一、模型和数据集介绍
1.1 预训练模型
chinese-roberta-wwm-ext 是基于 RoBERTa 架构下开发,其中 wwm 代表 Whole Word Masking,即对整个词进行掩码处理,通过这种方式,模型能够更好地理解上下文和语义关联,提高中文文本处理的准确性和效果。
与原始的 BERT 模型相比,chinese-roberta-wwm-ext 在训练数据规模和训练步数上做了一些调整,以进一步提升模型的性能和鲁棒性。并且在大规模无监督语料库上进行了预训练,使其具备强大的语言理解和生成能力。它能够广泛应用于各种自然语言处理任务,如文本分类、命名实体识别、情感分析等。我们可以使用这个模型作为基础,在不同的任务上进行微调和迁移学习,以实现更准确、高效的中文文本处理。
huggingface地址:https://huggingface.co/hfl/chinese-roberta-wwm-ext
进到 huggingface 中下载预训练模型:
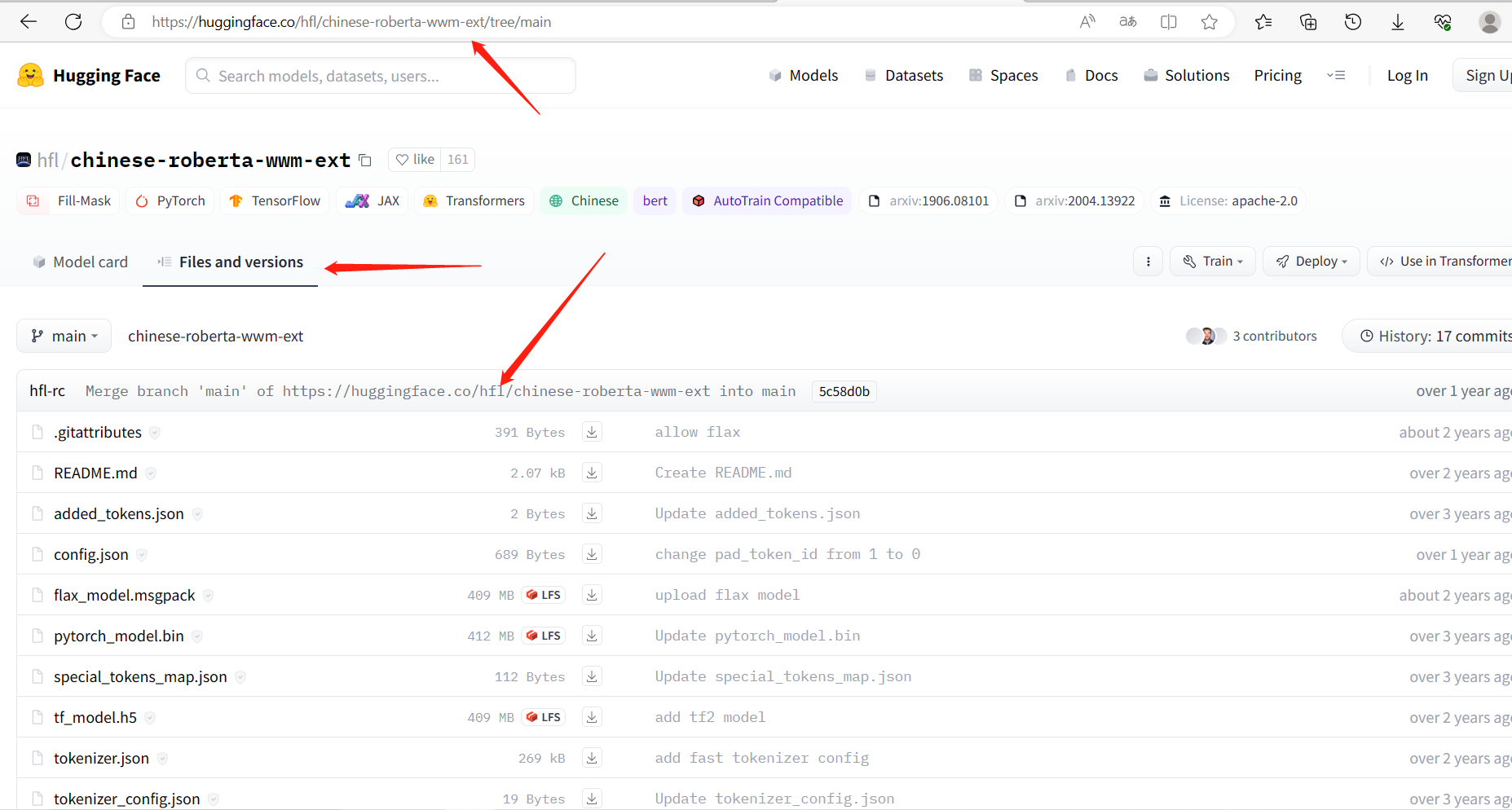
1.2 数据集
数据集采用 SMP2020微博情绪分类评测 ,进入下面链接下载数据集:
https://smp2020ewect.github.io/
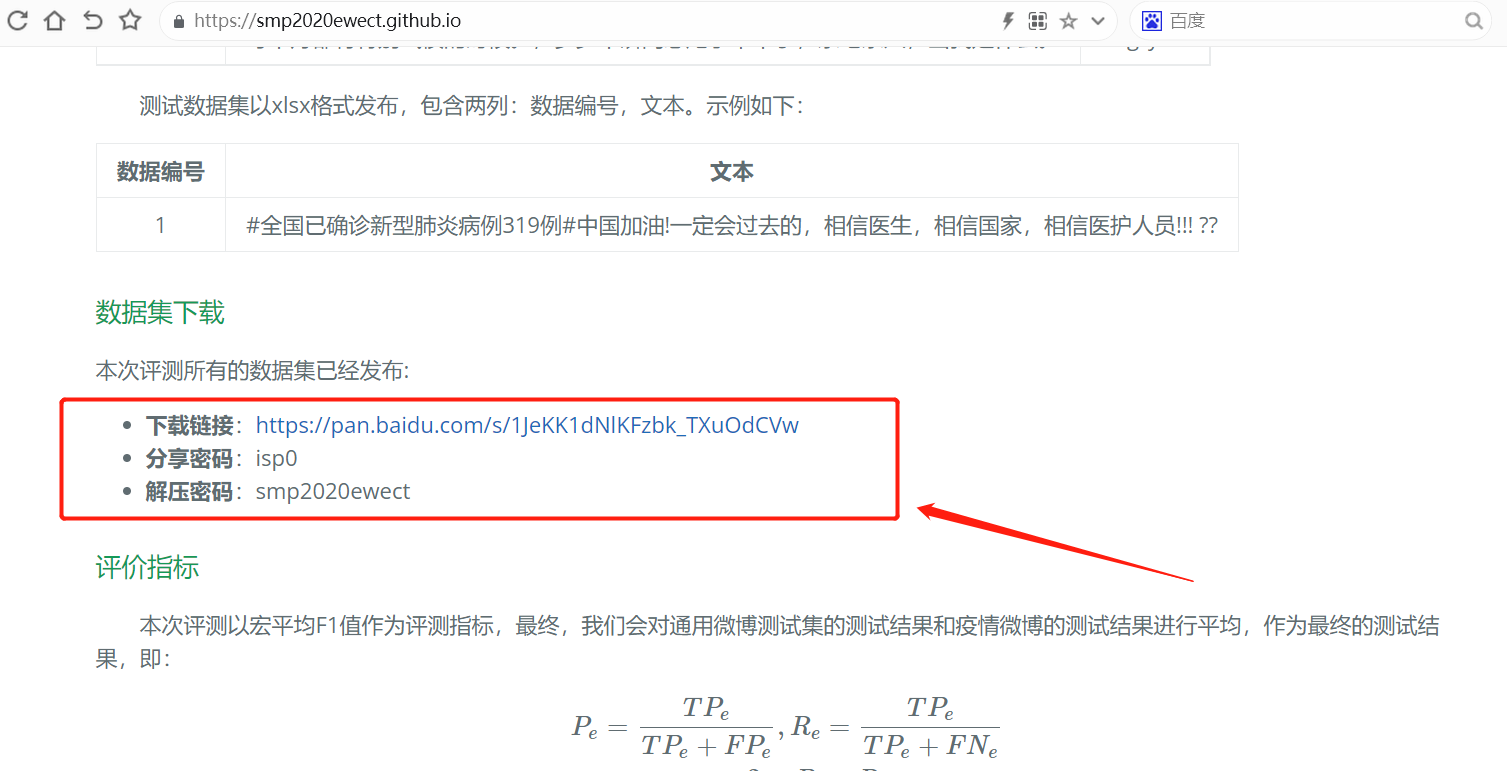
下载后数据分了三种类型,训练集、测试集、验证集:
数据的格式为 JSON 格式,结构如下:

其中 label 为当前 content 的分类,一共分了 6 种类别,如下所示:
| label | 说明 |
|---|---|
| fear | 恐惧 |
| neutral | 无情绪 |
| sad | 悲伤 |
| surprise | 惊奇 |
| angry | 愤怒 |
| happy | 积极 |
二、模型微调训练
2.1、处理数据集构建DataLoader
from transformers import BertTokenizer
from torch.utils.data import DataLoader, RandomSampler, TensorDataset
import numpy as np
import torch
import json
import os
class GenDateSet():
def __init__(self, tokenizer, train_file, val_file, label_dict, max_length=128, batch_size=10):
self.train_file = train_file
self.val_file = val_file
self.max_length = max_length
self.batch_size = batch_size
self.label_dict = label_dict
self.tokenizer = tokenizer
def gen_data(self, file):
if not os.path.exists(file):
raise Exception("数据集不存在")
input_ids = []
input_types = []
input_masks = []
labels = []
with open(file, encoding='utf8') as f:
data = json.load(f)
if not data:
