文章目录
- 手写数字识别
- 网络结构
- 加载数据集
- 数据集可视化
- CNN网络结构
- 训练模型
- 保存模型和加载模型
- 测试模型
手写数字识别
网络结构
网上给出的基本网络结构:
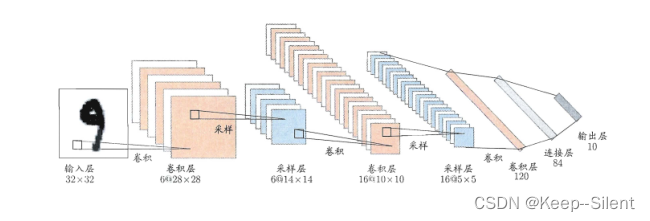
然而在本数据集中,输入图不是1*32*32,是1*28*28。所以正确的网络结构应该是
| level | input | stride | output | |
| 1 | 1*28*28 | 6*5*5 | 1 | 6*24*24 |
| MaxPool | 6*24*24 | MaxPool | 2 | 6*12*12 |
| 2 | 6*12*12 | 16*5*5 | 1 | 16*8*8 |
| MaxPool | 16*8*8 | MaxPool | 2 | 16*4*4 |
| Flatten | 16*4*4 | Flatten | 256 | |
| 3FC | 256 | FC | 120 | |
| 4FC | 120 | FC | 84 | |
| 5FC | 84 | FC | 10 |
加载数据集
# -*-coding =utf-8 -*-
import torch
import matplotlib.pyplot as plt
import torchvision
# 定义数据转换
transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.1307,), (0.3081,))
])
# 加载数据集
batch_size=32
path = r'05data'
train_dataset = torchvision.datasets.MNIST(root=path, train=True,transform=transform,download =False)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_dataset = torchvision.datasets.MNIST(root=path, train=True,transform=transform,download =False)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=True)
# loader.shape=1875*[32*1*28*28,32]
最后loader.shape是1875*[32*1*28*28,32],即 number*[batch(data)*height*width, batch(label)]
数据集可视化
from sklearn.preprocessing import MinMaxScaler
# 归一化转为[0,255]
transfer=MinMaxScaler(feature_range=(0, 255))
def visualize_loader(batch,predicted=''):
# batch=[32*1*28*28,32]
imgs=batch[0].squeeze().numpy() # 消squeeze()一维
fig, axes = plt.subplots(4, 8, figsize=(12, 6))
labels=batch[1].numpy()
if str(predicted)=='':
predicted=labels
for i, ax in enumerate(axes.flat):
ax.imshow(imgs[i])
ax.set_title(predicted[i],color='black' if predicted[i]==labels[i] else 'red')
ax.axis('off')
plt.tight_layout()
plt.show()
# loader.shape=1875*[32*1*28*28,32]
for batch in train_loader:
break
visualize_loader(batch)

上图是对数据集的可视化。
CNN网络结构
在PyTorch的torch.nn模块中,卷积函数Conv2d的输入张量的形状应为[batch_size, channels, height, width]对应数据集,无需修改(在一些架构中,可能是[batch_size, height, width, channels])。
# 创建模型
import torch
import torch.nn as nn
import torch.optim as optim
# 定义模型
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 6, kernel_size=5, stride=1)
self.relu = nn.ReLU()
self.maxpool = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(6, 16, kernel_size=5, stride=1)
self.flatten=nn.Flatten()
self.fc3 = nn.Linear(256, 120)
self.fc4 = nn.Linear(120, 84)
self.fc5 = nn.Linear(84, 10)
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.conv2(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.flatten(x)
x = self.fc3(x)
x = self.relu(x)
x = self.fc4(x)
x = self.relu(x)
x = self.fc5(x)
return x
打印模型结构
model = CNN()
print(model)
CNN(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(relu): ReLU()
(maxpool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(flatten): Flatten(start_dim=1, end_dim=-1)
(fc3): Linear(in_features=256, out_features=120, bias=True)
(fc4): Linear(in_features=120, out_features=84, bias=True)
(fc5): Linear(in_features=84, out_features=10, bias=True)
)
训练模型
import torch.optim as optim
num_epochs=1
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
correct = 0
total = 0
for images, labels in train_loader:
images = images.to(device)
labels = labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 统计准确率
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
running_loss += loss.item()
train_loss = running_loss / len(train_loader)
train_accuracy = correct / total
# 在测试集上评估模型
model.eval()
test_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
test_loss += loss.item()
test_loss = test_loss / len(test_loader)
test_accuracy = correct / total
# 打印训练过程中的损失和准确率
print(f"Epoch [{epoch+1}/{num_epochs}] - Train Loss: {train_loss:.4f}, Train Accuracy: {train_accuracy:.4f}, Test Loss: {test_loss:.4f}, Test Accuracy: {test_accuracy:.4f}")
Epoch [1/1] - Train Loss: 0.0154, Train Accuracy: 0.9951, Test Loss: 0.0109, Test Accuracy: 0.9964
保存模型和加载模型
#torch.save(model.state_dict(), '05model.pth')
# 创建一个新的模型实例
model = CNN()
# 加载模型的参数
model.load_state_dict(torch.load('05model.pth'))
测试模型
for batch in test_loader:
break
imgs=batch[0]
outputs = model(imgs)
_, predicted = torch.max(outputs.data, 1)
predicted=predicted.numpy()
print(predicted)
visualize_loader(batch,predicted)

上图中可视化了其中的32次预测,只有第三行第四列的“8”被预测为“5”,其余均是正确。
在测试集的总体预测准确度为99.64%,正确率挺高的。