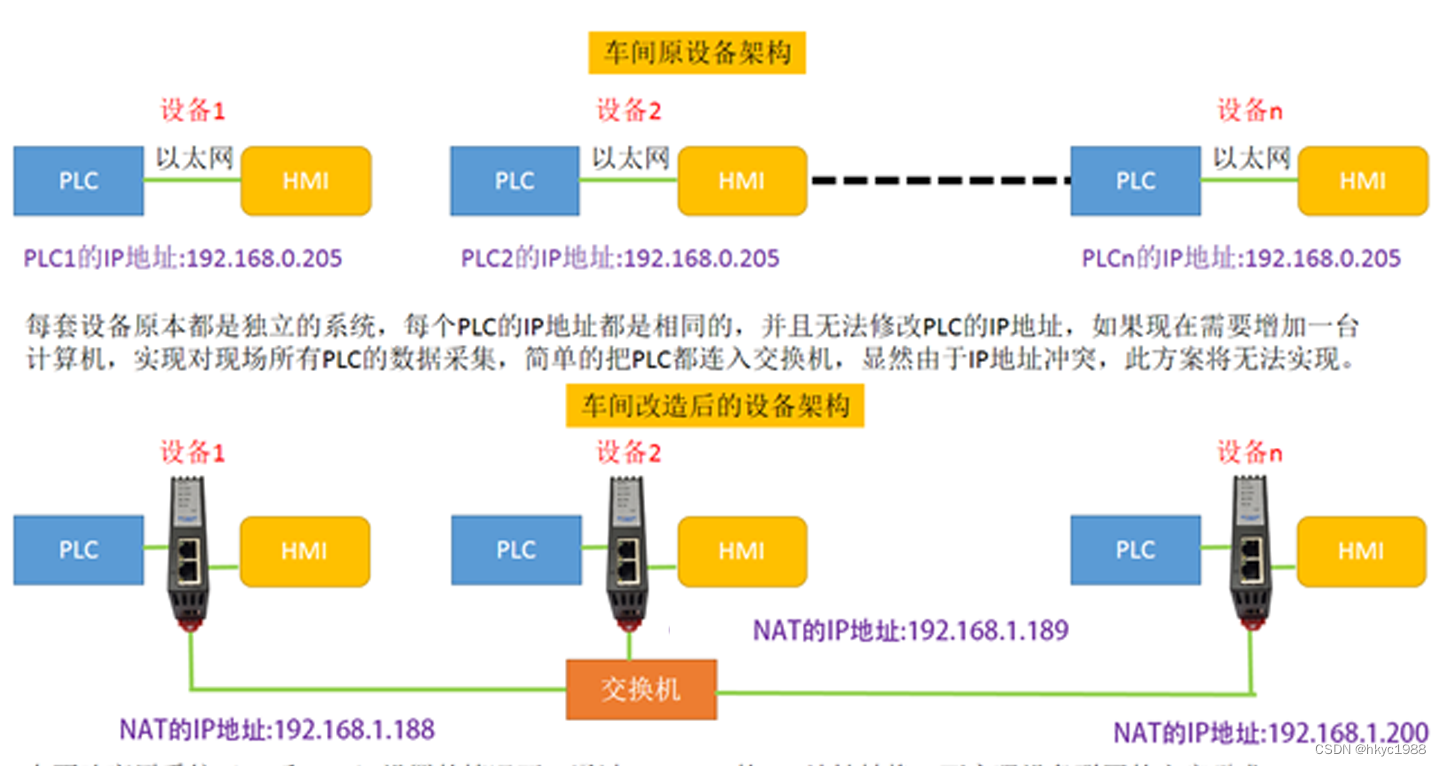
Systems介绍:
Catalog下面存HANA的 Schema。
Content下面建package来 放view 。
Provisioning可以建虚拟表 数据源啥的。
Security下面 是用户角色和权限。

一个calculation view里面的scenario场景下都有啥呢?
首先是semantics下面的节点,如果你选cube,第一个节点就是aggregation,如果你选了dimension,那第一个节点就是projection,如果你选的是cube with star join,那第一个节点就是Star Join。Semantics就是最终输出的结构。
在右边还能看到column,所有列,你能把列定义成属性或者数值。如果是个Star Join,那这些列底下还会有底层视图的shared columns,也就是维度。层级那一页也是从 底层维度视图或者在计算视图上定义的层级。参数变量包括用来过滤属性值的变量 和参数。
其他的Union,join ,projection,star join,aggregation,rank都很好用。
表链接语句解释:
referential Join: 要求参照完整性的时候用。
实际语义上它还是内连接,只不过预判是满足参照完整性。这个参照完整性是啥意思呢,就是我左边表里的条目,在右边必然会有一个对应的。这个参照join是简化的Inner join。我假设右边的表里会有条目和左边的表对应的。省去检查的这一步。
实际执行的时候就是这么一回事:**如果右表中的数据被获取,那我就执行Inner join。如果我不需要获取右表中的数据,那我就执行left outer join。**就看你取不取,以此来优化性能,毕竟左外比内联快多了。
啥场景用它呢?
