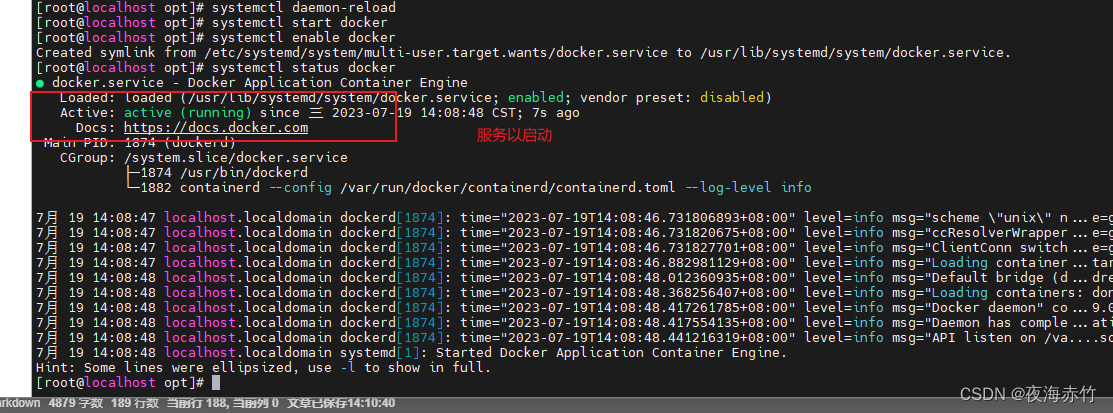
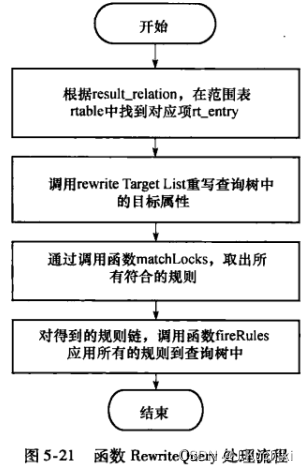
文章目录
- 简介
- 官方demo
- 读取并修改已存在的docx
- 参考文献
202201笔记迁移
简介
python的docx包是可以用来自动化处理docx文件,可以从无到有生成一个docx文件,也可以对已有的docx文件做批量修改。(但印象里是只能操作.docx文件,如果想操作.doc文件,得先另存为.docx先)
使用的第一步是安装,
pip install python-docx
注意安装的是python-docx,不要直接pip install docx,docx这个包虽然能够安装成功,但是无法使用。(至于为什么,可以参照参考文献2)
官方demo
官方文档,即参考文献1中直接列了一个简单的demo供大家使用,可以从中看到是如何一步一步自动生成一个docx。
为了更好的说明docx包的功能,我基于官方demo做了一些补充。
from docx import Document
from docx.shared import Inches, Pt
root_path = 'D:/Document/1-2021碎片学习/12-python/word自动化/docx_sample/'
# 以空白模板,来创建一个文档对象
document = Document()
# 设置document的全局样式,normal代表的应该是全部样式元素
# 需要注意的是,document、paragraph和run都可以自行设置样式style,且遵循就近原则,越往下,style的优先级越高。
document.styles['Normal'].font.name='Microsoft Yahei UI'
document.styles["Heading 1"].font.size=Pt(29) #设置全局1级标题的字体大小为29
# 创建标题,level参数用来控制标题级别,如果level=0,表示创建一个title
document.add_heading('Document Title', 0)
# 添加一个段落,(并设置其初始化文字)
p = document.add_paragraph('A plain paragraph having some ')
# 以节段run的形式,继续往该段落添加文字,并设置样式
p.add_run('bold').bold = True
p.add_run(' and some ')
p.add_run('italic.').italic = True
document.add_heading('Heading, level 1', level=1)
document.add_paragraph('Intense quote', style='Intense Quote') # 添加一个引用式段落
# 添加一个列表式段落
document.add_paragraph(
'first item in unordered list', style='List Bullet'
)
# 添加一系列自行标号的列表段落
document.add_paragraph(
'first item in ordered list', style='List Number'
)
document.add_paragraph(
'two item in ordered list', style='List Number'
)
# 添加一个图片
document.add_picture(root_path + 'data/VF.jpeg', width=Inches(1.25))
records = (
(3, '101', 'Spam'),
(7, '422', 'Eggs'),
(4, '631', 'Spam, spam, eggs, and spam')
)
# 添加一个table,并赋值
table = document.add_table(rows=1, cols=3)
hdr_cells = table.rows[0].cells
hdr_cells[0].text = 'Qty'
hdr_cells[1].text = 'Id'
hdr_cells[2].text = 'Desc'
for qty, id, desc in records:
row_cells = table.add_row().cells
row_cells[0].text = str(qty)
row_cells[1].text = id
row_cells[2].text = desc
# 设置分页符
document.add_page_break()
# 保存成实体文件
document.save(root_path + 'data/demo.docx')
最终生成的docx文件长什么样子呢?
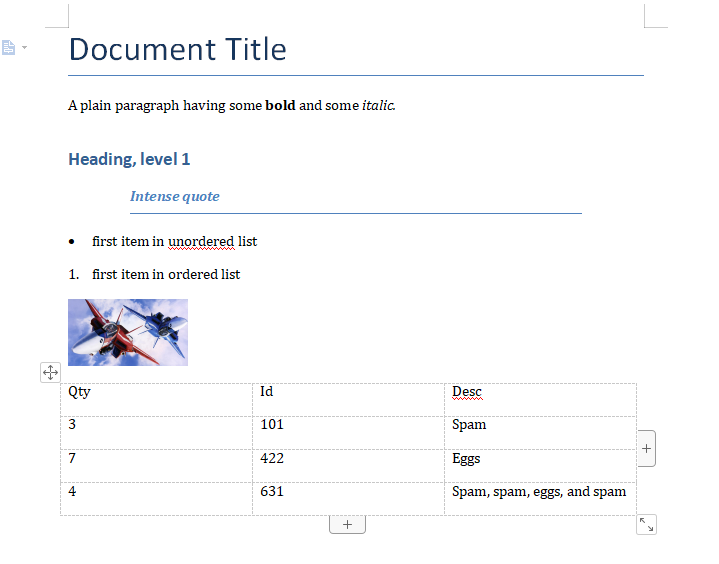
短短几行,基本写尽了python-docx的基础功能。
可以生成:
- 各级标题
- 各种格式的内容文本,部分加粗、斜体等都可以;
- 各种列表;
- 添加图片;
- 添加表格;
下面对python-docx的几大元素做简单介绍,最后再配一个操作现成docx的实例。
首先介绍几个基本概念(以下简称三要素):
- Document:是一个word文档对象,一个word在内存中是以一个Document对象的形式存在的;
- Paragraph:直译,就是段落,word文档中的内容由一个个段落组成。当在文档中输入一个回车键,就会形成一个新的段落。输入shift + enter,即软回车,不会分段,而是在段内换行;
- Run:表示一个节段,每个段落由多个节段组成。一个段落中具有相同样式的连续文本,组成一个节段。因此一个Paragraph对象由一个Run列表组成。
举一个例子来表示run和paragraph的关系:(图片来源于参考文献3)

以上的结构实际上是:

注意倒数第二行后面是一个软回车,所以它跟倒数第一行是一个paragraph。第二行是空,只有一个回车符,所以没有run。
等回头写一个验证一下。
关于样式,document、paragraph和run都可以自行设置样式style,且遵循就近原则,越往下,style的优先级越高,即在某个paragraph中,document所设置的全局样式可以被paragraph设置的样式覆盖。如果一个paragraph没有指定自己的style,那就跟着document的normal样式走。
读取并修改已存在的docx
事实上,日常生活中,创建一个docx的场景还是少的,应用最多的还是批量读取已存在的docx,并做修改。
下面首先以上一段生成的docx文件,来简单解析一下它在内存层次的存在形式,并根据之前做过的一个例子,来讲一下实际怎么使用这个包。
以下为简单示例,旨在展示简单的批量文本替换
# 读取一个已存在的docx示例
from docx import Document
import os
root_path = 'D:/Document/1-2021碎片学习/12-python/word自动化/docx_sample/'
data_path = os.path.join(root_path, 'data/')
document = Document(os.path.join(data_path, 'demo.docx'))
print(document)
# 每个文档对象下都有一个paragraphs列表,由paragraph组合而成
print(document.paragraphs)
for p in document.paragraphs:
# print(p)
# print(p.text)
for run in p.runs: # 一个paragraph也是由多个run组成
# print(run)
print(run.text) # 可尝试修改demo.docx文件,来调整run
if run.text == 'bold': # 对关键字做替换
run.text = 'bold bold'
document.save(os.path.join(data_path, 'new_demo.docx'))
所以如果只是要做批量的文本替换,实际上可以先调校好模板,(通过加粗或者字体等样式操作)让需要被替换的文字单独成一个run,然后循环的时候对这个run做if判断就可以了。
参考文献
- python-docx 官方文档,说实话写的有点简略
- from docx import Document报错的问题
- Word 神器 python-docx 写的挺不错的,尤其是对三要素的解释上,图文并茂,绝了
- Python操作Word的入门教程
- 一个浏览器包
- python-docx中关于style的可选值列取但是并没有详细解释每一种style用出来是什么效果
- python-docx设置段落格式 设置全局样式,段落样式