raise Exception("数据集不存在")
# 处理数据
for index, item in enumerate(data):
text = item['content']
label = item['label']
tokens = self.tokenizer(text, padding="max_length", truncation=True, max_length=self.max_length)
input_id, types, masks = tokens['input_ids'], tokens['token_type_ids'], tokens['attention_mask']
input_ids.append(input_id)
input_types.append(types)
input_masks.append(masks)
y_ = self.label_dict[label]
labels.append([y_])
if index % 1000 == 0:
print('处理', index, '条数据')
# 构建 TensorDataset
data_gen = TensorDataset(torch.LongTensor(np.array(input_ids)),
torch.LongTensor(np.array(input_types)),
torch.LongTensor(np.array(input_masks)),
torch.LongTensor(np.array(labels)))
# 打乱
sampler = RandomSampler(data_gen)
# 构建 DataLoader
return DataLoader(data_gen, sampler=sampler, batch_size=self.batch_size)
def gen_train_data(self):
# 生成训练集
return self.gen_data(self.train_file)
def gen_val_data(self):
# 生成验证集
return self.gen_data(self.val_file)
2.2 构建模型迭代训练
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch.nn as nn
from tqdm import tqdm
from gen_datasets import GenDateSet
# 标签结构
label_dict = {
'fear': 0,
'neutral': 1,
'sad': 2,
'surprise': 3,
'angry': 4,
'happy': 5
}
# 预训练模型位置
model_dir = 'D:\\AIGC\\model\\chinese-roberta-wwm-ext'
# 这里暂时使用测试集训练,数据较少
train_file = 'data/usual_train.txt'
# train_file = 'data/usual_test_labeled.txt'
# 验证集
val_file = 'data/virus_eval_labeled.txt'
# 训练模型存储位置
save_model_path = './model/'
# 最大长度
max_length = 128
# 分类数
num_classes = 6
