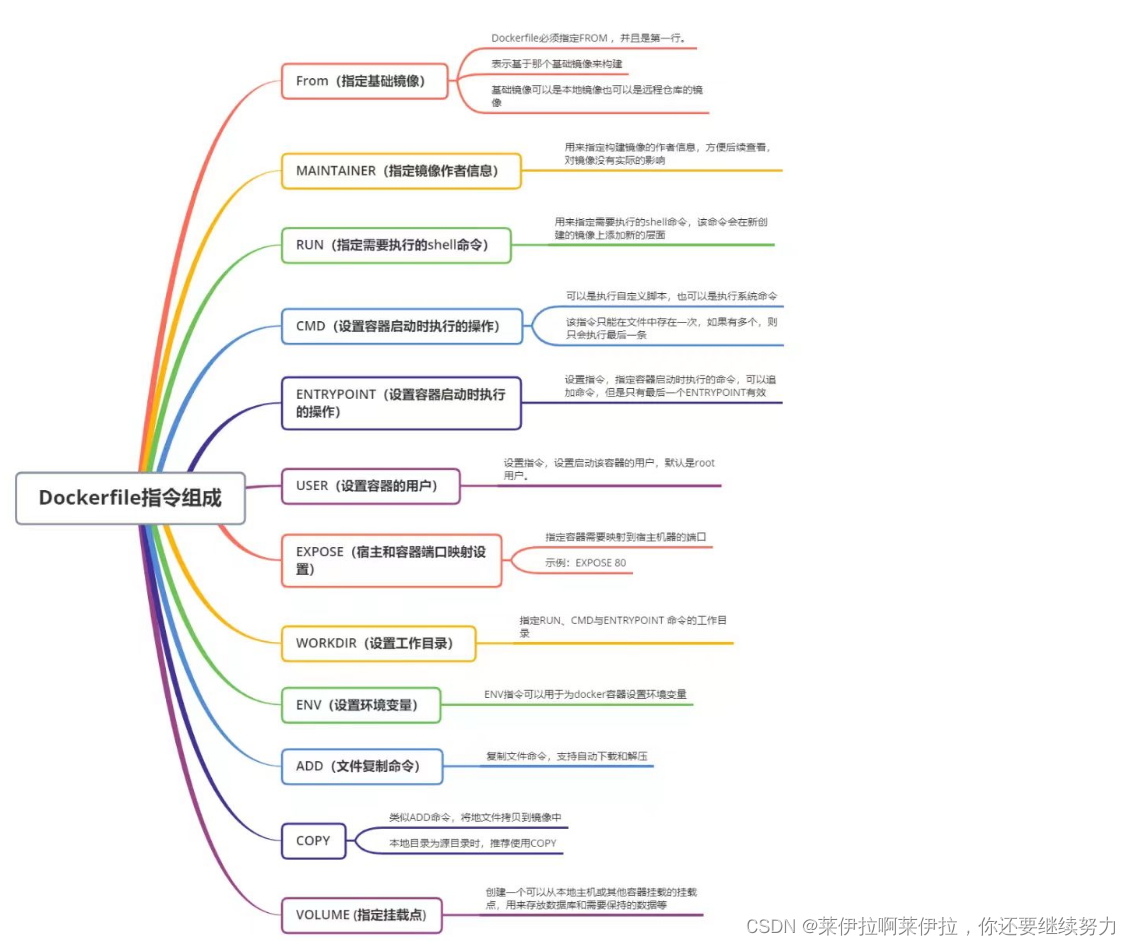
文章目录
- 一、背景
- 二、方法
- 2.1 Backbone
- 2.2 检测分支
- 2.3 Re-ID 分支
- 2.4 训练 FairMOT
- 2.5 Online Inference
- 三、效果
- 3.1 数据集
- 3.2 实现细节
- 3.3 消融实验
- 3.4 最终效果

论文:FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking
代码:https://github.com/ifzhang/FairMOT
出处:IJCV2021
一、背景
Multi-object tracking (MOT) 任务是什么:
- 估计视频中感兴趣目标的运动轨迹
MOT 的重要性,在计算机视觉中是一个很重要的任务:
- 有利于智能视频分析
- 人机交互
当时的方法是怎么解决 MOT 任务的
- 很多方法将 MOT 任务构建成了一个多任务学习的模型,包括:
- 目标检测
- reid
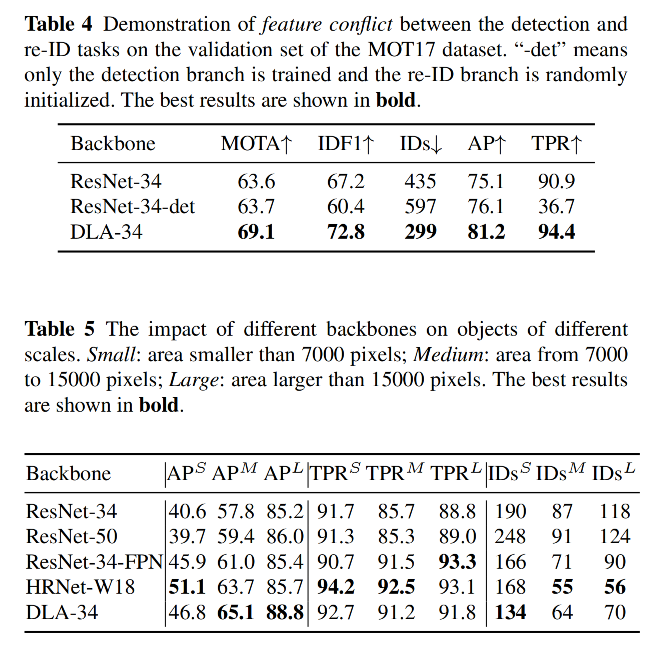
但作者认为,这两个任务是相互竞争的
之前的方法一般都是将 reid 作为检测后的第二个任务,其效果会被目标检测的效果影响,且网络一般都是偏向第一阶段的目标检测网络,对 reid 很不公平,而且两阶段的 MOT 方法难以实现实时推理,原因在于当目标数量很多时,这两个模型是不共享特征的,reid 模型需要对每个框都提取特征
