2023.7.19
cifar10百科:
[ 数据集 ] CIFAR-10 数据集介绍_cifar10_Horizon Max的博客-CSDN博客
torchvision各种预训练模型的调用方法:
pytorch最全预训练模型下载与调用_pytorch预训练模型下载_Jorbol的博客-CSDN博客
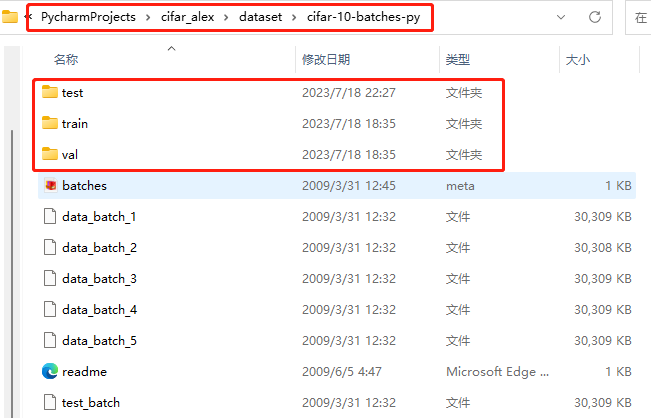
CIFAR10数据集下载并转换为图片:
文件结构:

import torchvision
from torch.utils.data import DataLoader
import os
import numpy as np
import imageio # 引入imageio包
train_data = torchvision.datasets.CIFAR10(root='./dataset', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# 路径将测试集作为验证集
train_path = './dataset/cifar-10-batches-py/train'
test_path = './dataset/cifar-10-batches-py/val'
for i in range(10):
file_name = train_path + '/'+ str(i)
if not os.path.exists(file_name):
os.mkdir(file_name)
for i in range(10):
file_name = test_path + '/' + str(i)
if not os.path.exists(file_name):
os.mkdir(file_name)
# 解压 返回解压后的字典
def unpickle(file):
import pickle as pk
fo = open(file, 'rb')
dict = pk.load(fo, encoding='iso-8859-1')
fo.close()
return dict
# begin unpickle
root_dir = "./dataset/cifar-10-batches-py"
# 生成训练集图片
print('loading_train_data_')
for j in range(1, 6):
dataName = root_dir + "/data_batch_" + str(j) # 读取当前目录下的data_batch1~5文件。
Xtr = unpickle(dataName)
print(dataName + " is loading...")
for i in range(0, 10000):
img = np.reshape(Xtr['data'][i], (3, 32, 32)) # Xtr['data']为图片二进制数据
img = img.transpose(1, 2, 0) # 读取image
picName = root_dir + '/train/' + str(Xtr['labels'][i]) + '/' + str(i + (j - 1) * 10000) + '.jpg'
imageio.imsave(picName, img) # 使用的imageio的imsave类
print(dataName + " loaded.")
