一、数据库的基本概念
1. 什么是数据库
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库。每个数据库都有一个或多个不同的API用于创建、访问、管理、搜索和复制所保存的数据。我们也可以将数据存储在其他地方,例如:纸张、磁带、硬盘等。但是,由于其在计算机软件应用当中的效率问题,我们通常选用数据库来保存和查找数据。
2. 常见的关系型数据库和非关系型数据库
2.1关系型数据库
常见的关系型数据库主要有Oracle、MySQL、Microsoft SQL Server、SQLite等。
-
Oracle:是由美国Oracle公司(甲骨文公司)所推出的关系数据库管理系统。Oracle系统是在数据库管理领域一直享有盛誉的产品,能够处理大量数据的存储和高速访问,特别适合大中型企业或机构使用。
-
MySQL:是一个开源的关系数据库管理系统,由瑞典MySQL AB公司开发,现在属于Oracle公司。MySQL已经成为了最流行的开源数据库系统,常用于网络应用,特别是网页应用。
-
Microsoft SQL Server: 是由Microsoft公司所推出的关系数据库管理系统,以操作简便、功能强大而受到广大用户的喜爱和欢迎。
-
SQLite:是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,其数据库的整体储存在一个独立的磁盘文件中。
关系型数据库的主要特点是数据以表格的形式出现,可以通过SQL语言轻松实现增删改查操作。核心是ACID规则(Atomic原子性,Consistency一致性,Isolation隔离性,Durability持久性)。
2.2 非关系型数据库:
常见的非关系型数据库主要有MongoDB、Redis、Cassandra、HBase等。
-
MongoDB:其特点是面向文档、无模式的数据模型。这种存储方式将类JSON的文档形式存储在数据库中,以达到存储的灵活性。
-
Redis:一款开源的键值对数据库,其特点是全部基于内存进行操作,所以速度非常快。他可以用来做缓存,也可以用来做消息队列、计数器等等。
-
Cassandra:是一种高度分布式的、去中心化的、可扩展的数据库。可以将数据存储在多个节点上,从而解决大数据量下的问题。
-
HBase:是一个开源的非关系型分布式数据库,它是Apache软件基金会的Hadoop项目的一部分。HBase的目标是为Hadoop提供类似于Google BigTable的功能。
非关系型数据库,通常无需固定的表结构,试图解决传统的关系型数据库在大数据和高并发的环境下的分布式存储问题。其核心是CAP理论和BASE理论。
2.3关系型数据库的组织结构
关系型数据库的组织结构通常由以下几个主要部分组成:
-
数据库引擎:数据库引擎是处理所有的数据库操作的主要组件,例如查询、插入、更新和删除。这是关系型数据库最重要的部分,它负责管理数据的实际存储和操作。
-
查询处理器:查询处理器是将客户端的查询请求解析为数据库能理解的格式的部分。在这个过程中,查询处理器将计算出能够最有效地获取数据的方法,这个过程称为查询优化。
-
存储引擎:存储引擎负责存储和检索数据库中的数据。存储引擎坚固且可靠,能够保证数据的稳定存储并且能在必要时进行恢复。
-
负责其他一些功能的额外组件,例如事务管理、备份等。
基于这个基础结构,MySQL等关系型数据库还有以下组成部分:
-
客户服务器模型:MySQL采用了客户/服务器模型,客户机发送请求,服务器返回结果。MySQL提供了各种形式的客户程序,包括命令行程序和图形化程序。
-
数据定义语言(DDL):它指的是操作数据库、表、索引等对象的语句的集合,包括CREATE、DROP、ALTER等命令。
-
数据控制语言(DCL):它主要包括权限的控制,如GRANT、REVOKE等。
-
数据操作语言(DML):它主要包括对数据的操作,如SELECT、INSERT、UPDATE、DELETE等。
-
数据库和表:MySQL可以创建多个数据库,每个数据库可以拥有多个表,这为组织数据提供了一个有效的方式。
-
索引:MySQL支持多种类型的索引,索引可以帮助快速定位特定的数据项。
-
事务管理:MySQL支持ACID事务,这将确保数据的一致性和可靠性。
-
视图:视图可以被看作是一个虚拟的表,它是基于SQL查询的结果。
-
存储过程和函数:MySQL支持存储过程和函数,这将帮助编写复杂的业务逻辑。
-
触发器和事件:MySQL支持触发器和事件,这使得数据库可以自动响应某些数据条件的变化。
通过以上的各个部分,MySQL等关系型数据库可以有效地组织和管理数据。
2.4 库、表、行、字段之间的关系
以mysql数据库为例:
MySQL是一种关系型数据库,它的数据结构按照库、表、行、字段四个层次进行组织。我们可以通过以下方式理解库、表、行、字段之间的关系:
-
库:在
MySQL中,数据库库(Database)类似于一个容器,用来存放表、视图等数据库对象。一套MySQL服务器可以有多个数据库库,每个库之间互相独立,不同的库可以存储不同类型或者用途的数据。 -
表:表(
Table)是库中的一个核心组成部分,它用来存储具有相同结构的数据。比如在一个学生信息管理的数据库库中,我们可能会设计一个学生信息表来存储所有的学生信息。每个库可以包含多个表。 -
字段:字段(
Column)相当于表中的一个属性,比如在学生信息表中,只能输入学号、学生姓名、学生性别等特定信息,每一种特定信息就对应一种字段。一张表可以有一个或者多个字段。 -
行:行(
Row)就是表中的一条记录。比如在学生信息表中,每个学生的信息就会作为一条记录存入表中,这就是行。一张表可以有一个或者多个行。
所以,整个关系可以理解为:一个MySQL数据库由一个或多个数据库库组成,每个数据库库中包含一个或多个表,每个表由字段定义并包含一个或多个行。
二、mysql数据库的安装
1. MySQL 在 Windows 系统下的安装