batch_size = 10
epoch = 10
def val(model, device, data):
model.eval()
test_loss = 0.0
acc = 0
for (input_id, types, masks, y) in tqdm(data):
input_id, types, masks, y = input_id.to(device), types.to(device), masks.to(device), y.to(device)
with torch.no_grad():
y_ = model(input_id, token_type_ids=types, attention_mask=masks)
logits = y_['logits']
test_loss += nn.functional.cross_entropy(logits, y.squeeze())
pred = logits.max(-1, keepdim=True)[1]
acc += pred.eq(y.view_as(pred)).sum().item()
test_loss /= len(data)
return acc / len(data.dataset)
def main():
# 加载 tokenizer 和 model
tokenizer = AutoTokenizer.from_pretrained(model_dir)
model = AutoModelForSequenceClassification.from_pretrained(model_dir, num_labels=num_classes)
# 加载数据集
dateset = GenDateSet(tokenizer, train_file, val_file, label_dict, max_length, batch_size)
# 训练集
train_data = dateset.gen_train_data()
# 验证集
val_data = dateset.gen_val_data()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.train()
model = model.to(device)
# 优化器
optimizer = torch.optim.Adam(model.parameters(), lr=1e-5)
best_acc = 0.0
for epoch_index in range(epoch):
batch_epoch = 0
for (input_id, types, masks, y) in tqdm(train_data):
input_id, types, masks, y = input_id.to(device), types.to(device), masks.to(device), y.to(device)
# 前向传播
outputs = model(input_id, token_type_ids=types, attention_mask=masks, labels=y)
# 梯度清零
optimizer.zero_grad()
# 计算 loss
loss = outputs.loss
# 反向传播
loss.backward()
optimizer.step()
batch_epoch += 1