# 生成测试集图片(将测试集作为验证集)
print('loading_val_data_')
testXtr = unpickle(root_dir + "/test_batch")
for i in range(0, 10000):
img = np.reshape(testXtr['data'][i], (3, 32, 32))
img = img.transpose(1, 2, 0)
picName = root_dir + '/val/' + str(testXtr['labels'][i]) + '/' + str(i) + '.jpg'
imageio.imsave(picName, img)
训练代码:
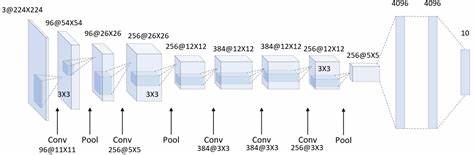
AlexNet 结构
1,查询需要的模型网站并填入
# 预训练模型官网
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
}
2, 加载预训练模型(在10分类的情况下,AlexNet的效果比ResNet18的效果稍好)
先print(Model),,看fc层的参数,设置好fc层
3,以AlexNet10分类任务来看

# Model = models.densenet161(pretrained=True)
Model = models.resnet18(pretrained=True)
for param in Model.parameters():
param.requires_grad = True
# print(Model)
# Model.fc = nn.Linear(2208, class_num)
Model.fc = nn.Linear(512, class_num)
此时,我们需要将在导入AlexNet模型下载的官网:
# 预训练模型官网:
model_urls = {'alexnet': 'https://download.pytorch.org/models/alexnet-owt-4df8aa71.pth',}# 加载模型:
Model = models.alexnet(pretrained=True)
for param in Model.parameters():
param.requires_grad = True
print(Model)
# 根据上面Classifier层的最后(6)Linear的输入通道 in_features = 4096 更改 model的fc层
Model.fc = nn.Linear(4096, class_num)
from torch.utils.data import DataLoader, Dataset
from PIL import Image
import numpy as np
import os
import torch
import torch.optim as optim
import torch.nn as nn
import torchvision.models as models
import torchvision.transforms as transforms
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform = transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), ]
)
class MyDataset(Dataset):
def __init__(self, root_dir, transform=None):
self.root_dir = root_dir
self.transform = transform
self.names_list = []
for dirs in os.listdir(self.root_dir):
dir_path = self.root_dir + '/' + dirs
for imgs in os.listdir(dir_path):
img_path = dir_path + '/' + imgs
self.names_list.append((img_path, dirs))
def __len__(self):
return len(self.names_list)
def __getitem__(self, index):
image_path, label = self.names_list[index]
if not os.path.isfile(image_path):
print(image_path + '不存在该路径')
return None
