文章目录
- 队列定义
- 队列应用
- 热土豆问题
- 打印任务
队列定义
队尾进,队头出
队列是一种有次序的数据集合,其特征是新数据项的添加总发生在一端(通常称为“尾rear”端)而现存数据项的移除总发生在另一端(通常称为“首front”端)
当数据项加入队列,首先出现在队尾,随着队首数据项的移除,它逐渐接近队首。
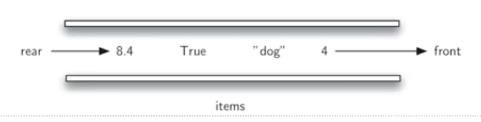
新加入的数据项必须在数据集末尾等待,而等待时间最长的数据项则是队首
这种次序安排的原则称为( FIFO:First-infirst-out)先进先出或“先到先服务first-come first-served”
- 队列的例子出现在我们日常生活的方方面面:排队队列仅有一个入口和一个出口
- 不允许数据项直接插入队中,也不允许从中间移除数据项
队列应用
-
打印队列:有任务在打印时,后来的打印请求排成队列FIFO
-
进程调度:原则综合了“先来先服务”
-
键盘缓冲:键盘敲击并不马上显示在屏幕上,而是将尚未敲击的字符暂存在队列性质缓冲区
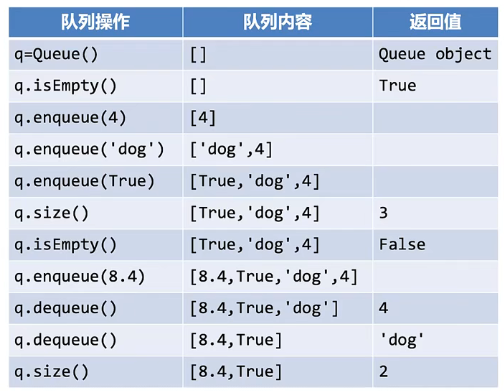
队列操作定义
- Queue():创建一个空队列对象,返回值为Queue对象;
- enqueue(item):将数据项item添加到队尾,无返回值;
- dequeue():从队首移除数据项,返回值为队首数据项,队列被修改;
- isEmpty():测试是否空队列,返回值为布尔值
- size():返回队列中数据项的个数
class Queue:
def __init__(self): # 默认列表最左边为队尾,最右边为队首
self.items = [] # 容纳Queue数据项
def is_empty(self):
return self.items == []
def size(self):
return len(self.items)
def enqueue(self, item): # O(n)
self.items.insert(0, item) # 添加到队尾
def dequeue(self): # O(1)
return self.items.pop() # 弹出队首数据项并返回值
队列应用
热土豆问题
类似击鼓传花
用队列来实现热土豆问题的算法,参加游戏的人名列表,以及传土豆次数num,算法返回最后剩下的人名
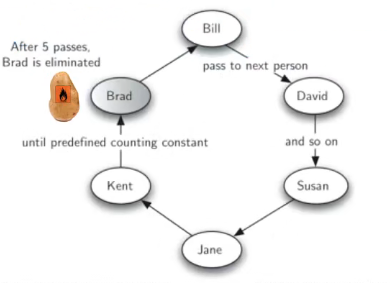
模拟算法
模拟程序采用队列来存放所有参加游戏的人名,按照传递土豆方向从队首排到队尾
- 游戏时,队首始终是持有土豆的人
模拟游戏开始,只需要将队首的人出队,随即再到队尾入队,算是土豆的一次
- 传递传递了num次后,将队首的人移除,不再入队如此反复,直到队列中剩余1人
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fp3d0EfO-1689843594037)(./image/image-20230720104036165.png)]
from queue import Queue
def hot_potato(name_list, num):
simqueue = Queue() # 创建一个空队列
for name in name_list: # 名字全部入列
simqueue.enqueue(name)
for i in range(num): # 进行一轮土豆传递
# 土豆默认在队首
simqueue.enqueue(simqueue.dequeue()) # 队首出列重新进队尾
while simqueue.size() > 1: # 一轮结束,队首持续出列,直至只剩一人为土豆持有者
simqueue.dequeue()
return simqueue.dequeue()
print(hot_potato(["bill", "hary", "gege", "hzh"], 7))
# gege
打印任务
多人共享打印机采取“先来先服务”的队列策略来执行打印任务
实例配置:
- 一个实验室,在任意的一个小时内,大约有10名学生在场,这一小时中,每人会发起2次左右的打印,每次1~20页
打印机的性能是:
- 以草稿模式打印的话,每分钟10页
- 以正常模式打印的话,打印质量好,但速度下降为每分钟5页。
问题建模
对象:打印任务、打印队列、打印机
- 打印任务的属性:提交时间、打印页数
- 打印队列的属性:具有FIFO性质的打印任务队列
- 打印机的属性:打印速度、是否忙

过程:生成和提交打印任务
- 确定生成概率:实例为每小时会有10个学生提交的20个作业,这样,概率是每180秒会有1个作业生成并提交,概率为每秒1/180。
- 确定打印页数:实例是120页,那么就是120页之间概率相同。

过程:实施打印
-
当前的打印作业:正在打印的作业
-
打印结束倒计时:新作业开始打印时开始倒计时,回0表示打印完毕,可以处理下一个作业
模拟时间:
-
统一的时间框架:以最小单位(秒)均匀流逝的时间,设定结束时间
-
同步所有过程:在一个时间单位里,对生成打印任务和实施打印两个过程各处理一次
模拟流程:
-
创建打印队列对象
-
时间按照秒的单位流逝
- 按照概率生成打印作业,加入打印队列,如果打印机空闲,且队列不空,则取出队首作业打印,记录此作业等待时间如果打印机忙,则按照打印速度进行1秒打印。如果当前作业打印完成,则打印机进入空闲
-
时间用尽,开始统计平均等待时间
-
作业的等待时间
-
生成作业时,记录生成的时间戳
-
开始打印时,当前时间减去生成时间即可
-
-
作业的打印时间
-
生成作业时,记录作业的页数
-