先去官网下载mysql-installer-community-8.0.19.0.msi执行文件
-
双击
mysql-installer-community-8.0.19.0.msi,启动 MySQL 安装程序。 -
如果弹框提示如下的警告信息,证明你的电脑需要安装额外的
.NET Framework依赖包。此时,先退出 MySQL 的安装程序,去网上下载NDP452-KB2901907-x86-x64-AllOS-ENU.exe,启动.NET Framework 4.5.2的安装程序。![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tGQfilGN-1689688301672)(./imgs/0.jpg)]](https://img-blog.csdnimg.cn/aece47da53134637abfe652b083fcbff.png)
-
重新启动 MySQL 的安装程序,看到如下界面:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-80tPtHC8-1689688301675)(./imgs/1.jpg)]](https://img-blog.csdnimg.cn/76b6bfb50a334ae38de993e64868f185.png)
-
进入如下界面:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TZ0dc7uz-1689688301675)(./imgs/2.jpg)]](https://img-blog.csdnimg.cn/4d161aeee7d04d15b84bfa5e6e2dd721.png)
-
正在安装依赖项:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EFQUz4NU-1689688301676)(./imgs/3.jpg)]](https://img-blog.csdnimg.cn/f262b9ab96b944ce92233e70ac69dbd8.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vnLtrrpL-1689688301677)(./imgs/4.jpg)]](https://img-blog.csdnimg.cn/ab6e966b73b84d4fa7e8c7d65bcb4364.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-w04JkREj-1689688301678)(./imgs/5.jpg)]](https://img-blog.csdnimg.cn/fc7d6a452a4f40fa926da3e4849b8d30.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VS1Q518j-1689688301682)(./imgs/6.jpg)]](https://img-blog.csdnimg.cn/3944b03f60b74fa0bce3454dea743d7e.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GtKM2Tc8-1689688301684)(./imgs/7.jpg)]](https://img-blog.csdnimg.cn/0334c63f11a94e5a8da7347de665edc1.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HPXqO5P5-1689688301684)(./imgs/9.jpg)]](https://img-blog.csdnimg.cn/ccbc8e44b2774a14b14fe92a27c9300e.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UAQ3A3Zf-1689688301685)(./imgs/10.jpg)]](https://img-blog.csdnimg.cn/960a1efc3a0342538cf290b66b6f7c86.png)
-
完成依赖项的安装:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0iOB7KUA-1689688301686)(./imgs/11.jpg)]](https://img-blog.csdnimg.cn/09b2771b5c4049b9a9d3b639bbd660bf.png)
此时,会弹出如下警告窗,直接点击 Yes 即可:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EtymeB0X-1689688301687)(./imgs/12.jpg)]](https://img-blog.csdnimg.cn/dc7153ac173b4a16a3003ea40832ffe0.png)
-
进入 MySQL 的安装页面:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3YyC4A8t-1689688301687)(./imgs/14.jpg)]](https://img-blog.csdnimg.cn/03ab1540e9c644febb1d6383dd0fcecd.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EOjgGjNa-1689688301688)(./imgs/15.jpg)]](https://img-blog.csdnimg.cn/946e23fbbfeb4672b9f64abad7e23c78.png)
-
完成 MySQL 功能项的安装:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jXygghkp-1689688301689)(./imgs/16.jpg)]](https://img-blog.csdnimg.cn/3eb75e78223544c9b7aeeb15d77a5eb0.png)
-
配置 MySQL:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VuMy54cg-1689688301690)(./imgs/17.jpg)]](https://img-blog.csdnimg.cn/fe941ea9e2ba4bd6b937ddf585b9eecc.png)
-
选择 MySQL 数据库的运行模式:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1awtfZIf-1689688301691)(./imgs/18.jpg)]](https://img-blog.csdnimg.cn/12ad41bbbbe5425c88443e27466f0c94.png)
-
设置网络模式:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oh3c1k2v-1689688301692)(./imgs/19.jpg)]](https://img-blog.csdnimg.cn/d72674ac79ff4cde9ef97d552a348320.png)
-
配置身份认证方式:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nacWqhIM-1689688301693)(./imgs/20.jpg)]](https://img-blog.csdnimg.cn/148f77780c414b7380cf10e24e345fcf.png)
-
将 MySQL 的默认 root 用户密码,设置为 admin123
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iLDW02bm-1689688301694)(./imgs/21.jpg)]](https://img-blog.csdnimg.cn/beac90ccdae0416c9d2631a3f4970b43.png)
-
将 MySQL 配置为 Windows 的服务:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7GKIIW24-1689688301694)(./imgs/22.jpg)]](https://img-blog.csdnimg.cn/d6f1cdfce76c4bc7af0f5ee07747c445.png)
-
保存刚才对 MySQL 配置的修改:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1FwvaoN3-1689688301695)(./imgs/23.jpg)]](https://img-blog.csdnimg.cn/4116aca132bd462684229addaf835db4.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-geXbqw4t-1689688301695)(./imgs/24.jpg)]](https://img-blog.csdnimg.cn/66124cff088a49a1ab12144bae4637a8.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gUGr9NXN-1689688301696)(./imgs/25.jpg)]](https://img-blog.csdnimg.cn/a42ad9eedbc74c53ae1cd2d6f6906d4c.png)
-
继续完成后续的配置流程:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UR0uyOKD-1689688301697)(./imgs/26.jpg)]](https://img-blog.csdnimg.cn/e8458994ee4b4cc2aadd489f1b57e842.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VZTcrcav-1689688301697)(./imgs/27.jpg)]](https://img-blog.csdnimg.cn/0aa54b621c7d4bf0baa0adcc79eca315.png)
-
最后一个配置项:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dBY5roBs-1689688301698)(./imgs/28.jpg)]](https://img-blog.csdnimg.cn/4397d91a7c184df9888488640bb97d22.png)
测试能否正常连接到刚才安装的 MySQL 数据库:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-i0Ejv1vv-1689688301699)(./imgs/29.jpg)]](https://img-blog.csdnimg.cn/c7337d6325c5483295853a863df30ed1.png)
-
保存刚才的配置:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Cj3i35mb-1689688301700)(./imgs/30.jpg)]](https://img-blog.csdnimg.cn/a84ff90a0a284f1eb82bd3ea9bdfa333.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uL4XuYPU-1689688301701)(./imgs/31.jpg)]](https://img-blog.csdnimg.cn/a1157d7c431843e1842e512e3faad157.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yk1HByFR-1689688301701)(./imgs/32.jpg)]](https://img-blog.csdnimg.cn/b135cd2f5fe1413d9e44b1855bd71c63.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EAt0bMxx-1689688301702)(./imgs/33.jpg)]](https://img-blog.csdnimg.cn/bff6c202055d44eaa50942e5f9f04879.png)
-
完成 MySQL 的安装与配置:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gtZLXDyY-1689688301702)(./imgs/34.jpg)]](https://img-blog.csdnimg.cn/9ceede90f7f34f8e8b89138e960b4d7a.png)
-
验证是否安装成功
找到安装路径bin
从这了打开shell,输入
mysql -V
查看版本
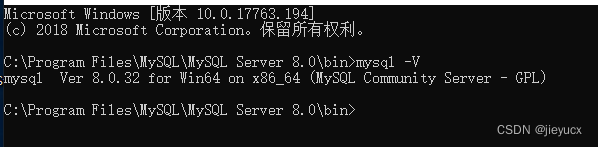
出现上图所示,代表安装成功
- 配置环境变量
将你的mysql执行目录C:\Program Files\MySQL\MySQL Server 8.0\bin,配置到path下面即可
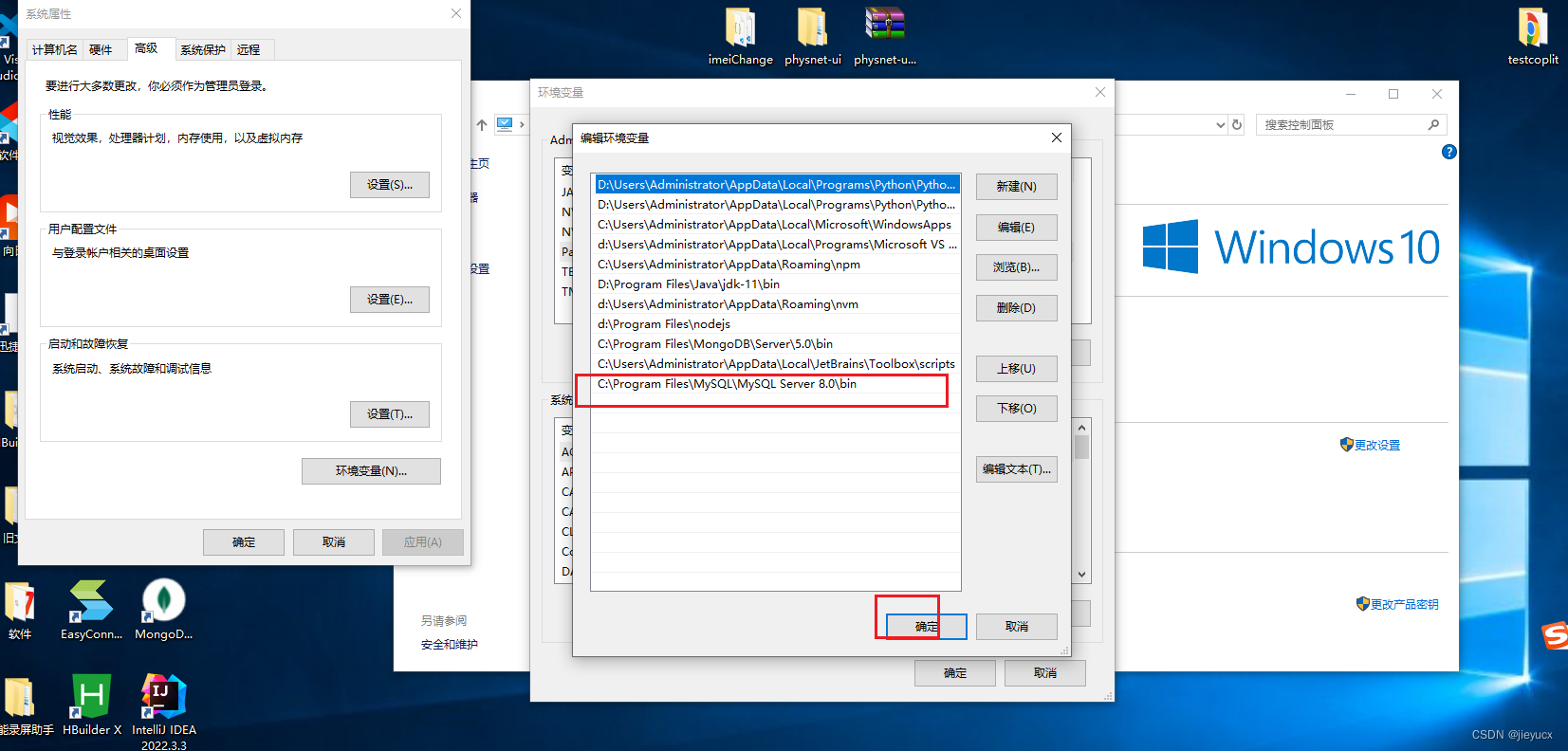
配置完成之后,在桌面打开shell,输入
mysql -V
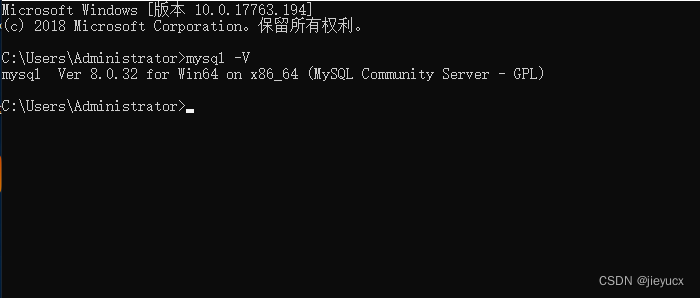
如上图所示代表环境变量配置完成。
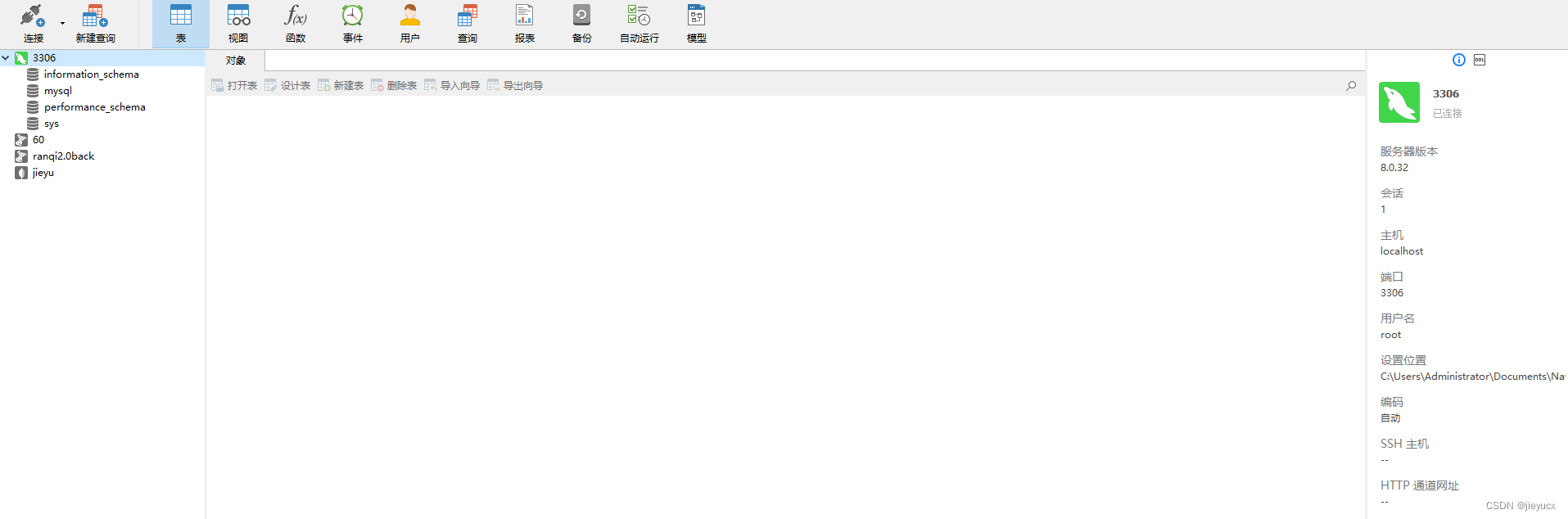
2. 可视化工具介绍
2.1 Navicat Premium

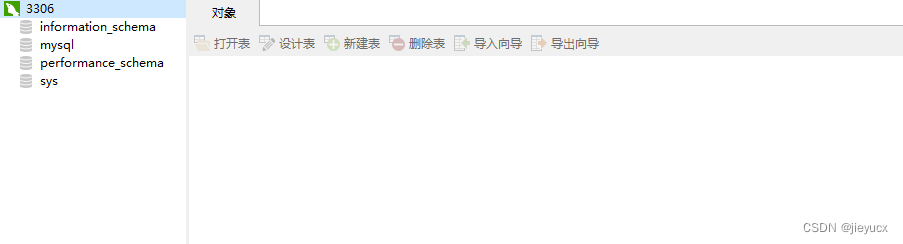
2.2 Navicat for MySQL

三、sql基本使用
1. 什么是sql,以及使用时的注意点
SQL,全称为Structured Query Language,即结构化查询语句,是一种用于操作和定义数据库系统的非过程化语言。它最初被设计用于处理在IBM公司开发的关系数据库中的数据。现如今,SQL已经成为了所有关系数据库的标准查询语言。
使用SQL时,应注意以下几点:
SQL语句中的单词不区分大小写,但是值与表名可以区分大小写(取决于数据库配置或者类型)。- 应该尽量避免
SQL注入攻击。这种攻击是通过插入恶意SQL代码来查询、修改、删除数据。因此,任何时候都应该对用户输入进行严格的检查,例如使用预处理语句(prepared statements)或者参数化查询。 SQL语句可能会在解析阶段或者运行阶段失败,所以需要有正确处理错误的机制。例如,插入或者更新数据可能会违反数据的完整性约束,查询可能会涉及到不存在的表或者列等等。- 性能考虑:
SQL语句的编写方式会影响查询的性能。例如,应尽可能避免在WHERE子句中使用函数或者计算,这会导致索引无法使用。另外,也应避免在大表中做全表扫描,此时应为常常被查询的列建立索引。 - 尽量保持
SQL语句的简洁,避免过于复杂。清晰和直观的SQL语句更容易被他人理解和维护。 SQL的执行顺序并不是按照编写顺序,需要了解执行的逻辑顺序,方便进行查询语句的设计。- 注意数据类型的转换和比较,不同的数据类型不能直接比较。
- 正确使用事务,确保数据的一致性和完整性。
2. sql能做什么
通过SQL,我们可以进行以下操作:
- 数据查询:
SQL可以用于从数据库中选择和提取数据。 - 数据操作:
SQL可以插入新的数据、更新现有数据,或者删除数据库中的数据。 - 数据定义:
SQL可以创建、修改或删除数据库以及其内部对象(如表、视图、触发器等)的结构。 - 数据控制:
SQL可以配置用户对数据库的访问权限、管理数据的安全性和完整性。
3. sql中的select语句
SQL的SELECT语句用于从数据库中选择数据。结果以结果表的形式返回,这些结果表又称为结果集。
假设我们有一个名为"users"的数据库表,包含字段"ID","Name"和"Age",如下:
| ID | Name | Age |
|---|---|---|
| 1 | 张三 | 18 |
| 2 | 李四 | 20 |
| 3 | 王五 | 23 |
要选择并显示表中的所有内容,您可以使用以下SQL语句:
SELECT * FROM users;
结果:
| ID | Name | Age |
|---|---|---|
| 1 | 张三 | 18 |
| 2 | 李四 | 20 |
| 3 | 王五 | 23 |
如果您只希望选择"Name"列,可以使用以下语句:
SELECT Name FROM users;
结果:
| Name |
|---|
| 张三 |
| 李四 |
| 王五 |
如果你想查询年龄大于18岁的用户,你可以使用这样的语句:
SELECT * FROM users WHERE Age > 18;
结果:
| ID | Name | Age |
|---|---|---|
| 2 | 李四 | 20 |
| 3 | 王五 | 23 |
如果你只需要查询张三的年龄,你可以使用这样的语句:
SELECT Age FROM users WHERE Name='张三';
结果:
| Age |
|---|
| 18 |
这就是SQL SELECT语句的基本使用,通过修改列名和添加WHERE子句,您可以选择数据表中的特定数据。
除了这些基础的查询外,SELECT语句还有很多其它的操作,如通过ORDER BY子句对结果进行排序,通过JOIN子句联接多个表,等等。在更复杂的情况下,你也可以使用聚合函数(如 COUNT, AVG, SUM等)和GROUP BY/HAVING子句进行更高级的数据查询和分析,但这属于更高级的主题了
4. sql中的insert into 语句
INSERT INTO 语句用来在数据库的表中插入新的行。
示例:
-
插入一条数据:在
user表中插入数据 (4,马六,25)。语句:
INSERT INTO user (id, name, age) VALUES (4, ‘马六’, 25);
结果:
id name age 1 张三 18 2 李四 20 3 王五 23 4 马六 25 -
插入多条数据:在
user表中插入数据 (5,赵七,21)和(6,孙八,24)语句:
INSERT INTO user (id, name, age) VALUES (5, ‘赵七’, 21), (6, ‘孙八’, 24);
结果:
id name age 1 张三 18 2 李四 20 3 王五 23 4 马六 25 5 赵七 21 6 孙八 24 -
如果不指定字段而插入数据,值必须和表的定义顺序一致。
语句:
INSERT INTO user VALUES (7, ‘吴九’, 27);
结果:
id name age 1 张三 18 2 李四 20 3 王五 23 4 马六 25 5 赵七 21 6 孙八 24 7 吴九 27
以上是SQL中的INSERT INTO语句的基本使用。
5. sql中的update语句
SQL中的UPDATE语句用于修改表中已存在的记录。
具体语法:
UPDATE table_name
SET column1 = value1, column2 = value2...., columnN = valueN
WHERE [condition];
在上面的语法中,你需要把table_name替换为你要更新记录的表名,column1到columnN是你的表中的列名,value1到valueN是新插入的值。
WHERE限定子用来分别选择你想更新的记录行。如果你不指定WHERE限定子,所有的记录都会被更新。
下面举例说明:
假设我们有以下表(user)中的三条数据:
| ID | Name | Age |
|---|---|---|
| 1 | 张三 | 18 |
| 2 | 李四 | 20 |
| 3 | 王五 | 23 |
如果我们想更新"李四"的年龄为25,我们可以这样做:
UPDATE user
SET age = 25
WHERE name = '李四';
更新后的表数据:
| ID | Name | Age |
|---|---|---|
| 1 | 张三 | 18 |
| 2 | 李四 | 25 |
| 3 | 王五 | 23 |
如果我们想将年龄大于20的人的名字全部改成"老王",我们可以这样做:
UPDATE user
SET name = '老王'
WHERE age > 20;
更新后的表数据:
| ID | Name | Age |
|---|---|---|
| 1 | 张三 | 18 |
| 2 | 老王 | 25 |
| 3 | 老王 | 23 |
注意:UPDATE语句要谨慎使用,尤其是没有添加WHERE条件时,会导致表中的所有数据被更改,可能带来灾难性后果。
6. sql中的delete语句
SQL中的DELETE语句用来删除表中的记录。
具体的语法是:
DELETE FROM 表名称 WHERE 条件。
比如我们有一个user表
| id | name | age |
|---|---|---|
| 1 | 张三 | 18 |
| 2 | 李四 | 20 |
| 3 | 王五 | 23 |
如果我们想要删除id为1的记录,我们可以使用以下SQL语句:
DELETE FROM user WHERE id = 1;
执行这条SQL语句后,原来的user表:
| id | name | age |
|---|---|---|
| 1 | 张三 | 18 |
| 2 | 李四 | 20 |
| 3 | 王五 | 23 |
会变成:
| id | name | age |
|---|---|---|
| 2 | 李四 | 20 |
| 3 | 王五 | 23 |
如果我们想要删除年龄大于18的记录,我们可以使用以下SQL语句:
DELETE FROM user WHERE age > 18;
执行这条SQL语句后,原来的user表:
| id | name | age |
|---|---|---|
| 1 | 张三 | 18 |
| 2 | 李四 | 20 |
| 3 | 王五 | 23 |
会变成:
| id | name | age |
|---|---|---|
| 1 | 张三 | 18 |
如果我们想要删除所有的记录,我们可以使用以下SQL语句:
DELETE FROM user;
执行这条SQL语句后,原来的user表:
| id | name | age |
|---|---|---|
| 1 | 张三 | 18 |
| 2 | 李四 | 20 |
| 3 | 王五 | 23 |
会变成一个空表:
| id | name | age |
|---|
注意:DELETE语句要慎用,尤其是不带WHERE子句的DELETE,因为一旦执行,表中的数据将全部被删除,恢复非常困难。在执行DELETE操作之前,一定要备份重要数据。
7. sql中的and和or运算符
在 SQL 中,AND 与 OR 是两种逻辑运算符,用于连接多个查询条件。AND 运算符返回所有条件为真的行,OR 运算符返回任何条件为真的行。
假设你的user表格如下:
| id | name | age |
|---|---|---|
| 1 | 张三 | 18 |
| 2 | 李四 | 20 |
| 3 | 王五 | 23 |
举例说明:
- 使用
AND举例:
查询年龄大于18并且名称为李四的人。
SELECT * FROM user WHERE age > 18 AND name = '李四';
结果:
| id | name | age |
|---|---|---|
| 2 | 李四 | 20 |
这个查询的结果包含了所有年龄大于18并且名称为李四的人。如果一个人的年龄小于或等于18,或者他们的名字不是李四,那么他们就不会被包含在这个结果集中。
- 使用
OR举例:
查询年龄等于18或者名称为王五的人。
SELECT * FROM user WHERE age = 18 OR name = '王五';
结果:
| id | name | age |
|---|---|---|
| 1 | 张三 | 18 |
| 3 | 王五 | 23 |
这个查询返回的每个人或者是年龄等于18,或者是名称是王五。只要满足这两个条件中的任何一个,那么这个人就会被包含在这个结果集中。
AND和OR混合使用:
查询年龄等于18和名称为张三或者姓名为王五的人。
SELECT * FROM user WHERE (age = 18 AND name = '张三') OR name = '王五';
结果:
| id | name | age |
|---|---|---|
| 1 | 张三 | 18 |
| 3 | 王五 | 23 |
在使用 AND 和 OR 时,一定要注意括号的使用,因为 AND 优先级高于 OR。在处理复杂的逻辑表达式时,使用括号能够使语句更加清晰,也能确保运算的优先级。
8. sql 中的order by子句的用法
在SQL中,ORDER BY语句用于对查询结果的记录进行排序。你可以按照一个或者多个列进行排序。默认情况下,ORDER BY语句按照升序排序。如果你希望按照降序排序,可以使用关键字 DESC。
举一个例子,我们可以用 ORDER BY 语句对user表中的age进行排序:
SELECT * FROM user ORDER BY age;
查询结果将会是:
| id | name | age |
|---|---|---|
| 1 | 张三 | 18 |
| 2 | 李四 | 20 |
| 3 | 王五 | 23 |
如果我们需要按照降序排序,我们可以添加 DESC 关键字:
SELECT * FROM user ORDER BY age DESC;
查询结果将会是:
| id | name | age |
|---|---|---|
| 3 | 王五 | 23 |
| 2 | 李四 | 20 |
| 1 | 张三 | 18 |
你也可以使用两个或更多的列进行排序。如,我们可以先按 age 对数据进行排序,然后再按 id 进行排序:
SELECT * FROM user ORDER BY age, id;
查询结果将会是:
| id | name | age |
|---|---|---|
| 1 | 张三 | 18 |
| 2 | 李四 | 20 |
| 3 | 王五 | 23 |
注意,当 age 相同的时候,才会按照 id 进行排序。在该例子中,因为所有的 age 都是不同的,所以看不出按照 id 列的排序效果。
9.sql中的count函数的使用
COUNT是SQL中的一个聚合函数,用于计算查询结果中的记录数。
假设你的user表格如下:
| id | name | age |
|---|---|---|
| 1 | 张三 | 18 |
| 2 | 李四 | 20 |
| 3 | 王五 | 23 |
- 计算所有用户数量:
SQL语句:SELECT COUNT(*) FROM user
结果:3
说明当前表中有3个用户。
- 计算年龄大于18的用户数量:
SQL语句:SELECT COUNT(*) FROM user WHERE age > 18
结果:2
说明有2个用户年龄大于18。
- 计算所有不同的年龄的用户数量:
SQL语句:SELECT COUNT(DISTINCT age) FROM user
结果:3
说明在这个用户表中有3种不同的年龄。
注意:COUNT会计算NULL字段,而COUNT(column)不会计算NULL字段。例如,如果name字段有空值,COUNT(name)只会计算有值的列,而 COUNT(*)会计算所有的记录数。
- 计算有非空姓名的用户数量:
SQL语句:SELECT COUNT(name) FROM user
结果假定所有的 name 都非空,那么结果是:3,因为我们有3个用户且他们的name字段都非空。
10. sql中的as关键字的用法
在SQL中,我们可以使用"AS"关键字给查询出来的结果列取别名。这可以增强查询结果的可读性,尤其在处理复杂的查询和连接时,别名就显得更为重要。
例子1:
如user表中
| id | name | age |
|---|---|---|
| 1 | 张三 | 18 |
| 2 | 李四 | 20 |
| 3 | 王五 | 23 |
我们可以把列名称"id",“name”,“age"分别改为"用户ID”,“用户名字"和"用户年龄”。
为了给一个列设定别名,我们可以在列名称后添加"AS"关键字,然后是你希望设定的别名。
例如:
SELECT id AS 用户ID, name AS 用户名字, age AS 用户年龄 FROM user;
这个查询会返回以下结果:
| 用户ID | 用户名字 | 用户年龄 |
|---|---|---|
| 1 | 张三 | 18 |
| 2 | 李四 | 20 |
| 3 | 王五 | 23 |
这样,我们就可以看到,每一列的名称都替换成了我们设定的别名,使我们的结果更具可读性。
另外,有一点需要注意,我们可以省略AS关键字,直接使用空格将列名和别名分隔开。例如:
SELECT id 用户ID, name 用户名字, age 用户年龄 FROM user;
