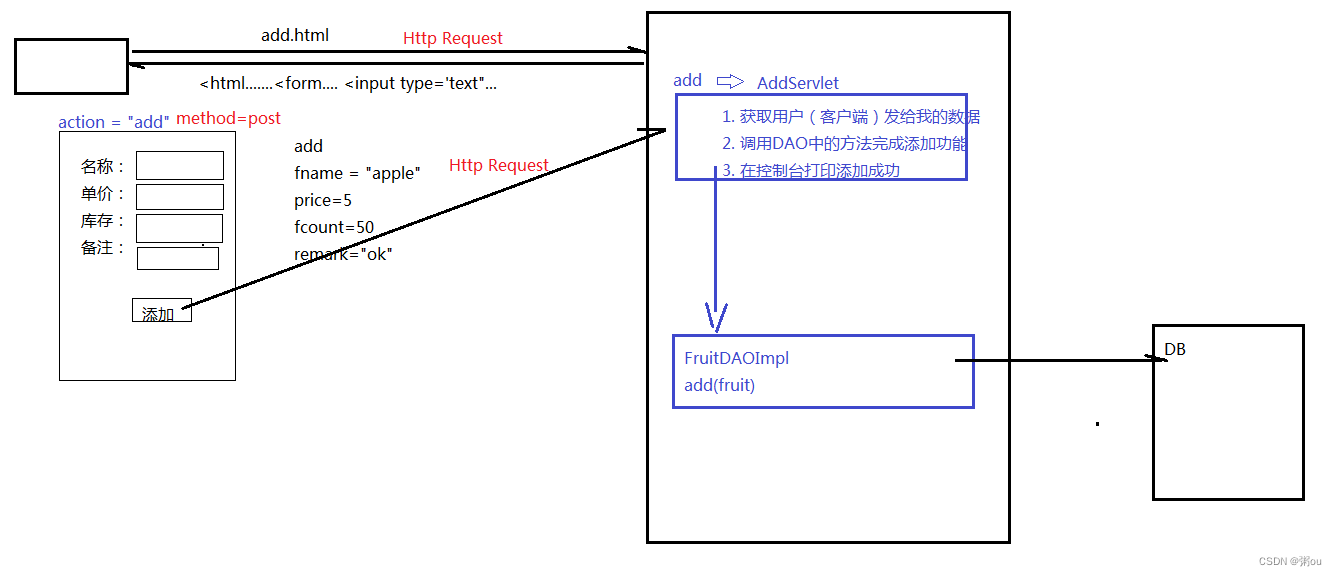
C++无锁编程——无锁队列(queue)
贺志国
2023.7.11
上一篇博客给出了最简单的C++数据结构——栈的几种无锁实现方法。队列的挑战与栈的有些不同,因为Push()和Pop()函数在队列中操作的不是同一个地方。因此同步的需求就不一样。需要保证对一端的修改是正确的,且对另一端是可见的。因此队列需要两个Node指针:head_和tail_。这两个指针都是原子变量,从而可在加锁的情形下,可给多个线程同时访问。首先来分析单生产者/单消费者的情形。
一、单生产者-单消费者模型下的无锁队列
单生产者/单消费者模型就是指,在某一时刻,最多只存在一个线程调用Push()函数,最多只存在一个线程调用Pop()函数。该情形下的代码(文件命名为 lock_free_queue.h)如下:
#pragma once
#include <atomic>
#include <memory>
template <typename T>
class LockFreeQueue {
public:
LockFreeQueue() : head_(new Node), tail_(head_.load()) {}
~LockFreeQueue() {
while (Node* old_head = head_.load()) {
head_.store(old_head->next);
delete old_head;
}
}
LockFreeQueue(const LockFreeQueue& other) = delete;
LockFreeQueue& operator=(const LockFreeQueue& other) = delete;
bool IsEmpty() const { return head_.load() == tail_.load(); }
void Push(const T& data) {
auto new_data = std::make_shared<T>(data);
Node* p = new Node; // 3
Node* old_tail = tail_.load(); // 4
old_tail->data.swap(new_data); // 5
old_tail->next = p; // 6
tail_.store(p); // 7
}
std::shared_ptr<T> Pop() {
Node* old_head = PopHead();
if (old_head == nullptr) {
return std::shared_ptr<T>();
}
const std::shared_ptr<T> res(old_head->data); // 2
delete old_head;
return res;
}
private:
// If the struct definition of Node is placed in the private data member
// field where 'head_' is defined, the following compilation error will occur:
//
// error: 'Node' has not been declared ...