由于他这个是默认参照完整性的,也就是说你左表的行必须在右表至少有一个对应的行。左右都使用这个参照完整性。如果没有参照完整性,那这个join出来计算的列就错了。你左边有,右边没,为了保证他这个参照完整性,他会给你在右表创建一个。但是你实际上没有这个,那数据就错了。
inner join:同时存在在两张表中。
left/right join:左边或者右边的内容全展示。不管另一边有还是没有。
数据库视图就是用的 inner join,而help view和 maintenance view用的就是outer join。
Text Join:语言相关的描述匹配。
可能有些奇怪,这个用来干什么的呢?你有一个产品表包含的是产品编号,但是没有描述。另外你有一个文本表,包含语言相关的产品文本描述。那你就可以用一个text join。来获取语言相关描述。右表必须得是文本 表。还必须确定语言列。如果文本不是语言相关你 也可用 左外连接。也就是说如果没有language这个列那你就用不了text join。
混合建模前提:

直接在BW Modeling Tools里面看到所有的Schema和package里的view。
现在我建的DSO啦,CP啦表都会被存放到HANA数据库上,Schema下面
不管是哪个,肯定是系统帮我生成的。已经在了,我只要知道它名字。
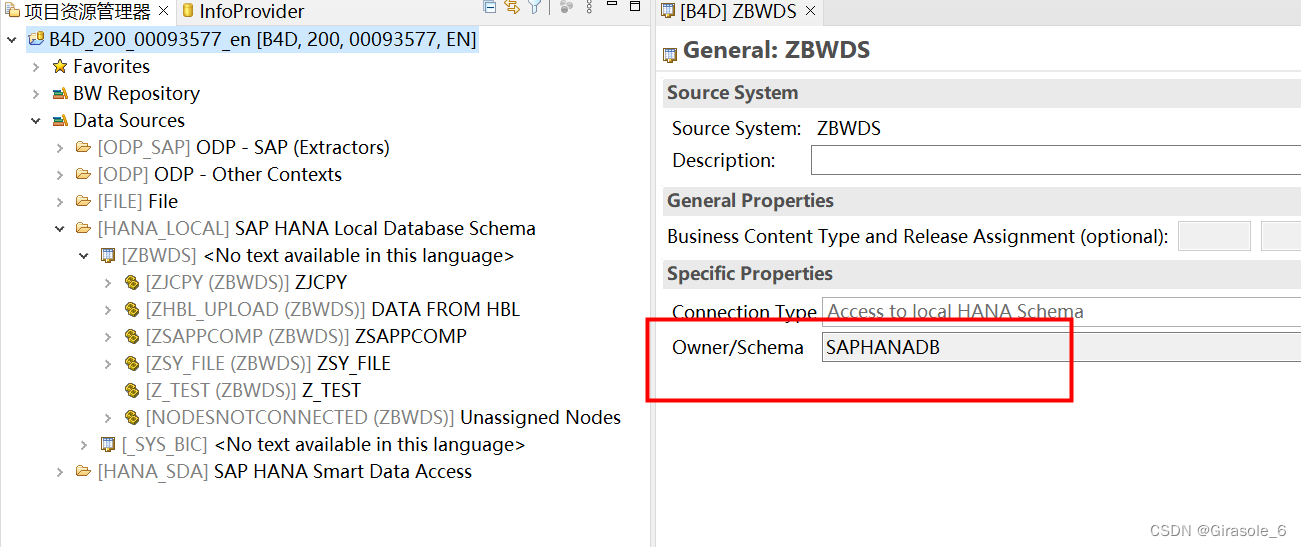
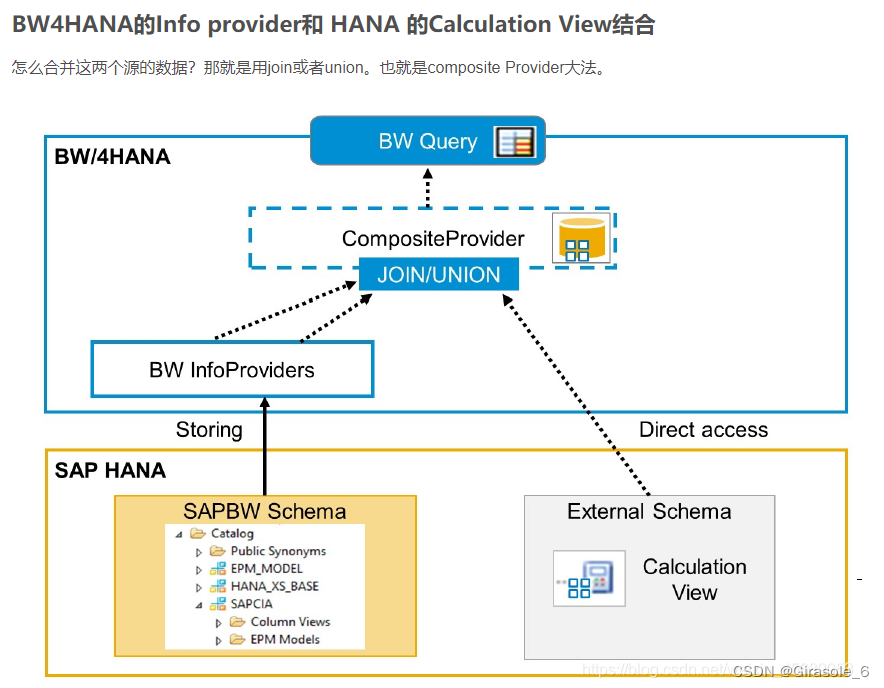
最顶层的这个CP虚拟层,提供报表和分析层的虚拟数据集市。从这个图可以看出,HANA 里面是直接视图来的。那么意思是这个view可以是SAP的源,也可以是非SAP的源。
以往在BW里面建模,那么必须得有一层info object,这是BW独有的。在BW之外,那都是字段 。这其实很费功夫。现在的话,这个中间通道在HANA这里打通了,不需要一定有info object了,可以直接字段了。
不仅省了好大功夫 ,而且这意味着不需要把数拉到BW再存一遍了。这个就很简单,你以前建了一个Calculation view和ADSO啥的,或者你建了一个CP可以用于其他CP的。那么你现在可以再建一个CP,用Union节点把你的CV和ADSO、CP都包进去。然后Data preview来看就行了。