系列文章目录(更新中)
`
第一章deeplabv3+源码之慢慢解析 根目录(1)main.py–get_argparser函数
第一章deeplabv3+源码之慢慢解析 根目录(2)main.py–get_dataset函数
第一章deeplabv3+源码之慢慢解析 根目录(3)main.py–validate函数
第一章deeplabv3+源码之慢慢解析 根目录(4)main.py–main函数
第一章deeplabv3+源码之慢慢解析 根目录(5)predict.py–get_argparser函数和main函数
第二章deeplabv3+源码之慢慢解析 datasets文件夹(1)voc.py–voc_cmap函数和download_extract函数
第二章deeplabv3+源码之慢慢解析 datasets文件夹(2)voc.py–VOCSegmentation类
第二章deeplabv3+源码之慢慢解析 datasets文件夹(3)cityscapes.py–Cityscapes类
第二章deeplabv3+源码之慢慢解析 datasets文件夹(4)utils.py–6个小函数
第三章deeplabv3+源码之慢慢解析 metrics文件夹stream_metrics.py–StreamSegMetrics类和AverageMeter类
第四章deeplabv3+源码之慢慢解析 network文件夹(1)backbone文件夹(a1)hrnetv2.py–4个函数和可执行代码
第四章deeplabv3+源码之慢慢解析 network文件夹(1)backbone文件夹(a2)hrnetv2.py–Bottleneck类和BasicBlock类
第四章deeplabv3+源码之慢慢解析 network文件夹(1)backbone文件夹(a3)hrnetv2.py–StageModule类
第四章deeplabv3+源码之慢慢解析 network文件夹(1)backbone文件夹(a4)hrnetv2.py–[HRNet类]
第四章deeplabv3+源码之慢慢解析 network文件夹(1)backbone文件夹(b)mobilenetv2.py–[3个类,3个函数]
第四章deeplabv3+源码之慢慢解析 network文件夹(1)backbone文件夹©resnet.py–[2个类,12个函数]
第四章deeplabv3+源码之慢慢解析 network文件夹(1)backbone文件夹(d)xception.py–[3个类,1个函数]
第四章deeplabv3+源码之慢慢解析 network文件夹(2)_deeplab.py–[7个类和1个函数]
第四章deeplabv3+源码之慢慢解析 network文件夹(3)modeling.py–[15个函数]
第四章deeplabv3+源码之慢慢解析 network文件夹(4)utils.py–[2个类]
第五章deeplabv3+源码之慢慢解析 utils文件夹(1)ext_transforms.py.py–[17个类]
第五章deeplabv3+源码之慢慢解析 utils文件夹(2)loss.py–[1个类]
第五章deeplabv3+源码之慢慢解析 utils文件夹(3)scheduler.py–[1个类]
第五章deeplabv3+源码之慢慢解析 utils文件夹(4)utils.py–[1个类,4个函数]
第五章deeplabv3+源码之慢慢解析 utils文件夹(5)visualizer.py–[1个类]
总结
文章目录
- 系列文章目录(更新中)
- 前期准备和说明
- 总体目录
- \_\_init__.py
- backbone文件夹
- backbone文件夹中的\_\_init__.py
- hrnetv2.py的导入部分
- hrnetv2.py的非函数非类代码
- hrnetv2.py的4个函数
前期准备和说明
提示:源码众多,此次选这个版本pytorch版
- 本章是各类神经网络的代码,所以前期准备是已经了解过(最好是学习过)pytorch。此处对于新手同学推荐的是沐神的动手学深度学习。开篇前置链接,新手必学内容,再次强调一遍,推荐资源都是免费的。
- 知道深度学习,特别是卷积神经网络为基础的系列网络的构建理论。
- 本章应该是新手同学最为关心的章节,建议有足够的耐心看全部补充链接。
- 每次只说一个函数,进度足够慢,尽量足够简单。
总体目录
提示:network文件夹总体结构如下。
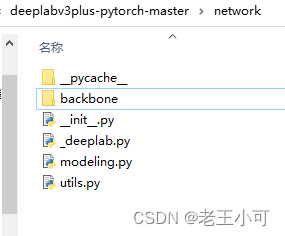
- 先介绍以下整体结构和__init__.py。
- 然后按顺序,本章从backbone文件夹,也就是主干网络(骨干网络)开始。
- 本章是全部代码中最长的章节,后续按函数和类进行内容安排,遇到长的类和函数,一节讲一个,体现deeplab慢慢学系列的初心。
__init__.py
from .modeling import *
from ._deeplab import convert_to_separable_conv
1.按显示顺序,modeling.py和_deeplab.py在backbone文件夹结束后再做详解。
backbone文件夹
提示: backbone文件夹总体结构如下。
- 本文件夹内虽然只有4个主要的python文件,但涉及的内容稍多,目的以详解为主,时间可能会有点长,望大家见谅。
- 题外话:学习靠日积月累,而不是突击。也许这是目前反主流的观点,但本系列目的一是讲东西,二就在于传播一些我认为有用的观念吧。
backbone文件夹中的__init__.py
from . import resnet
from . import mobilenetv2
from . import hrnetv2
from . import xception
1.简单明了,对外而言,确实就是这个四个模块。
hrnetv2.py的导入部分
#简简单单,torch的各种基本功能
import torch
from torch import nn
import torch.nn.functional as F
import os
1.简单明了,对外而言,确实就是这个四个模块。
2.传统的卷积神经网络模型常常存在多个下采样的过程,输入进来的图片利用卷积或者最大池化进行高和宽的压缩。HRNet则通过下采样以及上采样,在网络进行特征提取时融合不同形状的特征。HRNetV2可以适应不同任务的需要,语义分割就是其中之一。HRNet提取出来的特征极其丰富,包含各种的分辨率,理论上可以适应不同的CV需求(目标检测、语义分割、实例分割等)。整个HRNetV2由三部分组成,分别是主干部分、特征整合部分、预测头部分。详情后补链接。
3.理论不清楚的建议一定先高清楚,代码仅仅是对理论的实现,想真正搞清楚的必须看,切记切记!
