数值常用操作
python常用关于数值,数学常用的模块:math(数学),random(随机),numpy(科学计算),pandas(数据读写,数据分析)
| 函数 | 描述 |
|---|---|
| int(x) | 将x转换为一个整数。 |
| float(x) | 将x转换到一个浮点数。 |
| abs(x) | 求数字x的绝对值 |
| math.ceil(x) | 对数字x进行向上取整 |
| math.floor(x) | 对数字x进行地板取整 |
| max(a, b,c,…) | 求指定参数的最大值。 |
| min(a, b,c,…) | 求指定参数的最小值。 |
| math.modf(x) | 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。 |
| pow(x, y) | x的y次幂运算后的结果,等价于x**y。 |
| round(x [,n]) | 返回浮点数 x 的四舍五入值,如给出 n 值,则代表保留小数点后的位数。 |
| math.sqrt(x) | 返回数字x的平方根。 |
| random.choice(seq) | 从序列中随机挑选一个成员 |
| random.random() | 随机生成一个[0,1)范围的实数。 |
| random.randint(x,y) | 随机生成一个[x,y]范围的整数。 |
| random.shuffle(list) | 将序列的所有元素随机排序 |
"""int(x) 将x转换为一个十进制整数。"""
# 字符串转整数,字符串只能由数字组成的
# s1 = "35"
# data = int(s1)
# print(data, type(data))
# 可以把其他的进制数值字符串转换成十进制整数
# s2 = "0b1010"
# # s2 = "1010"
# data = int(s2,base=2)
# print(data, type(data))
"""float(x) 将x转换到一个浮点数。"""
# s2 = "3.5"
# data = float(s2)
# print(data, type(data))
"""abs(x) 求绝对值 |x|"""
# num1 = 100
# data = abs(num1)
# print(data) # 100
#
# num2 = -10
# data = abs(num2)
# print(data) # 10
"""int 取整"""
# num0 = 3.999999999
# data = int(num0)
# print(data) # 3
#
# num1 = 3.99999999999999999999
# data = int(num1)
# print(data) # 4
"""ceil 向上取整"""
# 表示引入数学模块(python文件)
# import math
# num0 = 3.1
# data = math.ceil(num0)
# print(data) # 4
#
# num0 = 3.9
# data = math.ceil(num0)
# print(data) # 4
#
#
# num0 = 3.0
# data = math.ceil(num0)
# print(data) # 3
"""floor 向下取整(地板取整)"""
# import math
# num0 = 3.1
# data = math.floor(num0)
# print(data) # 3
#
# num0 = 3.9
# data = math.floor(num0)
# print(data) # 4
#
#
# num0 = 3.0
# data = math.floor(num0)
# print(data) # 3
"""round 四舍五入取整"""
# num0 = 3.1
# data = round(num0)
# print(data) # 3
#
# num0 = 3.9
# data = round(num0)
# print(data) # 4
#
#
# num0 = 3.5
# data = round(num0)
# print(data) # 4
# """取最大数值"""
# ret = max(10, 12, 15, 20)
# print(ret) # 20
#
# """取最小数值"""
# ret = min(10, 12, 15, 20)
# print(ret) # 10
"""max和min也可以从字符串中提取最大值,类似 字符串比较,是编码位置的比较,原因是max和min内部就是使用比较运算符来处理的"""
# ret = max("A", "a", "c", "C")
# print(ret) # c
#
# """取最小数值"""
# ret = min("A", "a", "c", "C")
# print(ret) # A
"""提取一个数字的整数部分和小数部分"""
# import math
# ret = math.modf(3.1415) # (浮点数部分,整数部分)
# print(ret) # (0.14150000000000018, 3.0)
"""pow 幂运算"""
# print(pow(2,3)) # 8 相当于2**3次方
"""sqrt 平方根"""
# import math
# data = math.sqrt(4)
# print(data) # 2.0
"""随机数"""
import random
# 生成一个0~1之间的随机实数 [0,1) 不包含1
# data = random.random()
# print(data)
# 生成一个指定范围[a,b]的随机整数
# data = random.randint(1,100)
# print(data)
# choice 随机抽取一个成员
# data = ["A", "B", "C"]
# ret = random.choice(data)
# print(ret)
# 随机打乱序列的成员排列顺序,这个shuffle在很多编程语言里面都有,是基于洗牌算法实现的。
# data = ["A", "B", "C"]
# random.shuffle(data) # 注意:此处不需要写等号了,
# print(data)
字符串常用操作
python中常见的用于处理文本的操作模块:string字符串本身操作,re模块(RegExp正则),xpath,bs4
| 方法 | 描述 |
|---|---|
| string.capitalize() | 把字符串的第一个字符大写 |
| string.count(str, beg=0, end=len(string)) | 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
| string.decode(encoding=‘UTF-8’, errors=‘strict’) | 以 encoding 指定的编码格式解码 string,如果出错默认报一个 ValueError 的 异 常 , 除非 errors 指 定 的 是 ‘ignore’ 或 者’replace’ |
| string.encode(encoding=‘UTF-8’, errors=‘strict’) | 以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是’ignore’或者’replace’ |
| string.startswith(obj, beg=0,end=len(string)) | 检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查. |
| string.endswith(obj, beg=0, end=len(string)) | 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. |