if batch_epoch % 10 == 0:
print('Train Epoch:', epoch_index, ' , batch_epoch: ', batch_epoch, ' , loss = ', loss.item())
# 评估准确度
acc = val(model, device, val_data)
print('Train Epoch:', epoch_index, ' val acc = ', acc)
# 存储 best model
if best_acc < acc:
# torch.save(model.state_dict(), save_model_path)
model.save_pretrained("./model")
tokenizer.save_pretrained("./model")
best_acc = acc
if __name__ == '__main__':
main()
运行之后可以看到训练进度:
训练中可以看到验证集的准确率,等待训练结束后,可以在 model 下看到保存的模型和 tokenizer 文件:
三、模型测试
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
label_dict = {
0: '恐惧',
1: '无情绪',
2: '悲伤',
3: '惊奇',
4: '愤怒',
5: '积极'
}
model_dir = "./model"
num_classes = 6
max_length = 128
def main():
# 加载预训练模型和分词器
tokenizer = AutoTokenizer.from_pretrained(model_dir)
model = AutoModelForSequenceClassification.from_pretrained(model_dir, num_labels=num_classes)
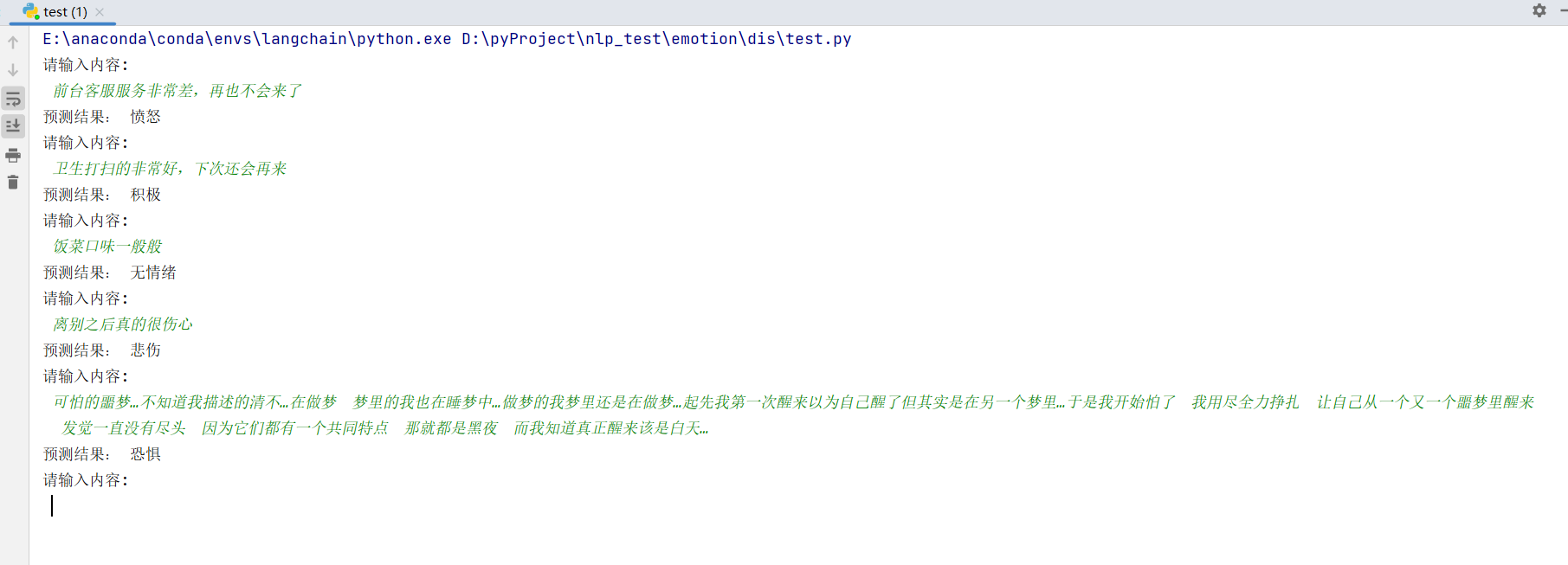
while True:
text = input("请输入内容: \n ")
if not text or text == "":
continue
if text == "q":
break
encoded_input = tokenizer(text, padding="max_length", truncation=True, max_length=max_length)
input_ids = torch.tensor([encoded_input['input_ids']])
token_type_ids = torch.tensor([encoded_input['token_type_ids']])
attention_mask = torch.tensor([encoded_input['attention_mask']])
# 前向传播
y_ = model(input_ids, token_type_ids=token_type_ids, attention_mask=attention_mask)
output = y_['logits'][0]
pred = output.max(-1, keepdim=True)[1][0].item()
print('预测结果:', label_dict[pred])
if __name__ == '__main__':
main()