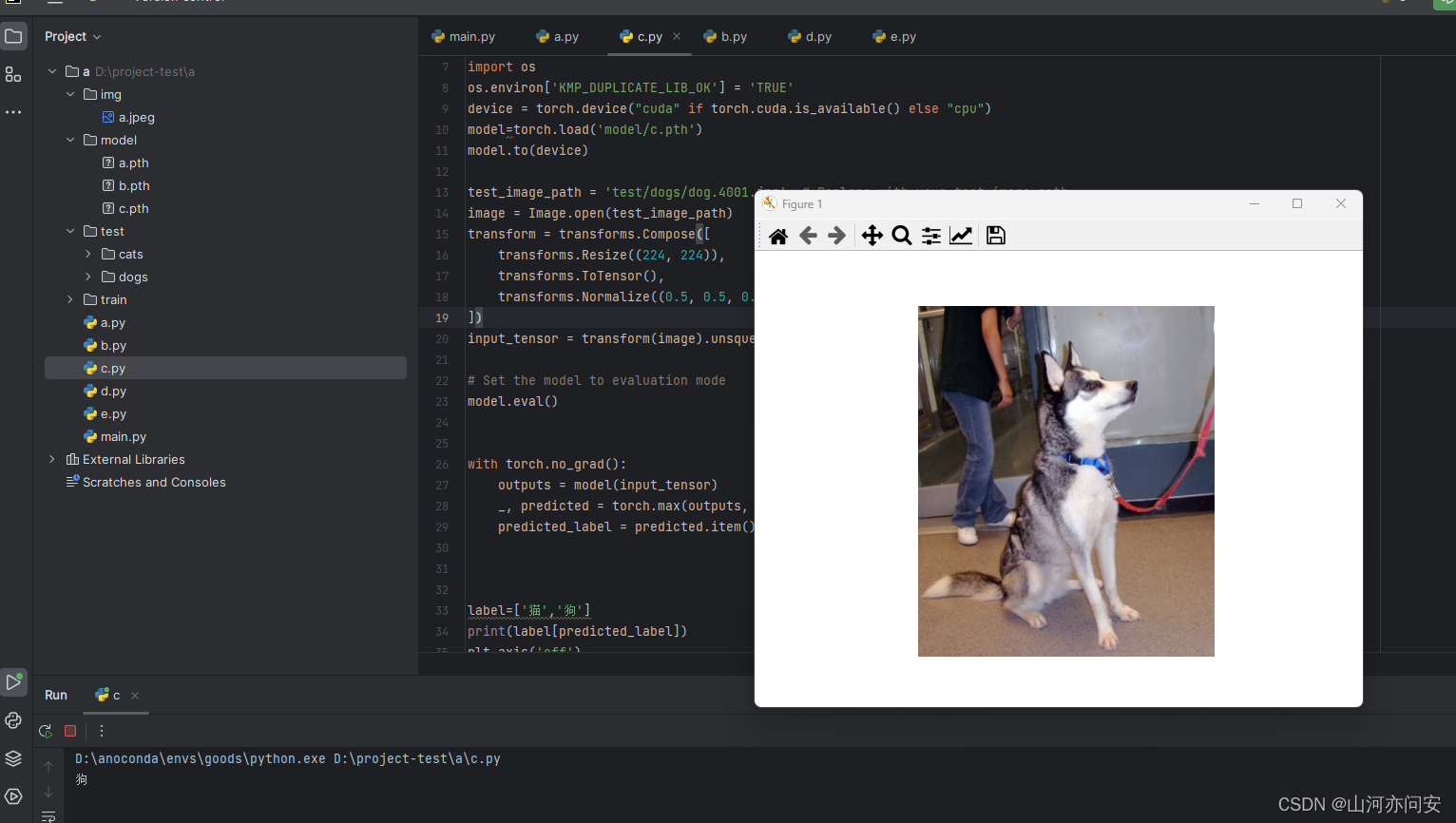
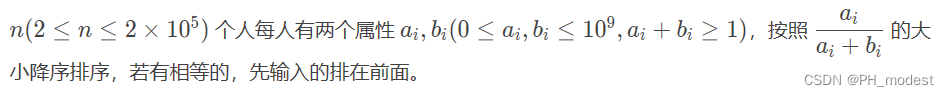验证码识别框架

新问题
最近遇到了数字验证码识别的新问题。
由于这次的数字验证码图片有少量变形和倾斜,所以,可能需要积累更多的原始采样进行学习。但按照4个验证码10个数字的理论随机组合(暗含某种数字仅有少量变化,不然此组合数量还应更大),也就是要采样差不多一万张图片;对每个图片适当分割后,那就差不多几万张图片了。想要对这些切割后的图片进行手工分类,成为基本数字的训练学习数据,手工工作量不小,也很无趣。
当时就在想,为什么不能用机器学习的聚类分析来做一部分粗略的前期工作呢?
基本数字图片存在某些相似性,即使无监督的聚类分析,应该可以提供一定程度上的分类。在粗略自动化聚类分析的基础上,选取少量、一部分正确数据作为训练样本,训练完第一个学习器后,利用增强分类能力的学习器,再对切割后的大量基本数字样本进行精确度更高的分类,然后不断迭代此过程进行自举。
随着不断地降低学习素材的噪声,和增大新样本数量提高信息量,是否在某个阶段就可以完成整个过程的自举了,而不用手工分类上万张基本图片了呢?
这个逐步提精和自举的过程,粗略觉得可行,而且至少和上一次的图片验证码走的路子不同,或许可以学到更多的东西。
最后幸运的是,这个新路子验证了猜测和想法,自举了几次后,就能够正确分类所有的数字图片了:)
对于机器学习的新认识
最初,对于这样的有变形的图片数据是否可以被简单的SVM支持向量机学习器识别正确,心内存在疑问,不过,结果还是不错的,依然可以达到100%的识别率。即使使用非线性核的SVM学习器,效果还并不如线性SVM学习器。
可能正如书本中评价SVM支持向量机的那样,对于高维数据,拥有足够稀疏性,本身就可以进行比较好的线性划分
总结
-
对于线性可分的数据,机器学习器能力都差不多;关键是如何形成线性可分的数据,即特征提取
-
噪音的降低和信息量的增加,一方面在于去除错误样本,另一方面在于正向增益样本的增多,这是一个信息论的问题!
-
- 集成学习多样而不同视角的特性数据,有助于算力窘迫的学习器进行学习
opencv的AI包
对于初步学习机器学习的朋友,可以利用opencv提供的机器学习组件,就可以完成一定程度的认知。
opency的机器学习包括了聚类分析、SVM支持向量机和KNN聚类分析,对于一般的机器学习应用也是足够的!
SVM支持向量机深入认识
SVM支持向量机学习器对采样数据,仅能经过一层的处理,这点要弱于CNN神经网络学习器。
可以认为,CNN神经网络能够对原始数据进行更多层的处理,特别是大量参数化的特性选取、抽取。
相比较于SVM的采样数据,必须就已经是线性可分,或者利用恰当的非线性核可进行处理,不然,就达不到有效的效果。
在你不拥有超强算力的时间,我的初步想法是,如果你可以对采样数据,做很多不同视角的特性抽取,可利用人类知识,或领域专家知识,即使是一些识别正确率不高的特性数据,利用集成学习加线性支持向量机的组合方法,应该依然可以取得比较好的学习效果!
异或分类问题
对于最简单的异或性质的分类,线性SVM也类似感知机,不能具有非常好的效果,需要核化方法的支持
CNN神经网络的认识
CNN神经网络学习,可以看成对第一层输入的全信息图片能够进行学习。一般这些特性规则无法用算法描述,利用CNN神经网络进行学习处理,包括了可参数化的特性的抽取和选取,通常具有较好的效果。 但如果输入并非全信息,我想CNN也会徒呼奈何的!
对比SVM来说,如果在一个相对比较容易降噪和特性抽取的领域,SVM也会具有非常好的效果
采样数据的全信息特性很重要
细微地方
- 为了增强基本数字图片中零值的数量,采用了阈值反向翻转的策略,使得图片中未提供信息的像素点值全部为零
- 同时opencv对图片机器学习,采用简单的拼接多行成为一行多维数据的做法,根据数字的形状特点,对于数字图片进行矩阵转置,可以将零值和非零信息更密集地集中在一些区域,可能会造成更好的聚性数据




![[CISCN 2023 初赛]go_session 解题思路过程](https://img-blog.csdnimg.cn/bd224c54e28c439184a9a521c2b395f8.png)