image = Image.open(image_path).convert('RGB')
label = np.array(label).astype(int)
label = torch.from_numpy(label)
if self.transform:
image = self.transform(image)
return image, label
if __name__ == '__main__':
# 准备数据集
train_data_path = './dataset/cifar-10-batches-py/train'
val_data_path = './dataset/cifar-10-batches-py/val'
# 数据长度
train_data_length = len(train_data_path)
val_data_length = len(val_data_path)
# 分类的类别
class_num = 10
# 迭代次数
epoch = 30
# 学习率
learning_rate = 0.00001
# 批处理大小
batch_size = 128
# 数据加载器
train_dataset = MyDataset(train_data_path, transform)
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_dataset = MyDataset(val_data_path, transform)
val_dataloader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
train_data_size = len(train_dataset)
val_data_size = len(val_dataset)
# 预训练模型官网
model_urls = {'alexnet': 'https://download.pytorch.org/models/alexnet-owt-4df8aa71.pth',}
# 调用预训练调整全连接层:搭建网络
# Model = models.densenet161(pretrained=True)
Model = models.alexnet(pretrained=True)
for param in Model.parameters():
param.requires_grad = True
print(Model)
# Model.fc = nn.Linear(2208, class_num)
Model.fc = nn.Linear(4096, class_num)
# 创建网络模型
ModelOutput = Model.cuda() # DenseNet161 ResNet18
# 采用多GPU训练
if torch.cuda.device_count() > 1:
print("使用", torch.cuda.device_count(), "个GPUs进行训练")
ModelOutput = nn.DataParallel(ModelOutput)
else:
ModelOutput = Model.to(device) # .Cuda()数据是指放到GPU上
print("使用", torch.cuda.device_count(), "个GPUs进行训练")
# 定义损失函数
loss_fn = nn.CrossEntropyLoss().cuda() # 交叉熵函数
# 定义优化器
optimizer = optim.Adam(ModelOutput.parameters(), lr=learning_rate)
# 记录验证的次数
total_train_step = 0
total_val_step = 0
# 训练
acc_list = np.zeros(epoch)
print("{0:-^27}".format('Train_Model'))
for i in range(epoch):
print("----------epoch={}----------".format(i + 1))
ModelOutput.train()
for data in train_dataloader: # data 是batch大小
image_train_data, t_labels = data
image_train_data = image_train_data.cuda()
t_labels = t_labels.cuda()
output = ModelOutput(image_train_data)
loss = loss_fn(output, t_labels.long())
