前言
在当今全球化和多元文化的时代,语音翻译技术正成为我们跨越语言障碍的得力助手!语音翻译(Speech Translation, ST)旨在将源语言语音翻译成目标语言文本,广泛应用于会议演讲翻译、视频字幕翻译、AR增强翻译等各种场景。语音翻译可以提高沟通效率和便利性,无论是在商务会议还是旅行中的日常交流,我们不再需要手忙脚乱地翻阅词典,或用肢体语言沟通,只需用自己的语言说出来,它就会帮我们实时翻译,让我们能和世界各地的人无障碍交流。

01. 语音翻译的挑战
近年来,神经机器翻译技术日趋成熟,拥有高质量、大规模的两种或多种语言之间的平行语料,是当今机器翻译模型获得良好性能的前提。然而,满足语音翻译需要的“语音-转写-翻译”数据相对稀缺。以英语到德语翻译为例,机器翻译中常用的 WMT16 数据集[1]有460万条训练数据,而语音翻译中最常用的 MuST-C 数据集[2]只有23万条训练数据,这存在着数十倍的差距。数据缺乏限制了语音翻译模型的性能,这与机器翻译中的低资源语言机器翻译场景十分相似。在低资源语言机器翻译中,回译、预训练等技术十分有效[3][4]。那么,能否借助低资源机器翻译的技术来帮助语音翻译呢?
然而,直接把机器翻译技术应用到语音翻译中是不现实的。这是因为语音和文本存在表示上的差异,语音数据通常表示为连续的波形信号或者梅尔频谱,而文本通过离散的符号来表示,这种表示上的差异增加了技术迁移的难度。因此,如果也能用离散符号来表征语音,那么自然可以用机器翻译技术来解决语音翻译问题,从而统一语音翻译与机器翻译了。
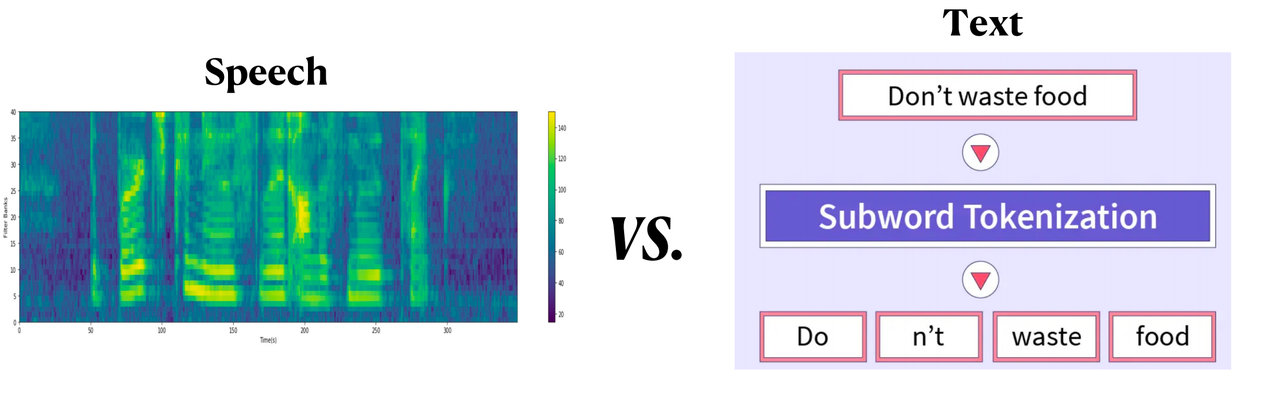