//
// It should be a bug of the compiler. The struct definition of Node is put in
// front of the private member function `DeleteNodes` to eliminate this error.
struct Node {
// std::make_shared does not throw an exception.
Node() : data(nullptr), next(nullptr) {}
std::shared_ptr<T> data;
Node* next;
};
private:
Node* PopHead() {
Node* old_head = head_.load();
if (old_head == tail_.load()) { // 1
return nullptr;
}
head_.store(old_head->next);
return old_head;
}
private:
std::atomic<Node*> head_;
std::atomic<Node*> tail_;
};
一眼望去,这个实现没什么毛病,当只有一个线程调用Push()和Pop()时,这种情况下队列一点毛病没有。Push()和Pop()之间的先行(happens-before )关系非常重要,直接关系到能否安全地获取到队列中的数据。对尾部节点tail_的存储⑦(对应于上述代码片段中的注释// 7,下同)同步(synchronizes with)于对tail_的加载①,存储之前节点的data指针⑤先行(happens-before )于存储tail_。并且,加载tail_先行于加载data指针②,所以对data的存储要先行于加载,一切都没问题。因此,这是一个完美的单生产者/单消费者(SPSC, single-producer, single-consume)队列。
问题在于当多线程对Push()和Pop()并发调用。先看一下Push():如果有两个线程并发调用Push(),会新分配两个节点作为虚拟节点③,也会读取到相同的tail_值④,因此也会同时修改同一个节点,同时设置data和next指针⑤⑥,存在明显的数据竞争!
PopHead()函数也有类似的问题。当有两个线程并发的调用这个函数时,这两个线程就会读取到同一个head_,并且会通过next指针去修改旧值。两个线程都能索引到同一个节点——真是一场灾难!不仅要保证只有一个Pop()线程可以访问给定项,还要保证其他线程在读取head_时,可以安全的访问节点中的next,这就是和无锁栈中Pop()一样的问题了。
Pop()的问题假设已解决,那么Push()呢?问题在于为了获取Push()和Pop()间的先行关系,就需要在为虚拟节点设置数据项前,更新tail_指针。并发访问Push()时,因为每个线程所读取到的是同一个tail_,所以线程会进行竞争。
说明:
先行(happens-before )与同步(synchronizes with)是原子变量在线程间同步的两个重要关系。
Happens-before(先行)
Regardless of threads, evaluation A happens-before evaluation B if any of the following is true: 1) A is sequenced-before B; 2) A inter-thread happens before B. The implementation is required to ensure that the happens-before relation is acyclic, by introducing additional synchronization if necessary (it can only be necessary if a consume operation is involved). If one evaluation modifies a memory location, and the other reads or modifies the same memory location, and if at least one of the evaluations is not an atomic operation, the behavior of the program is undefined (the program has a data race) unless there exists a happens-before relationship between these two evaluations.
(无关乎线程,若下列任一为真,则求值 A 先行于求值 B :1) A 先序于 B;2) A 线程间先发生于 B。要求实现确保先发生于关系是非循环的,若有必要则引入额外的同步(若引入消费操作,它才可能为必要)。若一次求值修改一个内存位置,而其他求值读或修改同一内存位置,且至少一个求值不是原子操作,则程序的行为未定义(程序有数据竞争),除非这两个求值之间存在先行关系。)
Synchronizes with(同步)
If an atomic store in thread A is a release operation, an atomic load in thread B from the same variable is an acquire operation, and the load in thread B reads a value written by the store in thread A, then the store in thread A synchronizes-with the load in thread B. Also, some library calls may be defined to synchronize-with other library calls on other threads.
