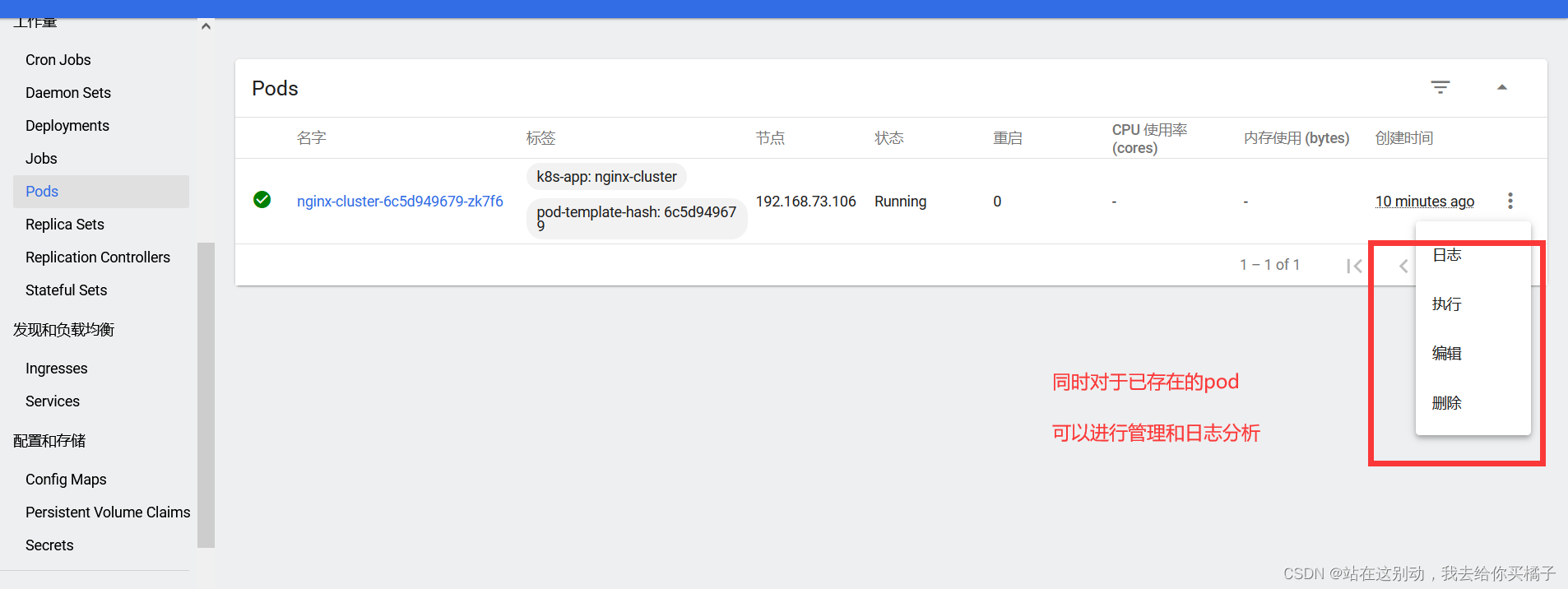
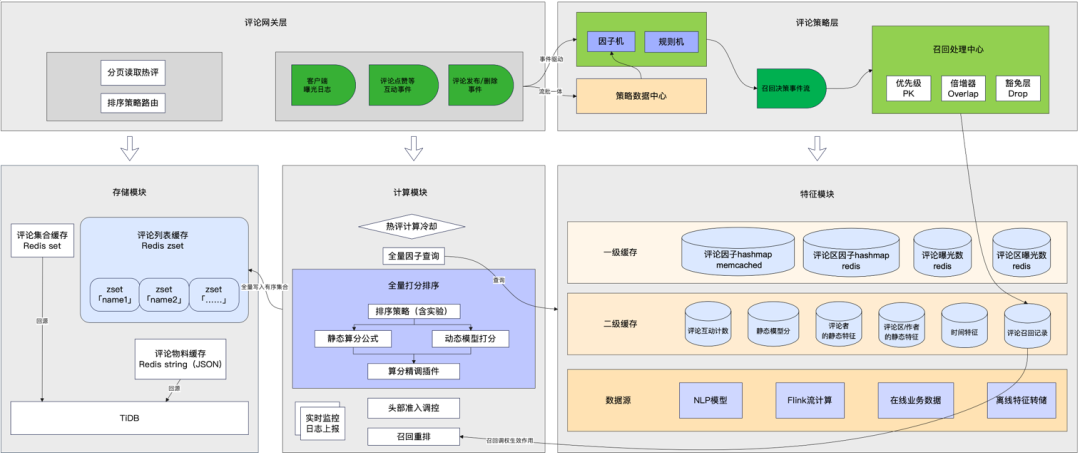
梅尔频谱和梅尔倒谱MFCCs是使用非常广泛的声音特征形式。
1.Mel-spectrogram梅尔语谱图
机器学习的第一步都是要提取出相应的特征(feature),如果输入数据是图片,例如28*28的图片,那么只需要把每个像素(pixel)作为特征,对应的像素值大小(代表颜色的强度)作为特征值即可。那么在音频、语音信号处理领域,我们需要将信号转换成对应的语谱图(spectrogram),将语谱图上的数据作为信号的特征。语谱图的横轴x为时间,纵轴y为频率,(x,y)对应的数值代表在时间x时频率y的幅值。
通常的语谱图其频率是线性分布的,但是人耳对频率的感受是对数的(logarithmic),即对低频段的变化敏感,对高频段的变化迟钝。
研究表明,人类对频率的感知并不是线性的,并且对低频信号的感知要比高频信号敏感。例如,人们可以比较容易地发现500和1000Hz的区别,确很难发现7500和8000Hz的区别。这时,梅尔标度(the Mel Scale)被提出,它是Hz的非线性变换,对于以mel scale为单位的信号,可以做到人们对于相同频率差别的信号的感知能力几乎相同。
所以线性分布的语谱图显然在特征提取上会出现“特征不够有用的情况”,因此梅尔语谱图应运而生。梅尔语谱图的纵轴频率和原频率经过如下公式互换:

而梅尔倒频系数(MFCCs)是在得到梅尔语谱图之后进行余弦变换(DCT,一种类似于傅里叶变换的线性变换),然后取其中一部分系数即可。
2.梅尔语谱图Mel-spectrogram具体是如何获得的
1)获取音频信号
python可以用librosa库来读取音频文件,只能读取wav音频文件格式。
2)信号预加重(pre-emphasis)
通常来讲语音/音频信号的高频分量强度较小,低频分量强度较大,信号预加重就是让信号通过一个高通滤波器,让信号的高低频分量的强度不至于相差太多。
3)分帧(framing)
把原信号按时间分成若干个小块,一块就叫一帧(frame)。
信号覆盖的时间太长,用它整个来做FFT,我们只能得到信号频率和强度的关系,而失去了时间信息。我们想要得到频率随时间变化的关系,所以将原信号分成若干帧,对每一帧作FFT(又称为短时FFT,因为我们只取了一小段时间),然后将得到的结果按照时间顺序拼接起来。这就是语谱图(spectrogram)的原理。
- frames变量,其每一行对应每一帧
- frame_size: 每一帧的长度,通常取20-40ms,太长使时间上的分辨率(time resolution)较小,太小加重运算成本
- frame_length: 每一帧对应的sample数量
- frame_stride: 相邻两帧的间隔,通常间隔必须小于每一帧的长度,即两帧之间要有重叠,以防丢失边界信息
- frame_step: 相邻两帧的sample数量
- frame_num: 整个信号所需要的帧数,补0(zero padding)让信号的长度正好能分成整数帧
4)加窗(window)