语音信号表示和文本
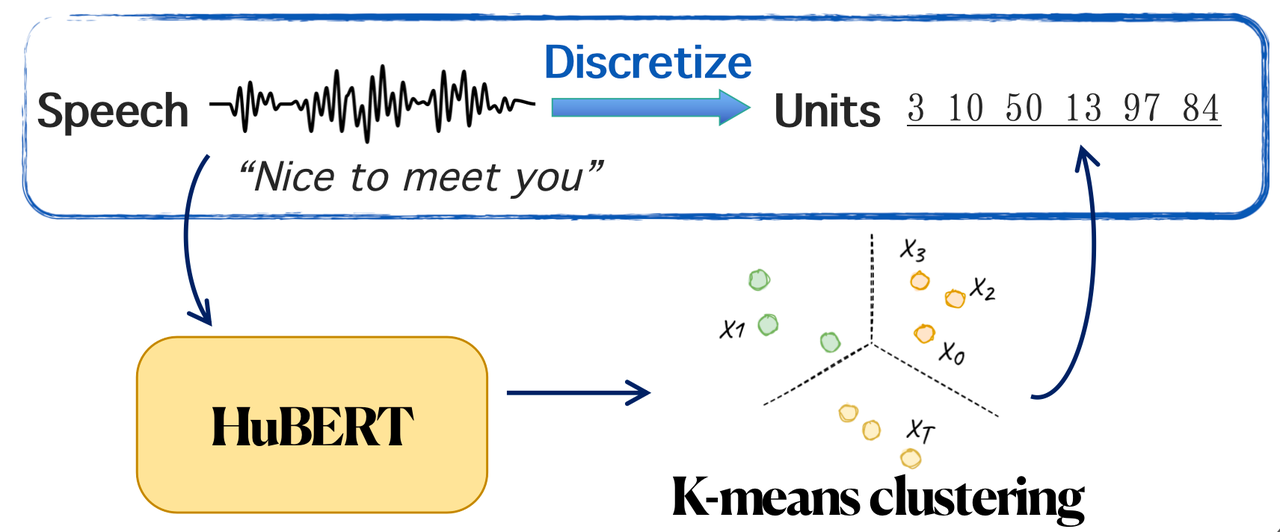
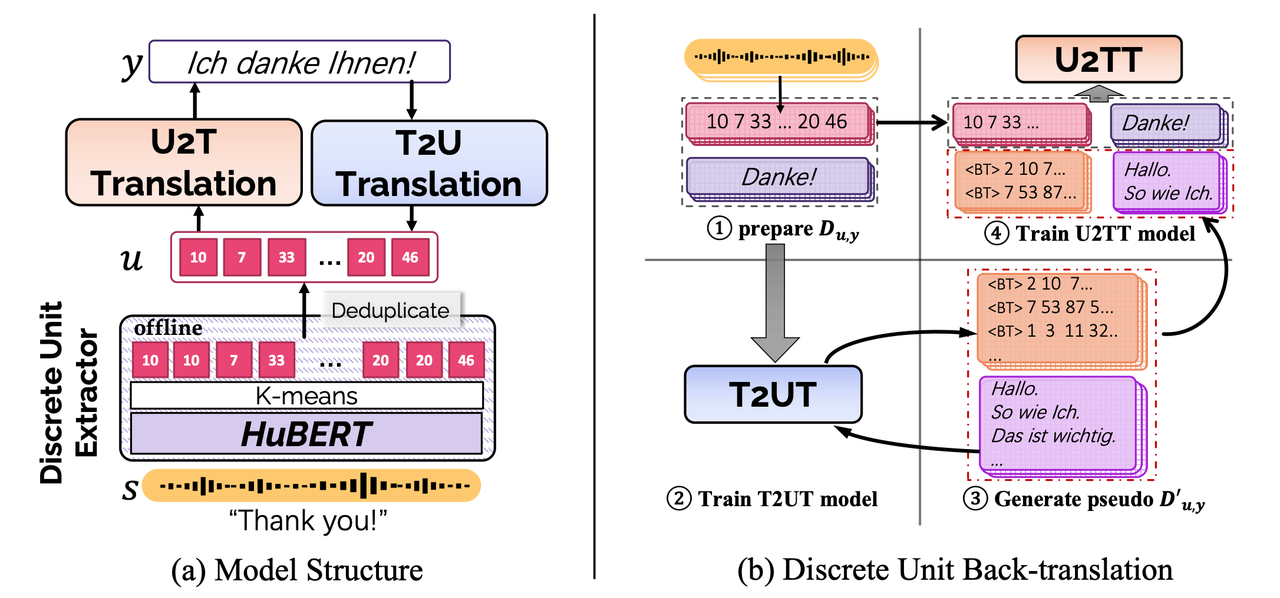
最近越来越多的工作聚焦在语音无监督离散化表示上[5][6]。如下图,比较常用的语音离散化表示是 HuBERT 离散单元[7],通过在 HuBERT 提取出的连续表示上做 K-means 聚类得到。研究表明这种离散化表示可以起到一定程度的信息过滤的作用,即保留内容信息并且除去说话人等无关信息[6]。HuBERT 得到的语音离散表示与低资源机器翻译技术相结合来解决语音翻译任务是一个可行的方法。参考 HuBERT 的研究,复旦大学和字节跳动 AI Lab 共同提出 DUB: Discrete Unit Back-translation for Speech Translation[8],该工作已被ACL 2023 Findings收录。

论文链接:
https://aclanthology.org/2023.findings-acl.447.pdf
代码链接:
https://github.com/0nutation/DUB
Huggingface space:
nutation/DUB · Hugging Face
这篇文章从一个新的视角来看待语音翻译,通过把语音表示为离散化符号,使语音翻译任务等同于一种特殊的低资源机器翻译任务,从而结合回译、预训练的技术来帮助语音翻译。
在此基础上,本文提出并回答两个问题:
-
对于语音翻译任务来说,语音离散表示和连续表示哪一个是更好的输入特征?
-
结合离散化表示,机器翻译技术能否为语音翻译带来提升?
此外,本文还展示了语音离散化表示在低资源濒危语言和不成文语言 (unwritten language) 上语音翻译的潜力。
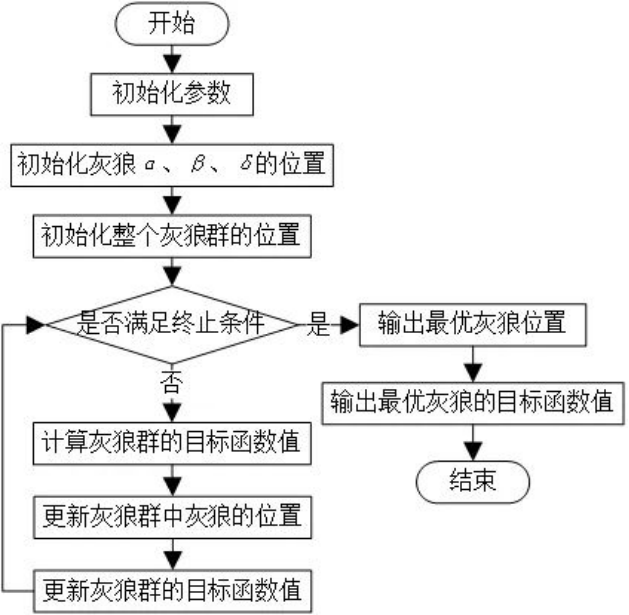
02. DUB模型结构与算法流程
2.1 模型结构
DUB使用一个离散单元提取器来对连续语音进行离散化(论文中使用的是HuBERT),从而得到离散单元序列。之后,使用两个 transformer 模型分别完成 unit-to-text translation (U2TT) 和 text-to-unit translation (T2UT) 的正向和反向翻译过程。
2.2 算法流程
基于上述 U2TT 和 T2UT 模型,DUB 的算法流程如下:
-
Step 1:对每个语音输入,提取对应的离散表示,并获取离散单元-翻译对;
-
Step 2:基于上述离散单元-翻译对训练 T2UT 模型;
-
Step 3:引入大量目标语言的文本数据 y’,送入训练好的 T2UT 模型,造出大量的伪离散单元,从而得到伪离散单元-翻译对。解码过程包括:Beam search、top-k sampling、sampling等;
-
Step 4:将真实离散单元-翻译对和伪离散单元-翻译对混合在一起训练出最终的U2TT模型。
03. DUB在语音翻译任务上的表现与分析
3.1 En-X和X-En语向上均获得显著翻译效果
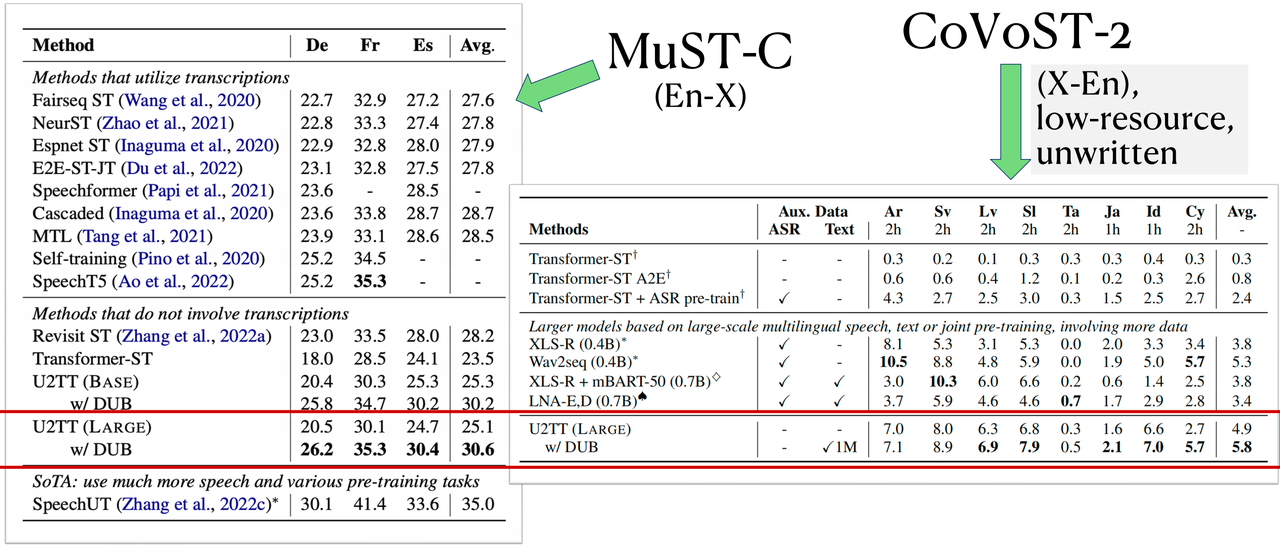
本文在 MuST-C 数据集的 En-De/Es/Fr 语向和 CoVoST2 数据集的 21 个 X-En 语向上进行了实验,如下表,与baseline 模型 U2TT 相比,DUB 在翻译质量上带来了显著的提升。在低资源 X-En 语向上,DUB 的性能甚至优于使用大量语音、文本数据进行联合预训练的系统,展现出 DUB 在低资源濒危语言和不成文语言 (unwritten language) 上语音翻译的潜力。
3.2 语音离散表示是比原始连续表示更好的输入表示,但存在一定的信息损失
对于前文提出的第一个问题:对于语音翻译任务来说,语音离散表示和连续表示哪一个是更好的输入特征?可以发现语音离散表示作为输入的 U2TT 要比原始连续表示 fbank 作为输入的 Transformer-ST 性能好,但与 Hubert 连续表示作为输入的 HuBERT-Transformer 相比存在一定的信息损失。由此说明语音离散表示是比原始连续表示更好的输入表示,但存在一定的信息损失。但是仅通过引入1M目标文本语料库,就可以弥补掉这部分的损失。

3.3 回译、预训练等机器翻译技术可以为语音翻译带来显著的性能提升
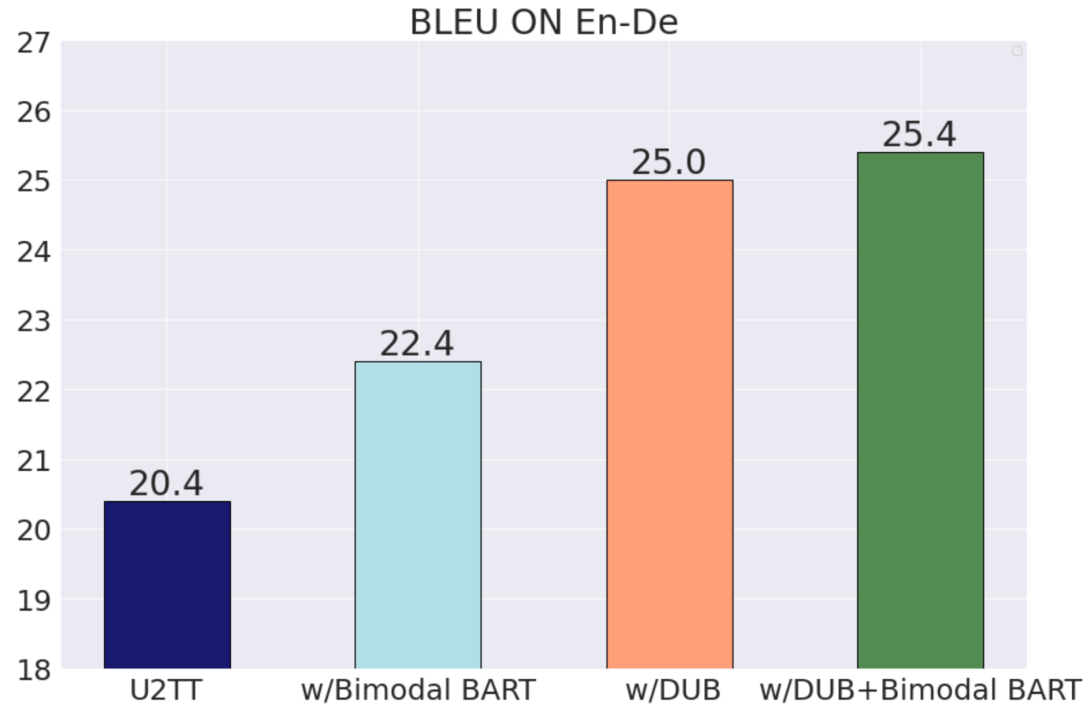
对于前文的第二个问题:结合离散化表示,机器翻译技术能否为语音翻译带来提升?从下图可以看出 DUB 对于 U2TT 可以带来接近5个 BLEU 的显著提升,说明回译技术是非常有效的。除了回译技术之外,预训练也是来提升低资源语言机器翻译的常见技术。作者还在大量的文本和语音离散单元上采用 mBART 的训练方式训练了一个 Bimodal BART,并采用它作为 U2TT 的预训练模型。Bimodal BART 也可以带来2个 BLEU 的提升,说明 mBART 预训练的方式对于语音翻译也是有效的。进一步,将 DUB 和 Bimodal BART 相结合,可以带来进一步的性能提升。
3.4 基于离散表示的语音翻译呈现出和机器翻译相同的现象
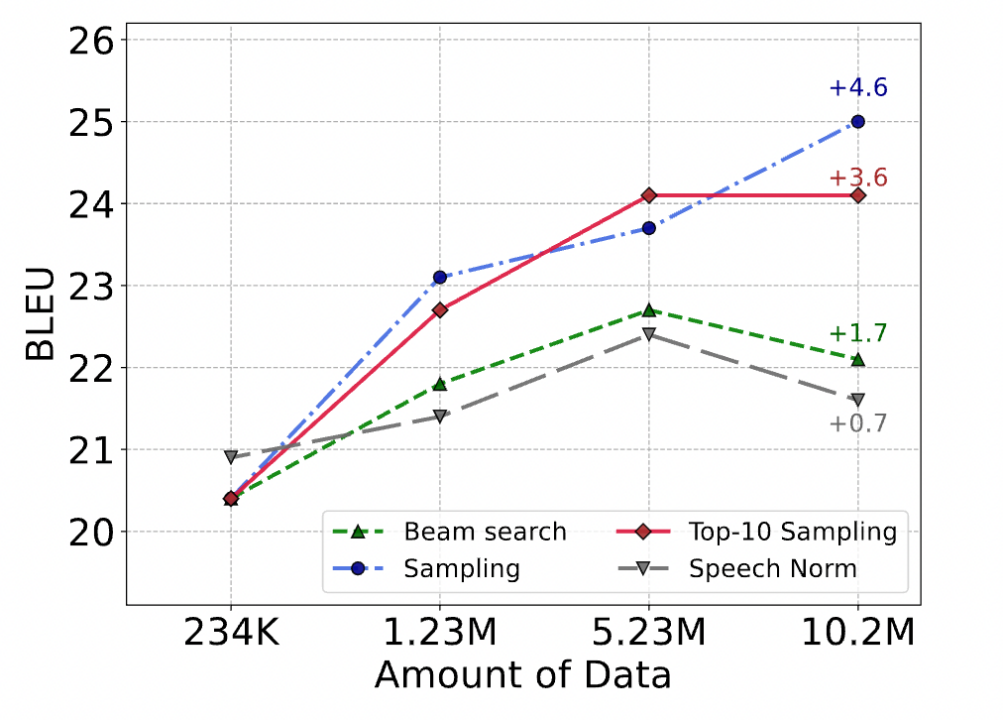
在 DUB 的 step 3 中利用 T2UT 模型来产生伪离散单元时,可以选择使用不同的解码策略,包括 Beam search、top-k sampling、sampling 等。如下图,可以观察到,从在 BLEU 指标上看,sampling > top10 sampling > beam search,这和机器翻译中的回译具有相同的结论,即产生的伪数据中的噪声越多,带来的提升就越大。这说明语音离散单元内部可能具有和文本类似的结构。
3.5 伪离散单元具有正确的语义信息
如下图,当连接 T2UT 和声码器模型,将文本通过 T2UT 产生的伪离散单元送入声码器,就可以恢复得到和原始文本具有相同语义的语音,从而可以实现文本到语音翻译功能。说明伪离散单元具有正确的语义信息。下面可以听一个德语到英语翻译的例子:

德语:Und sicher, hätten wir diese diese Hydranten die ganze Zeit freischaufeln können, und viele Menschen tun das.
英语参考:And certainly, we could have been shoveling out these fire hydrants all along, and many people do.
回译产生的英语语音:And certainly we could have released those hydrants all the time and many people do that.
04. 总结
本文主要介绍了 ACL 2023 上的一篇语音翻译的工作 DUB,其核心思想是通过把语音离散化来统一语音翻译与机器翻译任务,从而利用低资源机器翻译技术来帮助语音翻译。它首次提出将语音离散表示作为语音翻译任务的输入。实验结果证明了离散表示作为输入的有效性以及在这种框架下应用回译、预训练等机器翻译技术可以为语音翻译带来显著的性能提升。本文为语音理解任务提供了新的解决思路,并且展示出在低资源濒危语言和不成文语言 (unwritten language) 上的潜力。
参考文献
[1] Ondřej Bojar, Rajen Chatterjee, Christian Federmann, Yvette Graham, Barry Haddow, Matthias Huck, Antonio Jimeno Yepes, Philipp Koehn, Varvara Logacheva, Christof Monz, Matteo Negri, Aurélie Névéol, Mariana Neves, Martin Popel, Matt Post, Raphael Rubino, Carolina Scarton, Lucia Specia, Marco Turchi, et al… 2016. Findings of the 2016 Conference on Machine Translation. In Proceedings of the First Conference on Machine Translation: Volume 2, Shared Task Papers, pages 131–198, Berlin, Germany. Association for Computational Linguistics.
[2] Mattia A. Di Gangi, Roldano Cattoni, Luisa Bentivogli, Matteo Negri, and Marco Turchi. 2019. MuST-C: a Multilingual Speech Translation Corpus. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2012–2017, Minneapolis, Minnesota. Association for Computational Linguistics.
[3] Sergey Edunov, Myle Ott, Michael Auli, and David Grangier. 2018. Understanding back-translation at scale. In Proc. of EMNLP, pages 489–500, Brussels, Belgium. Association for Computational Linguistics.
[4] Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, and Luke Zettlemoyer. 2020. Multilingual denoising pre-training for neural machine translation. Transactions of the Association for Computational Linguistics, 8:726–742.
[5] Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. 2020. wav2vec 2.0: A frame- work for self-supervised learning of speech representations. Advances in Neural Information Processing Systems, 33:12449–12460.
[6] Kushal Lakhotia, Eugene Kharitonov, Wei-Ning Hsu, Yossi Adi, Adam Polyak, Benjamin Bolte, Tu-Anh Nguyen, Jade Copet, Alexei Baevski, Abdelrahman Mohamed, et al. 2021. On generative spoken language modeling from raw audio. Transactions of the Association for Computational Linguistics, 9:1336– 1354.
[7] Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. 2021. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3451–3460.
[8] Dong Zhang, Rong Ye, Tom Ko, Wang Mingxuan, and Zhou Yaqian. Dub: Discrete unit backtranslation for speech translation. In Findings in ACL 2023.
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。期待这里可以成为你学习Al前沿知识的高地,分享自己最新工作的沃士,在AI进阶之路上的升级打怪的根据地!更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区





![[高通平台][WLAN] IEEE802.11mc 介绍](https://img-blog.csdnimg.cn/4679ee740569443f9ef1e0403ba584a6.png)