息中间件,它是纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点。RocketMQ思路起源于Kafka,但并不是Kafka的一个Copy,它对消息的可靠传输及事务性做了优化,目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景。
RabbitMQ详解
RabbitMQ简介
1、RabbitMQ是一个在AMQP(Advanced Message Queuing Protocol )基础上实现的,可复用的企业消息系统。它可以用于大型软件系统各个模块之间的高效通信,支持高并发,支持可扩展。它支持多种客户端如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP等,支持AJAX,持久化,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。
2、RabbitMQ是使用Erlang编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正是如此,使的它变的非常重量级,更适合于企业级的开发。它同时实现了一个Broker构架,这意味着消息在发送给客户端时先在中心队列排队,对路由(Routing)、负载均衡(Load balance)或者数据持久化都有很好的支持。
RabbitMQ特点
1、可靠性
2、灵活的路由
3、扩展性
4、高可用性
5、多种协议
6、多语言客户端
7、管理界面
8、插件机制
AMQP介绍
AMQP,即Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同的开发语言等条件的限制。
RabbitMQ应用场景
对于一个大型的软件系统来说,它会有很多的组件或者说模块或者说子系统(subsystem or Component or submodule)。那么这些模块的如何通信?这和传统的IPC有很大的区别。传统的IPC很多都是在单一系统上的,模块耦合性很大,不适合扩展(Scalability);如果使用socket那么不同的模块的确可以部署到不同的机器上,但是还是有很多问题需要解决。比如:
1)信息的发送者和接收者如何维持这个连接,如果一方的连接中断,这期间的数据会不会丢失?
2)如何降低发送者和接收者的耦合度?
3)如何让Priority高的接收者先接到数据?
4)如何做到load balance?有效均衡接收者的负载?
5)如何有效的将数据发送到相关的接收者?也就是说将接收者subscribe 不同的数据,如何做有效的filter。
6)如何做到可扩展,甚至将这个通信模块发到cluster上?
7)如何保证接收者接收到了完整,正确的数据? AMDQ协议解决了以上的问题,而RabbitMQ实现了AMQP。
RabbitMQ常用术语
Broker:简单来说就是消息队列服务器实体。
Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
Queue:消息队列载体,每个消息都会被投入到一个或多个队列。
Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。
Routing Key:路由关键字,exchange根据这个关键字进行消息投递。
vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。
producer:消息生产者,就是投递消息的程序。
consumer:消息消费者,就是接受消息的程序。
channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
RabbitMQ图示
RabbitMQ从整体上来看是一个典型的生产者消费者模型,主要负责接收、存储和转发消息
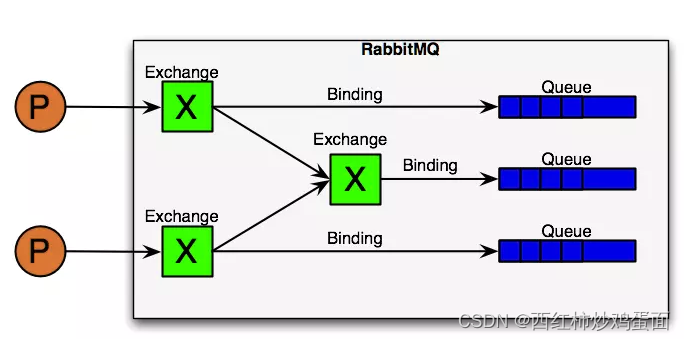
RabbitMQ使用流程
AMQP模型中,消息在producer中产生,发送到MQ的exchange上,exchange根据配置的路由方式发到相应的Queue上,Queue又将消息发送给consumer,消息从queue到consumer有push和pull两种方式。 消息队列的使用过程大概如下:
- 客户端连接到消息队列服务器,打开一个channel。
- 客户端声明一个exchange,并设置相关属性。
- 客户端声明一个queue,并设置相关属性。
- 客户端使用routing key,在exchange和queue之间建立好绑定关系。
- 客户端投递消息到exchange。
exchange接收到消息后,就根据消息的key和已经设置的binding,进行消息路由,将消息投递到一个或多个队列里。 exchange也有几个类型,完全根据key进行投递的叫做Direct交换机,例如,绑定时设置了routing key为”abc”,那么客户端提交的消息,只有设置了key为”abc”的才会投递到队列。
单机部署RabbitMQ
Linux部署RabbitMQ
1、环境
192.168.101.11 设置主机名和域名解析 rabbitmq1
192.168.101.12 设置主机名和域名解析 rabbitmq2
192.168.101.13 设置主机名和域名解析 rabbitmq3
2、安装Erlang
这里使用yum源进行安装。也可使用rpm包进行安装
yum -y install erlang
3、安装RabbitMQ
yum -y install rabbitmq-server-3.7.13-1.el7.noarch.rpm
4、修改配置文件
cp /usr/share/doc/rabbitmq-server-3.7.13/rabbitmq.config.example /etc/rabbitmq/rabbitmq.config
vim /etc/rabbitmq/rabbitmq.config
//打开配置文件,61行 去掉注释%%和逗号
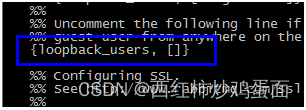
5、安装插件并启动服务
web管理界面工具
rabbitmq-plugins enable rabbitmq_management
systemctl restart rabbitmq-server
查看节点状态。(下图是node1节点)
[root@rabbitmq1 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbitmq1 ...
[{nodes,[{disc,[rabbit@rabbitmq1]}]},
{running_nodes,[rabbit@rabbitmq1]},
{cluster_name,<<"rabbit@rabbitmq1">>},
{partitions,[]},
{alarms,[{rabbit@rabbitmq1,[]}]}]
6访问测试
http://127.0.0.1:15672
默认账号密码:guest/guest
单机部署到此完成
RabbitMQ集群部署
1、简介
消息中间件RabbitMQ,一般以集群方式部署,主要提供消息的接受和发送,实现各微服务之间的消息异步。以下将介绍RabbitMQ+HA方式进行部署。
2、原理介绍
(1)RabbitMQ底层是通过Erlang架构来实现的,所以rabbitmqctl会启动Erlang节点,并基于Erlang节点来使用Erlang系统连接RabbitMQ节点,在连接过程中需要正确的Erlang Cookie和节点名称,Erlang节点通过交换Erlang Cookie以获得认证来实现分布式,所以部署Rabbitmq分布式集群时要先安装Erlang,并把其中一个服务的cookie复制到另外的节点。
(2)RabbitMQ集群中,各个RabbitMQ为对等节点,即每个节点均提供给客户端连接,进行消息的接收和发送。节点分为内存节点和磁盘节点,一般都建立为磁盘节点,为了防止机器重启后的消息消失;
(3)RabbitMQ的Cluster集群模式一般分为两种,普通模式和镜像模式。消息队列通过RabbitMQ HA镜像队列进行消息队列实体复制。
(4) 普通模式下,以两个节点(rabbit01、rabbit02)为例来进行说明。对于Queue来说,消息实体只存在于其中一个节点rabbit01(或者rabbit02),rabbit01和rabbit02两个节点仅有相同的元数据,即队列的结构。当消息进入rabbit01节点的Queue后,consumer从rabbit02节点消费时,RabbitMQ会临时在rabbit01、rabbit02间进行消息传输,把A中的消息实体取出并经过B发送给consumer。所以consumer应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列,要在多个节点建立物理Queue。否则无论consumer连rabbit01或rabbit02,出口总在rabbit01,会产生瓶颈。
双方存储元数据,消费时会出现瓶颈
(5) 镜像模式下,将需要消费的队列变为镜像队列,存在于多个节点,这样就可以实现RabbitMQ的HA高可用性。作用就是消息实体会主动在镜像节点之间实现同步,而不是像普通模式那样,在consumer消费数据时临时读取。缺点就是,集群内部的同步通讯会占用大量的网络带宽。
3、环境要求
(1)所有节点需要再同一个局域网内;
(2)所有节点需要有相同的 erlang cookie,否则不能正常通信,为了实现cookie内容一致,采用scp的方式进行。
(3)准备三台虚拟机,配置相同
192.168.101.11 设置主机名 rabbitmq1
192.168.101.12 设置主机名 rabbitmq2
192.168.101.13 设置主机名 rabbitmq3
操作系统:centos7.2以上
(4)集群中所有节点都需要hosts文件解析
[root@rabbitmq1 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.135.184 rabbitmq1
192.168.135.185 rabbitmq2
192.168.135.192 rabbitmq3
4、部署过程(每个节点都配置)
(1)一定要保证三台机器的cookie内容一致
找到erlang cookie文件的位置,源码包部署一般会存在~/.erlang.cookie;rpm包部署一般是在/var/lib/rabbitmq/.erlang.cookie。将 node1 的该文件使用rsync或者是scp复制到 node2、node3,文件权限需要是400。
scp -r /var/lib/rabbitmq/.erlang.cookie rabbitmq2:/var/lib/rabbitmq/.erlang.cookie
scp -r /var/lib/rabbitmq/.erlang.cookie rabbitmq3:/var/lib/rabbitmq/.erlang.cookie
cat /var/lib/rabbitmq/.erlang.cookie
(2)rabbitmqctl stop
关闭rabbitmq2和rabbitmq3的服务(不要关rabbitmq1)
如果2,3节点没有启动服务,会提示关闭错误。
(3)rabbitmq-server -detached
独立运行节点,warning提示不用理会
Warning: PID file not written; -detached was passed.
(4)rabbitmqctl cluster_status
查看各个节点状态。(下图是node1节点)
[root@rabbitmq1 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbitmq1 ...
[{nodes,[{disc,[rabbit@rabbitmq1]}]},
{running_nodes,[rabbit@rabbitmq1]},
{cluster_name,<<"rabbit@rabbitmq1">>},
{partitions,[]},
{alarms,[{rabbit@rabbitmq1,[]}]}]
每台主机看到的只有一个的server信息。
5、添加用户并设置密码
由于guest这个用户,只能在本地访问,所以我们要,在每个节点上,新增一个用户并赋予对/的所有权限,然后添加到管理员组中,让此用户能够远程访问
rabbitmqctl add_user admin admin
rabbitmqctl set_permissions -p "/" admin ".*" ".*" ".*"
rabbitmqctl set_user_tags admin administrator
6、访问测试
http://ip:15672
账号:admin
密码admin
此时每个节点是单独的一台RabbitMQ,下面来将他们组成集群。
组成集群
简介
rabbitmq-server 启动时,会一起启动——节点和应用,它预先设置RabbitMQ应用为standalone(脱机)模式。要将一个节点加入到现有的集群中,你需要停止这个应用,并将节点设置为原始状态。如果使用rabbitmqctl stop,应用和节点都将被关闭。所以使用rabbitmqctl stop_app仅仅关闭应用。(停应用,不停止节点)
1、将node2、node3加入到node1中组成集群
(1)磁盘节点
第二台节点
rabbitmqctl stop_app #仅停止应用,不关闭节点(注意是节点2)
rabbitmqctl join_cluster rabbit@rabbitmq1 #集群名字一定不要写错(查看rabbitmq1 的节点状态)
node2# rabbitmqctl start_app
如果此时查看节点1,会发现集群节点信息增加
[root@rabbitmq1 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbitmq1 ...
[{nodes,[{disc,[rabbit@rabbitmq1,rabbit@rabbitmq2]}]},
{running_nodes,[rabbit@rabbitmq2,rabbit@rabbitmq1]},
{cluster_name,<<"rabbit@rabbitmq1">>},
{partitions,[]},
{alarms,[{rabbit@rabbitmq2,[]},{rabbit@rabbitmq1,[]}]}]
第三台节点
rabbitmqctl stop_app
rabbitmqctl join_cluster rabbit@rabbitmq1 ##集群名字一定不要写错
rabbitmqctl start_app
如果此时查看节点1,会发现集群节点信息增加
[root@rabbitmq1 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbitmq1 ...
[{nodes,[{disc,[rabbit@rabbitmq1,rabbit@rabbitmq2,rabbit@rabbitmq3]}]},
{running_nodes,[rabbit@rabbitmq3,rabbit@rabbitmq2,rabbit@rabbitmq1]},
{cluster_name,<<"rabbit@rabbitmq1">>},
{partitions,[]},
{alarms,[{rabbit@rabbitmq3,[]},{rabbit@rabbitmq2,[]},{rabbit@rabbitmq1,[]}]}]
2、在任意节点上查看集群状态
node3# rabbitmqctl cluster_status
Cluster status of node rabbit@node3 ...
[{nodes,[{disc,[rabbit@node1,rabbit@node2,rabbit@node3]}]},
{running_nodes,[rabbit@node1,rabbit@node2,rabbit@node3]},
{cluster_name,<"rabbit@node1">}, #集群的名称默认为 rabbit@node1
{partitions,[]},
{alarms,[{rabbit@node1,[]},{rabbit@node2,[]},{rabbit@node3,[]}]}]
3、在任意节点上设置镜像队列策略
在web界面登陆,点击“Admin–Virtual Hosts(页面右侧)”,在打开的页面上的下方的“Add a new virtual host”处增加一个虚拟主机,同时给用户“admin”和“guest”均加上权限(在页面直接设置、点点点即可);
linux中设置镜像队列策略:
语法介绍
rabbitmqctl set_policy -p coresystem ha-all "^" '{"ha-mode":"all"}'
案例中的命令
rabbitmqctl set_policy -p ceshi ha-all "^" '{"ha-mode":"all"}'
注释:
"coresystem"
vhost名称,此处应该填写“ceshi”
ha-all
策略名称
"^"
queue的匹配模式为匹配所有的队列
{ }
为镜像定义,包括三个部分ha-mode, ha-params, ha-sync-mode
ha-mode
指明镜像队列的模式,有效值为 all/exactly/nodes
all---------表示在集群中所有的节点上进行镜像,包含新增节点
exactly-------(可选)表示在指定个数的节点上进行镜像,节点的个数由ha-params指定
nodes--------(可选)表示在指定的节点上进行镜像,节点名称通过ha-params指定
ha-sync-mode
(可选)进行队列中消息的同步方式,有效值为automatic和manual
此时镜像队列设置成功。队列会被复制到各个节点,各个节点状态保持一致(这里的虚拟主机coresystem是代码中需要用到的虚拟主机,虚拟主机的作用是做一个消息的隔离,本质上可认为是一个rabbitmq-server,是否增加虚拟主机,增加几个,这是由开发中的业务决定,即有哪几类服务,哪些服务用哪一个虚拟主机,这是一个规划)。
Rabbitmq+HAproxy
1、在独立服务器上安装HAProxy
yum -y install haproxy
2、修改配置文件
vim /etc/haproxy/haproxy.cfg
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
defaults
log global
mode tcp
option tcplog
option dontlognull
retries 3
option redispatch
maxconn 2000
contimeout 5s
clitimeout 120s
srvtimeout 120s
listen rabbitmq_cluster 0.0.0.0:80#作为代理的服务器的IP和端口
mode tcp
balance roundrobin
server rabbit1 192.168.101.11:15672 check inter 5000 rise 2 fall 2
server rabbit2 192.168.101.12:15672 check inter 5000 rise 2 fall 2
server rabbit3 192.168.101.13:15672 check inter 2000 rise 2 fall 3
listen monitor
bind 0.0.0.0:8100#监控页面的访问端口
mode http
option httplog
stats enable
stats uri /rabbitmqstats
stats refresh 30s
stats auth admin:admin
3、重启HAProxy
systemctl restart haproxy
4、登录浏览器输入地址
http://192.168.0.113/:8100/rabbitmqstats
查看HAProxy的状态
http://192.168.0.113:80/
高可用使用rabbitmq。







![[附源码]Python计算机毕业设计SSM基于技术的高校学生勤工俭学管理系统的设计与开发(程序+LW)](https://img-blog.csdnimg.cn/6e24bfa958054206a2b7354ca2845d57.png)