| string.find(str, beg=0, end=len(string)) | 检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
| string.format() | 格式化字符串 |
| string.index(str, beg=0, end=len(string)) | 跟find()方法一样,只不过如果str不在 string中会报一个异常. |
| string.isdecimal() | 如果 string 只包含十进制数字则返回 True 否则返回 False. |
| string.isdigit() | 如果 string 只包含数字则返回 True 否则返回 False. |
| string.isspace() | 如果 string 中只包含空格,则返回 True,否则返回 False. |
| string.join(seq) | 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
| string.split(str=“”, num=string.count(str)) | 以 str 为分隔符切片 string,如果 num 有指定值,则仅分隔 num+1 个子字符串 |
| string.splitlines([keepends]) | 按照行(‘\r’, ‘\r\n’, ‘\n’)分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
| string.lower() | 转换 string 中所有大写字符为小写. |
| string.upper() | 转换 string 中的小写字母为大写 |
| string.title() | 返回"标题化"的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
| string.strip() | 删除 string 字符串两边连续的空格. |
| string.lstrip() | 删除 string 字符串左边开头的空格 |
| string.rstrip() | 删除 string 字符串右边末尾的空格. |
| max(str) | 返回字符串 str 中最大的字母。 |
| min(str) | 返回字符串 str 中最小的字母。 |
| string.replace(str1, str2, num=string.count(str1)) | 把 string 中的 str1 替换成 str2,如果指定 num,则替换不超过 num 次. |
# 基于%号+占位符,实现格式化输出
# 要输出一个数字
# num = 10
# print("WD%04d" % num)
# # 格式化输出浮点数
# num = 3.5
# print("%.2f元" % num)
# 输出一个普通字符串
# s1 = "hello"
"""
字符串.capitalize()
字符串首个字母大写,如果字符串首个字符不是字母,则不会转换大写
"""
# s1 = "10hello world"
# print(s1)
# ret = s1.capitalize()
# print(ret)
"""
字符串.count(字符子串)
统计子串在字符串中出现的次数
"""
# s1 = "hello world"
# ret = s1.count("l")
# print(ret) # 3
"""
字符串.encode() # 编码,把一个字符串转换二进制安全格式字符串(bytes类型)
字符串.decode() # 解码,把一个二进制安全格式字符串转成普通字符串
encode和decode() 默认都有个encding参数选项用于设置当前字符串的编码类型,默认是utf-8
常见于:网络传输的数据,跨平台传输的数据,从内存、硬盘中读取的数据、加密解密都可能是bytes
"""
# s1 = "中文"
# data = s1.encode()
# print(data) # b'\xe4\xb8\xad\xe6\x96\x87'
# #
# # # 声明一个bytes字符串
# s2 = b'\xe4\xb8\xad\xe6\x96\x87'
# data = s2.decode()
# print(data) # hello
# # encode也可以用于转换字符编码
# s1 = "中文"
# data = s1.encode(encoding="gbk")
# print(data) # b'\xce\xc4\xd7\xd6'
#
# # 如果字符串在编码的时候,设置了非utf-8,则字符串在解码的时候,也要使用对应的非utf-8编码,否则python会报UnicodeDecodeError编码解码错误!!!
# s2 = b'\xa4\xa4\xa4\xe5'
# data = s2.decode(encoding="gbk")
# print(data)
"""
字符串.endswith(字符子串) # 判断字符串是否以字符子串结尾
字符串.startswith(字符子串) # 判断字符串是否以字符子串开头
字符串.find(字符子串) # 获取字符子串在字符串的下标位置,找不到结果为-1,找到则返回首次出现的下标位置,从0开始[不报错!]
字符串.index(字符子串) # 获取字符子串在字符串的下标位置,找不到则报错,找到则返回首次出现的下标位置,从0开始[报错!]
"""
# 判断某个人是否姓张
# name = "王晓明"
# if name.startswith("张"):
# print("你好,张先生!!")
# 判断某个人的名字里面是否有"明"
# name = "王晓明"
# ret = name.find("张") # -1
# print( ret )
# ret = name.find("王") # 0
# print( ret )
#
# ret = name.find("明") # 2
# print( ret )
# 判断某个人的名字是否以"明"结尾
# name = "王晓明"
# ret = name.endswith("明")
# print( ret )
# 判断是否是QQ邮箱
# mail = "1234@qq.com"
# ret = mail.endswith("qq.com")
# print(ret) # True
# 判断是否是一个合法的邮箱
# mail = "1234@qq.com"
# ret1 = mail.index("@")
# print(ret1) # 4
# ret2 = mail.index(".")
# print(ret2) # 7
# if ret1 < ret2:
# print("邮箱合法!") # 以后用正则判断更为准确!当然要最准确的话,就要通过发送邮件来证明
"""注意:find默认从左往右查找子串出现的第一个位置,如果希望从右往左查,则使用rfind"""
# s1 = "hello world"
# index = s1.find("l")
# print(index) # 2
#
# s1 = "hello world"
# index = s1.rfind("l")
# print(index) # 9
"""
判断字符串的组成成分
字符串.isalnum() 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True
"""
# s1 = "hello100"
# ret = s1.isalnum()
# print(ret) # True
#
# s1 = "hello+100"
# ret = s1.isalnum()
# print(ret) # False
"""
字符串.isdecimal() 如果 string 只包含十进制数字则返回 True 否则返回 False.
"""
# s1 = "123kl5k23k34"
# ret = s1.isdecimal()
# print(ret) # False
#
# # s1 = "12352.334" # 这种也为False
# s1 = "12352334" # 这种才是True
# ret = s1.isdecimal()
# print(ret) # False
#
"""
字符串.isspace() # 判断是否是空白字符串,空格字符串
"""
# s1 = "" # 空字符串,False
# ret = s1.isspace()
# print(ret)
#
# s1 = " " # 空格组成的,True
# ret = s1.isspace()
# print(ret)
"""
字符串 分割与合并
子串.join(序列) # 合并序列中每一个成员,使用指定子串进行拼接一个字符串
字符串.split(子串) # 使用子串作为分隔符,把字符串按子串分割成多段,组成一个列表[列表至少有一个成员]
字符串 转 列表 ---> 分割
列表/元组 转 字符串 ---> 合并
"""
# data = ["北京市", "昌平区", "白沙路"]
# ret = "--".join(data)
# print(ret)
# s1 = "北京市-昌平区-白沙路"
# ret = s1.split("-")
# print(ret) # ['北京市', '昌平区', '白沙路']
# # 如果无法分割,也不会报错,但是会把整个字符串作为一个整体,保存到列表中作为一个成员
# s1 = "北京市-昌平区-白沙路"
# ret = s1.split(":")
# print(ret) # ['北京市-昌平区-白沙路']
"""
字符串.splitlines() 按行分割
"""
# 假设这个字符串是在一个文件中读取出来
# content = """君不见黄河之水天上来,奔流到海不复回。
# 君不见高堂明镜悲白发,朝如青丝暮成雪。
# 人生得意须尽欢,莫使金樽空对月。
# 天生我材必有用,千金散尽还复来。
# 烹羊宰牛且为乐,会须一饮三百杯。
# 岑夫子,丹丘生,将进酒,杯莫停。
# 与君歌一曲,请君为我倾耳听。
# 钟鼓馔玉不足贵,但愿长醉不复醒。"""
#
# for item in content.splitlines():
# print(">>> ", item)
"""
字母转换大小写
字符串.lower() # 把字符串中的英文字母转换成小写
字符串.upper() # 把字符串中的英文字母装换成大写
字符串.title() # 按广告标题格式,把字符串那种所有单词的首字母转换成大写
"""
# s1 = "get"
# ret = s1.upper()
# print(ret) # GET
#
# s2 = "POST"
# ret = s2.lower()
# print(ret) # post
# s3 = "hello world"
# ret = s3.title()
# print(ret) # Hello World
"""
字符串.strip() # 去除字符串的两边空格,注意:字符串中间的空格不会被删除,只会删除两边连续的空格
字符串.lstrip() # 去除字符串的左边空格,注意:字符串中间的空格不会被删除,只会删除左边连续的空格
字符串.rstrip() # 去除字符串的右边空格,注意:字符串中间的空格不会被删除,只会删除右边连续的空格
"""
# s1 = "hello world"
# print(len(s1), s1)
#
# s2 = " hello wolrd "
# ret = s2.strip()
# print(len(ret), ret)
#
# s2 = " hello wolrd "
# ret = s2.lstrip()
# print(len(ret), ret)
#
# s2 = " hello wolrd "
# ret = s2.rstrip()
# print(len(ret), ret)
"""
字符串替换
字符串.replace(旧子串, 新子串, 替换次数)
"""
# 默认是全部替换
s1 = "python37 python37"
# 把 python 换成 java
ret = s1.replace("python", "java")
print(ret) # java37 java37
# 也可以指定替换次数
s1 = "python37 python37"
# 把 python 换成 java
ret = s1.replace("python", "java", 1)
print(ret) # java37 python37
字符串格式化输出
format格式化
通过 {} 和 : 来代替以前的 % 。
"{} {}".format("hello", "world") # # 不设置指定位置,按默认顺序
"{0} {1}".format("hello", "world") # 设置指定位置
"{1} {0} {1}".format("hello", "world") # 设置指定位置
"姓名:{name}, 性别:{sex}".format(name="小明", sex="男") # 指定变量
"姓名:{name}, 性别:{sex}".format(**{"name": "小明", "sex": "男"}) # 星星打散字典进行key指定值
"姓名:{0[0]}, 性别:{0[1]}".format(['",', '男']) # 基于列表索引指定参数,"0" 是必须的
"{:.2f}".format(3.1415926) # 浮点数格式化
"{:.2%}".format(0.14) # 百分比格式化
"{} 对应的位置是 {{0}}".format("小明")
f字符串
f字符串,也叫字面量格式化字符串,是python3.6版本以后推出的格式化方式。
以 f 开头,后面跟着字符串,字符串中的表达式用大括号 {} 包起来,python会将变量或表达式计算后的值替换到字符串中。
name = "小名"
print(f"我叫{name}") # 我叫小名
# 输出复核类型数据,直接在{}里面写上中括号即可
data = {"name": "小明", "sex": "男"}
print(f"姓名:{data['name']}, 性别:{data['sex']}")
# 姓名:小明, 性别:男
x = 1
y = 0.14
print(f"{x:.2f} {y:.2%}") # 1.00 14.00%
# python3.8以后,新增了一个表达式结果输出的省略写法
x = 10
y = 20
print(f"{x+y}") # 30
print(f"{x+y=}") # x+y=30
# 整数补0
x = 8
print(f"{x:02d}") # 01
列表常用操作
| 函数 | 描述 |
|---|---|
| len(list) | 列表元素个数 |
| max(list) | 返回列表元素最大值 |
| min(list) | 返回列表元素最小值 |
| list(seq) | 将元组、集合、转换为列表 |
| 方法 | 描述 |
|---|---|
| list.insert(index, obj) | 将对象插入列表中指定下标位置 |
| list.append(obj) | 在列表末尾添加新的成员 |
| list.count(obj) | 统计某个元素在列表中出现的次数 |
| list.extend(seq) | 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| list.index(obj) | 从列表中找出某个值第一个匹配项的索引位置 |
| list.pop([index=-1]) | 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值,按下标删除 |
| list.remove(obj) | 移除列表中左起第一个出现指定成员,按值删除 |
| list.reverse() | 反转排列列表中元素 |
| list.sort( key=None, reverse=False) | 对原列表进行排序 |
| list.clear() | 清空列表 |
| list.copy() | 浅复制列表 |
# 列表操作
"""计算列表成员数量"""
# data = [1,2,3]
# print(len(data)) # 3
"""计算最大值,最小值"""
# data = [11,2,13]
# ret = max(data)
# print(ret) # 13
#
# ret = min(data)
# print(ret) # 2
# 特殊情况:
# data = [11, "2", 13]
# ret = max(data)
# print(ret) # 因为max和min内部使用了大小于号来比较的,所以如果一个列表中出现了不同数据类型,则无法计算最大最小值,反而报错
"""
添加成员
列表.append(成员) # 列表末尾追加成员
列表.insert(index, 成员) # 在列表中下标位置初插入成员,插入以后,原下标对应的成员往后排序
"""
# data = ["小明", "小黑", "小红"]
# data.append("小白")
# print(data) # ['小明', '小黑', '小红', '小白']
#
# data = ["小明", "小红", "小白"]
# data.insert(0, "小黑")
# print(data) # ['小黑', '小明', '小红', '小白']
"""
列表修改成员的值
"""
# data = ["xiaoming", "xiaohong", "小白"]
# # 通过指定下标即可修改~!前提是下标存在!
# data[-1] = "xiaobai"
# print(data)
#
# data[4] = "xiaolan"
# print(data) # IndexError: list assignment index out of range
"""
列表.count(成员)
统计列表中指定成员的数量
"""
# data = ["A", "B", "C", "A", "D", "A"]
# ret = data.count("A")
# print(ret) # 3
"""
列表.extend(序列)
合并列表,把第二个列表的成员合并到第一个列表
"""
# data = ["A", "B", "C"]
# print(id(data), data)
# data.extend(["X", "Y", "Z"])
# print(data) # ['A', 'B', 'C', 'X', 'Y', 'Z']
# print(id(data), data) # 从这里可以看到,data还是原来的data,并没有产生新的数据,还是使用原来的内存。
"""
列表.index() 查找成员下标
不存在,会报错,ValueError: 'W' is not in list
存在,则返回当前成员在列表左起出现的第一个下标
"""
# data = ["A", "B", "C", "A"]
#
# # ret = data.index("W")
# # print(ret) # 不存在,会报错,ValueError: 'W' is not in list
#
# ret = data.index("A")
# print(ret) # 0
"""
剔除成员,默认情况下剔除最后一个成员,也可以通过index选项剔除指定成团
在数据结构中,pop操作剔除最后一个成员这种操作,也被称之为"出栈"
列表.pop([index=-1])
[index=-1] 中括号表示当前index选项属于可选选项,index不填的情况默认值为-1
"""
# data = ["A", "B", "C", "D"]
# item = data.pop()
# print(item) # D
# item = data.pop()
# print(item) # C
# item = data.pop()
# print(item) # B
# item = data.pop()
# print(item) # A
# item = data.pop()
# print(item) # 针对空列表,不能使用pop会报错!!!!IndexError: pop from empty list
# 也可以基于pop删除指定下标的成员
# data = ["A", "B", "C", "D"]
# ret = data.pop(1)
# print(ret) # B
# print(data) # ["A", "C", "D"]
"""
小明的面试题:基于循环在列表中偶数成员
"""
# 第一步,取出所有成员
# data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# for i in range(len(data)):
# print(i, data[i])
# 第二步,判断成员是否是偶数
# data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# for i in range(len(data)):
# if data[i] % 2 == 0:
# print(data[i])
# 第三步,删除if代码块中成员,报错
# data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# for i in range(len(data)):
# if data[i] % 2 == 0:
# data.pop(i)
#
# print(data) # IndexError: list index out of range
"""
首先,列表本身是可变类型,所以内部成员会发生改变,但是内部成员的下标不是固定的,而是通过排列得到的,
所以当我们使用循环基于正序进行成员删除时,没删除一个成员,后面的所有成员都会往前排列,占据被删除的成员下标
"""
"""一个不成熟的解决方案,还是有bug,但是解决报错的问题"""
# data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# for item in data:
# if item % 2 == 0:
# data.remove(item)
#
# print(data) # [1, 3, 5, 7, 9]
"""上面看似已经解决了问题,实际上并没有真的解决掉,当列表的数字是乱序的"""
# data = [2, 1, 5, 3, 6, 4, 7, 8, 9, 10]
# for item in data:
# if item % 2 == 0:
# data.remove(item)
#
# print(data) # [1, 5, 3, 4, 7, 9]
"""
列表只要在循环中进行正序删除(从左往右)都会存在这样的成员下标前置的问题,导致产生结果,与我们所期望的不一样。
所以,我们要改成逆序删除(从右往左)
"""
# data = [2, 1, 5, 3, 6, 4, 7, 8, 9, 10]
# length = len(data)
# for i in range(length-1, -1, -1):
# if data[i] % 2 == 0:
# data.pop(i)
#
# print(data) # [1, 5, 3, 7, 9]
"""除了基于逆序删除以外,还有第二个方案可以解决上面正序删除的BUG, 思路:根据正序删除的BUG出现原因,是因为列表本身的成员下标变动导致的"""
# data = [2, 1, 5, 3, 6, 4, 7, 8, 9, 10]
# new_data = []
# for i in data:
# if i % 2 != 0:
# new_data.append(i)
#
# print(new_data) # [1, 5, 3, 7, 9]
"""
列表.reverse()
"""
# data = [2, 1, 5, 3, 6, 4, 7, 8, 9, 10]
# data.reverse()
# print(data) # [10, 9, 8, 7, 4, 6, 3, 5, 1, 2]
"""
打乱列表,对列表进行洗牌
"""
# import random
# data = [1, 3, 5, 7, 9]
# random.shuffle(data)
# print(data) # [1, 9, 3, 5, 7]
"""
列表排序[基础]
默认是正序排序,可以通过reverse选项设置为True,表示逆序排序
列表.sort() # 正序排序,从小到大
列表.sort(reverse=True) # 逆序排序,从大到小
"""