分帧完毕之后,对每一帧加一个窗函数,以获得较好的旁瓣下降幅度。通常使用hamming window frames和hamming window直接相乘即可,注意这里不是矩阵乘法。
(在分帧的这个过程中也相当于给信号加了矩形窗,学过离散滤波器设计的人应该知道,矩形窗的频谱有很大的旁瓣,时域中将窗函数和原函数相乘,相当于频域的卷积,矩形窗函数和原函数卷积之后,由于旁瓣很大,会造成原信号和加窗之后的对应部分的频谱相差很大,这就是频谱泄露。hamming window有较小的旁瓣,造成的spectral leakage也就较小)
5)获取功率谱
frames变量,其每一行对应每一帧,分别对每一行做FFT,将得到的FFT变换取其magnitude,并进行平方再除以对应的FFT点数,即可得到功率谱。
6)梅尔滤波器组(Mel-filter banks)
最后一步是将梅尔滤波器运用到上一步得到的pow_frames上。
所谓梅尔滤波器组是一个等高的三角滤波器组,每个滤波器的起始点在上一个滤波器的中点处。其对应的频率在梅尔尺度上是线性的,因此称之为梅尔滤波器组。每个滤波器对应的频率可以将最大频率用上面提到的公式转换成梅尔频率,在梅尔尺度上线性分成若干个频段,再转换回实际频率尺度即可。
实际操作时,将每个滤波器分别和功率谱pow_frames进行点乘,获得的结果即为该频带上的能量(energy)。
mel-spectrogram,结果是一个矩阵,每一行是一帧,每一列代表对应的梅尔频带的能量。
7)Mel-spectogram feature
机器学习的时候,每一个音频段可用对应的mel-spectogram表示,每一帧对应的某个频段即为一个feature。
实际操作中,每个音频要采用同样的长度,feature数量才是相同的。通常还要进行归一化,即每一帧的每个元素要减去该帧的平均值,以保证每一帧的均值均为0。
3.MFCCs
python包:python_speech_features.mfcc
document:https://python-speech-features.readthedocs.io/en/latest/#
梅尔谱系数是互相关的,在一些机器学习算法中可能会出问题,因为有些算法假设数据不存在互相关性。因此,可以用DCT变换来压缩梅尔谱,得到一组不相关的系数。
MFCC是倒谱系数,所谓倒谱系数,就是对log之后的梅尔谱系数进行DCT变换,其实相当于将实际上是频域的信号当成时域信号强行进行频域变换,得到的是频域信号在伪频域的幅频相应,前2-13个系数代表的是包络,因为他们在伪频域上是低频信号,后面的系数是伪频域的高频信号,代表的是spectral details,在语音识别的时候,对我们帮助更大的是包络,因为包含了formants等信息。
MFCC的提取过程:
- 对一段连续的音频信号分帧
- 把每一帧转换为它的频谱(或能量谱)
- 对每一帧的频谱用梅尔滤波器(mel filterbank)进行滤波,再对每个滤波器的结果求和得到一个长度为n滤波器的向量
- 对3.中得到的向量的每个元素取对数
- 对4.中的向量做DCT,得到另一个向量(倒频谱)
- 保留第2~13个元素,这个长度为12的向量即为MFCC