文章目录
- 前言
- 一、Elasticsearch指标
- ES支持的搜索类型
- ES的能力
- ES的写入实时性
- ES不支持事务
- 二、Elasticsearch名词
- 节点(Node)
- 角色(Roles)
- 索引(index)
- 文档(document)
- 三、Elasticsearch集群核心配置
- 四、Elasticsearch集群健康值
- 五、Elasticsearch故障诊断
- Cat API
- Cluster API
- 六、Elasticsearch分片
- 概念
- 种类
- 作用及意义
- 分片基本策略
- 四、Elasticsearch API
- 查看ES信息请求
- Search API(查询)
- Index API(创建)
- settings API(更新)
- 删除索引
- 索引不可变性
- Reindex API(重建文档)
- Document API
- 文档操作类型
- create
- index
- Source API
- Update API(字段部分更新)
- Mget API(批量查询)
- Bulk API(批量更新)
- Delete_by_query API(条件执行)
- 总结
前言
本文记录ES的名词、配置、API等的介绍。
一、Elasticsearch指标
ES支持的搜索类型
- 结构化搜索
能预先确定数据的结构。
- 非结构化搜索
无法确定数据的结构,如文档、html等。
- 文本搜索
- 地理位置搜索
半径查找、矩形查找、空间查找等
ES的能力
ES最擅长从海量数据中检索少量相关数据,但不擅长单次查询大量数据。
ES的写入实时性
ES是OLAP系统,侧重于海量数据的检索,而写入实时性并不是很高,默认1秒,1秒是ES缓冲区Buffer的刷新间隔时间。
ES是以写入实时性去换取数据检索的性能
ES不支持事务
ES写入实时性不高,对于数据保持强一致性的场景并不适用,需要具有ACID特性的数据库来支持,如MYSQL。
二、Elasticsearch名词
节点(Node)
一个节点就是一个ES实例,是一个ES进程。
角色(Roles)
角色是节点的重要属性。
常见的角色有:
- 主节点(active master)
活跃的主节点,是对集群的管理,消耗资源的任务不适合主节点允许。尽可能避免主节点不可用状态。 - 候选节点(master-eligible)
当主节点发生故障时,参与选举,是主节点的替代节点 - 数据节点(data node)
用于处理任务的节点,包括CURD、搜索和聚合 - 预处理节点(ingest node)
用于数据写入前的预操作,可过滤一些写入ES的垃圾数据。
ES共有11个角色

具体可查看ES官方文档
角色配置
对节点的角色配置,可区分不同节点功能
在没有配置节点配置时,默认拥有全部角色
node.roles: [角色1, 角色2, ...]
索引(index)
在ES中的索引类似于MYSQL的表,并不是用来快速查询的数据结构。
使用Kibana中新建索引
## 索引规范
## 字母全部小写
## 多个单词用下划线,不使用驼峰或帕斯卡 text_index
PUT product
索引组成部分

- aliases
索引别名 - mappings
索引设置,如分片和副本数量 - settings
映射,定义索引中包含哪些字段,以及字段长度、类似、分词器等。
文档(document)
相当于MYSQL中一条数据,因为ES中数据是以JSON格式储存的。
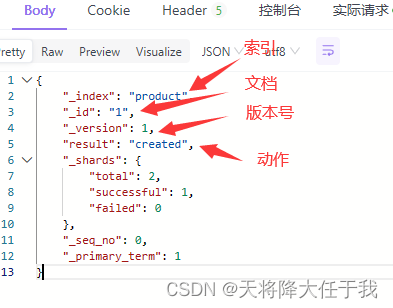
创建一个文档
http://192.168.8.125:9200/product/_doc/1
其中product为索引,_doc为类型,在7版本以后没有类型的概念,也就是索引下类型唯一,1为文档id。
 `
`
三、Elasticsearch集群核心配置
- network.host
提供服务的ip地址,一般配置为本节点所在服务器的内网地址,此配置会导致节点由开发模式转为生产模式,从而触发引导检查 - network_publish_host
提供服务的ip地址,一般配置为本节点所在服务器的公网地址 - http.port
服务端口号,默认9200。通常范围为9200-9299 - transport.port
节点通信端口。默认9300,通常范围为9300-9399 - dicovery.seed_hosts
提供集群中其它候选节点列表,并且可能处于活动状态且可联系以播种发现过程。每个地址可以是ip地址,也可以时通过DNS解析为一个或多个IP地址的主机名。 - cluster_initial_master_nodes
指定集群初次选举中用到的候选节点,称为集群引导,只在第一次形成集群时需要,如果配置了network.host,则此配置项必须配置。重新启动节点或将新节点添加到现有集群时不需要使用此设置。
四、Elasticsearch集群健康值
- 绿色
所有分片可用 - 黄色
至少有一个副本不可用,但是所有主分片都可用。能完成完整的读写服务,但是可用性较低 - 红色
至少有一个主分片不可用,数据不完整,此时集群无法完成完整的读写服务,集群不可用
五、Elasticsearch故障诊断
Cat API
- _cat/indices?health=yellow&v=true
查看当前集群中的所有索引 - _cat/health?v=true
查看健康状态 - _cat/nodeattrs
查看节点属性 - _cat/nodes?v
查看集群中的节点 - _cat/shards
查看集群中所有分片的分配情况
Cluster API
- _cluster/allocation/explain
可用于诊断分片未分配原因 - _cluster/health/ < target >
检查集群状态
六、Elasticsearch分片
概念
分片就是将索引分成若干块,而且分片是无限复制的
种类
- 主分片(primary shard)
- 副本分片(replica shard)
作用及意义
- 高可用性:提高分布式服务的高可用性
- 提高性能:提供系统服务的吞吐量和并发响应的能力
- 易扩展性:当集群的性能不满足业务要求时,可以方便快速的扩容集群,而无需停止服务
分片基本策略
- 一个索引包含一个或多个分片,默认一个主分片,副本可以修改数量,主分片不可以。
- 每一个分片都是Lucene实例,有完整的创建按索引和处理请求的能力
- ES会自动在nodes上做分片均衡
- 一个doc不可能同时存在于多个主分片中,但是当每个主分片的副本数量不为一时,可以同时存在于多个副本中。
- 主分片和副本分片不能存在于同一个节点上
- 完全相同的副本 不能同时存在于同一个节点上
四、Elasticsearch API
查看ES信息请求
- 查看ES信息
http://192.168.8.125:9200
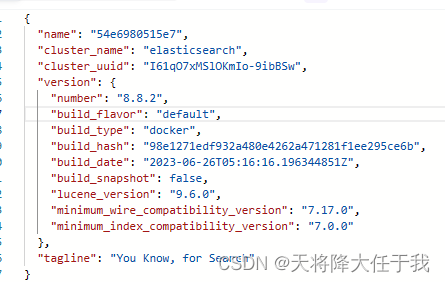
- 查看ES节点信息
http://192.168.8.125:9200/_cat/nodes
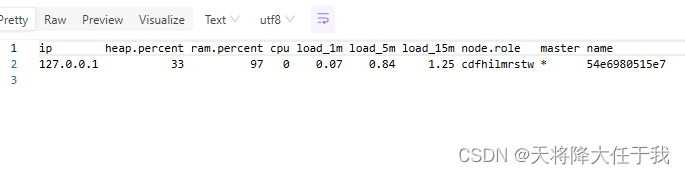
- 查看ES健康状态
http://192.168.8.125:9200/_cat/health

- 查看ES主节点
http://192.168.8.125:9200/_cat/master

- 查看ES所有索引
http://192.168.8.125:9200/_cat/indices
Search API(查询)
语法 GET请求
http://192.168.8.125:9200/_search
http://192.168.8.125:9200/<索引名>/_search
可选参数:
- size :数据长度
- from :从第几条开始
- timeout:超时时间
Index API(创建)
创建语法 PUT请求
http://192.168.8.125:9200/<索引名称>
可选参数:
{
"aliases": {
"NAME": {}
},
"mappings": {},
"settings": {
"number_of_shards": 1, #主分片数量
"number_of_replicas": 1 #每个主分片副分片数量
...
}
}
settings API(更新)
更新settings语法 PUT请求
http://192.168.8.125:9200/index_text/_settings
可选参数:
{
"number_of_replicas": 3
...
}
删除索引
删除语法 DELETE请求
http://192.168.8.125:9200/index_text
索引不可变性
索引创建成功后,以下属性不可变
- 索引名称
- 主分片数量
- 字段类型
Reindex API(重建文档)
重建语法 POST请求
http://192.168.8.125:9200/_reindex
可选参数:
{
"source": {
"index": "text_index"
},
"dest": {
"index": "text_index_new"
}
}
只复制数据,不复制结构
Document API
文档操作类型
- index:索引,可以创建,也可以全量替换(会将数据体内所有都替换)
- create:不存在则创建,存在则报错
以上操作为写操作,均发生在Primary Shard(主分片),当操作对象为数据流时,op_type必须为 create
create
在text_create索引下以create方式插入一条id为1内容是个JSON字符串的文档
PUT text_create/_doc/1?op_type=create
{
"name":"smz"
}
或
PUT text_create/_create/1
{
"name":"smz"
}
第一次则成功创建
{
"_index": "text_create",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
如果存在则报错
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[1]: version conflict, document already exists (current version [1])",
"index_uuid": "CF5tWqwITRG1Lk77yHJELw",
"shard": "0",
"index": "text_create"
}
],
"type": "version_conflict_engine_exception",
"reason": "[1]: version conflict, document already exists (current version [1])",
"index_uuid": "CF5tWqwITRG1Lk77yHJELw",
"shard": "0",
"index": "text_create"
},
"status": 409
}
index
在text_create索引下以index方式插入一条id为1内容是个JSON字符串的文档
PUT text_create/_doc/1?op_type=index
{
"name":"smz"
}
第一次则成功创建
{
"_index": "text_create",
"_id": "2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
如果存在则全量覆盖
{
"_index": "text_create",
"_id": "2",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1
}
不指定id则系统自动生成,且该方法只能使用POST请求
Source API
该API查出来的数据只会查出源字段,不会查出元字段(系统字段)。
语法如下
GET text_create/_source/1
{
"name": "smz"
}
与_doc API组合
GET text_create/_doc/1?_source=false
{
"_index": "text_create",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true
}
GET text_create/_doc/1?_source=true
{
"_index": "text_create",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"name": "smz"
}
}
Update API(字段部分更新)
在更新操作时会使源数据字段全都呗覆盖,所以采用update API来处理更新某个字段
语法如下
POST text_create/_update/1
{
"doc": {
"name":"smz2"
}
}
Mget API(批量查询)
批量查询出符合条件的,可以跨索引。
语法如下
GET _mget
{
"docs": [
{
"_index": "product",
"_id": "1"
},
{
"_index": "text_create",
"_id": "1"
}
]
}
GET text_create/_mget
{
"docs": [
{
"_id": "1"
},
{
"_id": "2"
}
]
}
GET text_create/_mget
{
"ids": [
1,
2
]
}
Bulk API(批量更新)
必须为两行形式,第一行为操作对应的对象,第二行为操作内容
批量添加,create可以更换为index,与上文单独一条添加的效果一样。
语法如下
POST _bulk
{"create":{"_index":"text_create","_id":"1"}}
{ "name":"smz2"}
{"create":{"_index":"text_create","_id":"2"}}
{ "name":"smz2"}
{"create":{"_index":"text_create","_id":"3"}}
{ "name":"smz2"}
批量更新。
POST text_create/_bulk
{"update":{"_id":"1"}}
{"doc":{"name": "smz_bulk"}}
{"update":{"_id":"2"}}
{"doc":{"name": "smz_bulk"}}
批量删除。
POST _bulk
{"delete":{"_index": "text_create","_id":"3"}}
{"delete":{"_index": "text_create","_id":"2"}}
Delete_by_query API(条件执行)
该API可以根据不同条件来执行操作。
语法如下
POST text_create/_delete_by_query
{
"query": {
...
}
}
总结
本文记录ES的名词、配置、API的基本用法等。