(如果在线程A上的一个原子存储是释放操作,在线程B上的对相同变量的一个原子加载是获得操作,且线程B上的加载读取由线程A上的存储写入的值,则线程A上的存储同步于线程B上的加载。此外,某些库调用也可能定义为同步于其它线程上的其它库调用。)
二、多生产者-多消费者模型下的无锁队列
为了解决多个线程同时访问产生的数据竞争问题,可以让Node节点中的data指针原子化,通过“比较/交换”操作对其进行设置。如果“比较/交换”成功,就说明能获取tail_,并能够安全的对其next指针进行设置,也就是更新tail_。因为有其他线程对数据进行了存储,所以会导致“比较/交换”操作的失败,这时就要重新读取tail_,重新循环。如果原子操作对于std::shared_ptr<>是无锁的,那么就基本结束了。然而,目前在多数平台中std::shared_ptr<>不是无锁的,这就需要一个替代方案:让Pop()函数返回std::unique_ptr<>,并且将数据作为普通指针存储在队列中。这就需要队列支持存储std::atomic<T*>类型,对于compare_exchange_strong()的调用就很有必要了。使用类似于无锁栈中的引用计数模式,来解决多线程对Pop()和Push()的访问。不过,队列中包含head_和tail_两个节点,因此需要两个引用计数器来维护节点的访问计数。下面是示例代码(文件命名为 lock_free_queue.h,示例来源于C++ Concurrency In Action, 2ed 2019,修复了其中的bug):
#pragma once
#include <atomic>
#include <memory>
template <typename T>
class LockFreeQueue {
public:
LockFreeQueue() : head_(CountedNodePtr(new Node)), tail_(head_.load()) {}
~LockFreeQueue() {
while (Pop()) {
// Do nothing
}
}
LockFreeQueue(const LockFreeQueue& other) = delete;
LockFreeQueue& operator=(const LockFreeQueue& other) = delete;
bool IsEmpty() const { return head_.load().ptr == tail_.load().ptr; }
bool IsLockFree() const { return head_.is_lock_free(); }
void Push(const T& data) {
auto new_data = std::make_unique<T>(data);
CountedNodePtr new_next(new Node);
new_next.external_count = 1;
CountedNodePtr old_tail = tail_.load();
while (true) {
IncreaseExternalCount(&tail_, &old_tail);
T* old_data = nullptr;
// We use compare_exchange_strong() to avoid looping. If the exchange
// fails, we know that another thread has already set the next pointer, so
// we don’t need the new node we allocated at the beginning, and we can
// delete it. We also want to use the next value that the other thread set
// for updating tail.
if (reinterpret_cast<Node*>(old_tail.ptr)
->data.compare_exchange_strong(old_data, new_data.get())) {
CountedNodePtr old_next =
reinterpret_cast<Node*>(old_tail.ptr)->next.load();
if (!reinterpret_cast<Node*>(old_tail.ptr)
->next.compare_exchange_strong(old_next, new_next)) {
delete reinterpret_cast<Node*>(new_next.ptr);
new_next = old_next;
}
SetNewTail(new_next, &old_tail);
// Release the ownership of the managed object so that the data will not
// be deleted beyond the scope the unique_ptr<T>.
new_data.release();
break;
} else {
// If the thread calling Push() failed to set the data pointer this time
// through the loop, it can help the successful thread to complete the
// update. First off, we try to update the next pointer to the new node
// allocated on this thread. If this succeeds, we want to use the node
// we allocated as the new tail node, and we need to allocate another
// new node in anticipation of managing to push an item on the queue. We
// can then try to set the tail node by calling set_new_tail before
// looping around again.