所以,后面就出现了单阶段的追踪方法,使用一个模型来学习检测和 reid 的特征:
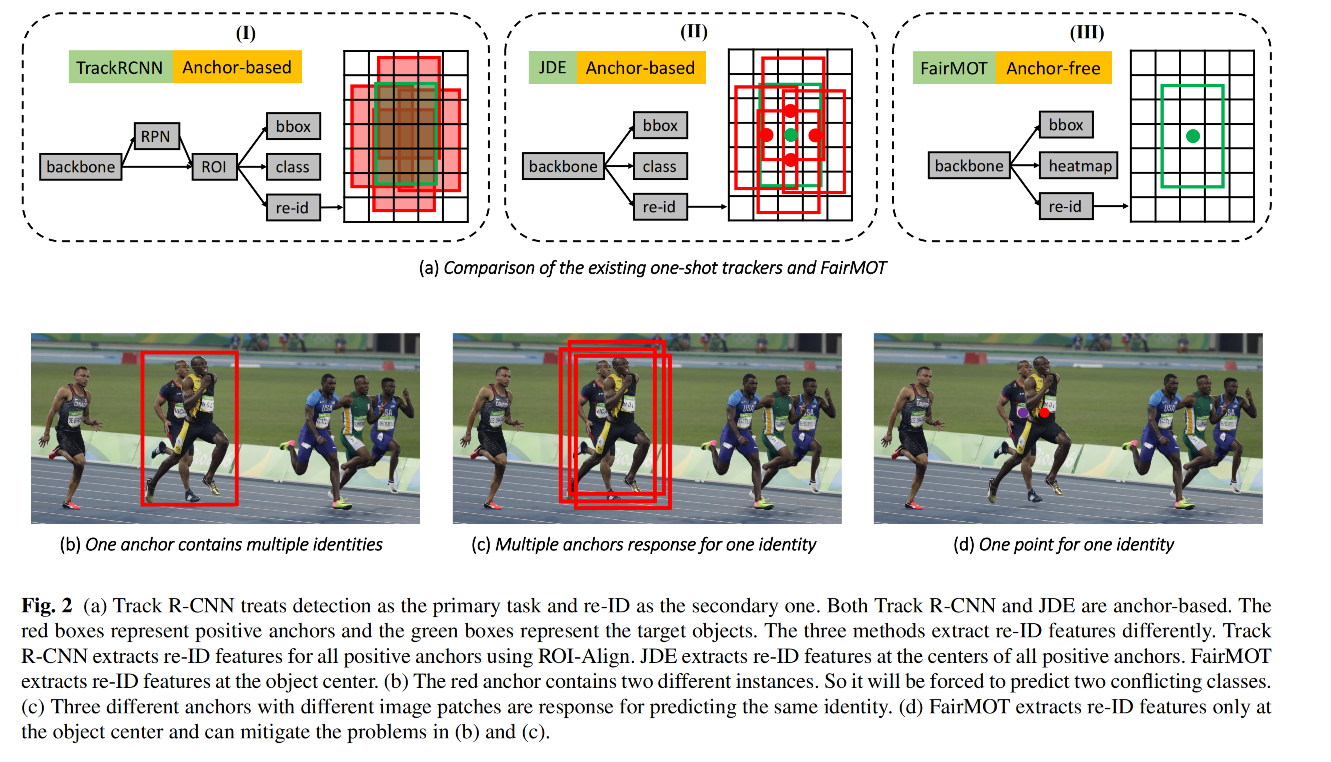
- Voigtlaender(在 Mask RCNN 中增加了一个 reid 分支,给每个 proposal 都学习 reid 特征,虽然提升了速度,但效果远远比不上两阶段方法,一般都是检测效果很好,但追踪效果变差
所以本文作者首先探讨了上述问题出现的原因:
- anchors:anchor 原本是为目标检测设计的,不适合用于对 reid 特征的学习
- 基于 anchors 的方法需要为待检测的目标生成 anchors,然后基于检测结果来抽取 reid 特征,所以,模型在训练时候就会进入 “先检测,后 reid” 的模式,reid 特征就会差一些
- 而且 anchor 会为 reid 特征的学习带来不确定性,尤其是在拥挤场景,一个 anchor 可能对应多个个体,多个 anchor 也可能对应一个个体
- 特征共享:这两个任务所需要的特征是不同的,所以不能直接进行特征共享
- reid 需要更 low-level 的特征来识别同一类别不同实例间的有区分力的特征
- 目标检测需要高层和低层信息结合来学习类别和位置
- 单阶段目标追踪方法会产生特征冲突,降低效果
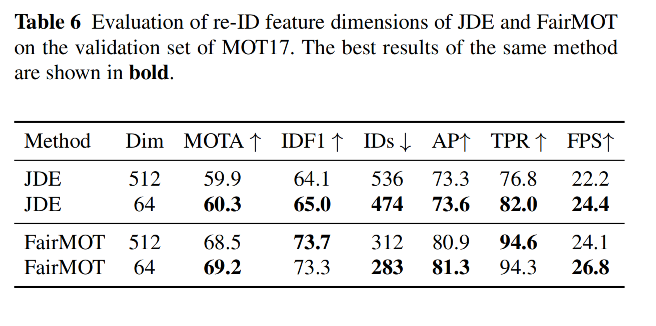
- 特征维度:(reid 需要更高维的特征,MOT 需要低维的特征即可)