这个查询和上面的查询有相同的结果。然而,为了可读性和避免混淆,建议总是使用AS关键字来设定别名。
例子2:
这个例子中,我们使用 COUNT 函数和 AS 关键字同时使用,计算名字不同的用户的数量,并给结果取别名为 unique_user_count。
SELECT COUNT(DISTINCT name) AS `unique_user_count`
FROM user;
结果会是:
unique_user_count
3
在这个查询中,我们使用 AS 关键词给结果列取别名为 unique_user_count。我们使用了 COUNT(DISTINCT name) 函数来计算名字不同的用户的数量。每个用户的姓名只被计算一次,即使他们有多个条目。因为我们的数据中每个用户的名字都是唯一的,所以返回结果为3。
四、在node中操作mysql数据库
1. 使用mysql模块连接mysql数据库
在Node.js中连接MySQL数据库需要使用一个叫做mysql的npm模块。下面的步骤介绍如何在Node.js中链接MySQL数据库。
步骤一:在你的项目中安装mysql模块
打开命令行/终端并键入以下命令:
npm install mysql
这将在你的项目中安装mysql模块。
步骤二:连接到MySQL数据库
一旦你安装了mysql模块,就可以通过在你的应用中包含以下代码来连接到MySQL数据库:
var mysql = require('mysql'); // 引入mysql模块
var connection = mysql.createConnection({
host : 'localhost', // 数据库地址
user : 'me', // 数据库用户
password : 'secret', // 数据库密码
database : 'my_db' // 要连接的数据库
});
connection.connect(); // 连接数据库
connection.query('SELECT 1 + 1 AS solution', function (error, results, fields) { // 执行查询
if (error) throw error;
console.log('The solution is: ', results[0].solution);
});
connection.end(); // 结束连接
在以上示例中,我们首先引入mysql模块,然后使用mysql.createConnection()方法创建一个表示与MySQL数据库的连接的对象。createConnection方法需要一个包含主机名、用户名、密码和数据库名的对象。
然后,我们调用connection.connect方法使连接在调用时有效。
接下来,我们使用connection.query方法来执行SQL查询。这个方法希望有一个表示查询的字符串,以及一个当查询结束时被执行的回调函数。这个回调函数会接收三个参数:一个错误对象、一个包含结果的对象和一个包含字段信息的对象。
最后,我们调用connection.end方法来结束这个连接。
请注意,您需要使用自己的数据库信息替换上述代码中的占位符(如“localhost”,“me”,“secret”等)。
2. 增删改查操作
2.1 select查询语句
var selectSQL = "SELECT * FROM user";
// 查询数据库
connection.query(selectSQL, function (err, result) {
if(err){
console.log('[SELECT ERROR] - ',err.message);
return;
}
// 打印查询结果
console.log(result);
});
// 关闭数据库连接
connection.end();
在这个例子中,我们打开了一个连接,执行了一个"select * from user"语句来查询user表的所有数据,成功后返回结果并关闭了连接。
查询结果应该如下(示例):
[
{ id: 1, name: '张三', age: 18 },
{ id: 2, name: '历史', age: 20 },
{ id: 3, name: '王五', age: 23 }
]
返回的result是一个对象数组,每一个对象代表一条记录,对象的属性名和表的字段名相同,属性值和相应的字段值相同。
2.2 insert into 插入语句
var userAddSql = "INSERT INTO user(id,name,age) VALUES(?,?,?)";
var userAddSql_Params = [4, "赵六", 21];
connection.query(userAddSql, userAddSql_Params, function (err, result) {
if (err) {
console.log("[INSERT ERROR] - ", err.message);
return;
}
//Console中的输出:
console.log("--------------------------INSERT----------------------------");
//Insert success
console.log("INSERT ID:", result);
console.log("-----------------------------------------------------------------\n\n");
});
打印结果如下:
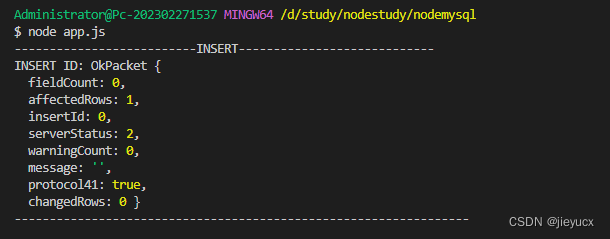
我们可以去数据库看看是否真的插入成功
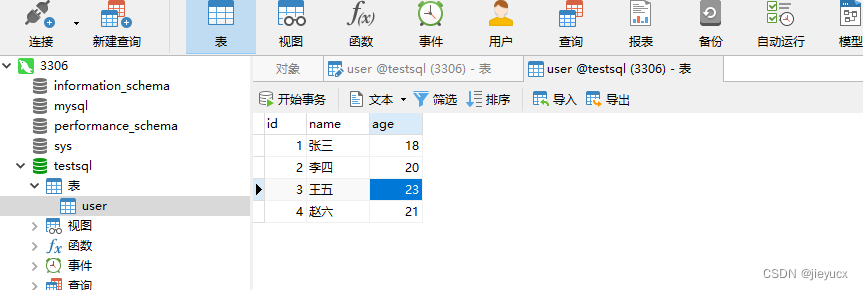
可以看到确实插入成功了。
另一种插入方式,
var userAddSql = "INSERT INTO user set ?";
var userAddSql_Params = { id: 5, name: "赵六", age: 21 };
connection.query(userAddSql, userAddSql_Params, function (err, result) {
if (err) {
console.log("[INSERT ERROR] - ", err.message);
return;
}
//Console中的输出:
console.log("--------------------------INSERT----------------------------");
//Insert success
console.log("INSERT ID:", result);
console.log("-----------------------------------------------------------------\n\n");
});
这样的话我们就不用写那么多字段了,可以让insert语句更简洁,让代码更具可读性。
2.3 update更新语句
更新之前的表数据
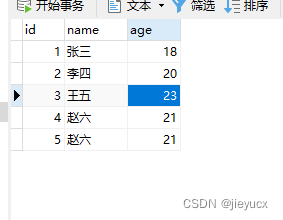
var userModSql = "UPDATE user SET name = ?,age = ? WHERE id = ?";
var userModSql_Params = ["吴七", 26, 5];
connection.query(userModSql, userModSql_Params, function (err, result) {
if (err) {
console.log("[UPDATE ERROR] - ", err.message);
return;
}
console.log("--------------------------UPDATE----------------------------");
console.log("UPDATE affectedRows", result.affectedRows);
if (result.affectedRows > 0) {
console.log("UPDATE success");
} else {
console.log("UPDATE fail");
}
console.log("-----------------------------------------------------------------\n\n");
}
);
打印结果如下:
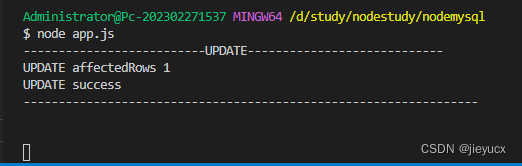
可以看到数据库中的表数据也做了相应的更新
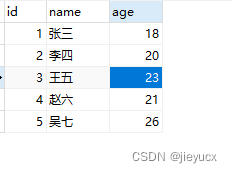
便捷写法
// 更新操作便捷写法
var userModSql = "UPDATE user SET ? WHERE ?";
var user = { name: "赵六1", age: 25 , id: 4};
connection.query(userModSql, [user, user.id], function (err, result) {
if (err) {
console.log("[UPDATE ERROR] - ", err.message);
return;
}
console.log("--------------------------UPDATE----------------------------");
console.log("UPDATE affectedRows", result.affectedRows);
if (result.affectedRows > 0) {
console.log("UPDATE success");
} else {
console.log("UPDATE fail");
}
console.log("-----------------------------------------------------------------\n\n");
}
);
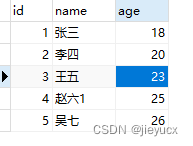
2.4 delete删除数据
// 删除操作
var userDelSql = "DELETE FROM user where id=5";
connection.query(userDelSql, function (err, result) {
if (err) {
console.log("[DELETE ERROR] - ", err.message);
return;
}
console.log("--------------------------DELETE----------------------------");
if (result.affectedRows > 0) {
console.log("DELETE success");
}else {
console.log("DELETE fail");
}
console.log("-----------------------------------------------------------------\n\n");
}
);
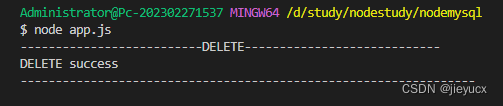
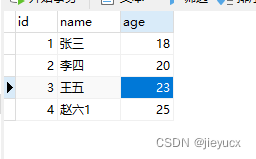
可以看到成功删除了id=5的数据
五、总结
好拉,以上就是我们对Node.js中如何通过mysql实现数据持久化的基本介绍啦。我们详细阐述了使用mysql实现数据持久化的步骤和注意事项,为你在实际开发中快速上手打下了基础。希望本文对你在使用Node.js进行后端开发,特别是在处理和mysql数据库的交互时,能提供必要的帮助和支持。注重数据底层的操作,可以帮助我们在处理复杂业务逻辑时,有更高效和稳定的表现。