# data = [9, 5, 1, 3, 7]
# data.sort()
# print(data) # [1, 3, 5, 7, 9]
# data = ["A", "D", "B", "E", "C"]
# data.sort()
# print(data) # ['A', 'B', 'C', 'D', 'E']
# 特殊情况:sort排序也是基于大小于号进行先后排序的,所以列表中存在不同类型数据时。会报错。
# data = ["A", "D", 9, 5, 1, "B", "E", "C"]
# data.sort()
# print(data) # TypeError: '<' not supported between instances of 'int' and 'str'
# 匿名函数 lambda
"""逆序排序"""
# data = [20, 13, 9, 5, 1, 11, 78, 1]
# data.sort(reverse=True)
# print(data) # [78, 20, 13, 11, 9, 5, 1, 1]
"""
学了后面的匿名函数以后,排序的代码可以长这样的
"""
# data = ["A", "D", 9, 5, 1, "B", "E", "C"]
# data.sort(key=lambda a: str(a))
# print(data) # [1, 5, 9, 'A', 'B', 'C', 'D', 'E']
"""
清空列表
列表.clear()
"""
# data = ["A", "B"]
# data.clear()
# print(data) # [],清空成员,但是还是在内存中保留了列表的内容空间
#
# # 列表.clear() 和 del 列表 的区别
# data = ["A", "B"]
# del data
# print(data) # del删除的是内存空间,所以一旦执行以后,连变量都没有了,后面使用需要重新赋值,否则报错
"""
复制列表(copy浅拷贝)
"""
# data1 = ["A", "B"]
# data2 = data1
# print("data2=", data2) # ['A', 'B']
# data2[1] = "C"
# print("data2=", data2) # ['A', 'C']
# print("data1=", data1) # ['A', 'C'],这里出现了当data2改变了成员以后,data1也被改变了。
#
# """
# 深拷贝和浅拷贝
# 赋值和引用的区别
# """
# 基于copy可以复制一个列表,可以某种程度上解决上面的BUG,但是某些特殊情况下还是有BUG的
data1 = ["A", "B"]
data2 = data1.copy()
print("data2=", data2) # data2= ['A', 'B']
data2[1] = "C"
print("data2=", data2) # data2= ['A', 'C']
print("data1=", data1) # data1= ['A', 'B']
引用与赋值
在使用list.copy操作这个过程中,我们需要了解列表赋值带来的问题。
在其他的编程语言(golang,java,php)中赋值实际上就是开辟了一个新的内存空间,把数据保存到了这个内存空间里面。但是在python是不存在这种情况的。
关于python中的=号赋值,实际上这种赋值是一种共享内存的引用赋值。所以可以这么说,python中根本没有其他语言的赋值这回事,全部都是引用操作。
# python中的变量在第一次出现时,直接赋值,这个过程就是创建一个内存空间,并把数据保存进去。
# num = 3
#
# # 但是,如果该变量赋值过程中,=号右边的不是一个新数据,而是已经在内存中出现过的数据/变量,则这个过程是不会占用新的内存空间的。
# num1 = num
# print(num, id(num))
# print(num1, id(num))
#
# num1 = 4
# print(num1) # 4
# print(num) # 3
# 这里重新修改了变量的指向,这里为什么num不跟着一起变化呢?原因是因为小数据池的机制导致的。
# 因此形成的效果在于如果变量的值是一个数值、字符串类型,那么变量改值就会发生变量指向到其他的内存空间,但是不影响引用的变量。
# 但是,针对于一些复杂的数据结构:字典,列表,集合,这几种就有区分了。
# data1 = [1,2,3]
# data2 = data1
# data2.append(4)
# print(id(data2), data2) # 2722959468672 [1, 2, 3, 4]
# print(id(data1), data1) # 2722959468672 [1, 2, 3, 4]
# 除了列表出出现这种情况,字典,集合有这种情况。
# 字典
# data1 = {"id":1, "title":"商品标题1"}
# data2 = data1
# data2["price"] = 99
# print(id(data2), data2) # 2404875316608 {'id': 1, 'title': '商品标题1', 'price': 99}
# print(id(data1), data1) # 2404875316608 {'id': 1, 'title': '商品标题1', 'price': 99}
# 集合
data1 = {"A", "B", "C"}
data2 = data1
data1.remove("A")
print(id(data2), data2) # 2697375590432 {'C', 'B'}
print(id(data1), data1) # 2697375590432 {'C', 'B'}
python中根本没有传值赋值,只有引用赋值。所谓引用赋值,就是多个变量共享一个内存地址,其中一个变量值发生更改,会导致指向该空间的其他变量的值也变化了。
浅拷贝与深拷贝
浅拷贝也叫浅复制,是编程语言中针对引用类型数据提供的一种表层复制数据的功能。
深拷贝也叫深复制,是编程语言总针对应用类型数据提供的一种深层复制数据的功能。
浅拷贝代码的问题
# 二级以上的列表[二维列表]
data1 = [1,[4,5,6],[8,9]]
data2 = data1.copy()
print(id(data2), data2) # 2085906686784 [1, [4, 5, 6], [8, 9]]
data2[0] = 2
data2[1].append(7)
print(id(data2), data2) # 2085906686784 [2, [4, 5, 6, 7], [8, 9]]
print(id(data1), data1) # 2085906687168 [1, [4, 5, 6, 7], [8, 9]]
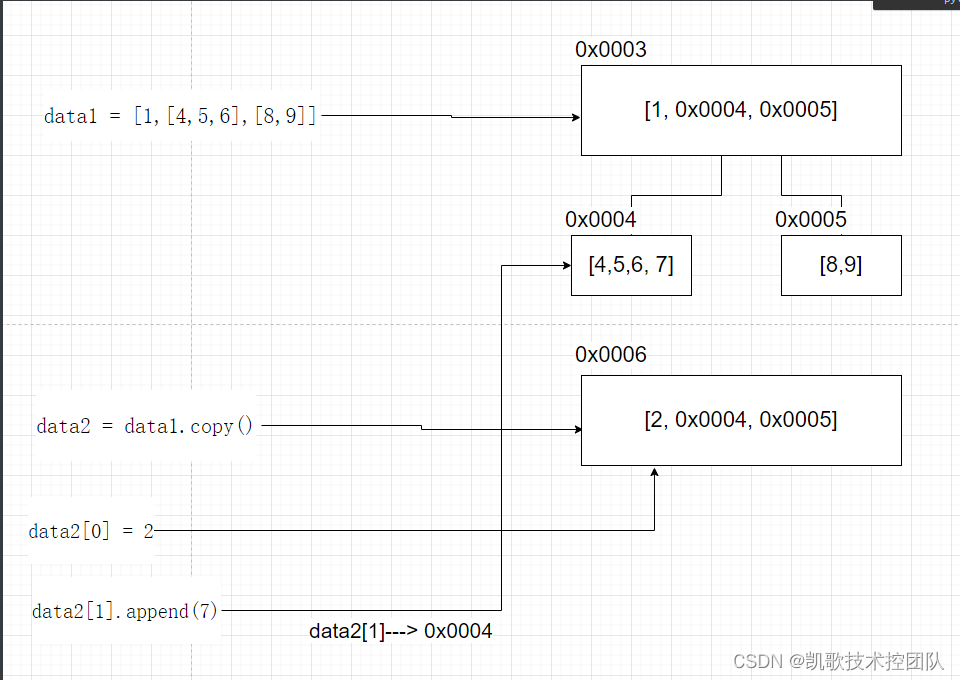
不仅列表有,字典和集合也有存在这个隐患。
要解决这个问题就必须使用深拷贝来对二级以上的复合类型数据来进行复制。
在python中除了可变数据类型(列表,集合,字典)本身提供的copy操作可以进行浅拷贝以外,还提供了一个copy模块给开发者进行数据的浅拷贝和深拷贝。
# copy模块
# copy方法,用于浅拷贝
import copy
data1 = [1 , 2 ,3 , 4 ]