CountedNodePtr old_next =
reinterpret_cast<Node*>(old_tail.ptr)->next.load();
if (reinterpret_cast<Node*>(old_tail.ptr)
->next.compare_exchange_strong(old_next, new_next)) {
old_next = new_next;
new_next.ptr = reinterpret_cast<uint64_t>(new Node);
}
SetNewTail(old_next, &old_tail);
}
}
}
std::unique_ptr<T> Pop() {
// We prime the pump by loading the old_head value before we enter the loop,
// and before we increase the external count on the loaded value.
CountedNodePtr old_head = head_.load();
while (true) {
IncreaseExternalCount(&head_, &old_head);
// If the head node is the same as the tail node, we can release the
// reference and return a null pointer because there’s no data in the
// queue.
Node* ptr = reinterpret_cast<Node*>(old_head.ptr);
if (ptr == nullptr) {
return std::unique_ptr<T>();
}
if (ptr == reinterpret_cast<Node*>(tail_.load().ptr)) {
ptr->ReleaseRef();
return std::unique_ptr<T>();
}
// If there is data, we want to try to claim it and we do this with the
// call to compare_exchange_strong(). It compares the external count and
// pointer as a single entity; if either changes, we need to loop again,
// after releasing the reference.
CountedNodePtr next = ptr->next.load();
if (head_.compare_exchange_strong(old_head, next)) {
// If the exchange succeeded, we’ve claimed the data in the node as
// ours, so we can return that to the caller after we’ve released the
// external counter to the popped node.
T* res = ptr->data.exchange(nullptr);
FreeExternalCounter(&old_head);
return std::unique_ptr<T>(res);
}
// Once both the external reference counts have been freed and the
// internal count has dropped to zero, the node itself can be deleted.
ptr->ReleaseRef();
}
}
private:
// Forward class declaration
struct Node;
struct CountedNodePtr {
explicit CountedNodePtr(Node* input_ptr = nullptr)
: ptr(reinterpret_cast<uint64_t>(input_ptr)), external_count(0) {}
// We know that the platform has spare bits in a pointer (for example,
// because the address space is only 48 bits but a pointer is 64 bits), we
// can store the count inside the spare bits of the pointer to fit it all
// back in a single machine word. Keeping the structure within a machine
// word makes it more likely that the atomic operations can be lock-free on
// many platforms.
uint64_t ptr : 48;
uint16_t external_count : 16;
};
struct NodeCounter {
NodeCounter() : internal_count(0), external_counters(0) {}
NodeCounter(const uint32_t input_internal_count,
const uint8_t input_external_counters)
: internal_count(input_internal_count),
external_counters(input_external_counters) {}
// external_counters occupies only 2 bits, where the maximum value stored
// is 3. Note that we need only 2 bits for the external_counters because
// there are at most two such counters. By using a bit field for this and
// specifying internal_count as a 30-bit value, we keep the total counter
// size to 32 bits. This gives us plenty of scope for large internal count
// values while ensuring that the whole structure fits inside a machine word
// on 32-bit and 64-bit machines. It’s important to update these counts
// together as a single entity in order to avoid race conditions. Keeping
// the structure within a machine word makes it more likely that the atomic
// operations can be lock-free on many platforms.
uint32_t internal_count : 30;
uint8_t external_counters : 2;
};
struct Node {
// There are only two counters in Node (counter and next), so the initial
// value of external_counters is 2.
Node()
: data(nullptr), counter(NodeCounter(0, 2)), next(CountedNodePtr()) {}
void ReleaseRef() {
NodeCounter old_node = counter.load();
NodeCounter new_counter;
// the whole count structure has to be updated atomically, even though we
// only want to modify the internal_count field. This therefore requires a
// compare/exchange loop.
do {
new_counter = old_node;
--new_counter.internal_count;
} while (!counter.compare_exchange_strong(old_node, new_counter));
// Once we’ve decremented internal_count, if both the internal and
// external counts are now zero, this is the last reference, so we can
// delete the node safely.
if (!new_counter.internal_count && !new_counter.external_counters) {
delete this;
}
}
std::atomic<T*> data;
std::atomic<NodeCounter> counter;
std::atomic<CountedNodePtr> next;
};
private:
static void IncreaseExternalCount(std::atomic<CountedNodePtr>* atomic_node,
CountedNodePtr* old_node) {
CountedNodePtr new_node;
// If `*old_node` is equal to `*atomic_node`, it means that no other thread
// changes the `*atomic_node`, update `*atomic_node` to `new_node`. In fact
// the `*atomic_node` is still the original node, only the `external_count`
// of it is increased by 1. If `*old_node` is not equal to `*atomic_node`,
// it means that another thread has changed `*atomic_node`, update
// `*old_node` to `*atomic_node`, and keep looping until there are no
// threads changing `*atomic_node`.
do {
new_node = *old_node;
++new_node.external_count;
} while (!atomic_node->compare_exchange_strong(*old_node, new_node));
old_node->external_count = new_node.external_count;
}
static void FreeExternalCounter(CountedNodePtr* old_node) {
Node* ptr = reinterpret_cast<Node*>(old_node->ptr);
const int increased_count = old_node->external_count - 2;
NodeCounter old_counter = ptr->counter.load();
NodeCounter new_counter;
// Update two counters using a single compare_exchange_strong() on the
// whole count structure, as we did when decreasing the internal_count
// in ReleaseRef().
// This has to be done as a single action (which therefore requires the
// compare/exchange loop) to avoid a race condition. If they’re updated
// separately, two threads may both think they are the last one and both
// delete the node, resulting in undefined behavior.
do {
new_counter = old_counter;
--new_counter.external_counters;
new_counter.internal_count += increased_count;
} while (!ptr->counter.compare_exchange_strong(old_counter, new_counter));
// If both the values are now zero, there are no more references to the
// node, so it can be safely deleted.
if (!new_counter.internal_count && !new_counter.external_counters) {
delete ptr;
}
}
void SetNewTail(const CountedNodePtr& new_tail, CountedNodePtr* old_tail) {
// Use a compare_exchange_weak() loop to update the tail , because if other
// threads are trying to push() a new node, the external_count part may have
// changed, and we don’t want to lose it.
Node* current_tail_ptr = reinterpret_cast<Node*>(old_tail->ptr);
while (!tail_.compare_exchange_weak(*old_tail, new_tail) &&
reinterpret_cast<Node*>(old_tail->ptr) == current_tail_ptr) {
// Do nothing
}
// We also need to take care that we don’t replace the value if another
// thread has successfully changed it already; otherwise, we may end up with
// loops in the queue, which would be a rather bad idea. Consequently, we
// need to ensure that the ptr part of the loaded value is the same if the
// compare/exchange fails. If the ptr is the same once the loop has exited,
// then we must have successfully set the tail , so we need to free the old
// external counter. If the ptr value is different, then another thread will
// have freed the counter, so we need to release the single reference held
// by this thread.
if (reinterpret_cast<Node*>(old_tail->ptr) == current_tail_ptr) {
FreeExternalCounter(old_tail);
} else {
current_tail_ptr->ReleaseRef();
}
}
private:
std::atomic<CountedNodePtr> head_;
std::atomic<CountedNodePtr> tail_;
};
上述代码中,值得特别指出的是,带引用计数的节点指针结构体CountedNodePtr使用了位域的概念:
struct CountedNodePtr {
explicit CountedNodePtr(Node* input_ptr = nullptr)
: ptr(reinterpret_cast<uint64_t>(input_ptr)), external_count(0) {}
uint64_t ptr : 48;
uint16_t external_count : 16;
};
};
为什么要这么做?现在主流的操作系统和编译器只支持最多8字节数据类型的无锁操作,即std::atomic<CountedNodePtr>的成员函数is_lock_free只有在sizeof(CountedNodePtr) <= 8时才会返回true。因此,必须将CountedNodePtr的字节数控制8以内,于是我们想到了位域。在主流的操作系统中,指针占用的空间不会超过48位(如果超过该尺寸则必须重新设计位域大小,请查阅操作系统使用手册确认),为此将external_count分配16位(最大支持65535),ptr分配48位,合计64位(8字节)。此时,std::atomic<CountedNodePtr>的成员函数is_lock_free在主流操作系统中都会返回true,是真正的无锁原子变量。为了适应上述更改,必须使用reinterpret_cast<Node*>(new_node.ptr)完成ptr从uint64_t到Node*类型的转换,使用reinterpret_cast<uint64_t>(new Node(data)完成指针变量从ptr从Node*到uint64_t类型的转换,从而正常地存储于ptr中。
同样地,另一个节点计数器结构体NodeCounter也使用了位域的概念:
struct NodeCounter {
NodeCounter() : internal_count(0), external_counters(0) {}
NodeCounter(const uint32_t input_internal_count,
const uint8_t input_external_counters)
: internal_count(input_internal_count),
external_counters(input_external_counters) {}
uint32_t internal_count : 30;
uint8_t external_counters : 2;
};
理由也是让std::atomic<NodeCounter>成为真正的无锁原子变量。该结构体中,external_counters只占2位,最大支持的数值为3,因为队列中有head_和tail_两个节点,只需要两个引用计数器分别对其的引用计数,因此external_counters的最大值只需为2,占两位足够。internal_count分配30位(最大支持1073741823)。两个元素合计32位(4字节)。此时,std::atomic<NodeCounter>的成员函数is_lock_free在主流操作系统中都会返回true,是真正的无锁原子变量。
三、测试代码
下面给出测试无锁栈工作是否正常的简单测试代码(文件命名为:lock_free_queue.cpp):
#include "lock_free_queue.h"
#include <algorithm>
#include <iostream>
#include <random>
#include <thread>
#include <vector>
namespace {
constexpr size_t kElementNum = 10;
constexpr size_t kThreadNum = 200;
constexpr size_t kLargeThreadNum = 2000;
} // namespace
int main() {
LockFreeQueue<int> queue;
// Case 1: Single thread test
for (size_t i = 0; i < kElementNum; ++i) {
std::cout << "The data " << i << " is pushed in the queue.\n";
queue.Push(i);
}
std::cout << "queue.IsEmpty() == " << std::boolalpha << queue.IsEmpty()
<< std::endl;
while (auto data = queue.Pop()) {
std::cout << "Current data is : " << *data << '\n';
}
// Case 2: multi-thread test. Producers and consumers are evenly distributed
std::vector<std::thread> producers1;
std::vector<std::thread> producers2;
std::vector<std::thread> consumers1;
std::vector<std::thread> consumers2;
for (size_t i = 0; i < kThreadNum; ++i) {
producers1.emplace_back(&LockFreeQueue<int>::Push, &queue, i * 10);
producers2.emplace_back(&LockFreeQueue<int>::Push, &queue, i * 20);
consumers1.emplace_back(&LockFreeQueue<int>::Pop, &queue);
consumers2.emplace_back(&LockFreeQueue<int>::Pop, &queue);
}
for (size_t i = 0; i < kThreadNum; ++i) {
producers1[i].join();
consumers1[i].join();
producers2[i].join();
consumers2[i].join();
}
producers1.clear();
producers1.shrink_to_fit();
producers2.clear();
producers2.shrink_to_fit();
consumers1.clear();
consumers1.shrink_to_fit();
consumers2.clear();
consumers2.shrink_to_fit();
// Case 3: multi-thread test. Producers and consumers are randomly distributed
std::vector<std::thread> producers3;
std::vector<std::thread> consumers3;
for (size_t i = 0; i < kLargeThreadNum; ++i) {
producers3.emplace_back(&LockFreeQueue<int>::Push, &queue, i * 30);
consumers3.emplace_back(&LockFreeQueue<int>::Pop, &queue);
}
std::vector<int> random_numbers(kLargeThreadNum);
std::mt19937 gen(std::random_device{}());
std::uniform_int_distribution<int> dis(0, 100000);
auto rand_num_generator = [&gen, &dis]() mutable { return dis(gen); };
std::generate(random_numbers.begin(), random_numbers.end(),
rand_num_generator);
for (size_t i = 0; i < kLargeThreadNum; ++i) {
if (random_numbers[i] % 2) {
producers3[i].join();
consumers3[i].join();
} else {
consumers3[i].join();
producers3[i].join();
}
}
consumers3.clear();
consumers3.shrink_to_fit();
consumers3.clear();
consumers3.shrink_to_fit();
return 0;
}
CMake的编译配置文件CMakeLists.txt:
cmake_minimum_required(VERSION 3.0.0)
project(lock_free_queue VERSION 0.1.0)
set(CMAKE_CXX_STANDARD 17)
# If the debug option is not given, the program will not have debugging information.
SET(CMAKE_BUILD_TYPE "Debug")
add_executable(${PROJECT_NAME} ${PROJECT_NAME}.cpp)
find_package(Threads REQUIRED)
# libatomic should be linked to the program.
# Otherwise, the following link errors occured:
# /usr/include/c++/9/atomic:254: undefined reference to `__atomic_load_16'
# /usr/include/c++/9/atomic:292: undefined reference to `__atomic_compare_exchange_16'
# target_link_libraries(${PROJECT_NAME} ${CMAKE_THREAD_LIBS_INIT} atomic)
target_link_libraries(${PROJECT_NAME} ${CMAKE_THREAD_LIBS_INIT})
include(CTest)
enable_testing()
set(CPACK_PROJECT_NAME ${PROJECT_NAME})
set(CPACK_PROJECT_VERSION ${PROJECT_VERSION})
include(CPack)
上述配置中添加了对原子库atomic的链接。因为引用计数的结构体CountedNodePtr包含两个数据成员(注:最初实现的版本未使用位域,需要添加对原子库atomic的链接。新版本使用位域,不再需要添加):int external_count; Node* ptr;,这两个变量占用16字节,而16字节的数据结构需要额外链接原子库atomic,否则会出现链接错误:
/usr/include/c++/9/atomic:254: undefined reference to `__atomic_load_16'
/usr/include/c++/9/atomic:292: undefined reference to `__atomic_compare_exchange_16'
VSCode调试启动配置文件.vscode/launch.json:
{
"version": "0.2.0",
"configurations": [
{
"name": "cpp_gdb_launch",
"type": "cppdbg",
"request": "launch",
"program": "${workspaceFolder}/build/${workspaceFolderBasename}",
"args": [],
"stopAtEntry": false,
"cwd": "${fileDirname}",
"environment": [],
"externalConsole": false,
"MIMode": "gdb",
"setupCommands": [
{
"description": "Enable neat printing for gdb",
"text": "-enable-pretty-printing",
"ignoreFailures": true
}
],
// "preLaunchTask": "cpp_build_task",
"miDebuggerPath": "/usr/bin/gdb"
}
]
}
使用CMake的编译命令:
cd lock_free_queue
# 只执行一次
mkdir build
cd build
cmake .. && make
运行结果如下:
./lock_free_queue
The data 0 is pushed in the queue.
The data 1 is pushed in the queue.
The data 2 is pushed in the queue.
The data 3 is pushed in the queue.
The data 4 is pushed in the queue.
The data 5 is pushed in the queue.
The data 6 is pushed in the queue.
The data 7 is pushed in the queue.
The data 8 is pushed in the queue.
The data 9 is pushed in the queue.
queue.IsEmpty() == false
Current data is : 0
Current data is : 1
Current data is : 2
Current data is : 3
Current data is : 4
Current data is : 5
Current data is : 6
Current data is : 7
Current data is : 8
Current data is : 9
VSCode调试界面如下: