想使用二维得图像生成三维得空间图像,英伟达有完整得方案,开源,但是三维拼接不一样,只需要二维,并且要实时,如何生成是我每天都在思考得东西。
cnn 提取特征器和自编码
在训练细胞神经网络时,问题之一是我们需要大量的标记数据。在图像分类的情况下,我们需要将图像分为不同的类别,这是一项手动工作。
我们可能想使用原始(未标记)数据来训练CNN特征提取器,这被称为自我监督学习。我们将使用训练图像作为网络输入和输出,而不是标签。自动编码器的主要思想是,我们将有一个编码器网络,将输入图像转换到一些潜在空间(通常它只是一个较小大小的向量),然后是解码器网络,其目标是重建原始图像。
由于我们正在训练自动编码器从原始图像中捕获尽可能多的信息以进行准确的重建,因此网络试图找到输入图像的最佳嵌入来捕获含义。
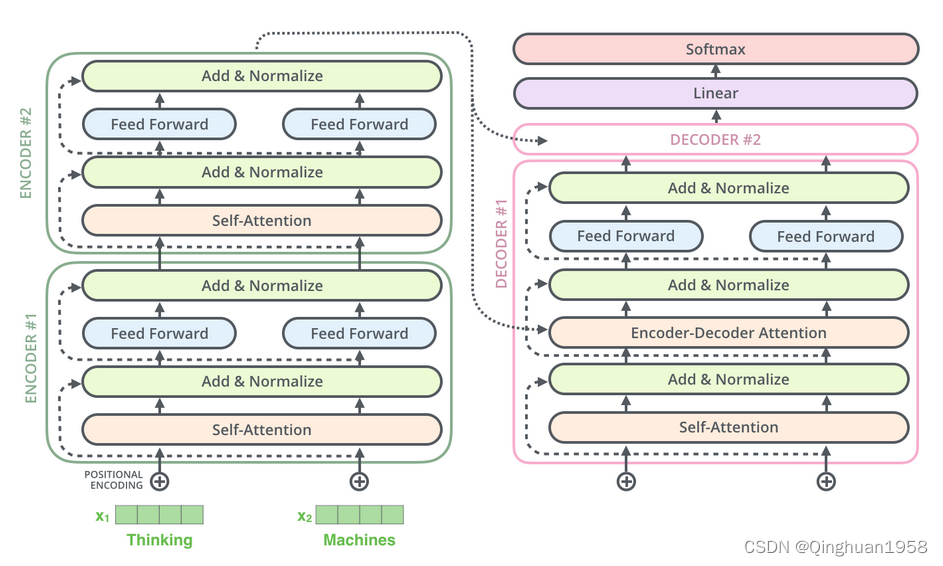
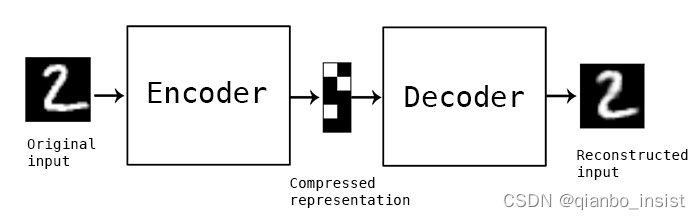
就像下面这副图像,使用encoder 和 decoder 来 从生成图像中来产生输出图像,这个应用应该是很广得,比如我们最近得视频拼接,是否可以从一个侧面或者另外一面生成正面图像?