hrnetv2.py的非函数非类代码
提示:hrnetv2.py包含4个类,4个函数,和其他可执行代码。先介绍非函数非类的代码。
1,文件开头的代码
__all__ = ['HRNet', 'hrnetv2_48', 'hrnetv2_32'] #一共有三种结构可选。
# Checkpoint path of pre-trained backbone (edit to your path). Download backbone pretrained model hrnetv2-32 @
# https://drive.google.com/file/d/1NxCK7Zgn5PmeS7W1jYLt5J9E0RRZ2oyF/view?usp=sharing .Personally, I added the backbone
# weights to the folder /checkpoints
model_urls = {
'hrnetv2_32': './checkpoints/model_best_epoch96_edit.pth', #源代码中保存hrnetv2_32模型的位置。
'hrnetv2_48': None
}
2,文件结尾的代码
if __name__ == '__main__': #单独运行本代码使用,被别的模块调用时不起作用。先学好python,切记!
try: #此段是检测要载入的模型文件是否存在。
CKPT_PATH = os.path.join(os.path.abspath("."), '../../checkpoints/hrnetv2_32_model_best_epoch96.pth')
print("--- Running file as MAIN ---")
print(f"Backbone HRNET Pretrained weights as __main__ at: {CKPT_PATH}")
except:
print("No backbone checkpoint found for HRNetv2, please set pretrained=False when calling model")
# Models
model = hrnetv2_32(pretrained=True) #使用与训练模型,详见hrnetv2_32函数。
#model = hrnetv2_48(pretrained=False)
if torch.cuda.is_available(): #GPU可用则用,不可用则用CPU。
torch.backends.cudnn.deterministic = True
device = torch.device('cuda')
else:
device = torch.device('cpu')
model.to(device)
in_ = torch.ones(1, 3, 768, 768).to(device) #用全1输入测试输出。
y = model(in_)
print(y.shape)
# Calculate total number of parameters:
# pytorch_total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
# print(pytorch_total_params)
hrnetv2.py的4个函数
提示:hrnetv2.py包含4个函数,相对简单。
1,文件开头的函数
def check_pth(arch): #检查路径。
CKPT_PATH = model_urls[arch] #从前文的model_urls字典中选择具体的模型路径。
if os.path.exists(CKPT_PATH):
print(f"Backbone HRNet Pretrained weights at: {CKPT_PATH}, only usable for HRNetv2-32")
else:
print("No backbone checkpoint found for HRNetv2, please set pretrained=False when calling model")
return CKPT_PATH
# HRNetv2-48 not available yet, but you can train the whole model from scratch.
2,文件末尾的函数
def _hrnet(arch, channels, num_blocks, pretrained, progress, **kwargs):
model = HRNet(channels, num_blocks, **kwargs) #详见HRNet类。
if pretrained: #如使用预训练模型,则检验路径,载入模型。
CKPT_PATH = check_pth(arch) #详见上文check_pth函数。
checkpoint = torch.load(CKPT_PATH)
model.load_state_dict(checkpoint['state_dict'])
return model
def hrnetv2_48(pretrained=False, progress=True, number_blocks=[1, 4, 3], **kwargs):
w_channels = 48 #hrnetv2_48,即w_channels = 48。
return _hrnet('hrnetv2_48', w_channels, number_blocks, pretrained, progress,
**kwargs)
def hrnetv2_32(pretrained=False, progress=True, number_blocks=[1, 4, 3], **kwargs):
w_channels = 32 #hrnetv2_32,即w_channels = 32。
return _hrnet('hrnetv2_32', w_channels, number_blocks, pretrained, progress,
**kwargs)
Tips
-
补充,很喜欢这位大佬的风格,个人推荐HRNetV2详解。
-
本节讲述了除了类代码以外的所有部分,是整体性的介绍。
-
下一个节介绍hrnetv2.py中的类。