data2 = copy.copy(data1)
data2.append(6)
print(data1)
# 深拷贝
# deepcopy方法,用于深拷贝
import copy
data1 = [1,2,3,4,[5,6,7]]
data2 = copy.deepcopy(data1)
data1[-1].append(19)
print(data2)
# 二级容器
data1 = {"a":[1,2,3,4],"b":{"c":1,"d":2}}
data2 = copy.deepcopy(data1)
data1["b"]["ee"] = "大风车"
print(data1)
print(data2)
元组常用操作
元组的基本操作与列表是一样的。对于操作来说,元组只有count和index操作。
集合常用操作
特点:去重,无序。
集合内置方法完整列表
| 方法 | 描述 |
|---|---|
| add() | 为集合添加元素 |
| update() | 给集合添加元素 |
| clear() | 移除集合中的所有元素 |
| copy() | 浅拷贝一个集合 |
| discard() | 删除集合中指定的元素 |
| remove() | 移除指定元素 |
| pop() | 随机移除元素 |
| difference() | 返回多个集合的差集 |
| difference_update() | 移除集合中的元素,该元素在指定的集合也存在。 |
| intersection() | 返回集合的交集 |
| intersection_update() | 返回集合的交集。 |
| isdisjoint() | 判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。 |
| issubset() | 判断指定集合是否为该方法参数集合的子集。 |
| issuperset() | 判断该方法的参数集合是否为指定集合的子集 |
| symmetric_difference() | 返回两个集合中不重复的元素集合(对称差集)。 |
| symmetric_difference_update() | 移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。 |
| union() | 返回两个集合的并集 |
常用操作代码:
"""集合的声明"""
"""空集"""
# data1 = set()
# print(data1, type(data1)) # set() <class 'set'>
#
"""有成员的集合"""
# data2 = {"A", "B", "C"}
# print(data2, type(data2)) # {'A', 'C', 'B'} <class 'set'>
"""
add 新增成员,成员如果已经存在,则会被去重
update 新增成员
"""
# data1 = {"A", "B"}
# data1.add("C")
# print(data1) # {'C', 'A', 'B'}
#
# data1 = {"A", "B"}
# data1.update("C")
# print(data1) # {'A', 'B', 'C'}
# # 添加已经存在的成员,会被去重掉
# data1 = {"A", "B"}
# data1.add("A")
# print(data1) # {'A', 'B'}
"""
clear 清空集合中所有的成员
del 使用关键字,删除空间对应的变量和数据
"""
# data1 = {"A", "B"}
# data1.clear()
# print(data1) # set() 空集
#
# data2 = {"A", "B"}
# del data2
# print(data2) # 报错,NameError: name 'data2' is not defined ===> data2没有这个变量
"""
删除集合的指定成员
集合.remove() 删除成员[常用]
集合.discard() 删除成员
集合.pop() 随机删除一个成员,类似于抽奖
"""
# data1 = {"A", "B", "C", "D"}
# data1.discard("C")
# print(data1) # {'D', 'A', 'B'}
# data1 = {"A", "B", "C", "D"}
# data1.remove("C")
# print(data1) # {'B', 'A', 'D'}
# 随机删除
data1 = {"A", "B", "C", "D"}
ret = data1.pop()
print(ret, data1)
集合的交叉并补操作
"""
集合1.difference(集合2) 差集
集合1 - 集合2
"""
# set1 = {"周杰伦", "李宇春", "王宝强", "斯嘉丽"}
# set2 = {"周润发", "刘德华", "斯嘉丽", "李宇春"}
# # 运算符
# # 算set1的差集
# print(set1 - set2) # {'王宝强', '周杰伦'}
# # 算set2的差集
# print(set2 - set1) # {'刘德华', '周润发'}
#
# # 方法
# # 算set1的差集
# print(set1.difference(set2)) # {'周杰伦', '王宝强'}
# # 算set2的差集
# print(set2.difference(set1)) # {'周润发', '刘德华'}
"""
并集
集合1.union(集合2)
集合1 | 集合2
"""
# set1 = {"周杰伦", "李宇春", "王宝强", "斯嘉丽"}
# set2 = {"周润发", "刘德华", "斯嘉丽", "李宇春"}
# # 运算符
# print(set1 | set2) # {'周杰伦', '刘德华', '李宇春', '王宝强', '斯嘉丽', '周润发'}
# # 方法
# print(set1.union(set2)) # {'周杰伦', '周润发', '李宇春', '斯嘉丽', '王宝强', '刘德华'}
"""
交集
集合1.intersection(集合2)
集合1 & 集合2
"""
# set1 = {"周杰伦", "李宇春", "王宝强", "斯嘉丽"}
# set2 = {"周润发", "刘德华", "斯嘉丽", "李宇春"}
# # 运算符
# print(set1 & set2) # {'斯嘉丽', '李宇春'}
# # 方法
# print(set1.intersection(set2)) # {'斯嘉丽', '李宇春'}
"""
对称差集:返回两个集合中不重复的元素集合, 补集情况涵盖在其中
集合1.symmetric_difference(集合2)
集合1 ^ 集合2
"""
# set1 = {"周杰伦", "李宇春", "王宝强", "斯嘉丽"}
# set2 = {"周润发", "刘德华", "斯嘉丽", "李宇春"}
# print(set1 ^ set2) # {'刘德华', '周杰伦', '周润发', '王宝强'}
# print(set1.symmetric_difference(set2)) # {'刘德华', '周杰伦', '周润发', '王宝强'}
"""基于对称差集就可以很方便的得到补集"""
# # (A ^ B) & B = A的补集
# # (A ^ B) & A = B的补集
# set1 = {"周杰伦", "李宇春", "王宝强", "斯嘉丽"}
# set2 = {"周润发", "刘德华", "斯嘉丽", "李宇春"}
# # set1的补集
# print((set1 ^ set2) & set2) # {'周润发', '刘德华'}
# # set2的补集
# print((set1 ^ set2) & set1) # {'周杰伦', '王宝强'}
"""
issuperset 判断一个集合是否是另一个集合的超集(父集)
issubset 判断一个集合是否是另一个集合的子集
"""
set1 = {"A", "B", "C", "D"}
set2 = {"A", "D"}
set3 = {"A", "C"}
# 判断set1是否是set2的父集
print( set1.issuperset(set2)) # True
# 判断set3是否是set1的子集
print( set3.issubset(set1)) # True
# 判断set2是否是set3的父集
print( set2.issuperset(set3)) # False
# 判断set2是否是set3的子集
print( set2.issubset(set3)) # False
字典常用操作
| 序号 | 函数及描述 |
|---|---|
| dict.clear() | 删除字典内所有元素 |
| dict.copy() | 返回一个字典的浅复制 |
| dict.fromkeys() | 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 |
| dict.get(key, default=None) | 返回指定键的值,如果键不在字典中返回 default 设置的默认值 |
| dict.items() | 把字典转换成二级对等容器,以列表格式返回。 |
| dict.keys() | 返回一个由字典的键组成的伪列表对象 |
| dict.values() | 返回一个由字典的值组成的伪列表对象 |
| dict.setdefault(key, None) | 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| dict.update(dict2) | 把字典dict2的键/值对更新到dict里 |
| dict.pop(key[,default]) | 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 |
| dict.popitem() | 返回并删除字典中的最后一对键和值。 |
"""字典的基本操作"""
# # 字典的声明
# # 空字典
# data1 = {}
# print(data1, type(data1)) # {} <class 'dict'>
#
# # 有成员的字典
# data2 = {"name":"小名", "age": 18}
# print(data2, type(data2)) # {'name': '小名', 'age': 18} <class 'dict'>
# # 获取字典成员的只
# data = {"name":"小名", "age": 18}
# print(data["name"]) # 小名
# # 新增/修改一个成员
# data = {"age": 12}
# data["name"] = "小红"
# print(data) # {'age': 12, 'name': '小红'}
# data["age"] = 18
# print(data) # {'age': 18, 'name': '小红'}
# # 删除一个成员
# data = {'age': 18, 'name': '小红'}
# del data["age"]
# print(data) # {'name': '小红'}
# # 统计字典成员数量
# data = {'age': 18, 'name': '小红'}
# print( len(data)) # 2
"""字典提供的常用操作"""
"""
字典.clear() 清空字典
del 字典 删除字典
"""
# data = {'age': 18, 'name': '小红'}
# data.clear()
# print(data) # {} 空字典
# data = {'age': 18, 'name': '小红'}
# del data
# print(data) # NameError: name 'data' is not defined
"""
字典.fromkeys(序列) 根据已有序列创建一个字典
"""
# list_data = ["a", "b"]
# data = {}
# new_data = data.fromkeys(list_data, "A")
# print(new_data) # {'a': 'A', 'b': 'A'}
"""
根据指定键获取字典中的成员的值,如果键不存在,则返回None,也可以指定默认值
字典.get("键", default=None)
子弹[键]
"""
# # 使用中括号获取指定键对应的值,如果键不存在,会报错
# data = {'age': 18, 'name': '小红'}
# print( data["price"] ) # KeyError: 'price'
# 使用get不会报错
# data = {'age': 18, 'name': '小红'}
# print( data.get("age") ) # 18
# print( data.get("money") ) # None,不存在的键则返回None
# print( data.get("money", 0.0)) # 0.0,当键不存在时,可以设置默认值
"""
二级对等容器转换字典
"""
# data = [("name","xiaoming"), ("age", 17), ]
# dict_data = dict(data)
# print(dict_data) # {'name': 'xiaoming', 'age': 17}
"""
字典转二级对等容器
"""
# data = {'name': 'xiaoming', 'age': 17}
# print(list(data.items())) # [('name', 'xiaoming'), ('age', 17)]
# 当然,items最大的作用就是让for循环遍历字典,得到每一个成员的键值对
# data = {'name': 'xiaoming', 'age': 17}
# for key, value in data.items():
# print(f"key={key}, value={value}")
# key=name, value=xiaoming
# key=age, value=17
"""如果在循环中,希望对于列表/元组,也想要类似字典这样,不仅要返回值,还要返回下标,可以使用"""
# data = ["A", "B", "C", "D", "E"]
# # data = ("A", "B", "C", "D", "E")
# # data = "ABCDECV"
# for index, item in enumerate(data): # enumerate可以让循环提取列表/元组/字符串的下标和值
# print(f"index={index}, item={item}")
# index=0, item=A
# index=1, item=B
# index=2, item=C
# index=3, item=D
# index=4, item=E
"""
字典.keys() # 返回一个由字典的键组成的伪列表对象
字典。values() # 返回一个由字典的值组成的伪列表对象
"""
# data = {'name': 'xiaoming', 'age': 17}
# print(data.keys()) # dict_keys(['name', 'age'])
# print(data.values()) # dict_values(['xiaoming', 17])
"""
字典.setdefault(key, defaultValue) # 设置键的默认值,如果键存在,则没有任何效果,只有键不存在时,则把当前键和默认值作为键值对添加到字典中
字典1.update(字典2) # 更新键对应的只,常用语合并字典
"""
# data = {'name': 'xiaoming', 'age': 17}
# data.setdefault("money", 0.0) # 第二个参数选项则是当键不存在时设置的默认值,如果不设置,则默认为None
# print(data)
# local_data = {"PASSWORD":"123", "URL": "127.0.0.1", "ENV": "dev"}
# data = {"SYSTEM": "Linux", "PASSWORD": "fkdkjgm343m24324m2390fdvsf", "URL": "www.fuguang.com"}
#
# # 不存在的键会新增,存在的键以传递进去的字典为主
# data.update(local_data)
# print(data) # {'SYSTEM': 'Linux', 'PASSWORD': '123', 'URL': '127.0.0.1', 'ENV': 'dev'}
"""
字典.pop(键) 删除指定键对应的成员
字典.popitem() 删除字典中最后一个成员
"""
# data = {'name': 'xiaoming', 'age': 17}
# name = data.pop("name")
# print(data) # {'age': 17}
# print(name) # xiaoming 被删除的键对应的值
data = {'name': 'xiaoming', 'age': 17}
data.popitem()
print(data) # {'name': 'xiaoming'}
案例:学生信息管理系统(终端版本)
需求:在终端下提供一个保存学生信息的程序,能查看学生数据列表,能修改学生数据,能删除数据,能新增数据,能退出管理系统。
课堂代码:
"""
学生信息管理系统
数据格式:
student_list = [
{"name":"姓名", "age": 16, "sex": "男", "mobile": 1331234567},
{"name":"姓名", "age": 16, "sex": "男", "mobile": 1331234567},
]
功能:查看学生数据列表,能修改学生数据,能删除数据,能新增数据,能退出管理系
"""
# 学生信息的存储列表
student_list = [
{'name': '小红', 'age': '16', 'sex': '女', 'mobile': '13312345678'},
{'name': '小红', 'age': '13', 'sex': '男', 'mobile': '13012345678'}
]
while True:
"""1. 显示菜单"""
print("* " * 15)
print("* 欢迎来到XX学生信息管理系统。")
print("*")
print("* 1. 查看学生信息")
print("* 2. 添加学生信息")
print("* 3. 修改学生信息")
print("* 4. 删除学生信息")
print("* 5. 退出信息系统")
print("* " * 15)
action = int( input("请输入要进行的操作序号(1·5):") )
print()
if action == 1:
"""查看学生信息"""
print("查看所有学生信息...")
# 格式化地循环输出每一个学生信息
for index, student in enumerate(student_list):
print(f"学号:{index+1} 姓名: {student['name']} 年龄;{student['age']} 性别:{student['sex']} 联系电话:{student['mobile']}")
else:
print("没有学生信息....")
elif action == 2:
"""添加学生信息"""
print("请输入要录入系统的学生信息...")
name = input("姓名:")
age = input("年龄:")
sex = input("性别:")
mobile = input("联系电话:")
# print(f"name={name}, age={age}, sex={sex}, mobile={mobile}")
# 把学生信息整理成字典,并作为成员追加到列表中
student = {"name": name, "age": age, "sex": sex, "mobile": mobile}
student_list.append(student)
# print(f"student_list={student_list}")
elif action == 3:
"""修改学生信息"""
pass
# 1. 展示数据功能,让用户选择自己修改数据的编号
# 2. 仿照添加数据功能,提供input让用户输入数据,并整理一个字典
# input("姓名(小红):")
# 3. 根据编号提取下标,修改指定下标数据的成员信息
elif action == 4:
"""删除学生信息"""
for index, student in enumerate(student_list):
print(f"学号:{index+1} 姓名: {student['name']} 年龄;{student['age']} 性别:{student['sex']} 联系电话:{student['mobile']}")
num = int(input("请你要删除的学生学号!"))
# print(f"被删除的学生学号:{num}, 对应数据的下标:{num-1}, 数据:{student_list[num-1]}")
# 根据下标删除列表成员
student_list.pop(num-1)
else:
print("成功退出系统中....")
break
print()
print()
总结
重点
1. 浅拷贝与深拷贝
为什么要进行浅拷贝和深拷贝,两者区别
2. 集合常用操作,加粗部分
3. 字典常用操作,加粗部分
理解
1. 引用赋值