- reid 特征一般使用的特征维度为 512 或 1024,远远大于目标检测的维度(一般为 类别+定位),所以降低 reid 特征的维度有利于两个任务的平衡
- MOT tracking 和 reid 是不同的,MOT 任务只需要对前后帧目标进行一对一的匹配,reid 需要更有区分力的高维特征来从大量的候选样本中匹配查询样本,MOT 是不需要高维特征的
- 低维度的 reid 特征会提高推理速度
本文提出了公平的方法 FairMOT:基于 CenterNet
- 将目标检测和 reid 同等对待,而不是先检测后 reid 的模式
- 不是对 CenterNet 和 REID 的简单结合
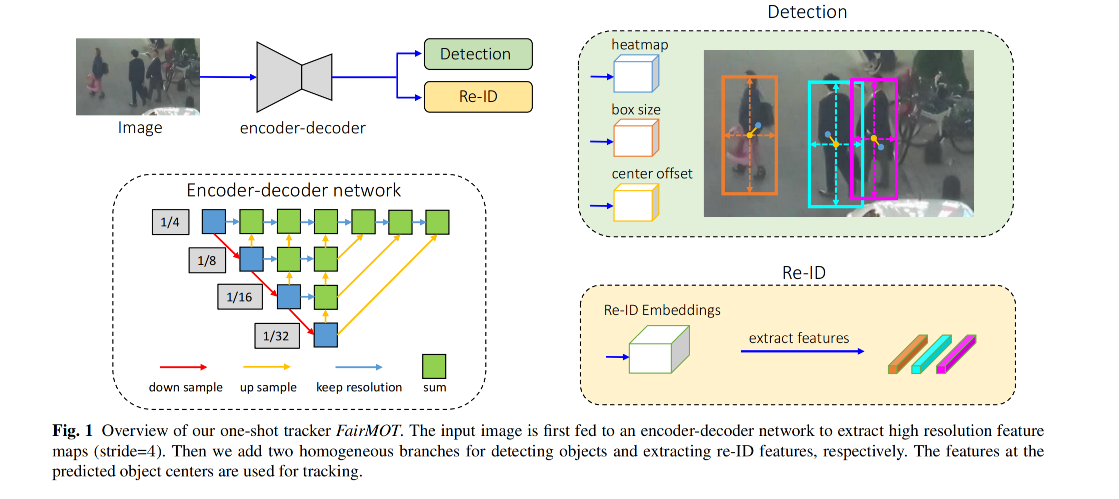
FairMOT 的结构图如图 1 所示:
- 由两个分支组成,分别来进行目标检测和抽取 reid 特征
- 目标检测分支是 anchor-free 的,是基于特征图来预测特征的中心点和尺寸
- reid 分支为每个目标中心位置预测 reid 特征
- 这样的两个分支并列的而非串联的,能更好的平衡这两个任务
二、方法
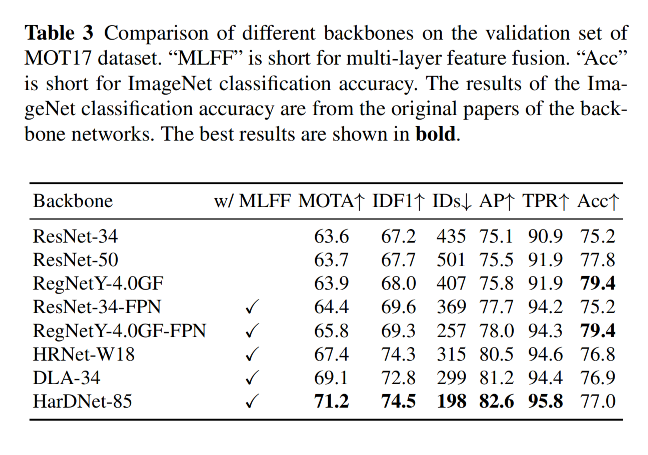
2.1 Backbone
作者使用 ResNet-34 作为基础 backbone,能更好的平衡速度和精度
还可以使用 DLA 来实现更强版本
2.2 检测分支
检测分支使用 CenterNet,centerNet 包含一个 heatmap head,一个 wh head,一个 offset head
2.3 Re-ID 分支
作者在 backbone 输出特征的基础上,构建了 reid 分支:
- reid 分支提取的特征,在不同目标上距离远,在相同目标上的距离近
- 所以作者使用 128 kernel 为特征图上的每个位置来抽取 reid 特性,得到的特征为 128xHxW
Re-ID loss:
reid 特征的学习方式被规范为分类任务,同一个个体的不同实例都被认为是同一类别
对一张图中的所有 gt 框,会得到其中心点位置,然后会抽取 reid 特征,并使用全连接层和 softmax 操作来将其映射为分类特征
假设 gt 类别向量为 L,预测的为 p,则 reid loss 为:

- K 是训练数据中所有个体的数量
- 在训练中,只有在目标中心的个体特征会参与训练
2.4 训练 FairMOT
作者联合训练检测和 reid 分支,将所有 loss 加起来
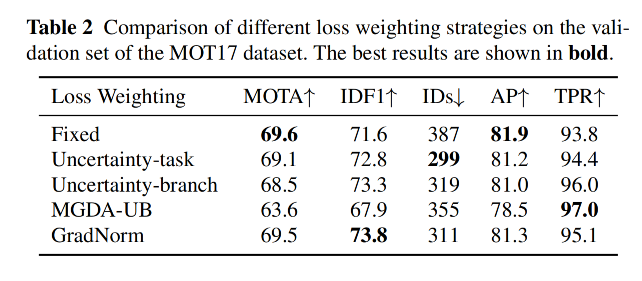
注意:作者使用了 uncertainty loss 来自动平衡两个任务:

- w 1 w_1 w1 和 w 2 w_2 w2 是可学习参数,用于平衡两个任务
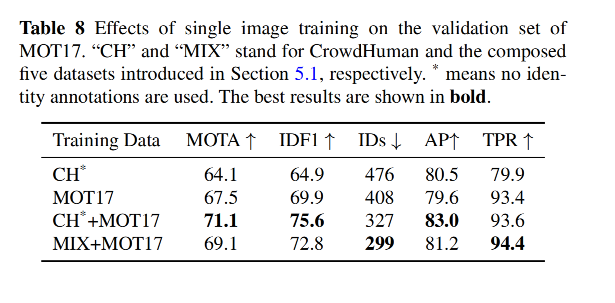
此外,作者还提出了 single image training method 来在 image-level 目标检测数据集上训练了 FairMOT(如 COCO、CrowdHuman 等)
- 作者每次只属于一个图片,将图像中每个目标都当做独立的个体,将每个 bbox 都当做一个单独的类别
2.5 Online Inference
1、网络推理
- 输入 1088x608
- 对预测的 heatmap,基于 heatmap score 来进行 NMS 过滤,来抽取峰值关键点(NMS 是 3x3 最大池化),保留大于阈值的 keypoint
- 基于保留下来的关键点和 wh、offset 分支来计算 box 尺寸
2、Online Association
- 首先,将第一帧检出的检测框建立为 tracklet(短轨迹)
- 之后,在后面的每一帧,都会使用 two-stage 匹配策略来将检出的 bbox 和 tracklet 匹配
- 匹配策略第一阶段:使用 Kalman 滤波和 reid 的特征来得到初始追踪结果,使用 Kalman 滤波是为了预测后面的帧的 tracklet 位置,并且计算预测框和检测框的 Mahalanobis distance ( D m D_m Dm)。然后将 D m D_m Dm 和余弦距离进行融合, D = λ D r + ( 1 − λ ) D m D=\lambda D_r + (1-\lambda) D_m D=λDr+(1−λ)Dm, λ = 0.98 \lambda=0.98 λ=0.98 是权重。当 D m D_m Dm 大于阈值 τ 1 = 0.4 \tau_1 = 0.4 τ1=0.4 时,被设置为无穷大
- 匹配策略第二阶段:对没匹配上的检测结果和 tracklet,作者会使用 box 之间的重合率来进行匹配,阈值 τ 2 = 0.5 \tau_2 = 0.5 τ2=0.5,会更新 tracklets 的特征
- 最后,会给没匹配上的检测结果重新初始化,并且对没有匹配上的 tracklets 保留 30 帧
三、效果
3.1 数据集
训练数据集:
- ETH 和 CityPerson:只有 box 的标注信息,故被用于训练检测分支
- CalTech、MOT17、CUHK-SYSU、PRW 有 box 和 identity 标注信息,可以训练两个分支
测试数据集:
- 2DMOT15、MOT16、MOT17、MOT29
测评方式:
- 检测效果:mAP
- reid 特征:True Positive Rate, false accept rate =0.1(TPR@FAR=0.1)
- 整个追踪效果:CLEAR、IDF1
3.2 实现细节
- 使用 DLA-34 的变体作为 backbone,在 COCO 上预训练后的模型来作为初始模型
- 优化器:Adam,初始学习率 1 0 − 4 10^{-4} 10−4
- epoch:30,在 20 epochs 的时候学习率降低到 1 0 − 5 10^{-5} 10−5
- batch size:12
- 输入数据大小:1088x608(特征图的分辨率为 272x152)
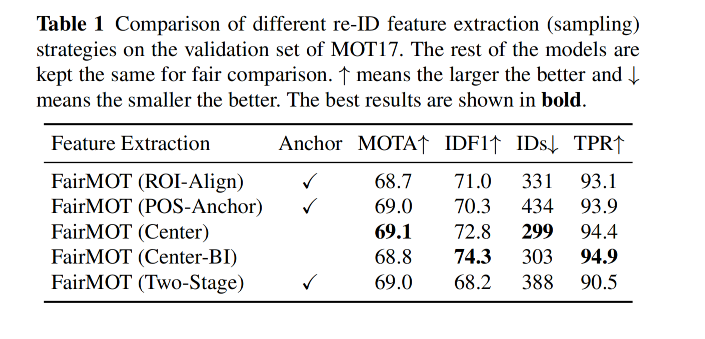
3.3 消融实验

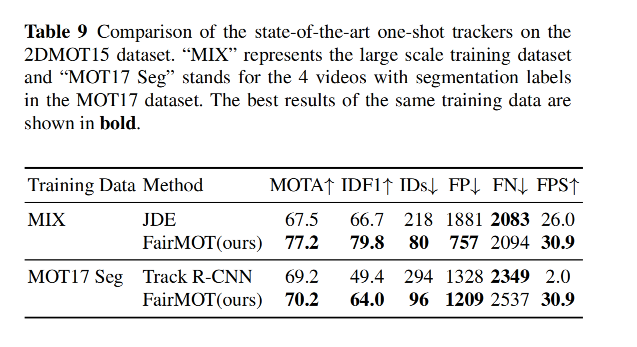
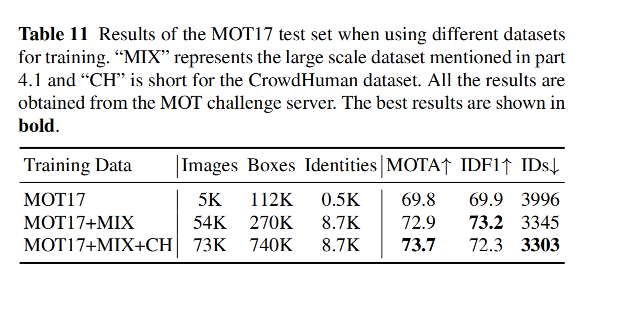
3.4 最终效果