部分代码得实现
只是想法,没有具体实现三维生成
import torch
import torchvision
import matplotlib.pyplot as plt
from torchvision import transforms
from torch import nn
from torch import optim
from tqdm import tqdm
import numpy as np
import torch.nn.functional as F
torch.manual_seed(42)
np.random.seed(42)
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
train_size = 0.9
lr = 1e-3
eps = 1e-8
batch_size = 256
epochs = 30
我们使用最简单得Minst数据集好了
def mnist(train_part, transform=None):
dataset = torchvision.datasets.MNIST('.', download=True, transform=transform)
train_part = int(train_part * len(dataset))
train_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_part, len(dataset) - train_part])
return train_dataset, test_dataset
transform = transforms.Compose([transforms.ToTensor()])
train_dataset, test_dataset = mnist(train_size, transform)
train_dataloader = torch.utils.data.DataLoader(train_dataset, drop_last=True, batch_size=batch_size, shuffle=True)
test_dataloader = torch.utils.data.DataLoader(test_dataset, batch_size=1, shuffle=False)
dataloaders = (train_dataloader, test_dataloader)
定义一个显示
def plotn(n, data, noisy=False, super_res=None):
fig, ax = plt.subplots(1, n)
for i, z in enumerate(data):
if i == n:
break
preprocess = z[0].reshape(1, 28, 28) if z[0].shape[1] == 28 else z[0].reshape(1, 14, 14) if z[0].shape[1] == 14 else z[0]
if super_res is not None:
_transform = transforms.Resize((int(preprocess.shape[1] / super_res), int(preprocess.shape[2] / super_res)))
preprocess = _transform(preprocess)
if noisy:
shapes = list(preprocess.shape)
preprocess += noisify(shapes)
ax[i].imshow(preprocess[0])
plt.show()
定义一个干扰器
def noisify(shapes):
return np.random.normal(loc=0.5, scale=0.3, size=shapes)
定义编码器
class Encoder(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=(3, 3), padding='same')
self.maxpool1 = nn.MaxPool2d(kernel_size=(2, 2))
self.conv2 = nn.Conv2d(16, 8, kernel_size=(3, 3), padding='same')
self.maxpool2 = nn.MaxPool2d(kernel_size=(2, 2))
self.conv3 = nn.Conv2d(8, 8, kernel_size=(3, 3), padding='same')
self.maxpool3 = nn.MaxPool2d(kernel_size=(2, 2), padding=(1, 1))
self.relu = nn.ReLU()
def forward(self, input):
hidden1 = self.maxpool1(self.relu(self.conv1(input)))
hidden2 = self.maxpool2(self.relu(self.conv2(hidden1)))
encoded = self.maxpool3(self.relu(self.conv3(hidden2)))
return encoded
再定义解码器
class Decoder(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(8, 8, kernel_size=(3, 3), padding='same')
self.upsample1 = nn.Upsample(scale_factor=(2, 2))
self.conv2 = nn.Conv2d(8, 8, kernel_size=(3, 3), padding='same')
self.upsample2 = nn.Upsample(scale_factor=(2, 2))
self.conv3 = nn.Conv2d(8, 16, kernel_size=(3, 3))
self.upsample3 = nn.Upsample(scale_factor=(2, 2))
self.conv4 = nn.Conv2d(16, 1, kernel_size=(3, 3), padding='same')
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
def forward(self, input):
hidden1 = self.upsample1(self.relu(self.conv1(input)))
hidden2 = self.upsample2(self.relu(self.conv2(hidden1)))
hidden3 = self.upsample3(self.relu(self.conv3(hidden2)))
decoded = self.sigmoid(self.conv4(hidden3))
return decoded
定义自动编码
class AutoEncoder(nn.Module):
def __init__(self, super_resolution=False):
super().__init__()
if not super_resolution:
self.encoder = Encoder()
else:
self.encoder = SuperResolutionEncoder()
self.decoder = Decoder()
def forward(self, input):
encoded = self.encoder(input)
decoded = self.decoder(encoded)
return decoded
model = AutoEncoder().to(device)
optimizer = optim.Adam(model.parameters(), lr=lr, eps=eps)
loss_fn = nn.BCELoss()
def train(dataloaders, model, loss_fn, optimizer, epochs, device, noisy=None, super_res=None):
tqdm_iter = tqdm(range(epochs))
train_dataloader, test_dataloader = dataloaders[0], dataloaders[1]
for epoch in tqdm_iter:
model.train()
train_loss = 0.0
test_loss = 0.0
for batch in train_dataloader:
imgs, labels = batch
shapes = list(imgs.shape)
if super_res is not None:
shapes[2], shapes[3] = int(shapes[2] / super_res), int(shapes[3] / super_res)
_transform = transforms.Resize((shapes[2], shapes[3]))
imgs_transformed = _transform(imgs)
imgs_transformed = imgs_transformed.to(device)
imgs = imgs.to(device)
labels = labels.to(device)
if noisy is not None:
noisy_tensor = noisy[0]
else:
noisy_tensor = torch.zeros(tuple(shapes)).to(device)
if super_res is None:
imgs_noisy = imgs + noisy_tensor
else:
imgs_noisy = imgs_transformed + noisy_tensor
imgs_noisy = torch.clamp(imgs_noisy, 0., 1.)
preds = model(imgs_noisy)
loss = loss_fn(preds, imgs)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
model.eval()
with torch.no_grad():
for batch in test_dataloader:
imgs, labels = batch
shapes = list(imgs.shape)
if super_res is not None:
shapes[2], shapes[3] = int(shapes[2] / super_res), int(shapes[3] / super_res)
_transform = transforms.Resize((shapes[2], shapes[3]))
imgs_transformed = _transform(imgs)
imgs_transformed = imgs_transformed.to(device)
imgs = imgs.to(device)
labels = labels.to(device)
if noisy is not None:
test_noisy_tensor = noisy[1]
else:
test_noisy_tensor = torch.zeros(tuple(shapes)).to(device)
if super_res is None:
imgs_noisy = imgs + test_noisy_tensor
else:
imgs_noisy = imgs_transformed + test_noisy_tensor
imgs_noisy = torch.clamp(imgs_noisy, 0., 1.)
preds = model(imgs_noisy)
loss = loss_fn(preds, imgs)
test_loss += loss.item()
train_loss /= len(train_dataloader)
test_loss /= len(test_dataloader)
tqdm_dct = {'train loss:': train_loss, 'test loss:': test_loss}
tqdm_iter.set_postfix(tqdm_dct, refresh=True)
tqdm_iter.refresh()
调用训练函数
train(dataloaders, model, loss_fn, optimizer, epochs, device)
使用模型去进行输入输出
model.eval()
predictions = []
plots = 5
for i, data in enumerate(test_dataset):
if i == plots:
break
predictions.append(model(data[0].to(device).unsqueeze(0)).detach().cpu())
plotn(plots, test_dataset)
plotn(plots, predictions)
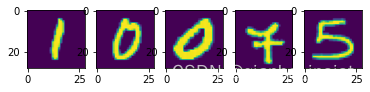
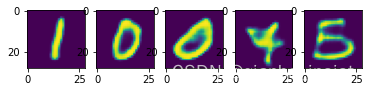
可以看出输入和输出是一一对应得,
联想
在做视频拼接得过程中,是想把二维得不同得侧面生成另外一面,也就是自动推测,这和生成三维有区别,只是部分
比如如下两幅图像

要拼接起来实属不易,这是海康那边让我们拼接得两幅图像,问题就是由于距离太近,桌子显然呈现得角度不同,人得眼睛没有那么宽,不可能同时看到这张桌子得左右两面,那么,如果拼接呢,最终结果就变成了下面这幅图

当然,上面两幅图像经过了不清楚,我经过了几次滤波变换,下面得图像可能清楚了一些,但是桌子变形了,问题就是,明明两个摄像头得宽度是足够看得见桌子得全貌得,如何展现就成了问题
因此我就想到了应该由生成式AI来解决这个问题,抛砖引玉,希望大家得出创造得方案。后面有新得结果继续给大家汇报。