# 优化器优化模型
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 优化更新参数
total_train_step = total_train_step + 1
print("train_times:{},Loss:{}".format(total_train_step, loss.item()))
# 验证步骤开始
ModelOutput.eval()
total_val_loss = 0
total_accuracy = 0
with torch.no_grad(): # 测试的时候不需要对梯度进行调整,所以梯度设置不调整
for data in val_dataloader:
image_val_data, v_labels = data
image_val_data = image_val_data.cuda()
v_labels = v_labels.cuda()
outputs = ModelOutput(image_val_data)
loss = loss_fn(outputs, v_labels.long())
total_val_loss = total_val_loss + loss.item() # 计算损失值的和
accuracy = 0
for j in v_labels: # 计算精确度的和
if outputs.argmax(1)[j] == v_labels[j]:
accuracy = accuracy + 1
# accuracy = (outputs.argmax(1) == v_labels).sum() # 计算一个数据的精确度
total_accuracy = total_accuracy + accuracy
val_acc = float(total_accuracy / val_data_size) * 100
acc_list[i] = val_acc # 记录验证集的正确率
print('the_classification_is_correct :', total_accuracy, val_data_length)
print("val_Loss:{}".format(total_val_loss))
print("val_acc:{}".format(val_acc), '%')
total_val_step += 1
torch.save(ModelOutput, "Model_{}.pth".format(i + 1))
# torch.save(ModelOutput.module.state_dict(), "Model_{}.pth".format(i + 1))
print("{0:-^24}".format('Model_Saved'), '\n')
print('val_max=', max(acc_list), '%', '\n') # 验证集的最高正确率
测试代码:
import torch
from torchvision import transforms
import os
from PIL import Image
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') # 判断是否有GPU
model = torch.load('Model_8.pth') # 加载模型
path = "./dataset/cifar-10-batches-py/test/" # 测试集
imgs = os.listdir(path)
test_num = len(imgs)
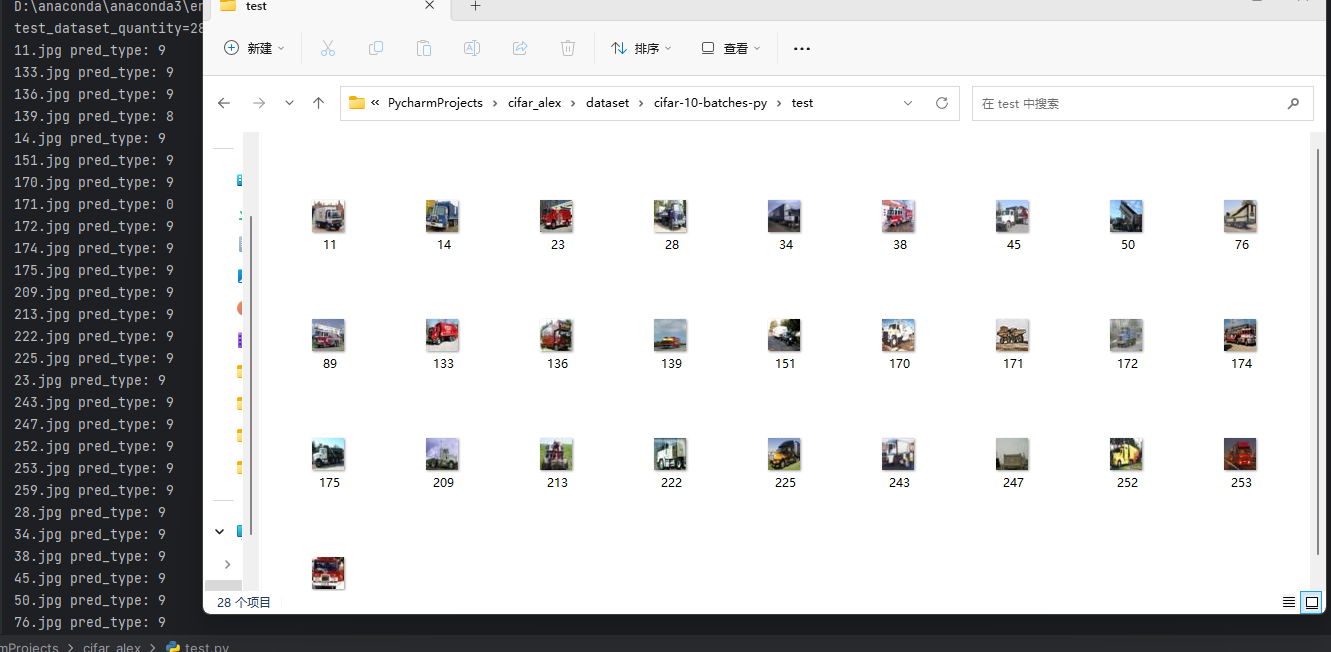
print(f"test_dataset_quantity={test_num}")
for img_name in imgs:
img = Image.open(path + img_name)
test_transform = transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), ]
)
img = test_transform(img)
img = img.to(device)
img = img.unsqueeze(0)
outputs = model(img) # 将图片输入到模型中
_, predicted = outputs.max(1)
pred_type = predicted.item()
print(img_name, 'pred_type:', pred_type)
在使用标签为9的卡车图像进行预测:
AlexNet:
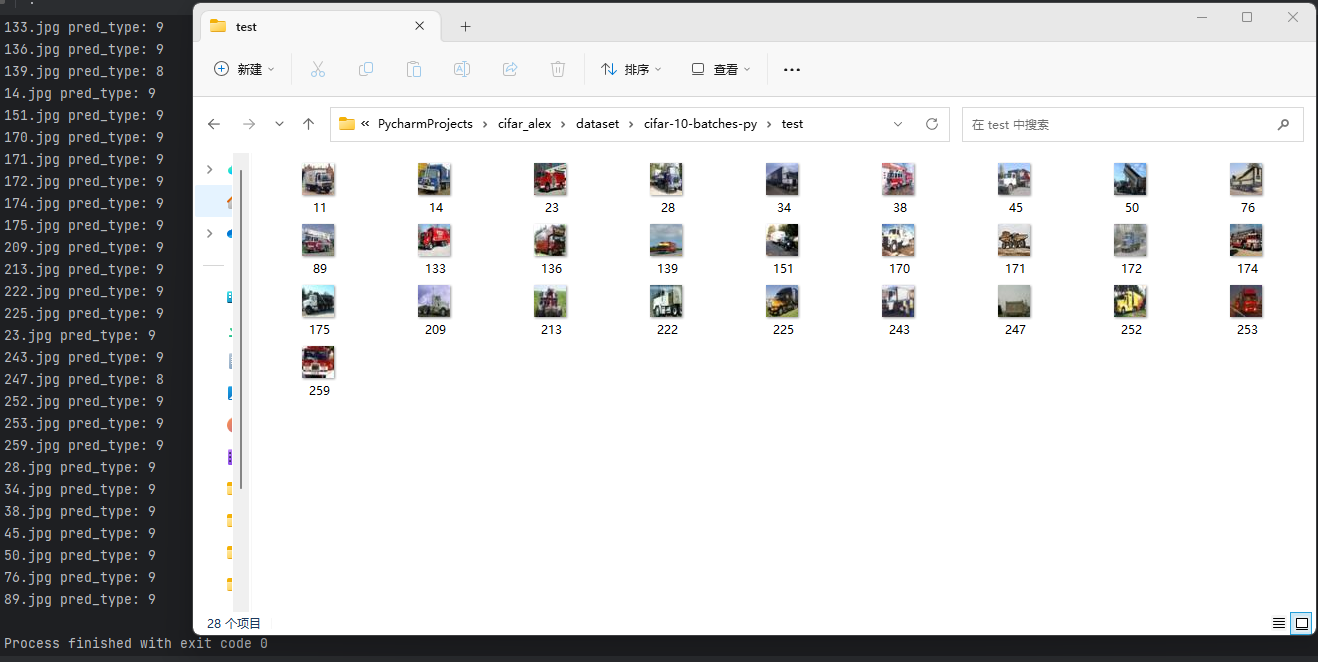
ResNet18: