这一篇是一个比较宽泛的训练框架讲解与说明。会大致说一些模型训练过程中需要的一些模块,datasets、backbone、neck、head、loss等。会先将框架结构,再讲核心机制。
目录
1.框架结构
1.1 configs
1.1.1 训练配置
1.1.2 datasets
1.1.3 models
1.1.4 schedules
1.1.5 自定义
1.2 mmdet
1.2.1 apis
1.2.2 datasets
1.2.3 models
1.2.4 core
1.3 tools
1.3.1 训练脚本
1.3.2 数据转换
1.3.3 其他
1.4 doc
1.5 mmdetection官方指导文件
2.核心机制
2.1 注册机制
2.2 类名调用类实例化
2.3 源代码解析
1.框架结构
主要说明这个几个结构(coonfigs、mmdet、tools,doc):

1.1 configs
这里面会放所有的配置文件,包括dataset的训练集、测试集等使用哪个数据集、已经需要经过哪些tranform操作才能走到backbone、head、loss进行优化等。也包括模型网络的配置,其中网络部分包含backbone、neck、head、loss。

包含_base_,这个相当于这里面有一些自带的数据集、模型、训练策略(优化器optimizer、lr等)。也包含后面的哪些自定义的直接可以训练的配置。
1.1.1 训练配置
以deepfashion/mask_rcnn_r50_fpn_15e_deepfashion.py为例:mmdetection/mask_rcnn_r50_fpn_15e_deepfashion.py at master · open-mmlab/mmdetection · GitHub
_base_ = [
'../_base_/models/mask_rcnn_r50_fpn.py',
'../_base_/datasets/deepfashion.py', '../_base_/schedules/schedule_1x.py',
'../_base_/default_runtime.py'
]
model = dict(
roi_head=dict(
bbox_head=dict(num_classes=15), mask_head=dict(num_classes=15)))
# runtime settings
runner = dict(type='EpochBasedRunner', max_epochs=15)_base_ 里面是基础配置,如果在deepfashion/mask_rcnn_r50_fpn_15e_deepfashion.py配置文件中有的会优先这个对应的参数,没有的参数会从_base_中取。
1.1.2 datasets
datasets:mmdetection/deepfashion.py at master · open-mmlab/mmdetection · GitHub
其中train.py会调用data, 通过type调用对应的DeepFashionDataset类,然后通过train_pipeline读取其中的image与annotations,并进行resize数据增强等。
# dataset settings
dataset_type = 'DeepFashionDataset'
data_root = 'data/DeepFashion/In-shop/'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
dict(type='Resize', img_scale=(750, 1101), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(750, 1101),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
imgs_per_gpu=2,
workers_per_gpu=1,
train=dict(
type=dataset_type,
ann_file=data_root + 'annotations/DeepFashion_segmentation_query.json',
img_prefix=data_root + 'Img/',
pipeline=train_pipeline,
data_root=data_root),
val=dict(
type=dataset_type,
ann_file=data_root + 'annotations/DeepFashion_segmentation_query.json',
img_prefix=data_root + 'Img/',
pipeline=test_pipeline,
data_root=data_root),
test=dict(
type=dataset_type,
ann_file=data_root +
'annotations/DeepFashion_segmentation_gallery.json',
img_prefix=data_root + 'Img/',
pipeline=test_pipeline,
data_root=data_root))
evaluation = dict(interval=5, metric=['bbox', 'segm'])1.1.3 models
models:https://github.com/open-mmlab/mmdetection/blob/master/configs/_base_/models/mask_rcnn_r50_fpn.py
包含backbone、neck、head,以及head中通过loss_*配置相应的loss损失函数。
# model settings
model = dict(
type='MaskRCNN',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5),
rpn_head=dict(
type='RPNHead',
in_channels=256,
feat_channels=256,
anchor_generator=dict(
type='AnchorGenerator',
scales=[8],
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[.0, .0, .0, .0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
roi_head=dict(
type='StandardRoIHead',
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
bbox_head=dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=80,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=False,
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
mask_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=14, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
mask_head=dict(
type='FCNMaskHead',
num_convs=4,
in_channels=256,
conv_out_channels=256,
num_classes=80,
loss_mask=dict(
type='CrossEntropyLoss', use_mask=True, loss_weight=1.0))),
# model training and testing settings
train_cfg=dict(
rpn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.7,
neg_iou_thr=0.3,
min_pos_iou=0.3,
match_low_quality=True,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=256,
pos_fraction=0.5,
neg_pos_ub=-1,
add_gt_as_proposals=False),
allowed_border=-1,
pos_weight=-1,
debug=False),
rpn_proposal=dict(
nms_pre=2000,
max_per_img=1000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.5,
match_low_quality=True,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
mask_size=28,
pos_weight=-1,
debug=False)),
test_cfg=dict(
rpn=dict(
nms_pre=1000,
max_per_img=1000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.5),
max_per_img=100,
mask_thr_binary=0.5)))1.1.4 schedules
schedules:https://github.com/open-mmlab/mmdetection/blob/master/configs/_base_/schedules/schedule_1x.py
包含训练的一些配置:优化器、学习率配置、以及训练的模式epoch等。
# optimizer
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None)
# learning policy
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.001,
step=[8, 11])
runner = dict(type='EpochBasedRunner', max_epochs=12)1.1.5 自定义
所有的这些配置都可以自己写,写到configs目录下。
其中可以参考:教程 1: 学习配置文件 — MMDetection3D 1.0.0rc4 文档
1.2 mmdet
这里面是一些核心代码,每部分会大致讲下。

1.2.1 apis
主要train、test、inference的核心代码的实现,比如说train_detector,读取配置、训练的这些在tools中。

1.2.2 datasets
主要包含一些datasets类的实现,以及调用train_pipelines,test_pipelines里面的一些实现。其中datasets类的话,就是通过名称搜索到对应的类实现,以及pipelines中几个重要文件的实现,formating、formatting、loading。比如其中的loading中LoadImageFromFile类。具体会另外一篇博客里面讲解。

1.2.3 models
这里面主要是配置文件中那些models网络结构类的实现。其中关注builder.py文件,注册都在这里。
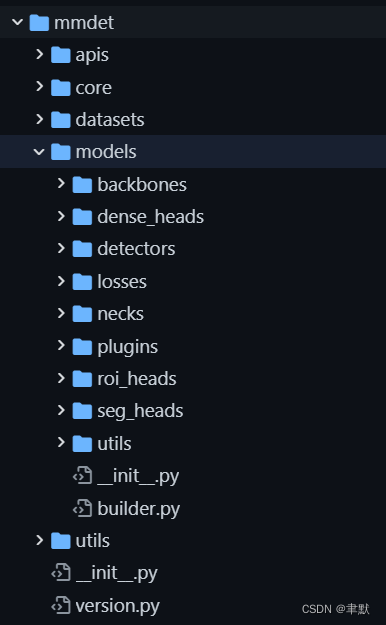
mmdetection/builder.py at master · open-mmlab/mmdetection · GitHub其中关注builder.py文件,注册都在这里,希望外部能够调用的话,写在__init__.py中。mmdetection/builder.py at master · open-mmlab/mmdetection · GitHub
# https://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/builder.py
# Copyright (c) OpenMMLab. All rights reserved.
import copy
import platform
import random
import warnings
from functools import partial
import numpy as np
import torch
from mmcv.parallel import collate
from mmcv.runner import get_dist_info
from mmcv.utils import TORCH_VERSION, Registry, build_from_cfg, digit_version
from torch.utils.data import DataLoader
from .samplers import (ClassAwareSampler, DistributedGroupSampler,
DistributedSampler, GroupSampler, InfiniteBatchSampler,
InfiniteGroupBatchSampler)
if platform.system() != 'Windows':
# https://github.com/pytorch/pytorch/issues/973
import resource
rlimit = resource.getrlimit(resource.RLIMIT_NOFILE)
base_soft_limit = rlimit[0]
hard_limit = rlimit[1]
soft_limit = min(max(4096, base_soft_limit), hard_limit)
resource.setrlimit(resource.RLIMIT_NOFILE, (soft_limit, hard_limit))
DATASETS = Registry('dataset')
PIPELINES = Registry('pipeline')
def _concat_dataset(cfg, default_args=None):
from .dataset_wrappers import ConcatDataset
ann_files = cfg['ann_file']
img_prefixes = cfg.get('img_prefix', None)
seg_prefixes = cfg.get('seg_prefix', None)
proposal_files = cfg.get('proposal_file', None)
separate_eval = cfg.get('separate_eval', True)
datasets = []
num_dset = len(ann_files)
for i in range(num_dset):
data_cfg = copy.deepcopy(cfg)
# pop 'separate_eval' since it is not a valid key for common datasets.
if 'separate_eval' in data_cfg:
data_cfg.pop('separate_eval')
data_cfg['ann_file'] = ann_files[i]
if isinstance(img_prefixes, (list, tuple)):
data_cfg['img_prefix'] = img_prefixes[i]
if isinstance(seg_prefixes, (list, tuple)):
data_cfg['seg_prefix'] = seg_prefixes[i]
if isinstance(proposal_files, (list, tuple)):
data_cfg['proposal_file'] = proposal_files[i]
datasets.append(build_dataset(data_cfg, default_args))
return ConcatDataset(datasets, separate_eval)
def build_dataset(cfg, default_args=None):
from .dataset_wrappers import (ClassBalancedDataset, ConcatDataset,
MultiImageMixDataset, RepeatDataset)
if isinstance(cfg, (list, tuple)):
dataset = ConcatDataset([build_dataset(c, default_args) for c in cfg])
elif cfg['type'] == 'ConcatDataset':
dataset = ConcatDataset(
[build_dataset(c, default_args) for c in cfg['datasets']],
cfg.get('separate_eval', True))
elif cfg['type'] == 'RepeatDataset':
dataset = RepeatDataset(
build_dataset(cfg['dataset'], default_args), cfg['times'])
elif cfg['type'] == 'ClassBalancedDataset':
dataset = ClassBalancedDataset(
build_dataset(cfg['dataset'], default_args), cfg['oversample_thr'])
elif cfg['type'] == 'MultiImageMixDataset':
cp_cfg = copy.deepcopy(cfg)
cp_cfg['dataset'] = build_dataset(cp_cfg['dataset'])
cp_cfg.pop('type')
dataset = MultiImageMixDataset(**cp_cfg)
elif isinstance(cfg.get('ann_file'), (list, tuple)):
dataset = _concat_dataset(cfg, default_args)
else:
dataset = build_from_cfg(cfg, DATASETS, default_args)
return dataset
def build_dataloader(dataset,
samples_per_gpu,
workers_per_gpu,
num_gpus=1,
dist=True,
shuffle=True,
seed=None,
runner_type='EpochBasedRunner',
persistent_workers=False,
class_aware_sampler=None,
**kwargs):
"""Build PyTorch DataLoader.
In distributed training, each GPU/process has a dataloader.
In non-distributed training, there is only one dataloader for all GPUs.
Args:
dataset (Dataset): A PyTorch dataset.
samples_per_gpu (int): Number of training samples on each GPU, i.e.,
batch size of each GPU.
workers_per_gpu (int): How many subprocesses to use for data loading
for each GPU.
num_gpus (int): Number of GPUs. Only used in non-distributed training.
dist (bool): Distributed training/test or not. Default: True.
shuffle (bool): Whether to shuffle the data at every epoch.
Default: True.
seed (int, Optional): Seed to be used. Default: None.
runner_type (str): Type of runner. Default: `EpochBasedRunner`
persistent_workers (bool): If True, the data loader will not shutdown
the worker processes after a dataset has been consumed once.
This allows to maintain the workers `Dataset` instances alive.
This argument is only valid when PyTorch>=1.7.0. Default: False.
class_aware_sampler (dict): Whether to use `ClassAwareSampler`
during training. Default: None.
kwargs: any keyword argument to be used to initialize DataLoader
Returns:
DataLoader: A PyTorch dataloader.
"""
rank, world_size = get_dist_info()
if dist:
# When model is :obj:`DistributedDataParallel`,
# `batch_size` of :obj:`dataloader` is the
# number of training samples on each GPU.
batch_size = samples_per_gpu
num_workers = workers_per_gpu
else:
# When model is obj:`DataParallel`
# the batch size is samples on all the GPUS
batch_size = num_gpus * samples_per_gpu
num_workers = num_gpus * workers_per_gpu
if runner_type == 'IterBasedRunner':
# this is a batch sampler, which can yield
# a mini-batch indices each time.
# it can be used in both `DataParallel` and
# `DistributedDataParallel`
if shuffle:
batch_sampler = InfiniteGroupBatchSampler(
dataset, batch_size, world_size, rank, seed=seed)
else:
batch_sampler = InfiniteBatchSampler(
dataset,
batch_size,
world_size,
rank,
seed=seed,
shuffle=False)
batch_size = 1
sampler = None
else:
if class_aware_sampler is not None:
# ClassAwareSampler can be used in both distributed and
# non-distributed training.
num_sample_class = class_aware_sampler.get('num_sample_class', 1)
sampler = ClassAwareSampler(
dataset,
samples_per_gpu,
world_size,
rank,
seed=seed,
num_sample_class=num_sample_class)
elif dist:
# DistributedGroupSampler will definitely shuffle the data to
# satisfy that images on each GPU are in the same group
if shuffle:
sampler = DistributedGroupSampler(
dataset, samples_per_gpu, world_size, rank, seed=seed)
else:
sampler = DistributedSampler(
dataset, world_size, rank, shuffle=False, seed=seed)
else:
sampler = GroupSampler(dataset,
samples_per_gpu) if shuffle else None
batch_sampler = None
init_fn = partial(
worker_init_fn, num_workers=num_workers, rank=rank,
seed=seed) if seed is not None else None
if (TORCH_VERSION != 'parrots'
and digit_version(TORCH_VERSION) >= digit_version('1.7.0')):
kwargs['persistent_workers'] = persistent_workers
elif persistent_workers is True:
warnings.warn('persistent_workers is invalid because your pytorch '
'version is lower than 1.7.0')
data_loader = DataLoader(
dataset,
batch_size=batch_size,
sampler=sampler,
num_workers=num_workers,
batch_sampler=batch_sampler,
collate_fn=partial(collate, samples_per_gpu=samples_per_gpu),
pin_memory=kwargs.pop('pin_memory', False),
worker_init_fn=init_fn,
**kwargs)
return data_loader
def worker_init_fn(worker_id, num_workers, rank, seed):
# The seed of each worker equals to
# num_worker * rank + worker_id + user_seed
worker_seed = num_workers * rank + worker_id + seed
np.random.seed(worker_seed)
random.seed(worker_seed)
torch.manual_seed(worker_seed)1.2.4 core
除了上面之外的应该其他部分基本都在core中实现了。

1.3 tools
这里包含几个重要的部分,一个是训练测试脚本、一个数据转换脚本、另外一个是模型转换脚本。

1.3.1 训练脚本
通过调用配置文件,基本就可以直接训练了。
python tools/train.py ${CONFIG_FILE}
# eg :
python tools/train.py configs/balloon/mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_balloon.py
mmdetection/train.py at master · open-mmlab/mmdetection · GitHub
# Copyright (c) OpenMMLab. All rights reserved.
import argparse
import copy
import os
import os.path as osp
import time
import warnings
import mmcv
import torch
import torch.distributed as dist
from mmcv import Config, DictAction
from mmcv.runner import get_dist_info, init_dist
from mmcv.utils import get_git_hash
from mmdet import __version__
from mmdet.apis import init_random_seed, set_random_seed, train_detector
from mmdet.datasets import build_dataset
from mmdet.models import build_detector
from mmdet.utils import (collect_env, get_device, get_root_logger,
replace_cfg_vals, setup_multi_processes,
update_data_root)
def parse_args():
parser = argparse.ArgumentParser(description='Train a detector')
parser.add_argument('config', help='train config file path')
parser.add_argument('--work-dir', help='the dir to save logs and models')
parser.add_argument(
'--resume-from', help='the checkpoint file to resume from')
parser.add_argument(
'--auto-resume',
action='store_true',
help='resume from the latest checkpoint automatically')
parser.add_argument(
'--no-validate',
action='store_true',
help='whether not to evaluate the checkpoint during training')
group_gpus = parser.add_mutually_exclusive_group()
group_gpus.add_argument(
'--gpus',
type=int,
help='(Deprecated, please use --gpu-id) number of gpus to use '
'(only applicable to non-distributed training)')
group_gpus.add_argument(
'--gpu-ids',
type=int,
nargs='+',
help='(Deprecated, please use --gpu-id) ids of gpus to use '
'(only applicable to non-distributed training)')
group_gpus.add_argument(
'--gpu-id',
type=int,
default=0,
help='id of gpu to use '
'(only applicable to non-distributed training)')
parser.add_argument('--seed', type=int, default=None, help='random seed')
parser.add_argument(
'--diff-seed',
action='store_true',
help='Whether or not set different seeds for different ranks')
parser.add_argument(
'--deterministic',
action='store_true',
help='whether to set deterministic options for CUDNN backend.')
parser.add_argument(
'--options',
nargs='+',
action=DictAction,
help='override some settings in the used config, the key-value pair '
'in xxx=yyy format will be merged into config file (deprecate), '
'change to --cfg-options instead.')
parser.add_argument(
'--cfg-options',
nargs='+',
action=DictAction,
help='override some settings in the used config, the key-value pair '
'in xxx=yyy format will be merged into config file. If the value to '
'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
'Note that the quotation marks are necessary and that no white space '
'is allowed.')
parser.add_argument(
'--launcher',
choices=['none', 'pytorch', 'slurm', 'mpi'],
default='none',
help='job launcher')
parser.add_argument('--local_rank', type=int, default=0)
parser.add_argument(
'--auto-scale-lr',
action='store_true',
help='enable automatically scaling LR.')
args = parser.parse_args()
if 'LOCAL_RANK' not in os.environ:
os.environ['LOCAL_RANK'] = str(args.local_rank)
if args.options and args.cfg_options:
raise ValueError(
'--options and --cfg-options cannot be both '
'specified, --options is deprecated in favor of --cfg-options')
if args.options:
warnings.warn('--options is deprecated in favor of --cfg-options')
args.cfg_options = args.options
return args
def main():
args = parse_args()
cfg = Config.fromfile(args.config)
# replace the ${key} with the value of cfg.key
cfg = replace_cfg_vals(cfg)
# update data root according to MMDET_DATASETS
update_data_root(cfg)
if args.cfg_options is not None:
cfg.merge_from_dict(args.cfg_options)
if args.auto_scale_lr:
if 'auto_scale_lr' in cfg and \
'enable' in cfg.auto_scale_lr and \
'base_batch_size' in cfg.auto_scale_lr:
cfg.auto_scale_lr.enable = True
else:
warnings.warn('Can not find "auto_scale_lr" or '
'"auto_scale_lr.enable" or '
'"auto_scale_lr.base_batch_size" in your'
' configuration file. Please update all the '
'configuration files to mmdet >= 2.24.1.')
# set multi-process settings
setup_multi_processes(cfg)
# set cudnn_benchmark
if cfg.get('cudnn_benchmark', False):
torch.backends.cudnn.benchmark = True
# work_dir is determined in this priority: CLI > segment in file > filename
if args.work_dir is not None:
# update configs according to CLI args if args.work_dir is not None
cfg.work_dir = args.work_dir
elif cfg.get('work_dir', None) is None:
# use config filename as default work_dir if cfg.work_dir is None
cfg.work_dir = osp.join('./work_dirs',
osp.splitext(osp.basename(args.config))[0])
if args.resume_from is not None:
cfg.resume_from = args.resume_from
cfg.auto_resume = args.auto_resume
if args.gpus is not None:
cfg.gpu_ids = range(1)
warnings.warn('`--gpus` is deprecated because we only support '
'single GPU mode in non-distributed training. '
'Use `gpus=1` now.')
if args.gpu_ids is not None:
cfg.gpu_ids = args.gpu_ids[0:1]
warnings.warn('`--gpu-ids` is deprecated, please use `--gpu-id`. '
'Because we only support single GPU mode in '
'non-distributed training. Use the first GPU '
'in `gpu_ids` now.')
if args.gpus is None and args.gpu_ids is None:
cfg.gpu_ids = [args.gpu_id]
# init distributed env first, since logger depends on the dist info.
if args.launcher == 'none':
distributed = False
else:
distributed = True
init_dist(args.launcher, **cfg.dist_params)
# re-set gpu_ids with distributed training mode
_, world_size = get_dist_info()
cfg.gpu_ids = range(world_size)
# create work_dir
mmcv.mkdir_or_exist(osp.abspath(cfg.work_dir))
# dump config
cfg.dump(osp.join(cfg.work_dir, osp.basename(args.config)))
# init the logger before other steps
timestamp = time.strftime('%Y%m%d_%H%M%S', time.localtime())
log_file = osp.join(cfg.work_dir, f'{timestamp}.log')
logger = get_root_logger(log_file=log_file, log_level=cfg.log_level)
# init the meta dict to record some important information such as
# environment info and seed, which will be logged
meta = dict()
# log env info
env_info_dict = collect_env()
env_info = '\n'.join([(f'{k}: {v}') for k, v in env_info_dict.items()])
dash_line = '-' * 60 + '\n'
logger.info('Environment info:\n' + dash_line + env_info + '\n' +
dash_line)
meta['env_info'] = env_info
meta['config'] = cfg.pretty_text
# log some basic info
logger.info(f'Distributed training: {distributed}')
logger.info(f'Config:\n{cfg.pretty_text}')
cfg.device = get_device()
# set random seeds
seed = init_random_seed(args.seed, device=cfg.device)
seed = seed + dist.get_rank() if args.diff_seed else seed
logger.info(f'Set random seed to {seed}, '
f'deterministic: {args.deterministic}')
set_random_seed(seed, deterministic=args.deterministic)
cfg.seed = seed
meta['seed'] = seed
meta['exp_name'] = osp.basename(args.config)
model = build_detector(
cfg.model,
train_cfg=cfg.get('train_cfg'),
test_cfg=cfg.get('test_cfg'))
model.init_weights()
datasets = [build_dataset(cfg.data.train)]
if len(cfg.workflow) == 2:
assert 'val' in [mode for (mode, _) in cfg.workflow]
val_dataset = copy.deepcopy(cfg.data.val)
val_dataset.pipeline = cfg.data.train.get(
'pipeline', cfg.data.train.dataset.get('pipeline'))
datasets.append(build_dataset(val_dataset))
if cfg.checkpoint_config is not None:
# save mmdet version, config file content and class names in
# checkpoints as meta data
cfg.checkpoint_config.meta = dict(
mmdet_version=__version__ + get_git_hash()[:7],
CLASSES=datasets[0].CLASSES)
# add an attribute for visualization convenience
model.CLASSES = datasets[0].CLASSES
train_detector(
model,
datasets,
cfg,
distributed=distributed,
validate=(not args.no_validate),
timestamp=timestamp,
meta=meta)
if __name__ == '__main__':
main()1.3.2 数据转换
当你准备自定义数据集时,可能就需要自己写转换脚本,这个时候,可以将脚本写在这里,也可以下载开源数据,通过别人的给的脚本进行转换。

例如这里转coco数据集格式:
mmdetection/images2coco.py at master · open-mmlab/mmdetection · GitHub
# Copyright (c) OpenMMLab. All rights reserved.
import argparse
import os
import mmcv
from PIL import Image
def parse_args():
parser = argparse.ArgumentParser(
description='Convert images to coco format without annotations')
parser.add_argument('img_path', help='The root path of images')
parser.add_argument(
'classes', type=str, help='The text file name of storage class list')
parser.add_argument(
'out',
type=str,
help='The output annotation json file name, The save dir is in the '
'same directory as img_path')
parser.add_argument(
'-e',
'--exclude-extensions',
type=str,
nargs='+',
help='The suffix of images to be excluded, such as "png" and "bmp"')
args = parser.parse_args()
return args
def collect_image_infos(path, exclude_extensions=None):
img_infos = []
images_generator = mmcv.scandir(path, recursive=True)
for image_path in mmcv.track_iter_progress(list(images_generator)):
if exclude_extensions is None or (
exclude_extensions is not None
and not image_path.lower().endswith(exclude_extensions)):
image_path = os.path.join(path, image_path)
img_pillow = Image.open(image_path)
img_info = {
'filename': image_path,
'width': img_pillow.width,
'height': img_pillow.height,
}
img_infos.append(img_info)
return img_infos
def cvt_to_coco_json(img_infos, classes):
image_id = 0
coco = dict()
coco['images'] = []
coco['type'] = 'instance'
coco['categories'] = []
coco['annotations'] = []
image_set = set()
for category_id, name in enumerate(classes):
category_item = dict()
category_item['supercategory'] = str('none')
category_item['id'] = int(category_id)
category_item['name'] = str(name)
coco['categories'].append(category_item)
for img_dict in img_infos:
file_name = img_dict['filename']
assert file_name not in image_set
image_item = dict()
image_item['id'] = int(image_id)
image_item['file_name'] = str(file_name)
image_item['height'] = int(img_dict['height'])
image_item['width'] = int(img_dict['width'])
coco['images'].append(image_item)
image_set.add(file_name)
image_id += 1
return coco
def main():
args = parse_args()
assert args.out.endswith(
'json'), 'The output file name must be json suffix'
# 1 load image list info
img_infos = collect_image_infos(args.img_path, args.exclude_extensions)
# 2 convert to coco format data
classes = mmcv.list_from_file(args.classes)
coco_info = cvt_to_coco_json(img_infos, classes)
# 3 dump
save_dir = os.path.join(args.img_path, '..', 'annotations')
mmcv.mkdir_or_exist(save_dir)
save_path = os.path.join(save_dir, args.out)
mmcv.dump(coco_info, save_path)
print(f'save json file: {save_path}')
if __name__ == '__main__':
main()1.3.3 其他
其他的用到了再看看吧。
1.4 doc
doc文件中包含很多参考文件

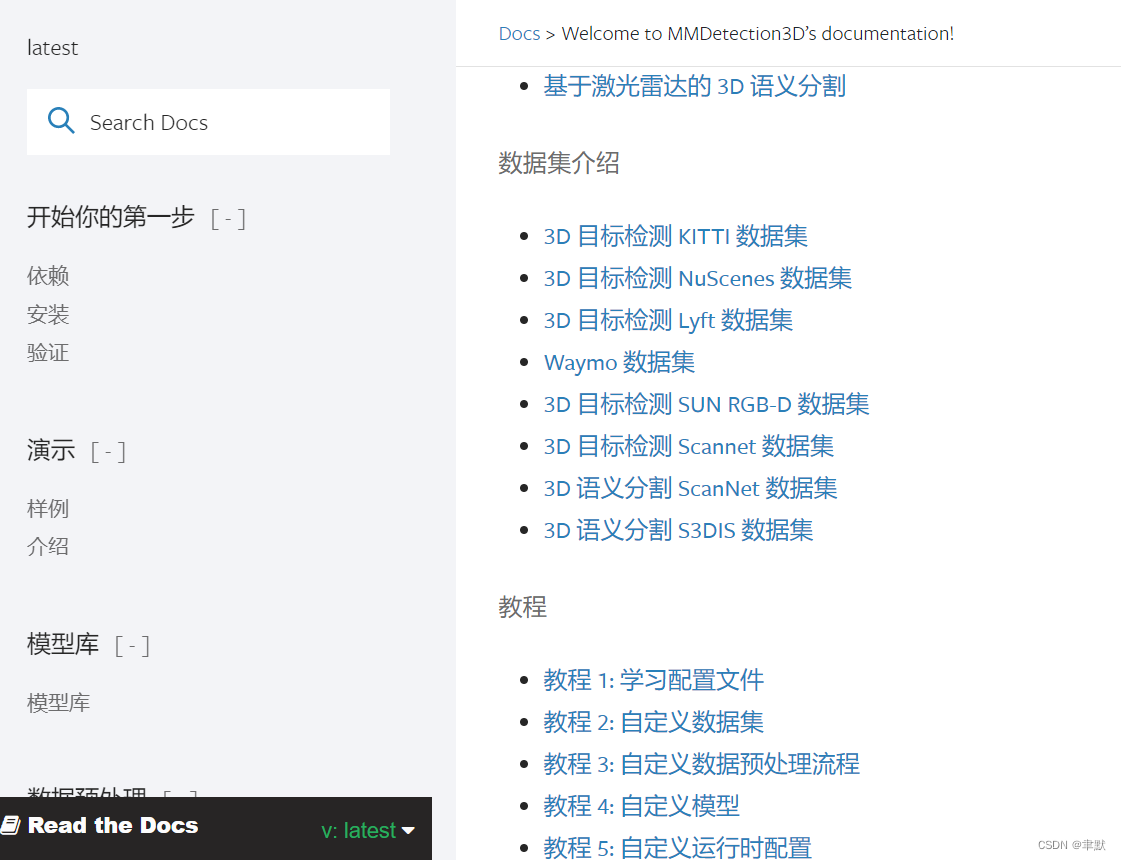
1.5 mmdetection官方指导文件
Welcome to MMDetection3D’s documentation! — MMDetection3D 1.0.0rc4 文档
2.核心机制
2.1 注册机制
注册机制:Python中的注册器模块 | Javen Chen's Blog
2.2 类名调用类实例化
python--根据字符串调用类方法或函数_无名无为的博客-CSDN博客_python 字符串 执行函数
2.3 源代码解析
会大致说下是如何调用的。
有三个比较关键的地方:
(1)初始化Registry类,并让其他的模块共用这一个注册
https://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/builder.pyhttps://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/builder.py#L7https://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/builder.py文件中的
MODELS = Registry('models', parent=MMCV_MODELS)
BACKBONES = MODELS
NECKS = MODELS
ROI_EXTRACTORS = MODELS
SHARED_HEADS = MODELS
HEADS = MODELS
LOSSES = MODELS
DETECTORS = MODELS(2)以BACKBONES为例,调用如下函数,将该类名存到字典中
https://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/backbones/darknet.py#L59
https://github.com/open-mmlab/mmcv/blob/master/mmcv/utils/registry.py#L287
# https://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/backbones/darknet.py#L59
@BACKBONES.register_module()
# https://github.com/open-mmlab/mmcv/blob/master/mmcv/utils/registry.py#L287
self._module_dict[name] = module(3)调用该cfg文件类名进行实例化
# https://github.com/open-mmlab/mmdetection/blob/master/tools/train.py#L212
model = build_detector(
cfg.model,
train_cfg=cfg.get('train_cfg'),
test_cfg=cfg.get('test_cfg'))
# https://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/builder.py#L48
def build_detector(cfg, train_cfg=None, test_cfg=None):
"""Build detector."""
if train_cfg is not None or test_cfg is not None:
warnings.warn(
'train_cfg and test_cfg is deprecated, '
'please specify them in model', UserWarning)
assert cfg.get('train_cfg') is None or train_cfg is None, \
'train_cfg specified in both outer field and model field '
assert cfg.get('test_cfg') is None or test_cfg is None, \
'test_cfg specified in both outer field and model field '
return DETECTORS.build(
cfg, default_args=dict(train_cfg=train_cfg, test_cfg=test_cfg))
# 以刚刚的https://github.com/open-mmlab/mmdetection/blob/master/configs/deepfashion/mask_rcnn_r50_fpn_15e_deepfashion.py
# https://github.com/open-mmlab/mmdetection/blob/master/configs/_base_/models/mask_rcnn_r50_fpn.py
# 找到Maskrnn类初始化后,https://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/detectors/mask_rcnn.py
# 找到其继承的类https://github.com/open-mmlab/mmdetection/blob/31c84958f54287a8be2b99cbf87a6dcf12e57753/mmdet/models/detectors/two_stage.py#L32
self.backbone = build_backbone(backbone)
# https://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/builder.py#L18
def build_backbone(cfg):
"""Build backbone."""
return BACKBONES.build(cfg)
# https://github.com/open-mmlab/mmcv/blob/37aa6dd04c7440dfa1d28a753a2f10d7c5ad621f/mmcv/utils/registry.py#L236
def build(self, *args, **kwargs):
return self.build_func(*args, **kwargs, registry=self)
# 属于这种情况https://github.com/open-mmlab/mmcv/blob/37aa6dd04c7440dfa1d28a753a2f10d7c5ad621f/mmcv/utils/registry.py#L125
self.build_func = build_from_cfg
# 最后实例化 https://github.com/open-mmlab/mmcv/blob/37aa6dd04c7440dfa1d28a753a2f10d7c5ad621f/mmcv/utils/registry.py#L69
return obj_cls(**args)
其中跳转这么多是为了走到backbone.build这一步,然后调用类名进行实例化。






![[附源码]Python计算机毕业设计SSM基于技术的高校学生勤工俭学管理系统的设计与开发(程序+LW)](https://img-blog.csdnimg.cn/6e24bfa958054206a2b7354ca2845d57.png)




![[附源码]JAVA毕业设计校园快递联盟系统(系统+LW)](https://img-blog.csdnimg.cn/ffc8d627721f48c99df4b53cde6432f4.png)