开始打印时,页数除以打印速度即可
-
打印机模拟代码
创建打印机类
from queue import Queue
import random
# 打印机类
class Printer:
def __init__(self, ppm):
self.pagerate = ppm # ppm:打印速度每分钟几张
self.current_task = None # 当前打印任务
self.time_remaining = 0 # 任务倒计时
def tick(self): # 打印一秒
if self.current_task != None:
self.time_remaining = self.time_remaining - 1
if self.time_remaining <= 0:
self.current_task = None
def busy(self): # 打印机是否忙
if self.current_task != None:
return True
else:
return False
def start_next(self, new_task): # 打印新作业
self.current_task = new_task # 将新任务设置为当前任务
self.time_remaining = new_task.get_pages() * 60 / self.pagerate # 任务所需时间:页数*60s/打印速度
创建任务类
# 任务类
class Task:
def __init__(self, time):
self.timestamp = time # 生成时间戳
self.pages = random.randrange(1, 21) # 随机生成打印页数
def get_stamp(self):
return self.timestamp
def get_pages(self):
return self.pages
def wait_time(self, currenttime):
return currenttime - self.timestamp # 当前时间-时间戳=等待时间
新打印任务
# 新打印任务
def new_print_task():
num = random.randrange(1, 181) # 1/180的概率生成作业
if num == 180:
return True
else:
return False
主函数:模拟打印任务
# 模拟
def simulation(num_seconds, pages_perminute): # 模拟时间,打印机模式(速度)
labprinter = Printer(pages_perminute) # 打印机对象
print_queue = Queue() # 打印队列
waiting_times = [] # 记录等待时间列表
# 模拟时间流逝
for current_second in range(num_seconds):
if new_print_task(): # 生成新作业
task = Task(current_second) # 生成一个任务对象
print_queue.enqueue(task) # 将任务入打印队尾
# 打印机空闲且打印队列有作业时,打印队列队首出队,变为新打印任务
if (not labprinter.busy()) and (not print_queue.is_empty()):
next_task = print_queue.dequeue()
waiting_times.append(next_task.wait_time(current_second)) # 将任务等待时间记录到列表
labprinter.start_next(next_task) # 打印机开始新任务
labprinter.tick() # 打印机打印一秒
# 打印平均等待时间
average_wait = sum(waiting_times) / len(waiting_times)
print("平均等待时间:%6.2f秒 任务剩余:%3d" % (average_wait, print_queue.size()))
测试结果:
按照每分钟打印5张速度,运行3600s(1小时),模拟运行3次
for i in range(10):
simulation(3600, 5)
# 平均等待时间:108.89秒 任务剩余: 0
# 平均等待时间: 44.33秒 任务剩余: 0
# 平均等待时间: 74.18秒 任务剩余: 0
# 平均等待时间: 77.48秒 任务剩余: 1
# 平均等待时间:167.89秒 任务剩余: 0
# 平均等待时间:170.67秒 任务剩余: 0
# 平均等待时间:137.10秒 任务剩余: 0
# 平均等待时间: 96.61秒 任务剩余: 3
# 平均等待时间:285.11秒 任务剩余: 0
# 平均等待时间:250.09秒 任务剩余: 1
ps:如果将打印机速度改成10张每分钟,等待时间会大大减少,任务也都无剩余,但是牺牲了打印质量
for i in range(10):
simulation(3600, 10)
# 平均等待时间: 24.18秒 任务剩余: 0
# 平均等待时间: 22.43秒 任务剩余: 0
# 平均等待时间: 6.05秒 任务剩余: 0
# 平均等待时间: 25.00秒 任务剩余: 0
# 平均等待时间: 25.71秒 任务剩余: 0
# 平均等待时间: 30.17秒 任务剩余: 0
# 平均等待时间: 9.41秒 任务剩余: 0
# 平均等待时间: 5.56秒 任务剩余: 0
# 平均等待时间: 7.86秒 任务剩余: 0
加粗样式